参考文档:
https://www.zhihu.com/question/28586791/answer/767316172
https://zhuanlan.zhihu.com/p/57361216 http://www.weixueyuan.net/nginx/compile/
1 从HTTP协议本身来讲
1.1 HTTP协议下GET和POST的核心区别
1.1.1 概览
从HTTP协议本身来讲的话,GET 和 POST 方法没有实质区别,只是报文格式不同。
GET和POST只是HTTP协议中两种请求方式,而HTTP协议是基于TCP/IP的应用层协议,无论GET还是POST,用的都是同一个传输层协议,他们能做的事情是一样的。从技术上,我们也可以给GET加上request body,给POST带上url参数。只是HTTP协议的规范来讲,这样不推荐。
1.1.2 核心差别:传输报文格式差别(HTTP协议推荐但不强制)
传输的数据不带参数时
传输不带数据参数时,GET和POST的最大区别Request Header请求头的第一行显示内容不一致。
POST请求:POST /Web/SalesAssist/Select HTTP/1.1
GET请求: GET /Web/SalesAssist/Select HTTP/1.1
不带参数时他们的区别就仅仅是报文的前几个字符不同而已
传输的数据带参数时
带参数时,从HTTP协议规范角度,GET方法的参数必须放在URL中,POST方法的参数应该放在Body中。
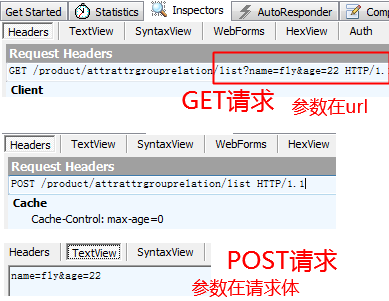
举个例子,如果参数是 name=fly,age=22
GET的简约版报文为:
GET /product/attrattrgrouprelation/list?name=fly&age=22 HTTP/1.1
Host: localhost
POST的简约版报文为:
POST /index.php HTTP/1.1
Host: localhost
Content-Type: application/x-www-form-urlencoded
name=fly&age=22
1.1.3 概览总结
现在我们知道了两种方法本质上都是 TCP 连接,其没有差别,也就是说,如果我不按规范来也是可以的。我们可以在 URL 上写参数,然后方法使用 POST;也可以在 Body 写参数,然后方法使用 GET。当然,这需要服务端支持。当然,我们会强烈建议遵照HTTP协议本身的规范制定我们的方案。
1.2 常见问题
1.2.1 GET方法的参数写法是固定的吗?
在默认约定中,我们的参数是写在?后面,用&切割。
我们知道,解析报文的过程是通过获取 TCP 数据,用正则等工具从数据中获取 Header 和 Body,从而提取参数。
也就是说,我们可以自己约定参数的写法,只要服务端能够解释出来就行,一种比较流行的写法是 http://www.example.com/user/name/fly/age/22。
1.2.2 POST方法比GET方法更安全吗?
按照网上大部分文章的解释,POST 比 GET 安全,因为数据在地址栏上不可见。从某种角度来讲,也可以这么算,因为参数直接暴露在URL,会增大安全暴露的风险,同时在后台日志记录的时候也会记录到GET请求链接附带的参数。
但,从传输的角度来说,其实他们都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文。要想安全传输,就只有加密,也就是 HTTPS
回到HTTP本身,的确GET请求的参数更倾向于放在url上,因此有更多机会被泄漏。比如携带私密信息的url会展示在地址栏上,还可以分享给第三方,就非常不安全了。此外,从客户端到服务器端,有大量的中间节点,包括网关,代理等。他们的access log通常会输出完整的url,比如nginx的默认access log就是如此。如果url上携带敏感数据,就会被记录下来。但请注意,就算私密数据在body里,也是可以被记录下来的,因此如果请求要经过不信任的公网,避免泄密的唯一手段就是https。这里说的“避免access log泄漏“仅仅是指避免可信区域中的http代理的默认行为带来的安全隐患。比如你是不太希望让自己公司的运维同学从公司主网关的log里看到用户的密码吧。
1.2.3 GET 方法的长度限制是怎么回事
在网上看到很多关于两者区别的文章都有这一条,提到浏览器地址栏输入的参数是有限的。
首先说明一点,HTTP 协议没有 Body 和 URL 的长度限制,对 URL 限制的大多是浏览器和服务器的原因。
浏览器原因就不说了,服务器是因为处理长 URL 要消耗比较多的资源,为了性能和安全(防止恶意构造长 URL 来攻击)考虑,会给 URL 长度加限制。
1.2.4 POST 方法会产生两个TCP数据包
有些文章中提到,post 会将 header 和 body 分开发送,先发送 header,服务端返回 100 状态码再发送 body。
HTTP 协议中没有明确说明 POST 会产生两个 TCP 数据包,而且实际测试(Chrome)发现,header 和 body 不会分开发送。
所以,header 和 body 分开发送是部分浏览器或框架的请求方法,不属于 post 必然行为。
1.2.5 从编码的角度
常见的说法有,比如GET的参数只能支持ASCII,而POST能支持任意binary,包括中文。但其实从上面可以看到,GET和POST实际上都能用url和body。因此所谓编码确切地说应该是http中url用什么编码,body用什么编码。
但要特别注意,这个编码方式只管把字符转换成URL可用字符,但是却不管字符集编码(比如中文到底是用UTF8还是GBK)这块早期一直都相当乱,也没有什么统一规范。比如有时跟网页编码一样,有的是操作系统的编码一样。最要命的是浏览器的地址栏是不受开发者控制的。这样,对于同样一个带中文的url,如果有的浏览器一定要用GBK(比如老的IE8),有的一定要用UTF8(比如chrome)。后端就可能认不出来。对此常用的办法是避免让用户输入这种带中文的url。如果有这种形式的请求,都改成用户界面上输入,然后通过Ajax发出的办法。Ajax发出的编码形式开发者是可以100%控制的。
顺便说一句,尽管在浏览器地址栏可以看到中文。但这种url在发送请求过程中,浏览器会把中文用字符编码+Percent Encode(即URL Encoding)翻译为真正的url,再发给服务器。浏览器地址栏里的中文只是想让用户体验好些而已。
2 从浏览器的角度分析GET/POST请求
2.1 此处浏览器的定义
HTTP最早被用来做浏览器与服务器之间交互HTML和表单的通讯协议;后来又被被广泛的扩充到接口格式的定义上。所以在讨论GET和POST区别的时候,需要现确定下到底是浏览器使用的GET/POST还是用HTTP作为接口传输协议的场景。此处我们从浏览器的角度来谈GET/POST是特指浏览器中**非**Ajax的HTTP请求,即从HTML和浏览器诞生就一直使用的HTTP协议中的GET/POST。浏览器用GET请求来获取一个html页面/图片/css/js等资源;用POST来提交一个

若有收获,就点个赞吧
0 人点赞
