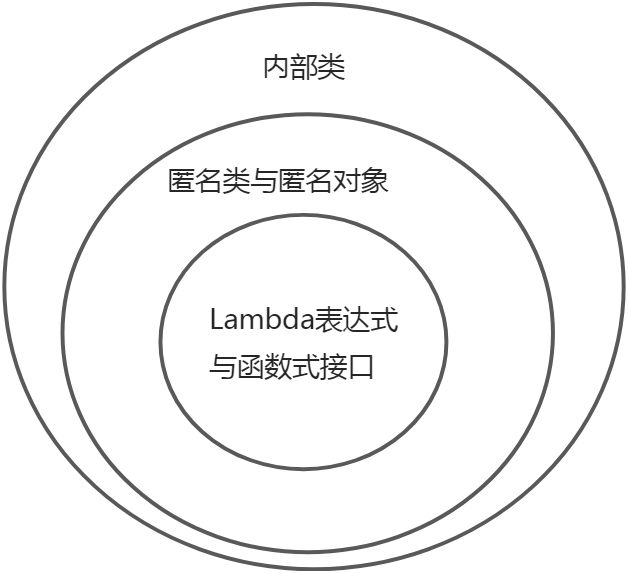
1 Lambda表达式(匿名对象实现方法)
Lambda表达式的本质=>名动词的综合体:左边是匿名对象(名词),右边是接口的方法实现体(动词)。即最核心的就是记住Lambda的接口的方法长成什么样子。
通用概览(函数式接口FI->匿名函数)
Lambda表达式的演变:内部类->匿名类(匿名对象)->Lambda表达式(函数式接口)->简易方法(IF)- 注意:实例化后的接口对象方法必须再额外调用(如果是StreamAPI一般都是由Stream对象内部自己调用),不能自调用(如线程内部的Runnable.run方法都是线程内部自己调用的。
- 在JAVA里面Lambda是一个匿名对象,在外观和功能以及本质上可以理解为是匿名函数。
1.1 Lambda的本质一:函数式接口的实例对象
概述
只包含一个抽象方法的接口,称为函数式接口。
可以在一个接口上使用 @FunctionalInterface 注解,可以检查它是否是一个函数式接口。在java.util.function包下定义了Java 8 的丰富的函数式接口。
函数式接口举例
@FunctionalInterfacepublic interface Runnable {public abstract void run();}
如何理解函数式接口?
- Java从诞生日起就是一直倡导“一切皆对象”,在Java里面面向对象(OOP)编程是一切。但是随着python、scala等语言的兴起和新技术的挑战,Java不得不做出调整以便支持更加广泛的技术要求,也即java不但可以支持OOP还可以支持OOF(面向函数编程)。
- 在函数式编程语言当中,函数被当做一等公民对待。在将函数作为一等公民的编程语言中,Lambda表达式的类型是函数。但是在Java8中,有所不同。在Java8中,Lambda表达式是对象,而不是函数,它们必须依附于一类特别的对象类型——函数式接口实例类型。即简单的说,在Java8中,Lambda表达式就是一个函数式接口的实例。这就是Lambda表达式和函数式接口的关系。也就是说,只要一个对象是函数式接口的实例,那么该对象就可以用Lambda表达式来表示。
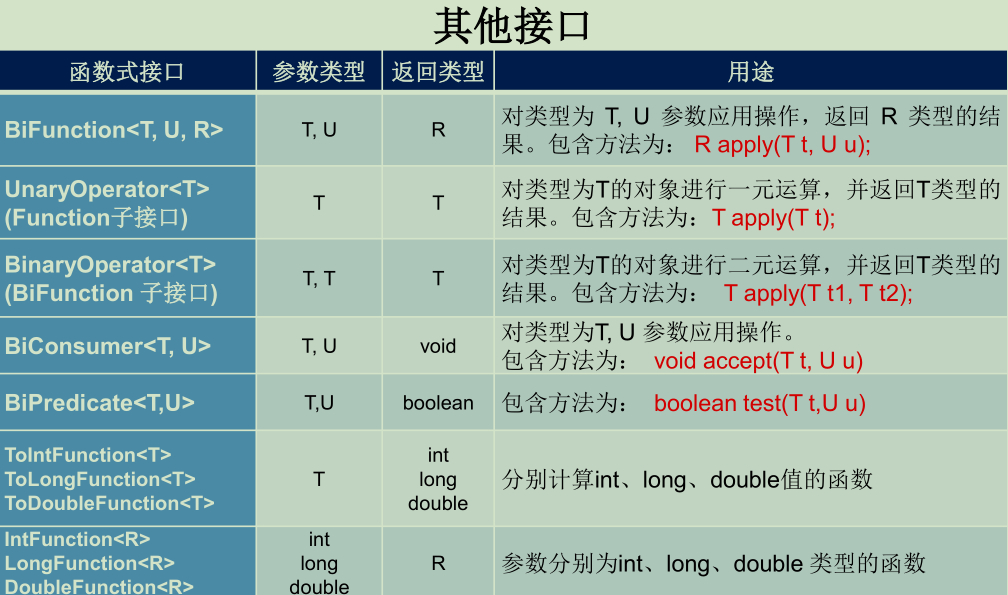
Java内置的函数式接口
| | 函数式接口 | 参数类型 | 返回类型 | 用途 | | —- | —- | —- | —- | —- | | 四大核心函数式接口 | Consumer消费型接口 | T | void | 对类型为T的对象应用操作,包含方法:void accept(T t) | | | Supplier 供给型接口 | 无 | T | 返回类型为T的对象,包含方法:T get() | | | Function 断定型接口 | T | boolean | 确定类型为T的对象是否满足某约束,并返回boolean 值。包含方法:boolean test(T t) | | 高频函数式接口 | Runable | 无 | void | 用于线程实例化方法时使用:The Runnableinterface should be implemented by any
* class whose instances are intended to be executed by a thread
包含方法:void run(); | | | Callable供给型接口(有异常) | 无 | V | A task that returns a result and may throw an exception.
包含方法V call() throws Exception; |
1.2 Lambda的身份二:匿名对象
阶段一:由内部类演变为匿名类(匿名对象)
内部类
定义:Java中允许将一个类A声明在另一个类B中,则类A就是内部类,类B称为外部类。
代码/*外部类*/public class OuterClass {/*内部类*/public class InnerClass{}}
匿名类与匿名对象
- 匿名类一定是内部类
- 匿名类在产生的时候同时会伴随匿名对象 的产生
我们先看一个不使用匿名类的场景
package AnonymousInner;abstract class Father{public abstract void speak();}class Son extends Father{@Overridepublic void speak() {System.out.println("我是熊孩子");}}public class MainDemo {public static void main(String[] args) {Father f=new Son();f.speak();}}//最后打印输出的是:我是熊孩子
可以看到,我们用Son继承了Father类,然后实现了Son的一个实例,将其向上转型为Father类的引用。
但是,如果此处的Son类只使用一次,那么将其编写为独立的一个类岂不是很麻烦?这个时候就应该想到匿名内部类了,我们可以使用匿名内部类来实现抽象方法。具体代码如下:使用匿名内部类有个前提条件:必须继承一个父类或实现一个接口,但最多只能继承一个父类,或实现一个接口
package AnonymousInner;abstract class Father{public abstract void speak();}public class MainDemo {public static void main(String[] args) {Father f=new Father() {@Overridepublic void speak() {System.out.println("我是熊孩子");}};}}//抽离出来的代码:public class NIMingDemo{Father f = new Father(){ .... };//{}里就是个匿名内部类,一般匿名类的使用都是附带的匿名对象的}
使用总结
- 匿名内部类是局部内部类的更深入一步,假如只创建某类的一个对象时,就不必将该类进行命名。
- 匿名内部类的前提是存在一个类或者接口,且匿名内部类是写在匿名方法中的,创建匿名类的同时也会创建一个匿名对象
- 如果对一个对象只需要进行一次方法调用,那么就可以使用匿名对象:
int age = new Person().getAge();即需要重写多个方法时不建议使用。 - 常将匿名对象作为实参传递给一个方法调用:
Test(new Person());阶段二:由匿名对象演变为Lambda表达式
Lambda 是一个匿名函数,我们可以把Lambda 表达式理解为是一段可以传递的代码(将代码像数据一样进行传递)。可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升。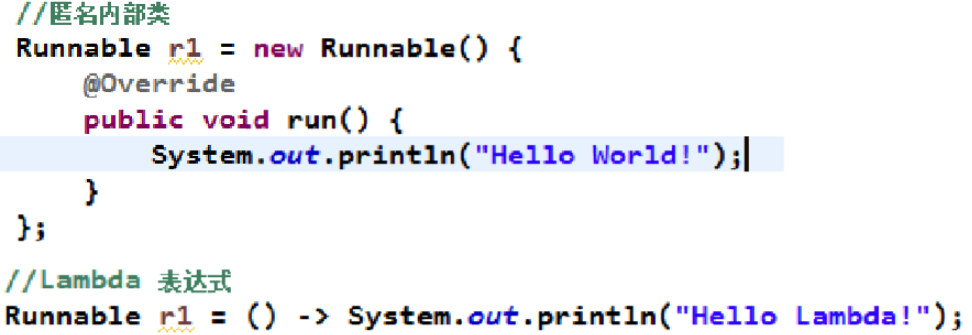
阶段二补充:Lambda即为函数式接口实例对象
需要注意的是:Lambda表达式除了是匿名对象的一个特殊情况下,其更是函数式接口的实例对象。1.3 Lambda表达式语法(参数->匿名函数)
Lambda 表达式在Java 语言中引入了一个新的语法元素和操作符。这个操作符为“->” ,该操作符被称为Lambda 操作符或箭头操作符。它将Lambda 分为两个部分:
左侧:指定了Lambda 表达式需要的所有参数
右侧:指定了Lambda 体,即Lambda 表达式要执行的功能。
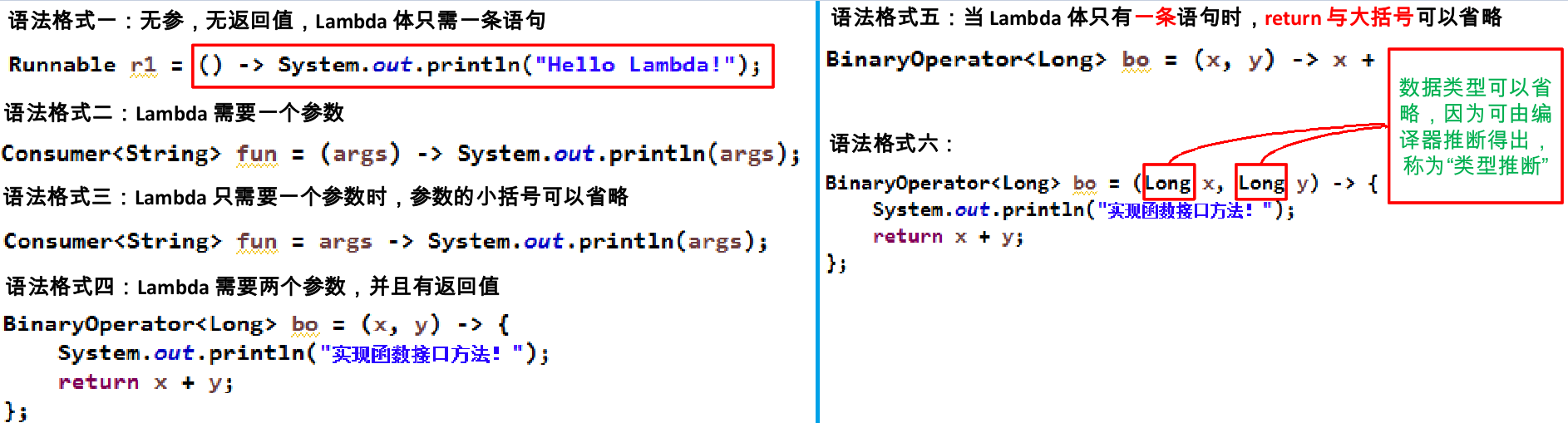
| 特征 | 代码说明 | |
|---|---|---|
| 未转变前 |
使用匿名函数```java |
BiFunction
| || Lambda表达式通用样式:()->{} | 左边用()代表参数,右边用{}代表方法体,中间用->做连接```javaBiFunction<Integer, Float, Float> biFunction = (o, f) -> {return o + f;};
| |
| |
| |
| |
| 简化一:左边简化() | 如果Lambda只需要一个参数时,参数的小括号可以省略Consumer<Integer> consumer=name-> System._out_.println(name); | |
| 简化二:右边简化{}和return | 如果右边方法体只有一条语句,则return和{}均可省略BiFunction<Integer, Float, Float> biFunction = (o, f) -> o + f; | |
1.4 自定义函数式接口和Lambda表达式的使用

1.5 方法引用和构造器引用:Lambda语法糖
概念:
- 方法引用可以看做是Lambda表达式深层次的表达。换句话说,方法引用就是Lambda表达式,也就是函数式接口的一个实例,通过方法的名字来指向一个方法,可以认为是Lambda表达式的一个语法糖。
实现接口的抽象方法(如Consumer.accept接口)的参数列表和返回值类型,必须与方法引用的方法的参数列表和返回值类型保持一致。而在此时方法引用的代码处就可以使用非常简洁的方式进行编写,因为这些省略的参数和返回值都和该Lambda的接口一样,在被调用的时候其也是会被识别到的。
我们看代码的时候只需将方法引用按照方法引用自己的接口进行补全去理解即可(方法引用自己的接口和Lambda接口的返回值和参数是一致的)。
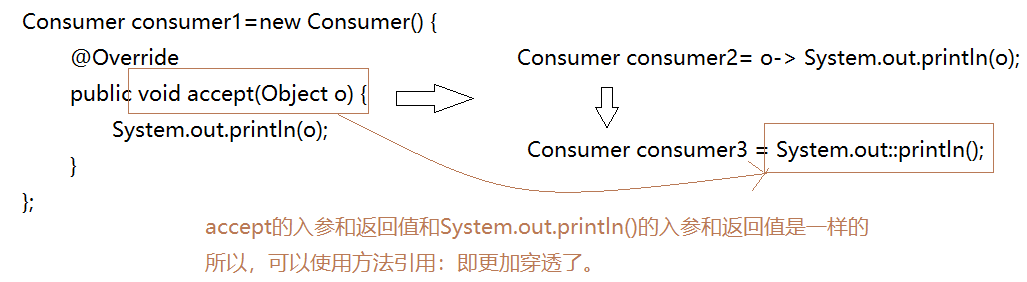
格式:使用操作符
::将类(或对象) 与 方法名分隔开来。- 如下三种主要使用情况:
对象:: 实例方法名类:: 静态方法名类::实例方法名
演变案例
//1.0 匿名对象Consumer consumer1=new Consumer() {@Overridepublic void accept(Object o) {System.out.println(o);}};//2.0 lambda表达式(类型由调用方传入确定)Consumer consumer2= o-> System.out.println(o);//3.0 方法引用Consumer consumer3 = System.out::println();
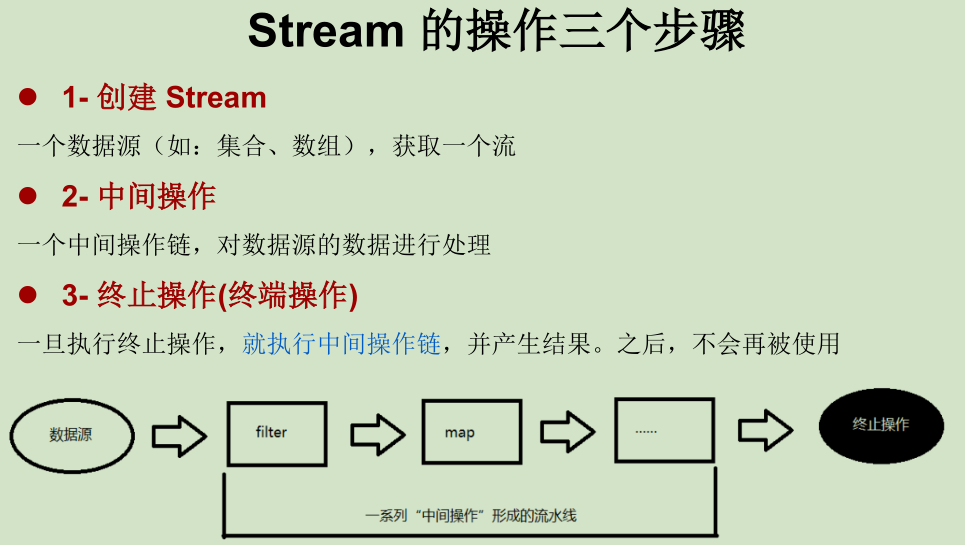
2 StreamAPI
概述
Stream使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对Java 集合运算和表达的高阶抽象。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
Stream 和 Collection 集合的区别:Collection 是一种静态的内存数据结构,而 Stream 是有关计算的。前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
注意点:
- Stream 自己不会存储元素。
- Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
- Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行
创建Stream对象的方式
方式一:通过集合的方法得到(2个方法)
List<Integer> list=new ArrayList<>();list.add(10);list.add(20);list.add(30);//返回一个顺序流Stream<Integer> stream = list.stream();//返回一个顺序流Stream<Integer> stream = list.parallelStream();
方式二:通过数组操作类Arrays.Stream()方法获得
static <T> Stream<T> stream(T[] array):返回一个流对象
int[] arrs={1,2,3};//得到一个int的操作IntStrem流对象(同理可重载得到LongStream或DoubleStream)IntStream stream1 = Arrays.stream(arrs);
方式三:通过Stream.of()得到
public static<T> Stream<T> of(T... values):返回一个流对象
//得到一个Integer的操作流,同理可得到StreamM<Long>或Stream<String>Stream<Integer> integerStream = Stream.of(123, 345, 666);Stream<Long> integerStream = Stream.of(123L, 345L, 666L);
方法四:创建无限流
可以使用静态方法Stream.iterate()和Stream.generate()创建无限流
public static void main(String[] args) {//迭代//public static<T> Stream<T> iterate(final T seed, final,UnaryOperator<T> f)Stream<Integer> stream = Stream.iterate(0, x -> x + 2);stream.limit(10).forEach(System.out::println);//生成//public static<T> Stream<T> generate(Supplier<T> s)Stream<Double> stream1 = Stream.generate(Math::random);stream1.limit(10).forEach(System.out::println);}
Stream的中间操作(删改)
多个 中间操作可以连接起来形成一个 流水线,除非流水线上触发终止操作,否则 中间操作不会执行任何的处理!而在 终止操作时一次性全部处理,称为“惰性求值”。
| 筛选与分片 | 方法 | 描述 |
|---|---|---|
| Stream |
接收 Lambda , 从流中排除某些元素 //案例:查询员工表中薪资大于7000的员工信息 stream.filter(e -> e.getSalary() > 7000) |
|
| Stream |
筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素 | |
| Stream |
截断流,使其元素不超过给定数量 | |
| Stream |
跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 | |
| 映射 | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 //案例:将数组的值都转成大写并输出 List<String> list = Arrays.asList("aa", "bb", "cc", "dd");list.stream().map(str -> str.toUpperCase()).forEach(System.out::println); |
|
? extends Stream<? extends R>> mapper); |
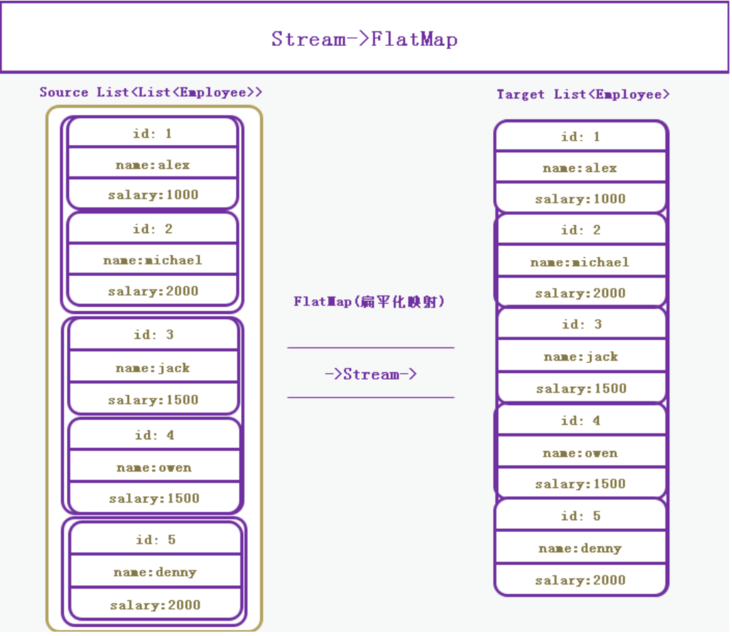
接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流,即打散了```java |
List
|| 排序 | Stream<T> sorted(); | 产生一个新流,其中按自然顺序排序 || | Stream<T> sorted(Comparator<? super T> comparator); | 产生一个新流,其中按比较器顺序排序<br />//案例```javaemployees.stream().sorted( (e1,e2) -> {int ageValue = Integer.compare(e1.getAge(),e2.getAge());if(ageValue != 0){return ageValue;}else{return -Double.compare(e1.getSalary(),e2.getSalary());}})
|
Stream的终止操作(查)
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。流进行了终止操作后,即不能再次使用。
| 匹配与查找 | 方法 | 描述 | 特别强调 |
|---|---|---|---|
| boolean allMatch(Predicate<? super T> predicate); | 检查是否匹配所有元素 //案例:是否所有的员工的年龄都大于18 boolean allMatch = employees.stream().allMatch(e -> e.getAge() > 18); |
||
| boolean anyMatch(Predicate<? super T> predicate); | 检查是否至少匹配一个元素 //案例:是否存在员工的工资大于 10000 boolean anyMatch = employees.stream().anyMatch(e -> e.getSalary() > 10000); |
||
| boolean noneMatch(Predicate<? super T> predicate); | 检查是否没有匹配所有元素 | ||
| Optional |
返回第一个元素 | ||
| Optional |
返回当前流中的任意元素 | ||
| long count(); | 返回流中元素总数 | ||
| Optional |
返回流中最大值 | ||
| Optional |
返回流中最小值 | ||
| void forEach(Consumer<? super T> action); | 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。相反,Stream API 使用内部迭代——它帮你把迭代做了) | ||
| 归约 | T reduce(T identity, BinaryOperator |
可以将流中元素反复结合起来,得到一个值。返回 T 案例:```java |
Integer[] arrs = {1, 3, 5, 7, 9, 11};
Stream
因 Google用它来进行网络搜索而出名。 |
| | Optional
另外, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例 |
扩展:强大的Collectors
Stream 的核心在于Collectors,即对处理后的数据进行收集。Collectors 提供了非常多且强大的API,可以将最终的数据收集成List、Set、Map,甚至是更复杂的结构(这三者的嵌套组合),Collectors 提供了很多API,这里可以大致分为三类:
参考文章:StreamAPI之Collectors收集器
| 方法 | 用法 | 案例 | |
|---|---|---|---|
| 数据收集 | List |
把流中元素收集到List | List |
| Set |
把流中元素收集到Set | Set |
|
| Collection |
把流中元素收集到创建的集合 | Collection |
|
| Collection toMap/toConcurrentMap(fun key,fun value) |
收集成Map | ||
| 聚合归约 | Long counting | 计算流中元素的个数 | long count = list.stream().collect(Collectors.counting()); |
| Integer summingInt | 对流中元素的整数属性求和 | int total=list.stream().collect(Collectors.summingInt(Employee::getSalary)); | |
| Double averagingInt | 计算流中元素Integer属性的平均值 | double avg = list.stream().collect(Collectors.averagingInt(Employee::getSalary)); | |
| IntSummaryStatistics ssummarizingInt | 收集流中Integer属性的统计值。如:平均值 | int SummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary)); | |
| String joining | 连接流中每个字符串 | String str= list.stream().map(Employee::getName).collect(Collectors.joining()); | |
| Optional |
根据比较器选择最大值 | Optional |
|
| Optional |
根据比较器选择最小值 | Optional |
|
| reducing 返回值:归约产生的类型 |
从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值 | int total=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum)); | |
| 前后处理 | Map |
根据某属性值对流分组,属性为K,结果为V | Map |
| Map |
根据某属性值对流分组,属性为K,结果为V | 多线程情况下操作同一份数据时候使用 | |
| partitioningBy Map |
根据true或false进行分区 | Map |
|
| collectingAndThen 返回值:转换函数返回的类型 |
包裹另一个收集器,对其结果转换函数 | int how= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size)); |
API详解
flatMap方法

若有收获,就点个赞吧
0 人点赞
