网卡
网卡是工作在链路层的网络组件,是局域网中连接计算机和传输介质的接口,不仅能实现与局域网传输介质之间的物理连接和电信号匹配,还涉及帧的发送与接收、帧的封装与拆封、介质访问控制、数据的编码与解码以及数据缓存的功能等。
网卡上面装有处理器和存储器(包括RAM和ROM)。网卡和局域网之间的通信是通过电缆或双绞线以串行传输方式进行的。而网卡和计算机之间的通信则是通过计算机主板上的I/O总线以并行传输方式进行。因此,网卡的一个重要功能就是要进行串行/并行转换。由于网络上的数据率和计算机总线上的数据率并不相同,因此在网卡中必须装有对数据进行缓存的存储芯片。
在安装网卡时必须将管理网卡的设备驱动程序安装在计算机的操作系统中。这个驱动程序以后就会告诉网卡,应当从存储器的什么位置上将局域网传送过来的数据块存储下来。网卡还要能够实现以太网协议。
网卡并不是独立的自治单元,因为网卡本身不带电源而是必须使用所插入的计算机的电源,并受该计算机的控制。因此网卡可看成为一个半自治的单元。当网卡收到一个有差错的帧时,它就将这个帧丢弃而不必通知它所插入的计算机。当网卡收到一个正确的帧时,它就使用中断来通知该计算机并交付给协议栈中的网络层。当计算机要发送一个IP数据包时,它就由协议栈向下交给网卡组装成帧后发送到局域网。
eth
eth0,eth1,eth2……代表网卡一,网卡二,网卡三……
lo代表127.0.0.1,即localhost
参考:
Linux命令:ifconfig
功能说明:显示或设置网络设备
语 法:ifconfig [网络设备][down up -allmulti -arp -promisc][add<地址>][del<地址>][<硬件地址>] [media<网络媒介类型>][mem_start<内存地址>][metric<数目>][mtu<字节>][netmask<子网掩码>][tunnel<地址>][-broadcast<地址>] [-pointopoint<地址>]
补充说明:ifconfig可设置网络设备的状态,或是显示目前的设置。
配置网卡的IP地址
ifconfig eth0 192.168.0.1 netmask 255.255.255.0
在eth0上配置上192.168.0.1 的IP地址及24位掩码。若想再在eth0上在配置一个192.168.1.1/24 的IP地址怎么办?用下面的命令
ifconfig eth0:0 192.168.1.1 netmask 255.255.255.0
这时再用ifconifg命令查看,就可以看到两个网卡的信息了,分别为:eth0和eth0:0.若还想再增加IP,那网卡的命名就接着是:eth0:1、eth0:2……
将网卡禁用
ifconfig eth0 down
将网卡启用
ifconfig eth0 up
tap/tun
+----------------------------------------------------------------+| || +--------------------+ +--------------------+ || | User Application A | | User Application B |<-----+ || +--------------------+ +--------------------+ | || | 1 | 5 | ||...............|......................|...................|.....|| ↓ ↓ | || +----------+ +----------+ | || | socket A | | socket B | | || +----------+ +----------+ | || | 2 | 6 | ||.................|.................|......................|.....|| ↓ ↓ | || +------------------------+ 4 | || | Newwork Protocol Stack | | || +------------------------+ | || | 7 | 3 | ||................|...................|.....................|.....|| ↓ ↓ | || +----------------+ +----------------+ | || | eth0 | | tun0 | | || +----------------+ +----------------+ | || 10.32.0.11 | | 192.168.3.11 | || | 8 +---------------------+ || | |+----------------|-----------------------------------------------+↓Physical Network
上图中有两个应用程序A和B,都在用户层,而其它的socket、协议栈(Newwork Protocol Stack)和网络设备(eth0和tun0)部分都在内核层,其实socket是协议栈的一部分,这里分开来的目的是为了看的更直观。
tun0是一个Tun/Tap虚拟设备,从上图中可以看出它和物理设备eth0的差别,它们的一端虽然都连着协议栈,但另一端不一样,eth0的另一端是物理网络,这个物理网络可能就是一个交换机,而tun0的另一端是一个用户层的程序,协议栈发给tun0的数据包能被这个应用程序读取到,并且应用程序能直接向tun0写数据。
这里假设eth0配置的IP是10.32.0.11,而tun0配置的IP是192.168.3.11.
这里列举的是一个典型的tun/tap设备的应用场景,发到192.168.3.0/24网络的数据通过程序B这个隧道,利用10.32.0.11发到远端网络的10.33.0.1,再由10.33.0.1转发给相应的设备,从而实现VPN。
下面来看看数据包的流程:
- 应用程序A是一个普通的程序,通过socket A发送了一个数据包,假设这个数据包的目的IP地址是192.168.3.1
- socket将这个数据包丢给协议栈
- 协议栈根据数据包的目的IP地址,匹配本地路由规则,知道这个数据包应该由tun0出去,于是将数据包交给tun0
- tun0收到数据包之后,发现另一端被进程B打开了,于是将数据包丢给了进程B
- 进程B收到数据包之后,做一些跟业务相关的处理,然后构造一个新的数据包,将原来的数据包嵌入在新的数据包中,最后通过socket B将数据包转发出去,这时候新数据包的源地址变成了eth0的地址,而目的IP地址变成了一个其它的地址,比如是10.33.0.1.
- socket B将数据包丢给协议栈
- 协议栈根据本地路由,发现这个数据包应该要通过eth0发送出去,于是将数据包交给eth0
- eth0通过物理网络将数据包发送出去
从上面的流程中可以看出,数据包选择走哪个网络设备完全由路由表控制,所以如果我们想让某些网络流量走应用程序B的转发流程,就需要配置路由表让这部分数据走tun0。
从上面介绍过的流程可以看出来,tun/tap设备的用处是将协议栈中的部分数据包转发给用户空间的应用程序,给用户空间的程序一个处理数据包的机会。于是比较常用的数据压缩,加密等功能就可以在应用程序B里面做进去,tun/tap设备最常用的场景是VPN,包括tunnel以及应用层的IPSec等。
用户层程序通过tun设备只能读写IP数据包,而通过tap设备能读写链路层数据包,类似于普通socket和raw socket的差别一样,处理数据包的格式不一样。
veth
Linux内核中有一个网络设备管理层,处于网络设备驱动和协议栈之间,负责衔接它们之间的数据交互。驱动不需要了解协议栈的细节,协议栈也不需要了解设备驱动的细节。
对于一个网络设备来说,就像一个管道(pipe)一样,有两端,从其中任意一端收到的数据将从另一端发送出去。
比如一个物理网卡eth0,它的两端分别是内核协议栈(通过内核网络设备管理模块间接的通信)和外面的物理网络,从物理网络收到的数据,会转发给内核协议栈,而应用程序从协议栈发过来的数据将会通过物理网络发送出去。
那么对于一个虚拟网络设备呢?首先它也归内核的网络设备管理子系统管理,对于Linux内核网络设备管理模块来说,虚拟设备和物理设备没有区别,都是网络设备,都能配置IP,从网络设备来的数据,都会转发给协议栈,协议栈过来的数据,也会交由网络设备发送出去,至于是怎么发送出去的,发到哪里去,那是设备驱动的事情,跟Linux内核就没关系了,所以说虚拟网络设备的一端也是协议栈,而另一端是什么取决于虚拟网络设备的驱动实现。
- veth和其它的网络设备都一样,一端连接的是内核协议栈。
- veth设备是成对出现的,另一端两个设备彼此相连
- 一个设备收到协议栈的数据发送请求后,会将数据发送到另一个设备上去。
先通过ip link命令添加veth0和veth1,然后配置veth0和veth1的IP,并将两个设备都启动起来
dev@debian:~$ sudo ip link add veth0 type veth peer name veth1dev@debian:~$ sudo ip addr add 192.168.2.11/24 dev veth0dev@debian:~$ sudo ip addr add 192.168.2.1/24 dev veth1dev@debian:~$ sudo ip link set veth0 updev@debian:~$ sudo ip link set veth1 up
下面这张关系图很清楚的说明了veth设备的特点:
+----------------------------------------------------------------+| || +------------------------------------------------+ || | Newwork Protocol Stack | || +------------------------------------------------+ || ↑ ↑ ↑ ||..............|...............|...............|.................|| ↓ ↓ ↓ || +----------+ +-----------+ +-----------+ || | eth0 | | veth0 | | veth1 | || +----------+ +-----------+ +-----------+ ||192.168.1.11 ↑ ↑ ↑ || | +---------------+ || | 192.168.2.11 192.168.2.1 |+--------------|-------------------------------------------------+↓Physical Network
上图中,我们给物理网卡eth0配置的IP为192.168.1.11, 而veth0和veth1的IP分别是192.168.2.11和192.168.2.1。
从veth0设备出去的数据包,会转发到veth1上,如果目的地址是veth1的IP的话,就能被协议栈处理,否则连ARP那关都过不了,IP forward啥的都用不上,所以不借助其它虚拟设备的话,这样的数据包只能在本地协议栈里面打转转,没法走到eth0上去,即没法发送到外面的网络中去。
bridge
首先,bridge是一个虚拟网络设备,所以具有网络设备的特征,可以配置IP、MAC地址等;其次,bridge是一个虚拟交换机,和物理交换机有类似的功能。
对于普通的网络设备来说,只有两端,从一端进来的数据会从另一端出去,如物理网卡从外面网络中收到的数据会转发给内核协议栈,而从协议栈过来的数据会转发到外面的物理网络中。
而bridge不同,bridge有多个端口,数据可以从任何端口进来,进来之后从哪个口出去和物理交换机的原理差不多,要看mac地址。
当刚创建一个bridge时,它是一个独立的网络设备,只有一个端口连着协议栈,其它的端口啥都没连,这样的bridge没有任何实际功能,如下图所示:
dev@debian:~$ sudo ip link add name br0 type bridgedev@debian:~$ sudo ip link set br0 up
这里假设eth0是我们的物理网卡,IP地址是192.168.3.21,网关是192.168.3.1
+----------------------------------------------------------------+| || +------------------------------------------------+ || | Newwork Protocol Stack | || +------------------------------------------------+ || ↑ ↑ ||..............|................................|................|| ↓ ↓ || +----------+ +------------+ || | eth0 | | br0 | || +----------+ +------------+ || 192.168.3.21 ↑ || | || | |+--------------|-------------------------------------------------+↓Physical Network
创建一对veth设备,并配置上IP
dev@debian:~$ sudo ip link add veth0 type veth peer name veth1dev@debian:~$ sudo ip addr add 192.168.3.101/24 dev veth0dev@debian:~$ sudo ip addr add 192.168.3.102/24 dev veth1dev@debian:~$ sudo ip link set veth0 updev@debian:~$ sudo ip link set veth1 up
将veth0连上br0
dev@debian:~$ sudo ip link set dev veth0 master br0#通过bridge link命令可以看到br0上连接了哪些设备dev@debian:~$ sudo bridge link6: veth0 state UP : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
这时候,网络就变成了这个样子:
+----------------------------------------------------------------+| || +------------------------------------------------+ || | Newwork Protocol Stack | || +------------------------------------------------+ || ↑ ↑ | ↑ ||............|............|..............|............|..........|| ↓ ↓ ↓ ↓ || +------+ +--------+ +-------+ +-------+ || | .3.21| | | | .3.101| | .3.102| || +------+ +--------+ +-------+ +-------+ || | eth0 | | br0 |<--->| veth0 | | veth1 | || +------+ +--------+ +-------+ +-------+ || ↑ ↑ ↑ || | | | || | +------------+ || | |+------------|---------------------------------------------------+↓Physical Network
br0和veth0相连之后,发生了几个变化:
- br0和veth0之间连接起来了,并且是双向的通道
- 协议栈和veth0之间变成了单通道,协议栈能发数据给veth0,但veth0从外面收到的数据不会转发给协议栈
- br0的mac地址变成了veth0的mac地址
相当于bridge在veth0和协议栈之间插了一脚,在veth0上面做了点小动作,将veth0本来要转发给协议栈的数据给拦截了,全部转发给bridge了,同时bridge也可以向veth0发数据。
通过veth0 ping veth1失败:去和回来的流程都没有问题,问题就出在veth0收到应答包后没有给协议栈,而是给了br0,于是协议栈得不到veth1的mac地址,从而通信失败。
通过上面的分析可以看出,给veth0配置IP没有意义,因为就算协议栈传数据包给veth0,应答包也回不来。这里我们就将veth0的IP让给bridge。
dev@debian:~$ sudo ip addr del 192.168.3.101/24 dev veth0dev@debian:~$ sudo ip addr add 192.168.3.101/24 dev br0
于是网络变成了这样子:
+----------------------------------------------------------------+| || +------------------------------------------------+ || | Newwork Protocol Stack | || +------------------------------------------------+ || ↑ ↑ ↑ ||............|............|...........................|..........|| ↓ ↓ ↓ || +------+ +--------+ +-------+ +-------+ || | .3.21| | .3.101 | | | | .3.102| || +------+ +--------+ +-------+ +-------+ || | eth0 | | br0 |<--->| veth0 | | veth1 | || +------+ +--------+ +-------+ +-------+ || ↑ ↑ ↑ || | | | || | +------------+ || | |+------------|---------------------------------------------------+↓Physical Network
其实veth0和协议栈之间还是有联系的,但由于veth0没有配置IP,所以协议栈在路由的时候不会将数据包发给veth0,就算强制要求数据包通过veth0发送出去,但由于veth0从另一端收到的数据包只会给br0,所以协议栈还是没法收到相应的arp应答包,导致通信失败。
这里为了表达更直观,将协议栈和veth0之间的联系去掉了,veth0相当于一根网线。
再通过br0 ping一下veth1,结果成功;但ping网关还是失败,因为这个bridge上只有两个网络设备,分别是192.168.3.101和192.168.3.102,br0不知道192.168.3.1在哪。
将物理网卡添加到bridge(将eth0添加到br0上):
dev@debian:~$ sudo ip link set dev eth0 master br0dev@debian:~$ sudo bridge link2: eth0 state UP : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 46: veth0 state UP : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
br0根本不区分接入进来的是物理设备还是虚拟设备,对它来说都一样的,都是网络设备,所以当eth0加入br0之后,落得和上面veth0一样的下场,从外面网络收到的数据包将无条件的转发给br0,自己变成了一根网线。
这时通过eth0来ping网关失败,但由于br0通过eth0这根网线连上了外面的物理交换机,所以连在br0上的设备都能ping通网关,这里连上的设备就是veth1和br0自己,veth1是通过veth0这根网线连上去的,而br0可以理解为自己有一块自带的网卡。
由于eth0已经变成了和网线差不多的功能,所以在eth0上配置IP已经没有什么意义了,并且还会影响协议栈的路由选择,比如如果上面ping的时候不指定网卡的话,协议栈有可能优先选择eth0,导致ping不通,所以这里需要将eth0上的IP去掉。
经过上面一系列的操作后,网络变成了这个样子:
+----------------------------------------------------------------+| || +------------------------------------------------+ || | Newwork Protocol Stack | || +------------------------------------------------+ || ↑ ↑ ||.........................|...........................|..........|| ↓ ↓ || +------+ +--------+ +-------+ +-------+ || | | | .3.101 | | | | .3.102| || +------+ +--------+ +-------+ +-------+ || | eth0 |<--->| br0 |<--->| veth0 | | veth1 | || +------+ +--------+ +-------+ +-------+ || ↑ ↑ ↑ || | | | || | +------------+ || | |+------------|---------------------------------------------------+↓Physical Network
在我们常见的物理交换机中,有可以配置IP和不能配置IP两种,不能配置IP的交换机一般通过com口连上去做配置(更简单的交换机连com口的没有,不支持任何配置),而能配置IP的交换机可以在配置好IP之后,通过该IP远程连接上去做配置,从而更方便。
bridge就属于后一种交换机,自带虚拟网卡,可以配置IP,该虚拟网卡一端连在bridge上,另一端跟协议栈相连。和物理交换机一样,bridge的工作不依赖于该虚拟网卡,但bridge工作不代表机器能连上网,要看组网方式。
docker
由于容器运行在自己单独的network namespace里面,所以都有自己单独的协议栈,情况和上面的虚拟机差不多,但它采用了另一种方式来和外界通信:
+----------------------------------------------------------------+-----------------------------------------+-----------------------------------------+| Host | Container 1 | Container 2 || | | || +------------------------------------------------+ | +-------------------------+ | +-------------------------+ || | Newwork Protocol Stack | | | Newwork Protocol Stack | | | Newwork Protocol Stack | || +------------------------------------------------+ | +-------------------------+ | +-------------------------+ || ↑ ↑ | ↑ | ↑ ||............|.............|.....................................|...................|.....................|....................|....................|| ↓ ↓ | ↓ | ↓ || +------+ +--------+ | +-------+ | +-------+ || |.3.101| | .9.1 | | | .9.2 | | | .9.3 | || +------+ +--------+ +-------+ | +-------+ | +-------+ || | eth0 | | br0 |<--->| veth | | | eth0 | | | eth0 | || +------+ +--------+ +-------+ | +-------+ | +-------+ || ↑ ↑ ↑ | ↑ | ↑ || | | +-------------------------------------------+ | | || | ↓ | | | || | +-------+ | | | || | | veth | | | | || | +-------+ | | | || | ↑ | | | || | +-------------------------------------------------------------------------------|--------------------+ || | | | || | | | || | | | |+------------|---------------------------------------------------+-----------------------------------------+-----------------------------------------+↓Physical Network (192.168.3.0/24)
容器中配置网关为.9.1,发出去的数据包先到达br0,然后交给host机器的协议栈,由于目的IP是外网IP,且host机器开启了IP forward功能,于是数据包会通过eth0发送出去,由于.9.1是内网IP,所以一般发出去之前会先做NAT转换(NAT转换和IP forward功能都需要自己配置)。由于要经过host机器的协议栈,并且还要做NAT转换,所以性能没有虚拟机的方案好,优点是容器处于内网中,安全性相对要高点。
容器间基于Veth实现网络通信

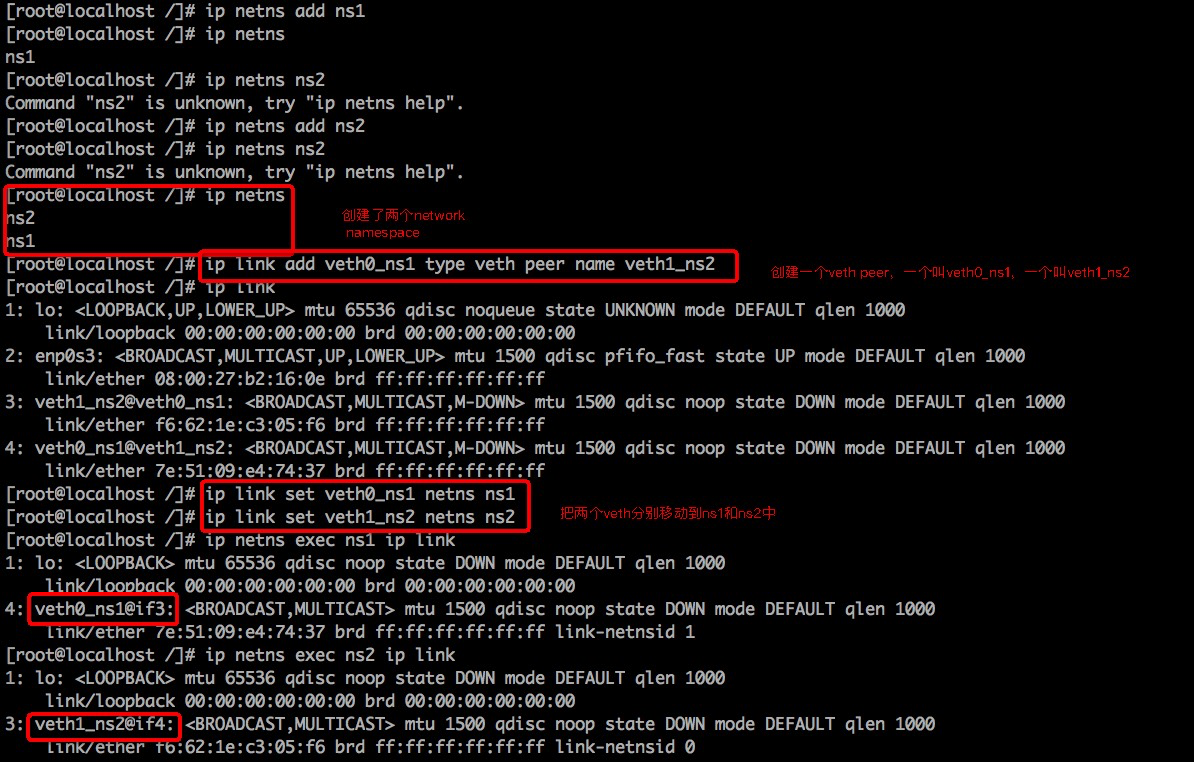
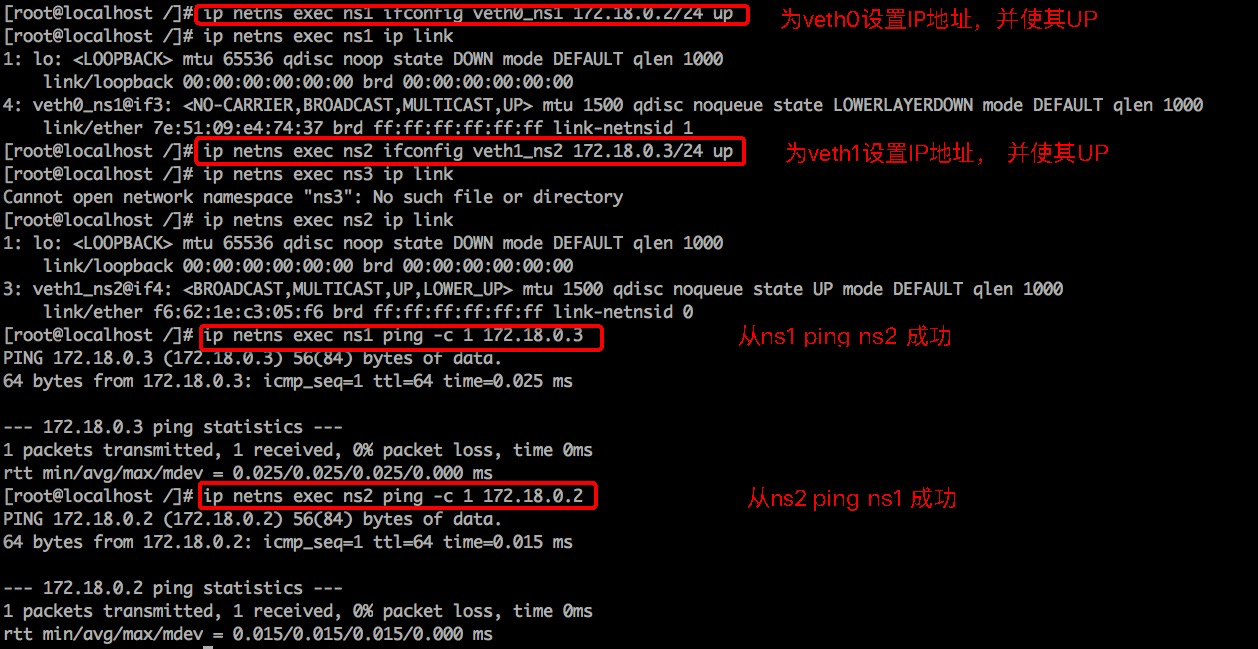
容器间/容器与宿主机/容器与外部网络基于Veth+Bridge实现网络通信
刚创建一个bridge时,它是一个独立的网络设备,只有一个端口连着协议栈,其它的端口啥都没连,设置(3)就可以使bridge收到来自容器的网络请求。
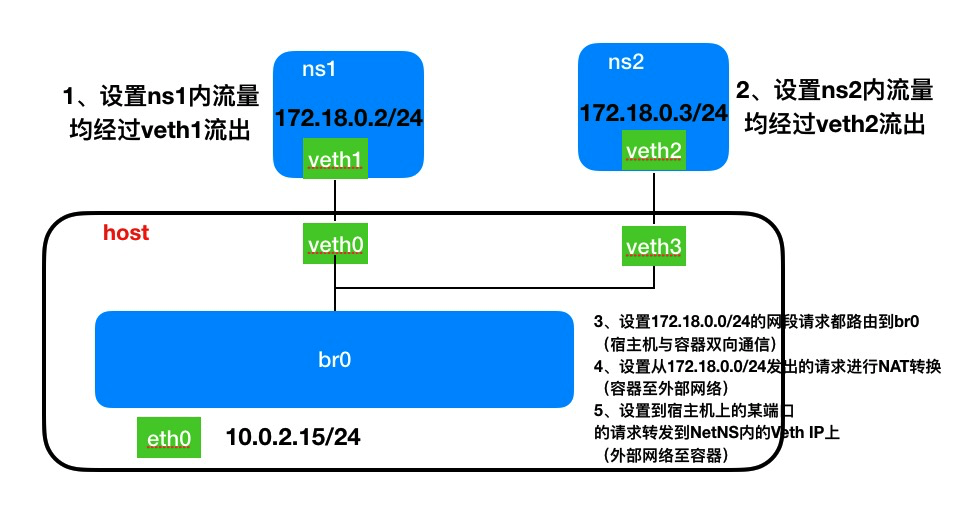
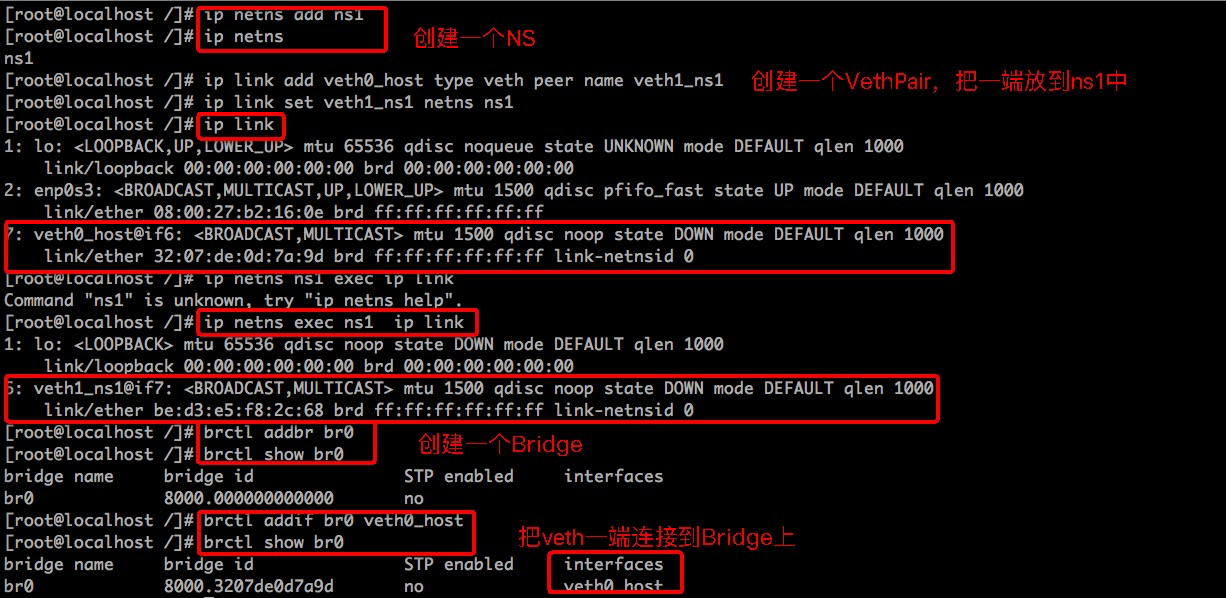
容器间通信基于Bridge实现。
配置容器与宿主机间连通
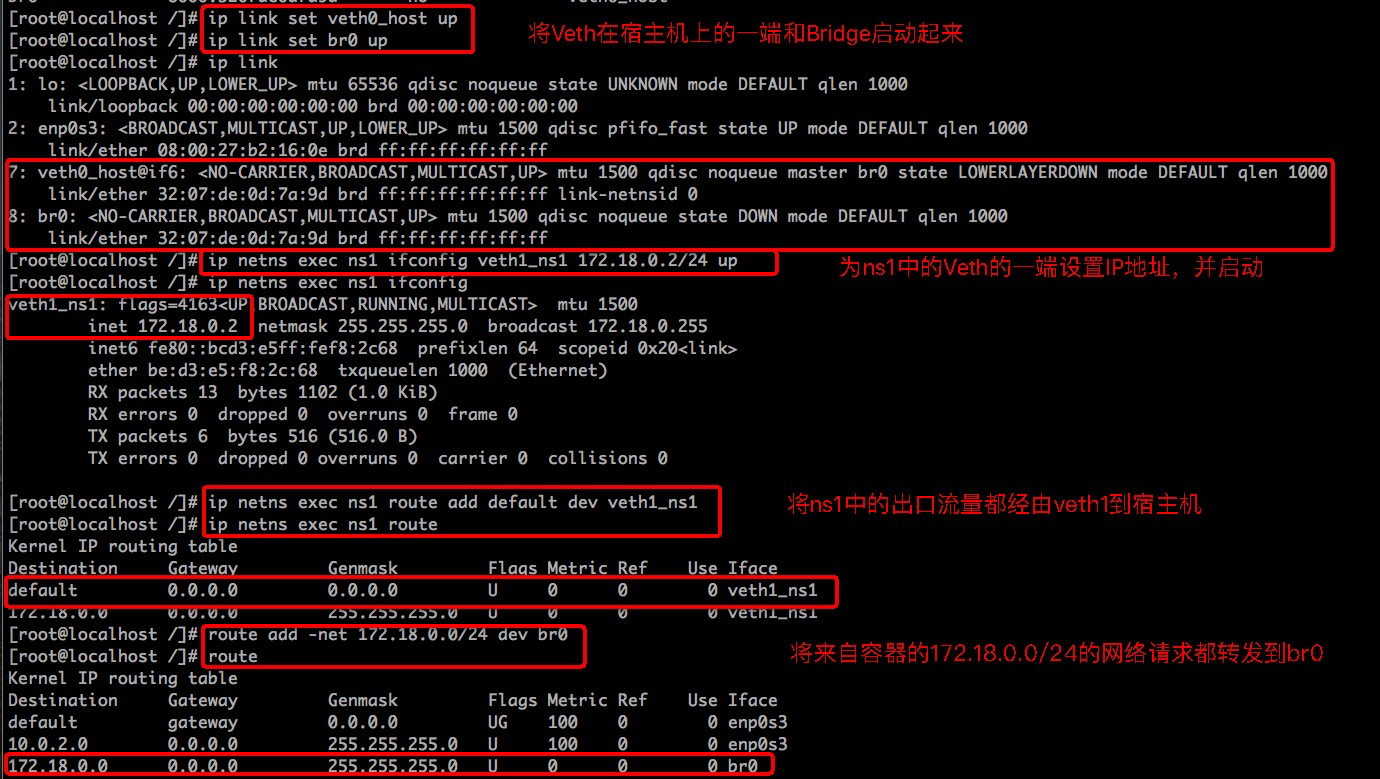
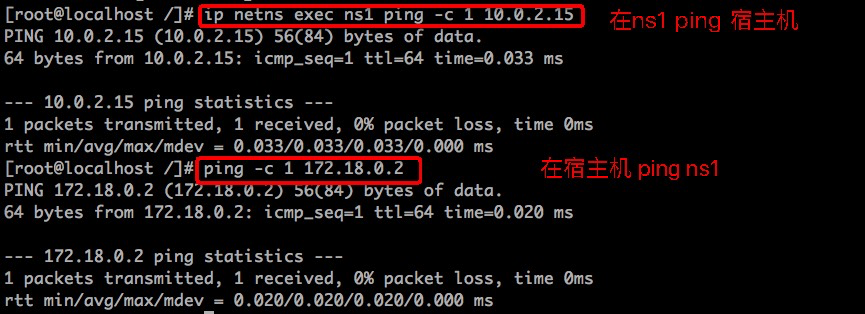
下面开始测试容器与宿主机间的连通性:
宿主机的网卡地址为10.0.2.15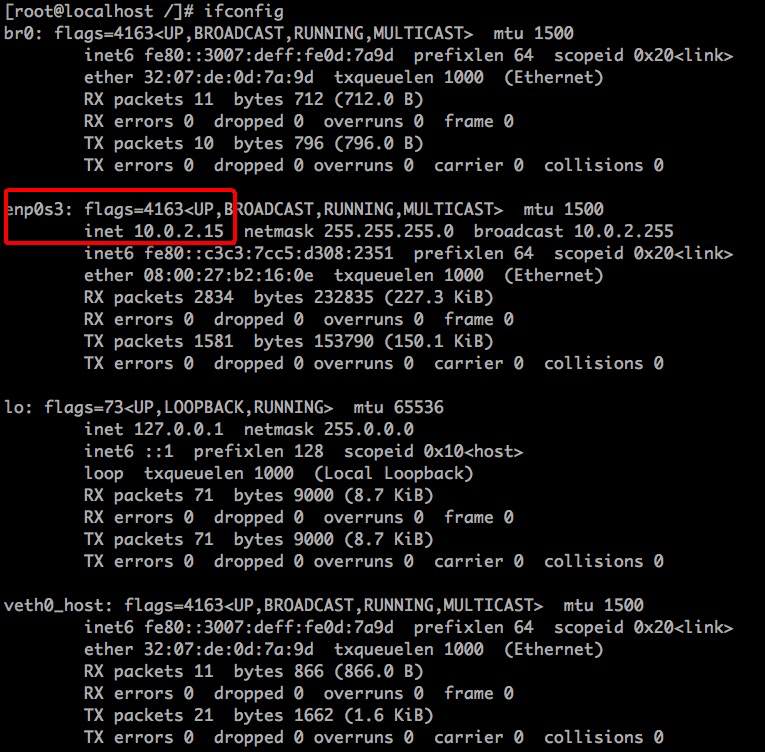
配置容器与外部网络连通
开启宿主机的ip forward
所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将包发往本机另一网卡,该网卡根据路由表继续发送数据包。这通常就是路由器所要实现的功能。
bridge收到来自容器的请求时,根据数据包的目的IP(比如目的IP为公网IP,则匹配到默认路由default,默认路由到eth0),将数据包转发到eth0,bridge和eth0不需要直连。
vi /usr/lib/sysctl.d/50-default.conf #命令(编辑配置文件)net.ipv4.ip_forward=1 # 设置转发sysctl –p
安装iptables
CentOS7默认的防火墙不是iptables,而是firewalle.
#先检查是否安装了iptablesservice iptables status#安装iptablesyum install -y iptables#安装iptables-servicesyum install -y iptables-services#停止firewalld服务systemctl stop firewalld#禁用firewalld服务systemctl mask firewalld#启用iptablessystemctl enable iptables.servicesystemctl start iptables.servicesystemctl status iptables.service
#查看iptables现有规则iptables -L -n#service iptables save# 注意删掉REJCECT规则,否则在ping的时候会出现Destination Host Prohibited# 比如说刚装好之后可能是这样的,注意把INPUT的第5条和FORWARD的第1条删掉[root@localhost mycontainer]# iptables -L -n --line-numberChain INPUT (policy ACCEPT)num target prot opt source destination1 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED2 ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/03 ACCEPT all -- 0.0.0.0/0 0.0.0.0/04 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:225 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibitedChain FORWARD (policy ACCEPT)num target prot opt source destination1 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibitedChain OUTPUT (policy ACCEPT)num target prot opt source destination
配置MASQUERADE(中文-化妆、伪装)
可以将来自某网段的网络请求的源地址转换成一个网络设备的地址。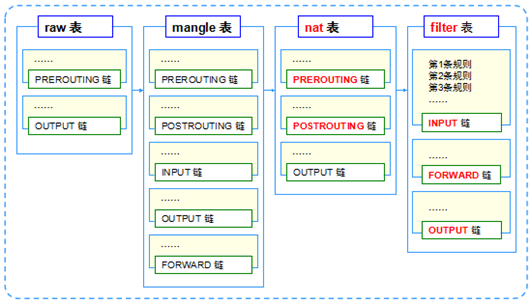
- tables
- iptables提供了一系列的”表”(tables),每个表由若干”链”(chains)组成,而每条链中可以有一条或数条规则(rule)组 成。并且系统缺省的表是”filter”。但是在使用NAT的时候,我们所使用的表不再是”filter”,而是”nat”表,所以我们必须使用”-t nat”选项来显式地指明这一点。因为系统缺省的表是”filter”,所以在使用filter功能时,我们没有必要显式的指明”-t filter”。
- 4个表:filter,nat,mangle,raw,默认表是filter(没有指定表的时候就是filter表)。
- 表的处理优先级:raw>mangle>nat>filter。
- chain
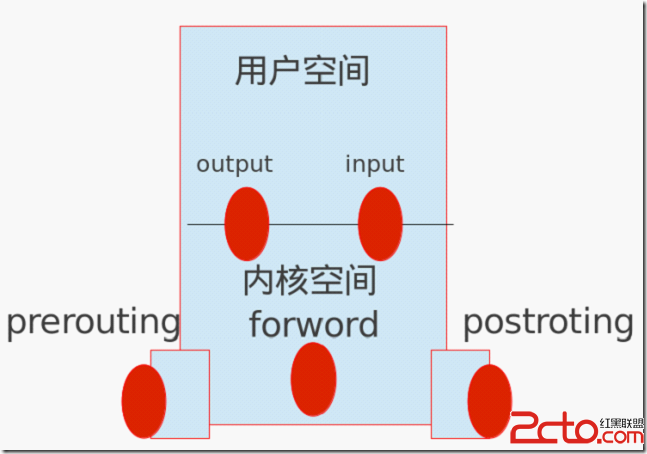
- PREROUTING 目的DNAT规则
- 把从外来的访问重定向到其他的机子上,比如内部SERVER,或者DMZ。
- 因为路由时只检查数据包的目的ip地址,所以必须在路由之前就进行目的PREROUTING DNAT;
- 系统先PREROUTING DNAT转换——>再过滤(FORWARD)——>最后路由。
- 路由和过滤(FORWARD)中match 的目的地址,都是针对被PREROUTING DNAT之后的。
- POSTROUTING 源SNAT规则
- 在路由以后在执行该链中的规则。
- 系统先路由——>再过滤(FORWARD)——>最后才进行POSTROUTING SNAT地址转换
- 其match 源地址是转换前的。
- OUTPUT 定义对本地产生的数据包的目的NAT规则
- PREROUTING 目的DNAT规则
MASQUERADE:用于外网口public地址是DHCP动态获取的(如ADSL)。
iptables -t nat -A POSTROUTING -s 172.18.0.0/24 -o 网络设备名 -j MASQUERADE# 在我们不清楚有哪些对外连通的网络设备时,我们会选择 ! -o 网桥名# 这样会避开网桥的IP作为新的SOURCE IPservice iptables saveiptables -t nat -vnL POSTROUTING --line-numberiptables -t nat -F POSTROUTING # 删除所有规则iptables -t nat -D CHAIN 行号 #删除一条规则
[]()[]()
配置DNAT
将destination对宿主机9080端口的请求转发到NetNS的IP:9080上。
iptables -t nat -A PREROUTING -p tcp -m tcp --dport 9080 -j DNAT --to-destination 172.18.0.2:80
Docker网络实现
func (daemon Daemon) containerStart(container container.Container, checkpoint string, checkpointDir string, resetRestartManager bool) (err error)
1、initializeNetworking -> allocateNetwork , WriteHostConfig -> connectToNetwork
connectToNetwork:
- buildCreateEndpointOptions
- CreateEndpoint -> driver.CreateEndpoint
- buildSandboxOptions(新的netns)
- NewSandbox -> setupResolutionFiles -> buildHostsFile, setupDNS 它会生成一个hosts文件,路径为sb.config.hostsPath = defaultPrefix + “/“ + sb.id + “/hosts”
- endpoint.Join(sandbox)
2、createSpec:转为spec 这里会把之前创建的netns的Path设置进去,后面会继续使用这个namespace。
3、containerd!
err = daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)
if err != nil {
return translateContainerdStartErr(container.Path, container.SetExitCode, err)
}
pid, err := daemon.containerd.Start(context.Background(), container.ID, checkpointDir,
container.StreamConfig.Stdin() != nil || container.Config.Tty,
container.InitializeStdio)
if err != nil {
if err := daemon.containerd.Delete(context.Background(), container.ID); err != nil {
logrus.WithError(err).WithField(“container”, container.ID).
Error(“failed to delete failed start container”)
}
return translateContainerdStartErr(container.Path, container.SetExitCode, err)
}
3.在Docker daemon成功启动后,我们就可以使用Docker Client进行容器创建了。容器的网络栈会在容器真正启动之前完成创建。在为容器创建网络栈的时候,首先会取得daemon中的netController,其值就是libnetwork中的向外提供的一组接口,即NetworkController。
接下来,Docker会调用BuildCreateEndpointOptions()来创建此容器中endpoint的配置信息。然后再调用CreateEndpoint()使用上面配置好的信息创建对应的endpoint。在bridge模式中,libnetwork创建的设备是veth pair。Libnetwork中调用netlink.LinkAdd(veth)进行了veth pair的创建,得到的一个veth设备是为了host所准备的,另一个是为了sandbox所准备的。将host端的veth加入到网桥(docker0)中。然后调用netlink.LinkSetUp(host),启动主机端的veth。最后对endpoint中的端口映射进行配置。
从本质上来讲,这一部分所做的工作就是调用linux系统调用,进行veth pair的创建。然后将veth pair的一端,作为docker0网桥的一个接口加入到这个网桥中。
4.创建SandboxOptions,然后调用controller.NewSandbox()来创建属于此container的新的sandbox。在接收到Docker创建sandbox的请求后,libnetwork会使用系统调用为容器创建一个新的netns,并将这个netns的路径返回给Docker。
5.调用ep.Join(sb)将endpoint加入到容器对应的sandbox中。先将endpoint加入到容器对应的sandbox中,然后对endpoint的ip信息和gateway等信息进行配置。
6.Docker在调用libcontainer来启动容器之后,libcontainer会在容器中的init进程初始化容器坏境的时候,将容器中的所有进程都加入到4中得到的netns中。这样容器就拥有了属于自己独立的网络栈,进而完成了网络部分的创建和配置工作。
疑问:
1、sandbox中创建的新的netns如何给到runc
2、sandbox对应的hosts文件如何给到runc

若有收获,就点个赞吧
0 人点赞
