为什么需要Go
1、goroutine等协程 并发编程范式(CSP并发模型),语言层面支持并发
2、足够简洁高效(函数可以有多个返回值,延时defer等)
3、统一编程风格
4、静态编译型语言+较快的编译速度(较C/C++而言)
5、GC
6、系统向?拥有一些系统库
工程结构
$GOPATH是go代码的根目录。下面包含三个子目录:bin、src、pkg。
- src是源码包,比如一个github项目github.com/gorilla/mux,那么使用go get后会下载到$GOPATH/src/github.com/gorilla/mux下面。
- pkg用于存放go install命令安装后的代码包的归档文件,文件后缀为.a。
- bin用于存放go install命令安装后的可执行文件。可执行文件名与源码文件(main.go)的上层目录名相同。
除了把$GOPATH加到环境变量外,还需要把$GOPATH/bin加到PATH环境变量中。
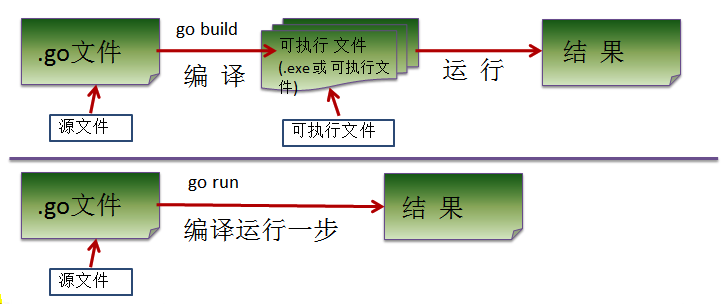
Go源码文件分为三类:命令源码文件、库源码文件和测试源码文件。
1、命令源码文件:如果一个源码文件处于main包,且有一个func main()函数的定义,则为命令源码文件。
- 可以直接用 go run 来运行
- 命令源码文件通常会单独放在一个代码包中。当代码包中尤其恩仅有一个命令源码文件时,在文件所在目录执行go build 命令,即可在该目录下生成一个与目录同名的可执行文件;使用go install 命令,则可在$GOPATH/bin下生产相应的可执行文件(前提是$GOPATH只对应一个目录)。
2、库源码文件:通常库源码文件的包名与目录名一致,且不包含func main()函数定义。
- 安装库源码文件go install 时会在$GOPATH/pkg下生成归档文件,并且会声称在对应的环境相关目录下(如$GOPATH/pkg/darwin_amd64代表mac os)
3、测试源码文件:可以使用go test来运行当前代码包下的所有测试源码文件。
- Go源文件以 “go” 为扩展名。
- Go应用程序的执行入口是main()函数。这个是和其它编程语言(比如java/c)
- Go语言严格区分大小写。
- Go方法由一条条语句构成,每个语句后不需要分号
- Go每行只能写一条语句
- Go定义的变量或import的包没有用到,编译会报错
- Go支持单行注释和多行注释
跨平台
Go的跨平台与Java不同。Java是相同一套代码,编译出来的字节码也是相同的,只是在不同OS上有不同的JVM,不同的JVM来运行相同的字节码,并保证它们运行效果一致;
而Go也是相同一套代码,但是会根据OS不同编译成不同的二进制文件,然后在指定OS上运行(前提是先安装Go)。在GoLand中执行交叉编译
Golang 支持在一个平台下生成另一个平台可执行程序的交叉编译功能。
1、Mac下编译Linux, Windows平台的64位可执行程序:
$ CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build test.go
$ CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build test.go
2、Linux下编译Mac, Windows平台的64位可执行程序:
$ CGO_ENABLED=0 GOOS=darwin GOARCH=amd64 go build test.go
$ CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build test.go
3、Windows下编译Mac, Linux平台的64位可执行程序:
$ SET CGO_ENABLED=0SET GOOS=darwin3 SET GOARCH=amd64 go build test.go
$ SET CGO_ENABLED=0 SET GOOS=linux SET GOARCH=amd64 go build test.go
注:如果编译web等工程项目,直接cd到工程目录下直接执行以上命令
GOOS:目标可执行程序运行操作系统,支持 darwin,freebsd,linux,windows
GOARCH:目标可执行程序操作系统构架,包括 386,amd64,arm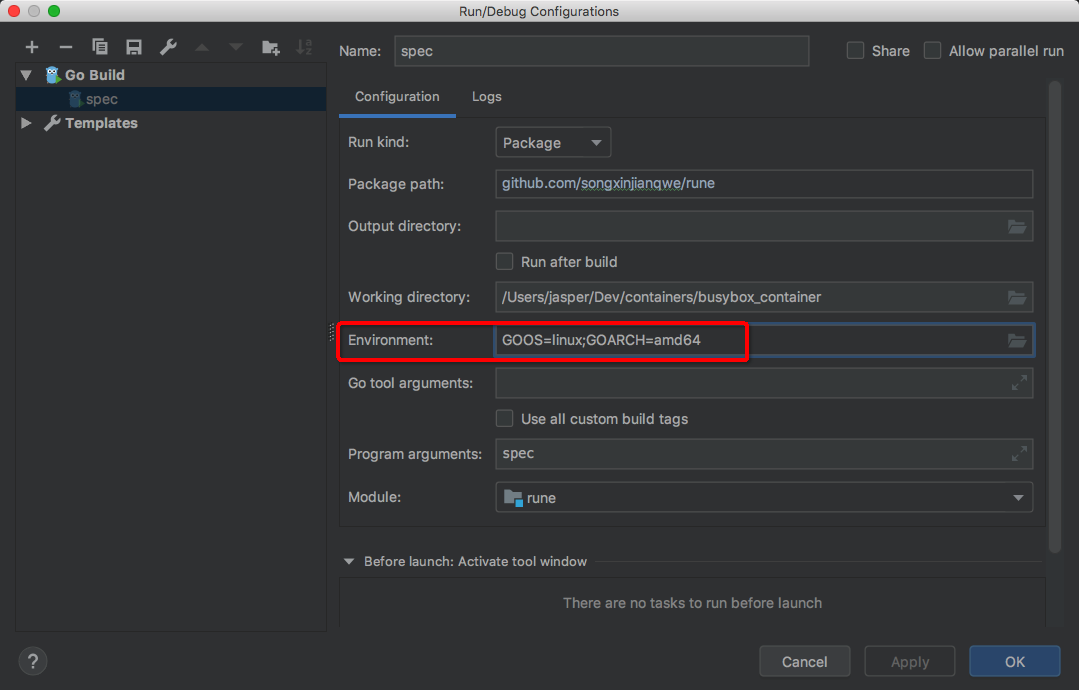
在GoLand中使用其他OS的库实现
在GoLand中将代码自动同步到远程
SFTP是SSH的一部分,所以共用端口即可。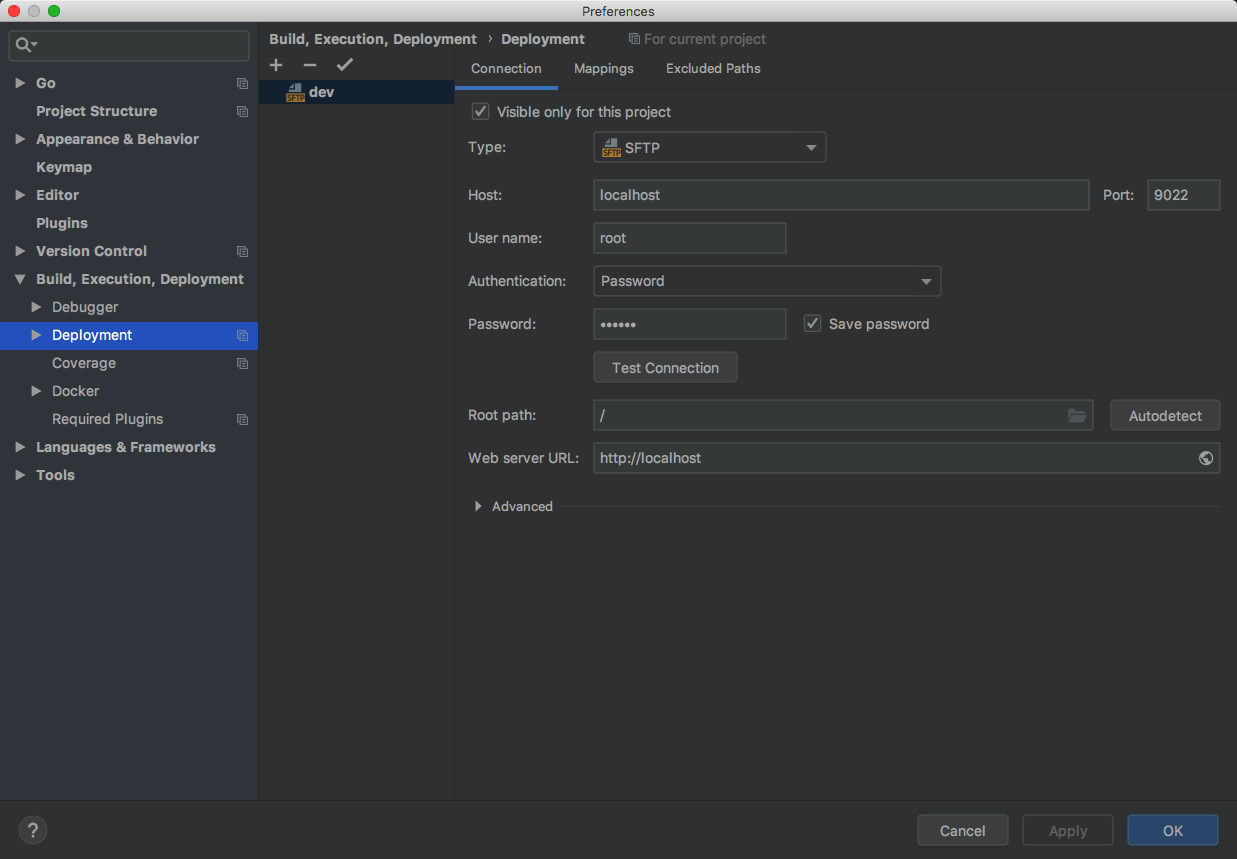
可以勾选Automatic Upload。在GoLand中进行远程debug
在服务器上安装dlvgo get -u github.com/derekparker/delve/cmd/dlv
1、代码上传到服务器
2、go build,编译为可执行文件
3、在服务器上启动debug进程(需要在VirtualBox中配置端口映射,比如映射到宿主机的9000)dlv --listen=:9000 --headless=true --api-version=2 exec ./main
4、在GoLand中进行如下配置,端口填写9000: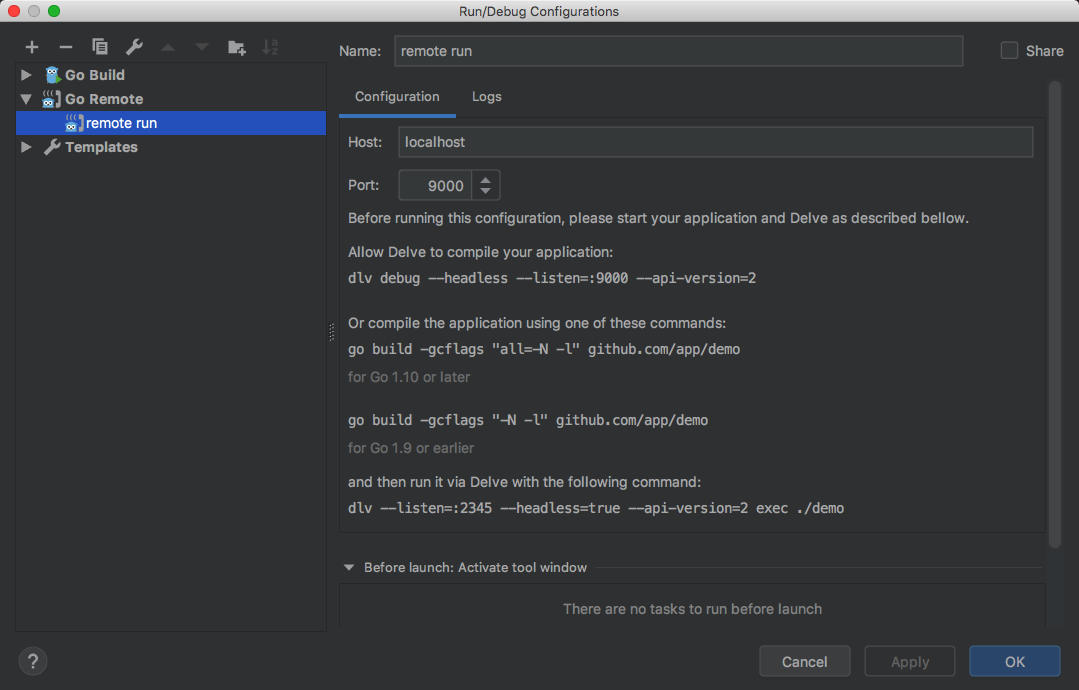
5、在GoLand中启动debug
包 package
1、包声明语句必须为文件代码第一行
2、包声明中的包名是代码包路径的最后一个元素
3、导包:import 代码包在$GOPATH/src下的相对路径,无论是否是本工程中的包
4、导入多个包可以import (package1,package2)
5、导入的多个包的最后一个元素不能重复,需要起别名 import (p1 package1, p2 package2)
6、导入的包没有使用会编译报错,如果仅仅是希望执行init函数,可以将别名换成 _
7、包初始化:func init() {…} 所有的代码包初始化函数都会在main函数执行前执行完毕,而且只会执行一次。另外,对一个代码包来说,其中的所有全局变量的初始化,都会在代码包的初始化函数执行前完成。
同一个代码包中可以存在多个代码包的包初始化函数,每一个源码文件中都可以定义多个。Go不会保证它们的执行函数。被导入的代码包的初始化函数总是会先执行。
标识符
预定义标识符:
- 基本数据类型的名词
- 接口类型error
- 常亮 true、false、iota
- 内置函数名词:append,cap,close,complex,copy,delete,imag,len,make,new,panic,print,println,real,recover。
-
关键字
type myString string,类似于C中的typedef
它们的值可以进行类型转换string(myString(“ABC”))
空接口:类型为interface{},任何类型都是空接口类型的实现类型。表达式
类型断言:判断一个接口值得实际类型是否为某个类型,或一个非接口值的类型是否实现了某个接口类型
v1.(I1),v1是一个接口值,I1是一个接口类型。
如果v1是一个非接口值,那么必须在做类型断言前把它转换成接口值,如:interface{}(v1).(I1)
如果类型断言的结果为否,意味着类型断言是失败的,会panic。
解法是i1, ok = interface{}(v1).(I1)。类型
基本类型
类型名 字节数 零值
bool 1 false
- byte 1 0
- rune 4 0 存储unicode字符,类似于int32
- int/uint 平台相关 0
- int8/uint8 1 0
- int16/uint16 2 0
- int32/uint32 3 0
- int64/uint64 4 0
- float32 4 0.0
- float64 8 0.0
- complex64 8 0.0 + 0.0i
- complex 16 0.0 + 0.0i
- string - “”
常亮定义:const
const (
c1 = v1
c2 = v2
)
高级类型
数组(值类型)
- ipv4 := […]uint8{192, 168, 0, 1}(短赋值,使用 := 不需要”var 变量名 类型” 中的前后两部分,类型会自动推导
- 长度不可变
- 数组的零值是一个不包含任何元素的空数组。比如[4]uint8{}。
- […]表示由Go编译器来计算元素数量
- 可以使用切片表达式,返回一个切片(返回一个视图,类似于Java中的subList)。
与Java中的List不同的是,数组是值类型,如果函数参数为一个数组,则传值时会将数组每一个值都浅拷贝一份。
切片(引用类型)
类似于Java中的ArrayList。
alphabet := []string{“a”, “b”, “c”},不需要带长度或者…
- 长度可变
- 零值为nil
- 空切片是长度为0的切片,make([]string, 0)可以返回一个空切片
- 可以对一个nil切片/空切片使用append、len、cap等方法,它们其实是一样的,使用nil切片就OK。
- append时有可能造成底层数组的容量增长。
- 切片值相当于对某个底层数组的引用,内部结构类似于:
type slice struct {arrayPtr *[] type,len uint,cap uint}
容量是指从指针指向的那个元素到底层数组最后一个元素的元素个数,也是在不更换底层数组的前提下,它的长度的最大值。
- append会返回一个新的切片,比如接收返回值才行。
make函数可以初始化切片、字典和通道,可以声明长度。
声明:var ipSwitches = map[string]int{}:key为string,value为int。
- 零值为nil
- 访问:ipSwitches[key]
- exist:value, ok := ipSwitches[key],第二个返回时是 是否存在
- 修改/添加:ipSwitches[key] = value
删除:delete(ipSwitches, key),无论是否存在
Channel(引用类型)
函数、方法(引用类型)
函数可以作为一个值来传递和使用
- 函数声明:
- func 函数名(param1 type1, param2 type2, …) 返回值类型 {}
- 如:func func1(v1 int, v2 string) (result int ,err error) {}
- 没有返回值,可以不写返回值结果列表
- 返回值结果列表中的结果要么都省略名称,要么都要有;有名称时可以当做变量使用,并且return时不需要显式写返回值变量名,只写return就行。
- 函数可以作为一个类型,比如:
type binaryOperation func(operand1 int, operand2 int) (result int, err error)func operate(op1 int, op2 int, bop binaryOperation) (result int, err errror) {if bop == nil {err = errors.New("invalid binary operation function")return}return bop(op1, op2)}
方法:与某个数据类型关联在一起的函数
type myInt intfunc (i myInt) add(another int) myInt {i = i + myInt(another)return i}
在func与函数名见,加了一个由圆括号包裹的接收者声明。
接受者声明由两部分组成:右边表明这个方法与哪个类型关联,左边是标识符,或者说接收者变量。
接收者类型可以是值类型,也可以是指针类型。
func (i *myInt) add(another int) myInt {*i = *i + myInt(another)return *i}
- 接收者变量代表的值实际上是原值的一个拷贝,如果不是指针类型,则不会修改源值(除非接收者类型是引用类型);如果是指针类型,则类似于Java中的成员方法,可以修改源值。
- 在进行方法调用时编译器做了语法糖:非指针数据类型的值,也是可以调用其指针方法,如i1.add(2),编译器会将转为(&i1).add(2)
接口(引用类型)
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。“
如果结构体想实现一个接口,那么需要实现这个接口的所有方法。
对接口值方法的调用会执行接口值里存储的用户定义类型的值对应的方法。
接口值是一个两个字word长度的数据结构,第一个字包含一个指向内部表iTable的指针,包含了所存储的值得类型信息。iTable包含了已存储的值的类型信息以及与整个值相关联的一组方法。第二个字是一个指向所存储值的指针(这就是在传入一个接收interface{}类型的值时要传入指针的原因)。
如果接收者类型是指针类型,那么使用值和指针都可以调用;如果是值类型,则只能调用值方法(有些情况下给出一个值,并不能拿到这个值的地址)。
比如:
type duration intfunc (d *duration) pretty() string {return fmt.Sprintf("Duration: %d", *d)}func main() {duration(42).pretty() // 创建了一个int对象,但是没有办法获得其指针}
接口的继承(嵌入类型):
- 嵌入类型是将已有的类型直接声明在新的结构类型中,被嵌入的类型被称为新的外部类型的内部类型。
- 通过嵌入类型,与内部类型相关的标识符会提升到外部类型上。这些被提升的标识符就像直接声明在外部类型里的标识符一样,也是外部类型的一部分。这样外部类型就组合了内部类型包含的所有属性,并且可以添加新的字段和方法。
- 外部类型可以通过声明与内部类型标识符同名的标识符来覆盖内部标识符的字段或者方法。 ```go type A interface { AMethod() }
type B interface { BMethod() A }
<a name="843cae35"></a>### 结构体(值类型)有名组合,无名继承- 结构体类型不仅可以关联方法,而且可以有内置字段。- 无名称字段称为嵌入字段。- 构造一个结构体实例:Type{fieldA:"v1", "fieldB":"v2"}或者Type{}- 零值为Type{}- new(Type)会返回一个*Type,构造一个空对象,并返回其指针;这个Type可以是基本数据类型,也可以是结构体。> 1、make只能用来分配及初始化类型为slice,map,chan的数据;new可以分配任意类型的数据> 2、new分配返回的是指针,即类型*T;make返回引用,即T;> 3、new分配的空间被清零,make分配后,会进行初始化。<a name="60a2bca2"></a>#### Stack Or Heap ?> How do I know whether a variable is allocated on the heap or the stack?> From a correctness standpoint, you don't need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language.> The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function's stack frame. However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.> In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap. However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.<a name="4f33e7aa"></a>## 枚举?```go// 枚举定义开始type TaskStatus intconst (ToBeExecuted TaskStatus = 0Executed TaskStatus = 1Executing TaskStatus = 2WaitForNextExecution TaskStatus = 3Stopped TaskStatus = 4)var statusText = map[TaskStatus]string {ToBeExecuted: "ToBeExecuted",Executed: "Executed",Executing: "Executing",WaitForNextExecution: "WaitForNextExecution",Stopped: "Stopped",}func (status TaskStatus) String() string {text, ok := statusText[status]if ok {return text}return "UNKNOWN"}// 枚举定义结束
容器类型(heap/堆、linkedlist/链表、ring/循环链表)
heap
type IntHeap []int // 定义一个类型func (h IntHeap) Len() int { return len(h) } // 绑定len方法,返回长度func (h IntHeap) Less(i, j int) bool { // 绑定less方法return h[i] < h[j] // 如果h[i]<h[j]生成的就是小根堆,如果h[i]>h[j]生成的就是大根堆}func (h IntHeap) Swap(i, j int) { // 绑定swap方法,交换两个元素位置h[i], h[j] = h[j], h[i]}func (h *IntHeap) Pop() interface{} { // 绑定pop方法,从最后拿出一个元素并返回old := *hn := len(old)x := old[n-1]*h = old[0 : n-1]return x}func (h *IntHeap) Push(x interface{}) { // 绑定push方法,插入新元素*h = append(*h, x.(int))}func main() {h := &IntHeap{2, 1, 5, 6, 4, 3, 7, 9, 8, 0} // 创建sliceheap.Init(h) // 初始化heapfmt.Println(*h)fmt.Println(heap.Pop(h)) // 调用popheap.Push(h, 6) // 调用pushfmt.Println(*h)for len(*h) > 0 {fmt.Printf("%d ", heap.Pop(h))}}
时间日期
time.Time
time.Location
time.Duration
访问控制
没有Java中的四种访问控制,Go中根据变量或函数的首字母是否大写来判断是否对包外可见,大写则可见,小写则不可见。
流程控制
- 没有do和while,只有for
- switch可以用于类型判断
- switch v.(type) { // switch i := v.(type)
- case string: …
- case int, uint:…
- default: …
- }
- fallthrough不允许出现在类型switch语句中
- switch v.(type) { // switch i := v.(type)
- if和switch都可以包含一条初始化子语句
- defer可以在函数结束后执行
- select类似于switch,但必须和channel 配合使用
- go用于启动goroutine
- if、for后面都不需要也不能加圆括号
- switch默认情况下是执行完一个case就结束的,需要接着执行下面的case需要加fallthrough
- 一个语句后不需要也不建议加分号
- for
- for i:= 0; i< 100; i++ {}
- for ; j < 10; j++ {}
- for k := 0; k < 0 ; {}
- for m < 50 {}
- for {}
- for index,elem := range array/slice {} 第一个返回值为索引,第二个为元素
defer延迟函数:适合释放资源或异常处理等收尾任务
err
- 致命错误可以使用panic
- panic(string)
- panic(error)
- 运行时恐慌可能是panic函数调用产生的,也可以是Go的运行时系统引发的。
- recover可以拦截panic
defer func() {if p := recover(); p != nil {fmt.Printf("Recovered panic: %s\n", p)}}()
也可以这样处理:
defer func() {if e := recover(); e != nil {if se, ok := e.(scanError) ; ok {err = se.err} else {panic(e)}}}()
如果是已知类型的panic,则作为返回值返回,否则直接让程序崩溃。
占位符
普通占位符
占位符 说明 举例 输出
%v 相应值的默认格式。 Printf(“%v”, people) {zhangsan},
%+v 打印结构体时,会添加字段名 Printf(“%+v”, people) {Name:zhangsan}
%#v 相应值的Go语法表示 Printf(“#v”, people) main.Human{Name:”zhangsan”}
%T 相应值的类型的Go语法表示 Printf(“%T”, people) main.Human
%% 字面上的百分号,并非值的占位符 Printf(“%%”) %
布尔占位符
占位符 说明 举例 输出
%t true 或 false。 Printf(“%t”, true) true
整数占位符
占位符 说明 举例 输出
%b 二进制表示 Printf(“%b”, 5) 101
%c 相应Unicode码点所表示的字符 Printf(“%c”, 0x4E2D) 中
%d 十进制表示 Printf(“%d”, 0x12) 18
%o 八进制表示 Printf(“%d”, 10) 12
%q 单引号围绕的字符字面值,由Go语法安全地转义 Printf(“%q”, 0x4E2D) ‘中’
%x 十六进制表示,字母形式为小写 a-f Printf(“%x”, 13) d
%X 十六进制表示,字母形式为大写 A-F Printf(“%x”, 13) D
%U Unicode格式:U+1234,等同于 “U+%04X” Printf(“%U”, 0x4E2D) U+4E2D
浮点数和复数的组成部分(实部和虚部)
占位符 说明 举例 输出
%b 无小数部分的,指数为二的幂的科学计数法,
与 strconv.FormatFloat 的 ‘b’ 转换格式一致。例如 -123456p-78
%e 科学计数法,例如 -1234.456e+78 Printf(“%e”, 10.2) 1.020000e+01
%E 科学计数法,例如 -1234.456E+78 Printf(“%e”, 10.2) 1.020000E+01
%f 有小数点而无指数,例如 123.456 Printf(“%f”, 10.2) 10.200000
%g 根据情况选择 %e 或 %f 以产生更紧凑的(无末尾的0)输出 Printf(“%g”, 10.20) 10.2
%G 根据情况选择 %E 或 %f 以产生更紧凑的(无末尾的0)输出 Printf(“%G”, 10.20+2i) (10.2+2i)
字符串与字节切片
占位符 说明 举例 输出 %s 输出字符串表示(string类型或[]byte) Printf(“%s”, []byte(“Go语言”)) Go语言 %q 双引号围绕的字符串,由Go语法安全地转义 Printf(“%q”, “Go语言”) “Go语言” %x 十六进制,小写字母,每字节两个字符 Printf(“%x”, “golang”) 676f6c616e67 %X 十六进制,大写字母,每字节两个字符 Printf(“%X”, “golang”) 676F6C616E67
指针
占位符 说明 举例 输出
%p 十六进制表示,前缀 0x Printf(“%p”, &people) 0x4f57f0
其它标记
占位符 说明 举例 输出
- 总打印数值的正负号;对于%q(%+q)保证只输出ASCII编码的字符。
Printf("%+q", "中文") "\u4e2d\u6587"
- 在右侧而非左侧填充空格(左对齐该区域)
备用格式:为八进制添加前导 0(%#o) Printf(“%#U”, ‘中’) U+4E2D
为十六进制添加前导 0x(%#x)或 0X(%#X),为 %p(%#p)去掉前导 0x; 如果可能的话,%q(%#q)会打印原始 (即反引号围绕的)字符串; 如果是可打印字符,%U(%#U)会写出该字符的 Unicode 编码形式(如字符 x 会被打印成 U+0078 ‘x’)。 ‘ ‘ (空格)为数值中省略的正负号留出空白(% d); 以十六进制(% x, % X)打印字符串或切片时,在字节之间用空格隔开 0 填充前导的0而非空格;对于数字,这会将填充移到正负号之后标准库
os
管道(进程间通信)
Cmd
```go // Run starts the specified command and waits for it to complete. // // The returned error is nil if the command runs, has no problems // copying stdin, stdout, and stderr, and exits with a zero exit // status. // // If the command starts but does not complete successfully, the error is of // type ExitError. Other error types may be returned for other situations. // // If the calling goroutine has locked the operating system thread // with runtime.LockOSThread and modified any inheritable OS-level // thread state (for example, Linux or Plan 9 name spaces), the new // process will inherit the caller’s thread state. func (c Cmd) Run() error
// Start starts the specified command but does not wait for it to complete. // // The Wait method will return the exit code and release associated resources // once the command exits. func (c *Cmd) Start() error
<a name="51dd7dca"></a>#### 匿名管道ps -ef | grep go<br />shell会为每个命令都创建一个进程,然后把左边命令的标准输出用管道与右边命令的标准输入连接起来。管道的优点在于简单,而缺点则是只能单向通信以及对通信双方关系上的严格限制。<br />这个称为匿名管道。```gofunc anonymousPipeline(cmd1 *exec.Cmd, cmd2 *exec.Cmd) {if cmd1 == nil || cmd2 == nil {fmt.Printf("cmd1 or cmd2 couldn't be nil")}var cmd1Output bytes.Buffercmd1.Stdout = &cmd1Outputerr := cmd1.Run()if err != nil {fmt.Printf("Error: Couldn't execute command No.0: %s\n", err)return}//fmt.Printf("cmd1: %s\n", string(cmd1Output.String()))cmd2.Stdin = &cmd1Outputvar cmd2Output bytes.Buffercmd2.Stdout = &cmd2Outputerr = cmd2.Run()if err != nil {fmt.Printf("Error: Couldn't execute command No.1: %s\n", err)return}fmt.Printf("cmd2: %s\n", string(cmd2Output.String()))}func main() {cmd1 := exec.Command("ps", "-ef")cmd2 := exec.Command("grep","go")anonymousPipeline(cmd1, cmd2)}
命名管道
任何进程都可以通过命名管道交换数据。实际上,命名管道以文件的形式存在于文件系统中。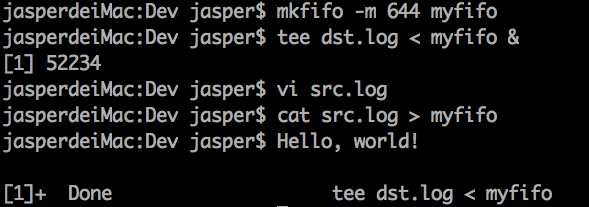
这里是使用管道来将src.log的数据转移到dst.log中。
命名管道默认是阻塞式(读写),tee命令这里是从管道中读取数据,这条命令就变成了阻塞式的,使用&来使其后台运行。
当cat时,向管道写入数据,此时tee命令在后台监听管道数据,当管道接收到数据后变为前台进程。
os.Pipe和io.Pipe不同,前者返回值为File,后者返回值为PipeReader.PipeWriter;前者是一个文件,后者是内存;前者没有处理并发写入的并发问题,后者有处理。
命名管道可以被多路复用,所以当有多个输入端同时写入数据的时候我们就不得不考虑操作的原子性问题。由于os.Pipe函数生成的管道在底层是由操作系统级别的管道来支持的,操作系统提供的管道并不提供原子操作支持。为此,Go语言标准库代码包io中提供了一种被存在于内存中、具备原子操作的保证的管道(以下称为内存管道)。
代码块
Go
xxxxxxxxxx
1
func inMemorySyncPipe() {2
reader, writer := io.Pipe()3
go func() {4
output := make([]byte, 100)5
n, err := reader.Read(output)6
if err != nil {7
fmt.Printf(“Error: Couldn’t read data from the named pipe: %s\n”, err)8
}9
fmt.Printf(“Read %d byte(s). [in-memory pipe]\n”, n)10
}()11
input := make([]byte, 26)12
for i := 65; i <= 90; i++ {13
input[i-65] = byte(i)14
}15
n, err := writer.Write(input)16
if err != nil {17
fmt.Printf(“Error: Couldn’t write data to the named pipe: %s\n”, err)18
}19
fmt.Printf(“Written %d byte(s). [in-memory pipe]\n”, n)20
time.Sleep(200 time.Millisecond)21
}
信号(进程间通信)
操作系统信号是IPC中唯一一种异步的通信方法,它的本质是用软件来模拟硬件的终端机制。信号用来通知某个进程有某个事件发生了。
目前操作系统支持的信号有以下这些:
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL5) SIGTRAP 6) SIGABRT 7) SIGEMT 8) SIGFPE9) SIGKILL 10) SIGBUS 11) SIGSEGV 12) SIGSYS13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGURG17) SIGSTOP 18) SIGTSTP 19) SIGCONT 20) SIGCHLD21) SIGTTIN 22) SIGTTOU 23) SIGIO 24) SIGXCPU25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH29) SIGINFO 30) SIGUSR1 31) SIGUSR2
| SIGABRT | 由调用abort函数产生,进程非正常退出 |
|---|---|
| SIGALRM | 用alarm函数设置的timer超时或setitimer函数设置的interval timer超时 |
| SIGBUS | 某种特定的硬件异常,通常由内存访问引起 |
| SIGCANCEL | 由Solaris Thread Library内部使用,通常不会使用 |
| SIGCHLD | 进程Terminate或Stop的时候,SIGCHLD会发送给它的父进程。缺省情况下该Signal会被忽略 |
| SIGCONT | 当被stop的进程恢复运行的时候,自动发送 |
| SIGEMT | 和实现相关的硬件异常 |
| SIGFPE | 数学相关的异常,如被0除,浮点溢出,等等 |
| SIGFREEZE | Solaris专用,Hiberate或者Suspended时候发送 |
| SIGHUP | 发送给具有Terminal的Controlling Process,当terminal被disconnect时候发送 |
| SIGILL | 非法指令异常 |
| SIGINFO | BSD signal。由Status Key产生,通常是CTRL+T。发送给所有Foreground Group的进程 |
| SIGINT | 由Interrupt Key产生,通常是CTRL+C或者DELETE。发送给所有ForeGround Group的进程 |
| SIGIO | 异步IO事件 |
| SIGIOT | 实现相关的硬件异常,一般对应SIGABRT |
| SIGKILL | 无法处理和忽略。中止某个进程 |
| SIGLWP | 由Solaris Thread Libray内部使用 |
| SIGPIPE | 在reader中止之后写Pipe的时候发送 |
| SIGPOLL | 当某个事件发送给Pollable Device的时候发送 |
| SIGPROF | Setitimer指定的Profiling Interval Timer所产生 |
| SIGPWR | 和系统相关。和UPS相关。 |
| SIGQUIT | 输入Quit Key的时候(CTRL+\)发送给所有Foreground Group的进程 |
| SIGSEGV | 非法内存访问 |
| SIGSTKFLT | Linux专用,数学协处理器的栈异常 |
| SIGSTOP | 中止进程。无法处理和忽略。 |
| SIGSYS | 非法系统调用 |
| SIGTERM | 请求中止进程,kill命令缺省发送 |
| SIGTHAW | Solaris专用,从Suspend恢复时候发送 |
| SIGTRAP | 实现相关的硬件异常。一般是调试异常 |
| SIGTSTP | Suspend Key,一般是Ctrl+Z。发送给所有Foreground Group的进程 |
| SIGTTIN | 当Background Group的进程尝试读取Terminal的时候发送 |
| SIGTTOU | 当Background Group的进程尝试写Terminal的时候发送 |
| SIGURG | 当out-of-band data接收的时候可能发送 |
| SIGUSR1 | 用户自定义signal 1 |
| SIGUSR2 | 用户自定义signal 2 |
| SIGVTALRM | setitimer函数设置的Virtual Interval Timer超时的时候 |
| SIGWAITING | Solaris Thread Library内部实现专用 |
| SIGWINCH | 当Terminal的窗口大小改变的时候,发送给Foreground Group的所有进程 |
| SIGXCPU | 当CPU时间限制超时的时候 |
| SIGXFSZ | 进程超过文件大小限制 |
| SIGXRES | Solaris专用,进程超过资源限制的时候发送 |
在OS内部,每个信号都有正整数表示,称为信号编号。
/**如果当前进程收到了未自定义处理方法的信号,就会执行由OS指定的默认操作。如果收到了自定义处理方法的信号,就会放到对应的channel中,由我们自己来处理这个信号,仅仅打印一些信息是不够的。特例:SIGKILL和SIGSTOP是无法自定义处理方法的,只会执行OS的默认操作,根本原因是它们向OS的超级用户提供了使进程停止或终止的可靠方法*/func registerAndListenerThenStopSignals() {receivedSignals := make(chan os.Signal, 1)customProcessingSignals := []os.Signal{syscall.SIGINT, syscall.SIGQUIT}fmt.Printf("Set notification for %s... [customProcessingSignals]\n", customProcessingSignals)// 类似于addListener,当当前进程真正收到信号时,会放入到channel中,我们可以使用一个goroutine来监听这个channelsignal.Notify(receivedSignals, customProcessingSignals...)waitGroup := sync.WaitGroup{}waitGroup.Add(1)go func() {for sig := range receivedSignals {fmt.Printf("received %s\n", sig)}waitGroup.Done()}()// 取消掉在之前调用signal.Notify函数时告知signal处理程序需要自行处理若干信号的行为。signal.Stop(receivedSignals)close(receivedSignals)waitGroup.Done()}func main() {registerAndListenerThenStopSignals()}
- 多个channel可以都注册监听器,相当于处理了多个handler。
- 在signal内部,存储了一个key为channel,value为信号集合的Map。
- 当调用Notify时,会对Map执行不存在key,则添加;存在则更新;
- 当调用Stop时,会删除同key;
- 当接收到一个已申请自定义处理的信号之后,signal处理程序会将其封装,然后遍历Map,查看它们的value中是否包含了该信号。如果包含,则发送给key。
完整示例:
package mainimport ("bytes""errors""fmt""io""os""os/exec""os/signal""runtime/debug""strconv""strings""sync""syscall""time")func main() {go func() {time.Sleep(time.Second * 5)handleSignal()}()killMyself()}func handleSignal() {receivedSignals := make(chan os.Signal, 1)customProcessingSignals := []os.Signal{syscall.SIGINT, syscall.SIGQUIT}fmt.Printf("Set notification for %s... [customProcessingSignals]\n", customProcessingSignals)// 类似于addListener,当当前进程真正收到信号时,会放入到channel中,我们可以使用一个goroutine来监听这个channelsignal.Notify(receivedSignals, customProcessingSignals...)waitGroup := sync.WaitGroup{}waitGroup.Add(1)go func() {for sig := range receivedSignals {fmt.Printf("received %s\n", sig)}waitGroup.Done()}()waitGroup.Wait()}func killMyself() {defer func() {if err := recover(); err != nil {fmt.Printf("Fatal Error: %s\n", err)debug.PrintStack()}}()// ps aux | grep "signal" | grep -v "grep" | grep -v "go run" | awk '{print $2}'cmds := []*exec.Cmd{exec.Command("ps", "aux"),exec.Command("grep", "signal"),exec.Command("grep", "-v", "grep"),exec.Command("grep", "-v", "go run"),exec.Command("awk", "{print $2}"),}output, err := runCmds(cmds)if err != nil {fmt.Printf("Command Execution Error: %s\n", err)return}pids, err := getPids(output)if err != nil {fmt.Printf("PID Parsing Error: %s\n", err)return}fmt.Printf("Target PID(s):\n%v\n", pids)for _, pid := range pids {proc, err := os.FindProcess(pid)if err != nil {fmt.Printf("Process Finding Error: %s\n", err)return}sig := syscall.SIGQUITfmt.Printf("Send signal '%s' to the process (pid=%d)...\n", sig, pid)err = proc.Signal(sig)if err != nil {fmt.Printf("Signal Sending Error: %s\n", err)return}}}func getPids(strs []string) ([]int, error) {var pids []intfor _, str := range strs {pid, err := strconv.Atoi(strings.TrimSpace(str))if err != nil {return nil, err}pids = append(pids, pid)}return pids, nil}func runCmds(cmds []*exec.Cmd) ([]string, error) {if cmds == nil || len(cmds) == 0 {return nil, errors.New("The cmd slice is invalid!")}first := truevar output []bytevar err errorfor _, cmd := range cmds {fmt.Printf("Run command: %v\n", getCmdPlaintext(cmd))if !first {var stdinBuf bytes.BufferstdinBuf.Write(output)cmd.Stdin = &stdinBuf}var stdoutBuf bytes.Buffercmd.Stdout = &stdoutBufif err = cmd.Start(); err != nil {return nil, getError(err, cmd)}if err = cmd.Wait(); err != nil {return nil, getError(err, cmd)}output = stdoutBuf.Bytes()//fmt.Printf("Output:\n%s\n", string(output))if first {first = false}}var lines []stringvar outputBuf bytes.BufferoutputBuf.Write(output)for {line, err := outputBuf.ReadBytes('\n')if err != nil {if err == io.EOF {break} else {return nil, getError(err, nil)}}lines = append(lines, string(line))}return lines, nil}func getCmdPlaintext(cmd *exec.Cmd) string {var buf bytes.Bufferbuf.WriteString(cmd.Path)for _, arg := range cmd.Args[1:] {buf.WriteRune(' ')buf.WriteString(arg)}return buf.String()}func getError(err error, cmd *exec.Cmd, extraInfo ...string) error {var errMsg stringif cmd != nil {errMsg = fmt.Sprintf("%s [%s %v]", err, (*cmd).Path, (*cmd).Args)} else {errMsg = fmt.Sprintf("%s", err)}if len(extraInfo) > 0 {errMsg = fmt.Sprintf("%s (%v)", errMsg, extraInfo)}return errors.New(errMsg)}
socket(进程间通信)
io
io包是围绕着实现了io.Writer和io.Reader接口类型的值而构建的。
type Writer interface {Write(p []byte) (n int, err error)}
返回的是写入的字节数。正常情况下应该返回len(p),如果是小于len(p),则error一定不为nil。
Write不能改写切片里的数据。
type Reader interface {Read(p []byte) (n int, err error)}
- read最多读入len(p)个字节,保存到p。
- 当成功读入n > 0的字节后,如果遇到错误或者文件读取完毕,则返回读入的字节数。本次读取文件完毕后,可能会返回err == EOF,也可能会返回err = nil。但是下次调用read总会返回0,EOF。
bytes.Buffer可以作为字节缓冲区使用。

sort
实现1(抽象类型)
package sort// A type, typically a collection, that satisfies sort.Interface can be// sorted by the routines in this package. The methods require that the// elements of the collection be enumerated by an integer index.type Interface interface {// Len is the number of elements in the collection.Len() int// Less reports whether the element with// index i should sort before the element with index j.Less(i, j int) bool// Swap swaps the elements with indexes i and j.Swap(i, j int)}// Sort sorts data.// It makes one call to data.Len to determine n, and O(n*log(n)) calls to// data.Less and data.Swap. The sort is not guaranteed to be stable.func Sort(data Interface) {n := data.Len()quickSort(data, 0, n, maxDepth(n))}
自定义struct需要实现这几个方法,之后就可以使用sort.Sort排序了。
type Person struct {Name stringAge int}type PersonList []Personfunc (pl PersonList) Len() int {return len(pl)}func (pl PersonList) Less(i, j int) bool {return pl[i].Age > pl[j].Age}func (pl PersonList) Swap(i, j int) {pl[i], pl[j] = pl[j], pl[i]}func NewPerson(name string, age int) Person {person := Person{}person.Name = nameperson.Age = agereturn person}func main() {var personList PersonListfor i:= 0 ; i < 10; i++ {personList = append(personList, NewPerson("P" + strconv.Itoa(i) , i))}sort.Sort(personList)for _, p := range personList {fmt.Printf("%#v\n", p)}}
实现2(特定类型,如切片)
切片
type Person struct {Name stringAge int}func NewPerson(name string, age int) Person {person := Person{}person.Name = nameperson.Age = agereturn person}func main() {var personList []Personfor i:= 0 ; i < 10; i++ {personList = append(personList, NewPerson("P" + strconv.Itoa(i) , i))}sort.Slice(personList, func(i, j int) bool {return personList[i].Age > personList[j].Age})for _, p := range personList {fmt.Printf("%#v\n", p)}}
int
func main() {n := 10intArr := make([]int, n)for i := 0; i < n ;i++ {intArr[i] = n - i - 1}fmt.Printf("%#v\n", intArr)sort.Ints(intArr)fmt.Printf("%#v\n", intArr)}
常用类库
logrus(日志)
import log “github.com/sirupsen/logrus”
/**全局有效*/func init() {//设置输出样式,自带的只有两种样式logrus.JSONFormatter{}和logrus.TextFormatter{}log.SetFormatter(&log.TextFormatter{})//设置output,默认为stderr,可以为任何io.Writer,比如文件*os.Filelog.SetOutput(os.Stdout)//设置最低loglevellog.SetLevel(log.InfoLevel)}
cli(命令行工具制作)
errors(错误处理)
Go工程结构
标识符
关键字
字面量
操作符
表达式
基本数据类型
数组
切片
字典
函数和方法
接口
结构体
代码块和作用域
if
switch
for
defer
panic和recover
依赖管理
默认情况下,你依赖的包,需要自己手动go get下载到$GOPATH下,然后依赖。
当其他人需要引用你的包时,需要手动将间接依赖的包也go get下来。
而且默认情况下无法指定依赖的包的版本,依赖的总是最新的版本。
Go在1.5版本引入了vendor属性(默认关闭,需要设置go环境变量GO15VENDOREXPERIMENT=1),并在1.6版本中默认开启了vendor属性。
简单来说,vendor属性就是让go编译时,优先从项目源码树根目录下的vendor目录查找代码(可以理解为切了一次GOPATH),如果vendor中有,则不再去GOPATH中去查找。
但是vendor目录又带来了一些新的问题:
- vendor目录中依赖包没有版本信息。这样依赖包脱离了版本管理,对于升级、问题追溯,会有点困难。
- 如何方便的得到本项目依赖了哪些包,并方便的将其拷贝到vendor目录下? Manual is fxxk.
社区为了解决这些(工程)问题,在vendor基础上开发了多个管理工具,比较常用的有godep, govendor, glide。go官方也在开发官方dep,目前还是Alpha状态。
govendor:
https://www.jianshu.com/p/88669ba57d04
godep:
https://www.cnblogs.com/zuxingyu/p/6015715.html
还是将/vendor整个提交到github去了,这样的话不需要单独下载间接依赖或者govendor sync来下载间接依赖。
并发编程
对于CPU密集型应用,性能瓶颈在CPU,此时不需要设置过多线程,只需要设置核数个线程即可,跑满CPU就是最大化效率,过多线程会导致线程切换,降低CPU利用率。
而Web应用等属于IO密集型应用,性能瓶颈基本集中于数据库IO。在数据库性能一定的情况下,应用服务器需要支持尽可能多的并发请求,其实就是在内存一定的情况下支持更多并发的用户请求进入系统。但是一味增加线程数也是不切实际的,会导致线程切换频繁,CPU的开销增大,反而降低效率。
阻塞IO是指进入IO后当前线程进入等待态,等待IO返回,由OS执行线程调度。
而异步IO是指进入IO后当前线程并不会进入等待态,可以继续执行其他代码,IO执行完毕触发回调,此时继续分配线程,执行后续任务。
- 对于Tomcat等基于request per thread(NIO+线程池)服务器,往往会设置有着几百个线程的线程池。线程可以在开始阻塞IO时进入等待态,由OS执行线程调度,在IO完毕后线程重新回到就绪态,此时OS会给该线程分配时间片。而支持尽可能多的并发请求的关键,在于每个线程无法做到快速回收,必须等待IO完毕后才会回收,因此无法做到所有线程都处于工作状态,需要频繁地进行线程切换。
- 对于Netty等基于event loop的服务器,往往会设置较少的线程数,每个线程都在执行event loop中的request,假设此时是异步IO,那么request在执行时在遇到异步IO时会使用异步回调的方式来处理,线程会立即回收,继续处理下一个request。而异步IO就绪后,又会去触发回调,重新分配线程进行处理。这样就不会使线程进入等待态,致使OS触发线程调度,增加线程切换的开销。但现实情况是,数据库IO基本都是阻塞IO,即使异步回调,也没有办法避免线程进入等待态。
- 最好的处理办法就是异步回调+异步IO,而这一点Netty可以实现,协程也可以实现,主要区别只是编程范式,前者需要编写回调逻辑,后者则是编写顺序逻辑(killim可以了解一下,是一个Java协程库)。
- 但是即使是在阻塞IO的情况下,协程也有其优势所在:线程的维护开销是相对较大的,无法同时创建过多的线程,而协程更为轻量,消耗的内存更少,可以同时存在更多的协程;并且协程的切换也比线程切换的代价要小。要注意一点的是,要通过性能测试来确定,对于IO密集型的应用来说,性能瓶颈究竟在哪里,一定要从最痛的点入手,而非盲目地去改造应用程序。
- 另外,NIO,或者说IO多路复用,一般是指TCP网络编程中,Server可以以NIO的方式来管理Socket,节省掉的是客户端发来的数据就绪的时间,BIO是当前线程在accept之后,当调用read时如果客户端数据尚未就绪,则进入阻塞;而NIO以轮询的方式来检查客户端数据是否就绪(一个线程就可以管理若干个客户端连接),而非直接阻塞,在就绪后才分配线程,进行read。这里的IO是指网络IO,而前面提到的同步或异步IO,只是数据库IO。
伪代码示例:
同步IO
public void count() {// query and waitLong count = jdbcTemplate.queryForObject("select count(*) from user", Long.class);// 后续操作}
异步IO
public void count() {asyncJdbcTemplate.queryForObject("select count(*) from user", Long.class).addListener(new DataCallback<Long> {public void handle(Long data) {// 后续逻辑}})}
listener的逻辑会放到event loop中执行,待异步IO返回后才会被分配到某个线程执行。
并发编程中保证数据一致性的关键是如何看待状态。状态,包括内存状态,比如Java中的成员变量,以及数据库状态。不论是Tomcat还是Netty,到我们业务逻辑时都是并发执行的。对于内存状态来说,我们要尽量避免使用可变的成员变量,如果一定用,那么必须要去考虑并发问题,要么加锁,要么使用线程安全的集合,要么使用CAS等无锁算法;对于数据库状态来说,我们要考虑某一段操作是否需要是原子执行的,如果需要,那么就需要使用悲观锁(select for update),或者是乐观锁(version,CAS)。
goroutine
不要用共享内存的方式来通信,而应以通信的方式来共享内存。
Go推荐通过channel(线程安全的BlockingQueue)来在多个goroutine之间传递数据。
goroutine是Go暴露出来的调度单位,Go并没有暴露线程这种概念。
一条go语句意味着一个函数或方法的并发执行。go语句是由go关键字和调用表达式(针对函数或方法的调用,函数可以是命名的,也可以是匿名的)组成的。
Go运行时系统对go语句中的函数(go函数)的执行是并发的。
go函数的返回值是没有意义的,数据传递要通过channel来实现。
func printConcurrently(words []string, waitGroup *sync.WaitGroup) {for _, word := range words {go func(aWord string) {waitGroup.Add(1)defer waitGroup.Done()fmt.Println(aWord)}(word)}}/**main函数如果要作为应用启动函数,则必须放在main包中一个项目(项目并不是go中的概念)中,可以存在多个同名包*/func main() {group := sync.WaitGroup{}printConcurrently([]string{"Eric", "Harry", "Robert", "Jim", "Mark"}, &group)group.Wait()fmt.Println("finished!")}
封装main函数的goroutine被称为主goroutine。主goroutine会由runtime.m0负责运行。主goroutine启动会设置每个goroutine锁能申请的栈的最大空间,执行系统监测任务,然后执行一系列初始化工作,包括init函数的执行,之后会执行main函数。在执行完main函数后,还会检查主goroutine是否引发了panic,并进行必要的处理。最后,主goroutine会结束自己以及当前进程的运行。
channel
Go中channel既指通道类型(引用类型),也指代可以传递某种类型的值的通道。
- 类型声明:chan T,默认为双向通道。
单向通道:chan<- T(发送通道);<-chan T(接收通道)
- 初始化:make(chan int, 10) 称为缓冲通道 ;make(chan int)称为非缓冲通道(TransferQueue)
- 接收:elem := <- myChan 通道没有元素时阻塞(Gwaiting)
- elem, ok := <-myChan
- 如果接收操作因通道关闭而结束时,第二个返回值会为false
- elem, ok := <-myChan
- 发送:拷贝一份发送!通道满时阻塞
- myChan <- “a”
- 可以作为goroutine的同步机制,比如本goroutine完成后向一个容量为1的channel发送一个元素,而等待该goroutine完成的goroutine会从该channel取出一个元素(用sync.waitGroup更好)。
生产者消费者模式
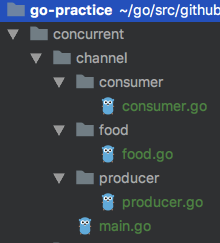
Main
/**这个示例是一个多生产者-多消费者模式的示例;1)启动了三个生产者goroutine,分别生产20个食物,当结束时,将waitProducersStop的计数值--2)启动了两个消费者goroutine,无限消费食物,直至通道被关闭,当结束时,将waitConsumersStop的计数值--3)构造了大小为6的BlockingQueue(channel),传入生产者和消费者的goroutine4)main函数在等待生产者均生产完毕时,会关闭通道;5)消费者在消费时如果发现通道被关闭,则会从无限循环中退出*/func main() {blockingQueue := make(chan *food.Food, 6)waitProducersStop := sync.WaitGroup{}waitConsumersStop := sync.WaitGroup{}for i := 0; i < 3; i++ {producerName := fmt.Sprintf("producer-%d", i)go producer.Produce(producerName, blockingQueue, &waitProducersStop)waitProducersStop.Add(1)}for i := 0; i < 2; i++ {consumerName := fmt.Sprintf("consumer-%d", i)go consumer.Consume(consumerName, blockingQueue, &waitConsumersStop)waitConsumersStop.Add(1)}waitProducersStop.Wait()fmt.Println("All Producers Stopped")close(blockingQueue)waitConsumersStop.Wait()fmt.Println("All Consumers Stopped")fmt.Println("【MAIN】finished")}
Producer
func Produce(producerName string, blockingQueue chan<- *food.Food, waitProducerStop *sync.WaitGroup) {for i := 0; i < 20; i++ {food := food.NewFood(fmt.Sprintf("【Food-%d-From-%s】", i, producerName))blockingQueue <- foodfmt.Printf("【%s】produced %#v\n", producerName, food)}waitProducerStop.Done()fmt.Printf("【%s】stopped\n", producerName)}
Consumer
func Consume(consumerName string, blockingQueue <-chan *food.Food, waitGroup *sync.WaitGroup) {for {if food, ok := <-blockingQueue; ok {fmt.Printf("【%s】consumed %s\n", consumerName, food)} else {break}}waitGroup.Done()fmt.Printf("【%s】stopped\n", consumerName)}
Food
type Food struct {Id string}func NewFood(id string) *Food {f := Food{}f.Id = idreturn &f}
注意事项
1、当主goroutine(main函数)结束后,整个应用会结束
2、 通道也是可以作为waitGroup使用的,一般是放入一个strcut {}{}(类型是struct{},后一个{}是初始化),空结构体类型的变量是不占用内存的,并且所有该类型的变量都拥有相同的内存地址
3、如果试图向一个已关闭的通道发送元素,那么会引发运行期panic,即使发送操作正在因为通道已满而阻塞。为了避免这种情况发送,我们可以在select代码块中执行发送操作。
select类似于switch语句,但是只能用于通道发送和接收。
分支选择规则:在开始执行select语句时,所有跟在case关键字右边的发送语句或接收语句中的通道表达式和元素表达式都会先求值(顺序为从左到右,自上而下),如果某个case中发送或接收操作可以立即执行(当前goroutine不会因此操作而被阻塞),则被选中。如果只有一个case满足条件时,则只会执行该case下面的语句;如果多个case满足条件,则随机选中一个case执行;如果都不满足,则进入default;如果都不满足,且没有default,则当前goroutine会阻塞,直到至少有一个case中的操作可以执行。
intChan := make(chan int, 10)strChan := make(chan string, 10)// ...select {case e1 := <- intChan:fmt.Println("The 1th was selected, e1=%v.\n", e1)case e2 := <- strChan:fmt.Println("The 2nd case was selected, e2=%v.\n", e2)default:fmt.Println("Default!")}
无论如何都不应该在接收端发送通道,因为接收端无法判断发送端是否还会向该通道发送元素。
在发送端关闭通道一般不会对接收端的接收操作产生什么印象。如果通道在被关闭时仍有元素,则依然可以取出,并根据该表达式的第二个返回值来判断通道是否已关闭且已无元素可取。
还可以顺便检查通道是否关闭,如果关闭且无元素,则跳出select
select {case e, ok := <- strChan:if !ok {break}fmt.Println("Received:%v\n", e)}
4、channel的阻塞唤醒是有排队机制的,先阻塞的会被先唤醒。每次只会唤醒一个goroutine。
5、发送方向通道发送的值会被复制,接收方接收的总是该值得副本。如果是值类型(且递归下去也是值类型,如struct),则不会涉及线程安全问题;如果是引用类型,则需要使用同步机制(互斥锁、读写锁)。
6、单向channel(这个类似于Java中PECS)。构造出来的channel都是双向的,但是在函数的形式参数中可以规定channel为单向,将错误操作在编译时暴露出来(比如Producer只应该放入元素,Consumer只应该取出元素)。
形式参数为单向channel时,实际参数可以是单向或双向channel;反之只能是双向channel。
chan<- type:只能放入元素
<-chan type:只能取出元素
Goroutine Pool
Run是需要阻塞到有gouroutine空闲时接收了任务才会返回,类似于使用了TransferQueue作为工作队列的ThreadPoolExector。
package poolimport ("sync")type Runnable interface {Run()}type GoroutinePool struct {workQueue chan RunnablewaitGroup sync.WaitGroup}func NewGoroutinePool(maxPoolSize int) *GoroutinePool {pool := GoroutinePool{workQueue: make(chan Runnable),}pool.waitGroup.Add(maxPoolSize)for i := 0; i < maxPoolSize ; i++ {go func() {for runnable := range pool.workQueue {runnable.Run()}pool.waitGroup.Done()}()}return &pool}func (this* GoroutinePool) Run(r Runnable) {this.workQueue <- r}func (this* GoroutinePool) ShutDown() {close(this.workQueue)this.waitGroup.Wait()}
time(定时任务)
延迟任务
结构体Timer(定时器),有两种方式可以构造:
- time.NewTimer(延迟任务),传入一个纳秒值,表示在该纳秒后,会执行延迟任务
timer := time.NewTimer(3*time.Hour + 36*time.Minute)- timer类型为*time.Timer
在time.Timer类型中,对外通知定时器到期的途径就是通道,由字段C代表。C代表的是一个chan time.Time类型的带缓冲的接收通道。C的值原先为双向通道,只不过在赋给C的时候被自动转换为了接收通道。定时器内部仍然可以向它发送元素值,一旦触及到期时间,定时器就会向它的通知通道发送一个元素值,这个元素值代表了该定时器的绝对到期时间。
time.AfterFunc是另一种新建定时器的方法,第一个参数是相对到期时间,第二个参数是到期时需要执行的函数(在另一个goroutine中执行)。
定时任务(scheduleAtFixRate)
time.Ticker(断续器)。定时器在重置之前只会到期一次,而断续器会在到期后立即进入下一个周期并等待再次到期,直至被停止。
ticker := time.NewTicker(time.Second)
for range ticker.C {//...}// 或者for now := range ticker.C {//...}
锁
互斥锁
sync.Mutex
用法:
var mutex sync.Mutexfunc write() {mutex.Lock()defer mutex.Unlock()//...}
注意!不可重入!
一个已经加锁了的函数中调用另一个希望再次获取该锁的函数时,会导致阻塞!
这需要我们仔细设计,将加锁、解锁始终放到同一层次中,不要将不同层次的函数都设计成原子的。
var mutex sync.Mutexfunc opAtomically() {mutex.Lock()defer mutex.Unlock()fmt.Println("opAtomically executing")}func main() {mutex.Lock()defer mutex.Unlock()fmt.Println("main executing")opAtomically()}
main executing fatal error: all goroutines are asleep - deadlock! goroutine 1 [semacquire]: sync.runtime_SemacquireMutex(0x117fea4, 0x0) /usr/local/Cellar/go/1.11.5/libexec/src/runtime/sema.go:71 +0x3d sync.(*Mutex).Lock(0x117fea0) /usr/local/Cellar/go/1.11.5/libexec/src/sync/mutex.go:134 +0xff main.opAtomically() /Users/jasper/go/src/github.com/songxinjianqwe/go-practice/concurrent/mutex/main.go:11 +0x31 main.main() /Users/jasper/go/src/github.com/songxinjianqwe/go-practice/concurrent/mutex/main.go:20 +0x9e
读写锁
条件
sync.Cond
sync.NewCond(l Locker) *Cond
三个方法:
- Wait(注意:循环测试条件,被lock包裹)
- Signal(唤醒一个goroutine)
- Broadcast(唤醒所有goroutine)
原子操作
sync/atomic
支持以下类型:int32,int64,uint32,uint64,uintptr,unsafe.Pointer。
支持以下操作:增、减、比较并交换、载入、存储、交换
函数命名:OP+类型名
如:newi32 := atomic.AddInt32(&i32, 3)
atomic.CompareAndSwap$Type
atomic.Load$Type ->原子读取
atomic.Store$Type ->原子写入(for {CompareAndSwap()})
原子值类型:atomic.Value,有两个方法:Load和Store,对应interface{}(类似于Java中的Object)。
一旦原子值实例存储了某一个类型的值,那么它只有存储的值都必须是该类型的。
sync.Once
sync.Once中包裹的函数只会执行一次。
可以作为单例的实现方式:
type StandAloneEngine struct {tasks sync.Map // key为task id,类型为string;value为task实例的指针}var instantiated *StandAloneEnginevar once sync.Oncefunc NewStandAloneEngine() *StandAloneEngine {once.Do(func() {instantiated = &StandAloneEngine{}})return instantiated}
sync.WaitGroup
类似于Java中的CountDownLatch。
通常用于等待异步任务的结束,channel也可以实现相同的效果。前者适合没有返回值的任务,后者适合有返回值的任务。
sync.Pool
存放临时值的容器,类似于对象池(Netty中的Recycler)。
- pool := sync.Pool{New: newFunc},这个用来生成新的对象,newFunc的类型为func() interface{}
- 公开指针方法Put和Get。如果Put没有调用过,且New字段被赋予了nil,则Get会返回nil。
- GC时会将临时对象池中的对象值全部移除,再次Get就会调用newFunc来创建新的对象。
sync.Map
类似于Java中的ConcurrentHashMap。原理
线程实现模型
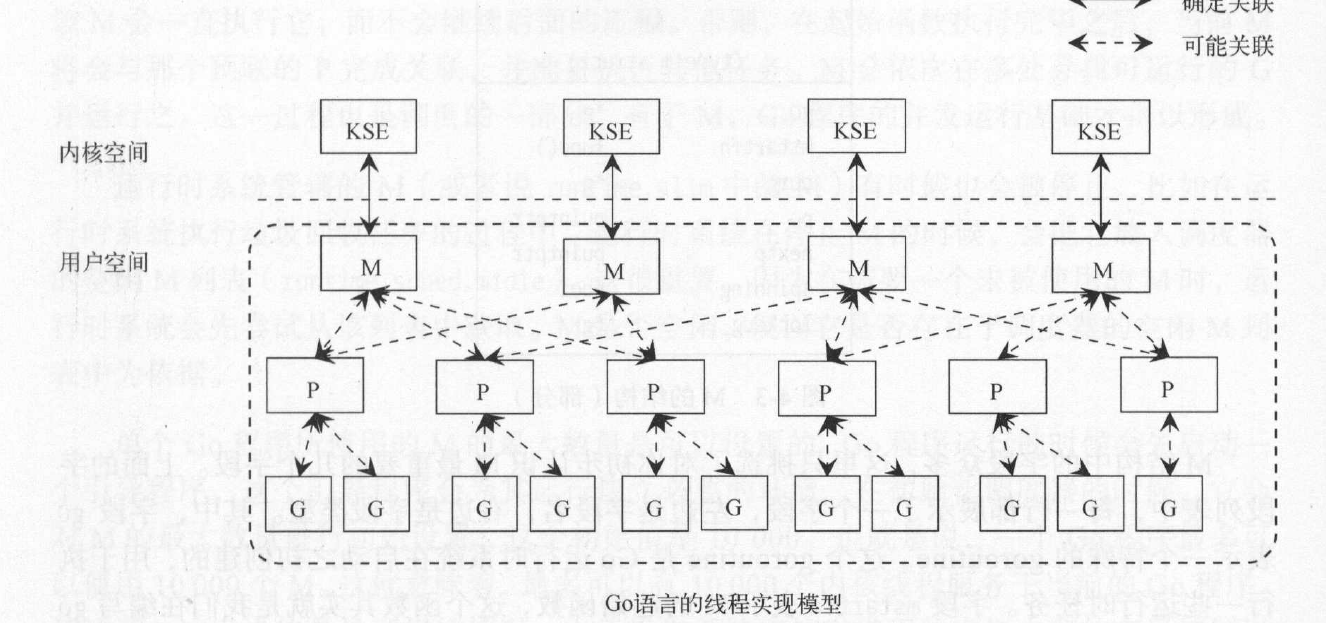
区别在于线程与内核调度实体(Kernel Scheduling Entity,KSE)之间的对应关系。这里的线程是指应用的调度单位(控制流)。用户级
线程由用户级别的线程库管理。
应用程序在对线程进行创建、终止、切换或同步等操作的时候,并不需要让OS从用户态切换到内核态。但是此模型下的多线程并不能够整呢正并发运行。如果线程阻塞,则所属进程也被阻塞。另外,即使多核,同一进程也只对应一个KSE,多个线程无法并行执行。
多个用户级线程对应一个KSE(M:1)。内核级
线程由内核负责管理,它们是内核的一部分。
进程中的每一个线程都与一个KSE对应(1:1),可以真正实现线程的并发运行。但是内核级线程的管理成本要比用户级线程高很多,线程的创建会用到更多的内核资源,并且创建、切换、同步线程的所花费的时间也会更多。两级线程模型
一个进程可以与多个KSE对应,而一个进程中可以有多个应用程序线程,这些应用程序线程可以映射到同一个已关联的KSE上。多个用户级线程对应多个KSE(M:N)。
在Go中,应用程序线程称为goroutine。
goroutine的实现
Go的线程实现模型有三个要素:
- M:machine,对应内核线程
- P:processor,一个P代表执行一个Go代码段所必需的资源(上下文)
- G:goroutine,一个G代表一个Go代码片段
一个G的执行需要P和M的支持。一个M在与一个P关联后,就形成了一个有效的G运行环境(内核线程+上下文环境)。每个P都包含一个可运行的G的队列。该队列中的G会依次传递给与本地P关联的M,并获得运行时机。
在某个时刻,M与P相互引用(一对一),P则持有一组G(一对多)。
一个M在其生命周期中,会且仅会与一个KSE蟾皮你关联,而M与P、P与G之间的关系都是易变的,它们之间的关系会在实际调度的过程中改变。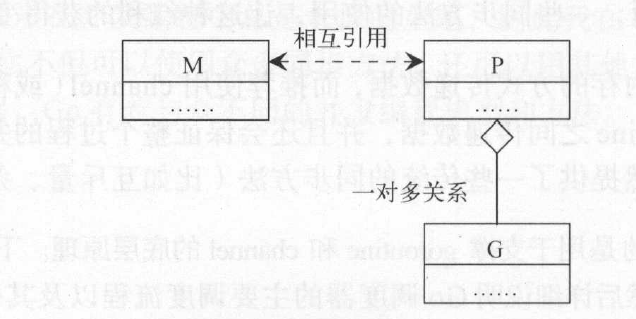
M
在大多数情况下,创建M,都是由于没有足够多的M来关联P并运行其中可运行的G。
type m struct {g0 *g // 主goroutinemstartfn func() // 起始函数,如系统监控、GC辅助或M自旋curg *g // 当前M正在运行的G的指针p puintptr // 与当前M关联的Pnextp punitptr // 暂存与当前M有潜在关联的P(预联)spining bool // 这个M是否正在寻找可运行的Glockedg *g // Go可以把一个M和一个G锁定在一起,表示与当前M锁定的那个G}
M在创建之初,会被加入全局的M列表(runtime.allm)中。创建后,进行初始化,然后执行起始函数mstartfn,之后与预联的P完成关联,并准备执行其他任务。M会依次在多处寻找可运行的G并运行它。
M有时候会停止,如执行GC。在停止时,会被放入到空闲M列表(runtime.sched.midle),之后再次需要创建M时会优先考虑复用。
单个Go程序的M最大数量是可以设置的,初始值为10000,通过runtime/debug.SetMaxThreads来设置,并且需要尽早调用。
P
P的数量即为可运行G的队列的数量。一个G在被启用后,会先被追加到某个P的可运行G队列中,以等待运行时机。一个P只有与一个M关联在一起,可运行G队列中的G才有机会运行。
当M因系统调用而阻塞(它运行的G进入了系统调用)的时候,运行时系统会把该M和与之关联的P分离开来。这时,如果这个P的可运行G队列中还有未被运行的G,那么运行时系统就会找到一个空闲M,或创建一个新的M,并与该P关联以满足这些G的运行需要。因此M的数量在很多时候都会比P多。
P的最大数量的默认为CPU核数。
与空闲M列表类似,运行时系统中也存在一个空闲P列表(runtime.sched.pidle)。当一个P不再与任何M关联的时候,运行时系统就会把它放到该列表;而当运行时系统需要一个空闲的P关联某个M的话,会从此列表取出一个。P进入空闲P列表的前提是它的可运行G列表必须为空。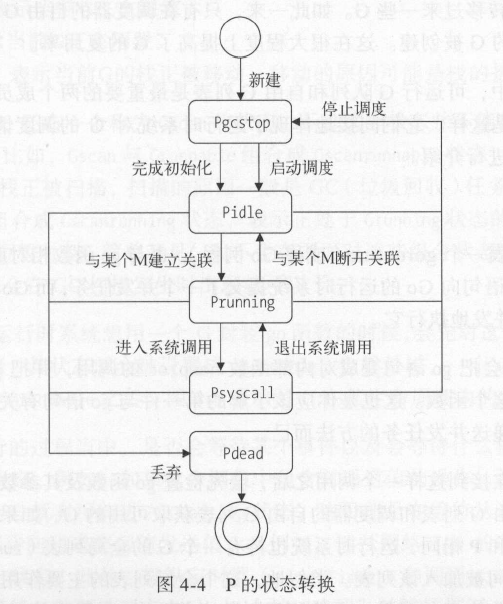
每个P中除了都有一个可运行G队列外,还都包含一个自由G列表。这个列表中包含了一些已经运行完成的G,当需要新的G的时候,优先考虑复用。当该列表增长到一定程度,运行时系统会把其中的部分G转移到调度器的自由G列表中。
G
Go的编译器会将go语句变成对内部函数newproc的调用,并把go函数及其参数都作为参数传递给这个函数。
运行时系统在接收到这样一个调用后,会:
- 先检查go函数及其参数的合法性
- 试图从本地P的自由G列表和调度器的自由G列表获取可用的G,如果没有,就创建一个G,放入到全局G列表(runtime.allgs)
- 将G存储到本地P的runnext字段中。
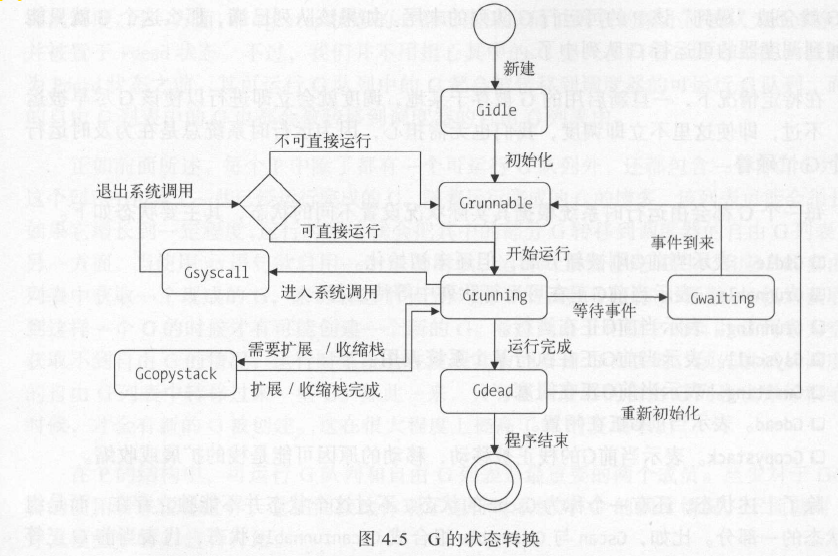
调度器的实现
一轮调度
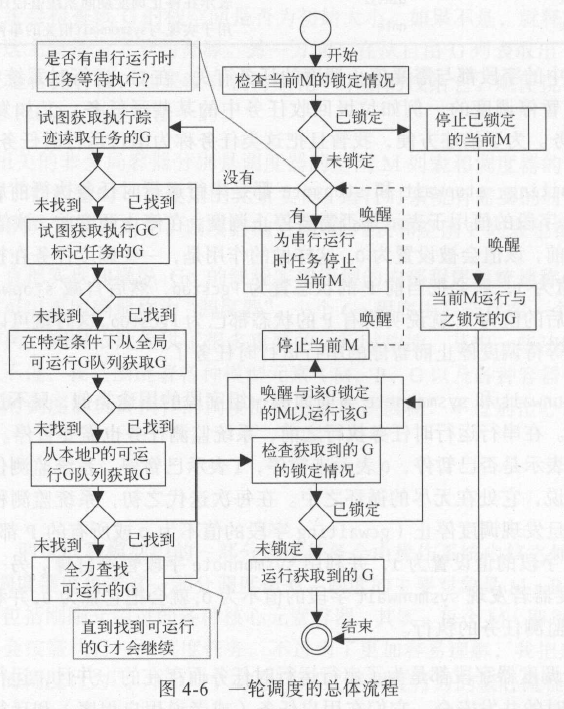
全力查找可运行的G
调度器如果没有找到可运行的G,就会进入该子流程,会多次从各处搜索可运行的G,甚至会从别的P(非本地P)哪里偷取可运行的G。

若有收获,就点个赞吧
0 人点赞
