- create.go#Action(入口)
- 1) utils.go#setUpSpec(加载spec对象)
- 2) utils_linux.go#startContainer(create、run、restore入口)
- 2.1) utils_linux.go#createContainer
- 2.1.1) libcontainer/specconv/spec_linux.go#CreateLibcontainerConfig(spec转config)
- spec
- config
- 2.1.1.1) libcontainer/specconv/spec_linux.go#createLibcontainerMount
- 2.1.1.2) libcontainer/specconv/spec_linux.go#createDevices
- 2.1.1.3) libcontainer/specconv/spec_linux.go#createDevices
- 2.1.1.4) libcontainer/specconv/spec_linux.go#setupUserNamespace
- 2.1.1.5) libcontainer/specconv/spec_linux.go#createHooks
- 2.1.2) utils_linux.go#loadFactory
- 2.1.3) libcontainer/factory_linux.go#Create
- 2.1.1) libcontainer/specconv/spec_linux.go#CreateLibcontainerConfig(spec转config)
- 2.2) utils_linux.go#runner.run(在当前container中运行一个Process)
- 2.2.1) libcontainer/container_linux.go#linuxContainer.Start
- 2.2.1.1) libcontainer/container_linux.go#linuxContainer.start
- 2.2.1.1.1) libcontainer/container_linux.go#linuxContainer.newParentProcess
- 2.2.1.1.2) 【parent】libcontainer/process_linux.go#initProcess.start
- 2.2.1.1.3) 【child】init.go#Action(容器init进程,与上一步不是顺序关系,而是异步通信)
- 2.2.1.1.4) libcontainer/container_linux.go#linuxContainer.updateState
- 2.1) utils_linux.go#createContainer
create.go#Action(入口)
1、检查对应有一个参数,即容器名
2、读取当前目录下的config.json,JSON反序列化为spec对象
3、启动容器startContainer,传入操作类型为CREATE
4、根据startContainer的返回值,退出
Action: func(context *cli.Context) error {if err := checkArgs(context, 1, exactArgs); err != nil {return err}if err := revisePidFile(context); err != nil {return err}spec, err := setupSpec(context)if err != nil {return err}status, err := startContainer(context, spec, CT_ACT_CREATE, nil)if err != nil {return err}// exit with the container's exit status so any external supervisor is// notified of the exit with the correct exit status.os.Exit(status)return nil},
1) utils.go#setUpSpec(加载spec对象)
// setupSpec performs initial setup based on the cli.Context for the containerfunc setupSpec(context *cli.Context) (*specs.Spec, error) {bundle := context.String("bundle")if bundle != "" {if err := os.Chdir(bundle); err != nil {return nil, err}}// ********************************** NOTICE ********************************** //spec, err := loadSpec(specConfig)// ********************************** NOTICE ********************************** //if err != nil {return nil, err}return spec, nil}
1.1) spec.go#loadSpec(加载config.json)
// loadSpec loads the specification from the provided path.func loadSpec(cPath string) (spec *specs.Spec, err error) {cf, err := os.Open(cPath)if err != nil {if os.IsNotExist(err) {return nil, fmt.Errorf("JSON specification file %s not found", cPath)}return nil, err}defer cf.Close()if err = json.NewDecoder(cf).Decode(&spec); err != nil {return nil, err}return spec, validateProcessSpec(spec.Process)}func validateProcessSpec(spec *specs.Process) error {if spec.Cwd == "" {return fmt.Errorf("Cwd property must not be empty")}if !filepath.IsAbs(spec.Cwd) {return fmt.Errorf("Cwd must be an absolute path")}if len(spec.Args) == 0 {return fmt.Errorf("args must not be empty")}return nil}
2) utils_linux.go#startContainer(create、run、restore入口)
1、检查容器id是否传入
2、调用createContainer方法创建一个容器
3、构造一个runner对象,并调用其run方法。
type CtAct uint8const (CT_ACT_CREATE CtAct = iota + 1CT_ACT_RUNCT_ACT_RESTORE)func startContainer(context *cli.Context, spec *specs.Spec, action CtAct, criuOpts *libcontainer.CriuOpts) (int, error) {id := context.Args().First()if id == "" {return -1, errEmptyID}notifySocket := newNotifySocket(context, os.Getenv("NOTIFY_SOCKET"), id)if notifySocket != nil {notifySocket.setupSpec(context, spec)}// ********************************** NOTICE ********************************** //container, err := createContainer(context, id, spec)// ********************************** NOTICE ********************************** //if err != nil {return -1, err}if notifySocket != nil {err := notifySocket.setupSocket()if err != nil {return -1, err}}// Support on-demand socket activation by passing file descriptors into the container init process.listenFDs := []*os.File{}if os.Getenv("LISTEN_FDS") != "" {listenFDs = activation.Files(false)}r := &runner{enableSubreaper: !context.Bool("no-subreaper"),shouldDestroy: true,container: container,listenFDs: listenFDs,notifySocket: notifySocket,consoleSocket: context.String("console-socket"),detach: context.Bool("detach"),pidFile: context.String("pid-file"),preserveFDs: context.Int("preserve-fds"),action: action,criuOpts: criuOpts,init: true,}// ********************************** NOTICE ********************************** //return r.run(spec.Process)// ********************************** NOTICE ********************************** //}
2.1) utils_linux.go#createContainer
1、将spec对象转为config对象
2、获取container的工厂对象
3、调用工厂的create方法
func createContainer(context *cli.Context, id string, spec *specs.Spec) (libcontainer.Container, error) {rootlessCg, err := shouldUseRootlessCgroupManager(context)if err != nil {return nil, err}// ********************************** NOTICE ********************************** //config, err := specconv.CreateLibcontainerConfig(&specconv.CreateOpts{CgroupName: id,UseSystemdCgroup: context.GlobalBool("systemd-cgroup"),NoPivotRoot: context.Bool("no-pivot"),NoNewKeyring: context.Bool("no-new-keyring"),Spec: spec,RootlessEUID: os.Geteuid() != 0,RootlessCgroups: rootlessCg,})// ********************************** NOTICE ********************************** //if err != nil {return nil, err}// ********************************** NOTICE ********************************** //factory, err := loadFactory(context)// ********************************** NOTICE ********************************** //if err != nil {return nil, err}// ********************************** NOTICE ********************************** //return factory.Create(id, config)// ********************************** NOTICE ********************************** //}
2.1.1) libcontainer/specconv/spec_linux.go#CreateLibcontainerConfig(spec转config)
spec
// Spec is the base configuration for the container.type Spec struct {// Version of the Open Container Initiative Runtime Specification with which the bundle complies.Version string `json:"ociVersion"`// Process configures the container process.Process *Process `json:"process,omitempty"`// Root configures the container's root filesystem.Root *Root `json:"root,omitempty"`// Hostname configures the container's hostname.Hostname string `json:"hostname,omitempty"`// Mounts configures additional mounts (on top of Root).Mounts []Mount `json:"mounts,omitempty"`// Hooks configures callbacks for container lifecycle events.Hooks *Hooks `json:"hooks,omitempty" platform:"linux,solaris"`// Annotations contains arbitrary metadata for the container.Annotations map[string]string `json:"annotations,omitempty"`// Linux is platform-specific configuration for Linux based containers.Linux *Linux `json:"linux,omitempty" platform:"linux"`// Solaris is platform-specific configuration for Solaris based containers.Solaris *Solaris `json:"solaris,omitempty" platform:"solaris"`// Windows is platform-specific configuration for Windows based containers.Windows *Windows `json:"windows,omitempty" platform:"windows"`// VM specifies configuration for virtual-machine-based containers.VM *VM `json:"vm,omitempty" platform:"vm"`}// Process contains information to start a specific application inside the container.type Process struct {// Terminal creates an interactive terminal for the container.Terminal bool `json:"terminal,omitempty"`// ConsoleSize specifies the size of the console.ConsoleSize *Box `json:"consoleSize,omitempty"`// User specifies user information for the process.User User `json:"user"`// Args specifies the binary and arguments for the application to execute.Args []string `json:"args"`// Env populates the process environment for the process.Env []string `json:"env,omitempty"`// Cwd is the current working directory for the process and must be// relative to the container's root.Cwd string `json:"cwd"`// Capabilities are Linux capabilities that are kept for the process.Capabilities *LinuxCapabilities `json:"capabilities,omitempty" platform:"linux"`// Rlimits specifies rlimit options to apply to the process.Rlimits []POSIXRlimit `json:"rlimits,omitempty" platform:"linux,solaris"`// NoNewPrivileges controls whether additional privileges could be gained by processes in the container.NoNewPrivileges bool `json:"noNewPrivileges,omitempty" platform:"linux"`// ApparmorProfile specifies the apparmor profile for the container.ApparmorProfile string `json:"apparmorProfile,omitempty" platform:"linux"`// Specify an oom_score_adj for the container.OOMScoreAdj *int `json:"oomScoreAdj,omitempty" platform:"linux"`// SelinuxLabel specifies the selinux context that the container process is run as.SelinuxLabel string `json:"selinuxLabel,omitempty" platform:"linux"`}// Linux contains platform-specific configuration for Linux based containers.type Linux struct {// UIDMapping specifies user mappings for supporting user namespaces.UIDMappings []LinuxIDMapping `json:"uidMappings,omitempty"`// GIDMapping specifies group mappings for supporting user namespaces.GIDMappings []LinuxIDMapping `json:"gidMappings,omitempty"`// Sysctl are a set of key value pairs that are set for the container on startSysctl map[string]string `json:"sysctl,omitempty"`// Resources contain cgroup information for handling resource constraints// for the containerResources *LinuxResources `json:"resources,omitempty"`// CgroupsPath specifies the path to cgroups that are created and/or joined by the container.// The path is expected to be relative to the cgroups mountpoint.// If resources are specified, the cgroups at CgroupsPath will be updated based on resources.CgroupsPath string `json:"cgroupsPath,omitempty"`// Namespaces contains the namespaces that are created and/or joined by the containerNamespaces []LinuxNamespace `json:"namespaces,omitempty"`// Devices are a list of device nodes that are created for the containerDevices []LinuxDevice `json:"devices,omitempty"`// Seccomp specifies the seccomp security settings for the container.Seccomp *LinuxSeccomp `json:"seccomp,omitempty"`// RootfsPropagation is the rootfs mount propagation mode for the container.RootfsPropagation string `json:"rootfsPropagation,omitempty"`// MaskedPaths masks over the provided paths inside the container.MaskedPaths []string `json:"maskedPaths,omitempty"`// ReadonlyPaths sets the provided paths as RO inside the container.ReadonlyPaths []string `json:"readonlyPaths,omitempty"`// MountLabel specifies the selinux context for the mounts in the container.MountLabel string `json:"mountLabel,omitempty"`// IntelRdt contains Intel Resource Director Technology (RDT) information for// handling resource constraints (e.g., L3 cache, memory bandwidth) for the containerIntelRdt *LinuxIntelRdt `json:"intelRdt,omitempty"`}
type CreateOpts struct {CgroupName stringUseSystemdCgroup boolNoPivotRoot boolNoNewKeyring boolSpec *specs.SpecRootlessEUID boolRootlessCgroups bool}// CreateLibcontainerConfig creates a new libcontainer configuration from a// given specification and a cgroup namefunc CreateLibcontainerConfig(opts *CreateOpts) (*configs.Config, error) {// runc's cwd will always be the bundle pathrcwd, err := os.Getwd()if err != nil {return nil, err}cwd, err := filepath.Abs(rcwd)if err != nil {return nil, err}spec := opts.Specif spec.Root == nil {return nil, fmt.Errorf("Root must be specified")}rootfsPath := spec.Root.Pathif !filepath.IsAbs(rootfsPath) {rootfsPath = filepath.Join(cwd, rootfsPath)}labels := []string{}for k, v := range spec.Annotations {labels = append(labels, fmt.Sprintf("%s=%s", k, v))}config := &configs.Config{Rootfs: rootfsPath,NoPivotRoot: opts.NoPivotRoot,Readonlyfs: spec.Root.Readonly,Hostname: spec.Hostname,Labels: append(labels, fmt.Sprintf("bundle=%s", cwd)),NoNewKeyring: opts.NoNewKeyring,RootlessEUID: opts.RootlessEUID,RootlessCgroups: opts.RootlessCgroups,}exists := falsefor _, m := range spec.Mounts {// ********************************** NOTICE ********************************** //config.Mounts = append(config.Mounts, createLibcontainerMount(cwd, m))// ********************************** NOTICE ********************************** //}// ********************************** NOTICE ********************************** //if err := createDevices(spec, config); err != nil {// ********************************** NOTICE ********************************** //return nil, err}// ********************************** NOTICE ********************************** //c, err := createCgroupConfig(opts)// ********************************** NOTICE ********************************** //if err != nil {return nil, err}config.Cgroups = c// set linux-specific configif spec.Linux != nil {if config.RootPropagation, exists = mountPropagationMapping[spec.Linux.RootfsPropagation]; !exists {return nil, fmt.Errorf("rootfsPropagation=%v is not supported", spec.Linux.RootfsPropagation)}if config.NoPivotRoot && (config.RootPropagation&unix.MS_PRIVATE != 0) {return nil, fmt.Errorf("rootfsPropagation of [r]private is not safe without pivot_root")}for _, ns := range spec.Linux.Namespaces {t, exists := namespaceMapping[ns.Type]if !exists {return nil, fmt.Errorf("namespace %q does not exist", ns)}if config.Namespaces.Contains(t) {return nil, fmt.Errorf("malformed spec file: duplicated ns %q", ns)}config.Namespaces.Add(t, ns.Path)}if config.Namespaces.Contains(configs.NEWNET) && config.Namespaces.PathOf(configs.NEWNET) == "" {config.Networks = []*configs.Network{{Type: "loopback",},}}if config.Namespaces.Contains(configs.NEWUSER) {if err := setupUserNamespace(spec, config); err != nil {return nil, err}}config.MaskPaths = spec.Linux.MaskedPathsconfig.ReadonlyPaths = spec.Linux.ReadonlyPathsconfig.MountLabel = spec.Linux.MountLabelconfig.Sysctl = spec.Linux.Sysctlif spec.Linux.Seccomp != nil {seccomp, err := SetupSeccomp(spec.Linux.Seccomp)if err != nil {return nil, err}config.Seccomp = seccomp}if spec.Linux.IntelRdt != nil {config.IntelRdt = &configs.IntelRdt{}if spec.Linux.IntelRdt.L3CacheSchema != "" {config.IntelRdt.L3CacheSchema = spec.Linux.IntelRdt.L3CacheSchema}if spec.Linux.IntelRdt.MemBwSchema != "" {config.IntelRdt.MemBwSchema = spec.Linux.IntelRdt.MemBwSchema}}}if spec.Process != nil {config.OomScoreAdj = spec.Process.OOMScoreAdjif spec.Process.SelinuxLabel != "" {config.ProcessLabel = spec.Process.SelinuxLabel}if spec.Process.Capabilities != nil {config.Capabilities = &configs.Capabilities{Bounding: spec.Process.Capabilities.Bounding,Effective: spec.Process.Capabilities.Effective,Permitted: spec.Process.Capabilities.Permitted,Inheritable: spec.Process.Capabilities.Inheritable,Ambient: spec.Process.Capabilities.Ambient,}}}createHooks(spec, config)config.Version = specs.Versionreturn config, nil}
config
// Config defines configuration options for executing a process inside a contained environment.type Config struct {// NoPivotRoot will use MS_MOVE and a chroot to jail the process into the container's rootfs// This is a common option when the container is running in ramdiskNoPivotRoot bool `json:"no_pivot_root"`// ParentDeathSignal specifies the signal that is sent to the container's process in the case// that the parent process dies.ParentDeathSignal int `json:"parent_death_signal"`// Path to a directory containing the container's root filesystem.Rootfs string `json:"rootfs"`// Readonlyfs will remount the container's rootfs as readonly where only externally mounted// bind mounts are writtable.Readonlyfs bool `json:"readonlyfs"`// Specifies the mount propagation flags to be applied to /.RootPropagation int `json:"rootPropagation"`// Mounts specify additional source and destination paths that will be mounted inside the container's// rootfs and mount namespace if specifiedMounts []*Mount `json:"mounts"`// The device nodes that should be automatically created within the container upon container start. Note, make sure that the node is marked as allowed in the cgroup as well!Devices []*Device `json:"devices"`MountLabel string `json:"mount_label"`// Hostname optionally sets the container's hostname if providedHostname string `json:"hostname"`// Namespaces specifies the container's namespaces that it should setup when cloning the init process// If a namespace is not provided that namespace is shared from the container's parent processNamespaces Namespaces `json:"namespaces"`// Capabilities specify the capabilities to keep when executing the process inside the container// All capabilities not specified will be dropped from the processes capability maskCapabilities *Capabilities `json:"capabilities"`// Networks specifies the container's network setup to be createdNetworks []*Network `json:"networks"`// Routes can be specified to create entries in the route table as the container is startedRoutes []*Route `json:"routes"`// Cgroups specifies specific cgroup settings for the various subsystems that the container is// placed into to limit the resources the container has availableCgroups *Cgroup `json:"cgroups"`// AppArmorProfile specifies the profile to apply to the process running in the container and is// change at the time the process is execedAppArmorProfile string `json:"apparmor_profile,omitempty"`// ProcessLabel specifies the label to apply to the process running in the container. It is// commonly used by selinuxProcessLabel string `json:"process_label,omitempty"`// Rlimits specifies the resource limits, such as max open files, to set in the container// If Rlimits are not set, the container will inherit rlimits from the parent processRlimits []Rlimit `json:"rlimits,omitempty"`// OomScoreAdj specifies the adjustment to be made by the kernel when calculating oom scores// for a process. Valid values are between the range [-1000, '1000'], where processes with// higher scores are preferred for being killed. If it is unset then we don't touch the current// value.// More information about kernel oom score calculation here: https://lwn.net/Articles/317814/OomScoreAdj *int `json:"oom_score_adj,omitempty"`// UidMappings is an array of User ID mappings for User NamespacesUidMappings []IDMap `json:"uid_mappings"`// GidMappings is an array of Group ID mappings for User NamespacesGidMappings []IDMap `json:"gid_mappings"`// MaskPaths specifies paths within the container's rootfs to mask over with a bind// mount pointing to /dev/null as to prevent reads of the file.MaskPaths []string `json:"mask_paths"`// ReadonlyPaths specifies paths within the container's rootfs to remount as read-only// so that these files prevent any writes.ReadonlyPaths []string `json:"readonly_paths"`// Sysctl is a map of properties and their values. It is the equivalent of using// sysctl -w my.property.name value in Linux.Sysctl map[string]string `json:"sysctl"`// Seccomp allows actions to be taken whenever a syscall is made within the container.// A number of rules are given, each having an action to be taken if a syscall matches it.// A default action to be taken if no rules match is also given.Seccomp *Seccomp `json:"seccomp"`// NoNewPrivileges controls whether processes in the container can gain additional privileges.NoNewPrivileges bool `json:"no_new_privileges,omitempty"`// Hooks are a collection of actions to perform at various container lifecycle events.// CommandHooks are serialized to JSON, but other hooks are not.Hooks *Hooks// Version is the version of opencontainer specification that is supported.Version string `json:"version"`// Labels are user defined metadata that is stored in the config and populated on the stateLabels []string `json:"labels"`// NoNewKeyring will not allocated a new session keyring for the container. It will use the// callers keyring in this case.NoNewKeyring bool `json:"no_new_keyring"`// IntelRdt specifies settings for Intel RDT group that the container is placed into// to limit the resources (e.g., L3 cache, memory bandwidth) the container has availableIntelRdt *IntelRdt `json:"intel_rdt,omitempty"`// RootlessEUID is set when the runc was launched with non-zero EUID.// Note that RootlessEUID is set to false when launched with EUID=0 in userns.// When RootlessEUID is set, runc creates a new userns for the container.// (config.json needs to contain userns settings)RootlessEUID bool `json:"rootless_euid,omitempty"`// RootlessCgroups is set when unlikely to have the full access to cgroups.// When RootlessCgroups is set, cgroups errors are ignored.RootlessCgroups bool `json:"rootless_cgroups,omitempty"`}
2.1.1.1) libcontainer/specconv/spec_linux.go#createLibcontainerMount
func createLibcontainerMount(cwd string, m specs.Mount) *configs.Mount {flags, pgflags, data, ext := parseMountOptions(m.Options)source := m.Sourcedevice := m.Typeif flags&unix.MS_BIND != 0 {if device == "" {device = "bind"}if !filepath.IsAbs(source) {source = filepath.Join(cwd, m.Source)}}return &configs.Mount{Device: device,Source: source,Destination: m.Destination,Data: data,Flags: flags,PropagationFlags: pgflags,Extensions: ext,}}
2.1.1.2) libcontainer/specconv/spec_linux.go#createDevices
func createDevices(spec *specs.Spec, config *configs.Config) error {// add whitelisted devicesconfig.Devices = []*configs.Device{{Type: 'c',Path: "/dev/null",Major: 1,Minor: 3,FileMode: 0666,Uid: 0,Gid: 0,},{Type: 'c',Path: "/dev/random",Major: 1,Minor: 8,FileMode: 0666,Uid: 0,Gid: 0,},{Type: 'c',Path: "/dev/full",Major: 1,Minor: 7,FileMode: 0666,Uid: 0,Gid: 0,},{Type: 'c',Path: "/dev/tty",Major: 5,Minor: 0,FileMode: 0666,Uid: 0,Gid: 0,},{Type: 'c',Path: "/dev/zero",Major: 1,Minor: 5,FileMode: 0666,Uid: 0,Gid: 0,},{Type: 'c',Path: "/dev/urandom",Major: 1,Minor: 9,FileMode: 0666,Uid: 0,Gid: 0,},}// merge in additional devices from the specif spec.Linux != nil {for _, d := range spec.Linux.Devices {var uid, gid uint32var filemode os.FileMode = 0666if d.UID != nil {uid = *d.UID}if d.GID != nil {gid = *d.GID}dt, err := stringToDeviceRune(d.Type)if err != nil {return err}if d.FileMode != nil {filemode = *d.FileMode}device := &configs.Device{Type: dt,Path: d.Path,Major: d.Major,Minor: d.Minor,FileMode: filemode,Uid: uid,Gid: gid,}config.Devices = append(config.Devices, device)}}return nil}
2.1.1.3) libcontainer/specconv/spec_linux.go#createDevices
func createCgroupConfig(opts *CreateOpts) (*configs.Cgroup, error) {var (myCgroupPath stringspec = opts.SpecuseSystemdCgroup = opts.UseSystemdCgroupname = opts.CgroupName)c := &configs.Cgroup{Resources: &configs.Resources{},}if spec.Linux != nil && spec.Linux.CgroupsPath != "" {myCgroupPath = libcontainerUtils.CleanPath(spec.Linux.CgroupsPath)if useSystemdCgroup {myCgroupPath = spec.Linux.CgroupsPath}}if useSystemdCgroup {if myCgroupPath == "" {c.Parent = "system.slice"c.ScopePrefix = "runc"c.Name = name} else {// Parse the path from expected "slice:prefix:name"// for e.g. "system.slice:docker:1234"parts := strings.Split(myCgroupPath, ":")if len(parts) != 3 {return nil, fmt.Errorf("expected cgroupsPath to be of format \"slice:prefix:name\" for systemd cgroups")}c.Parent = parts[0]c.ScopePrefix = parts[1]c.Name = parts[2]}} else {if myCgroupPath == "" {c.Name = name}c.Path = myCgroupPath}// In rootless containers, any attempt to make cgroup changes is likely to fail.// libcontainer will validate this but ignores the error.c.Resources.AllowedDevices = allowedDevicesif spec.Linux != nil {r := spec.Linux.Resourcesif r == nil {return c, nil}for i, d := range spec.Linux.Resources.Devices {var (t = "a"major = int64(-1)minor = int64(-1))if d.Type != "" {t = d.Type}if d.Major != nil {major = *d.Major}if d.Minor != nil {minor = *d.Minor}if d.Access == "" {return nil, fmt.Errorf("device access at %d field cannot be empty", i)}dt, err := stringToCgroupDeviceRune(t)if err != nil {return nil, err}dd := &configs.Device{Type: dt,Major: major,Minor: minor,Permissions: d.Access,Allow: d.Allow,}c.Resources.Devices = append(c.Resources.Devices, dd)}if r.Memory != nil {if r.Memory.Limit != nil {c.Resources.Memory = *r.Memory.Limit}if r.Memory.Reservation != nil {c.Resources.MemoryReservation = *r.Memory.Reservation}if r.Memory.Swap != nil {c.Resources.MemorySwap = *r.Memory.Swap}if r.Memory.Kernel != nil {c.Resources.KernelMemory = *r.Memory.Kernel}if r.Memory.KernelTCP != nil {c.Resources.KernelMemoryTCP = *r.Memory.KernelTCP}if r.Memory.Swappiness != nil {c.Resources.MemorySwappiness = r.Memory.Swappiness}if r.Memory.DisableOOMKiller != nil {c.Resources.OomKillDisable = *r.Memory.DisableOOMKiller}}if r.CPU != nil {if r.CPU.Shares != nil {c.Resources.CpuShares = *r.CPU.Shares}if r.CPU.Quota != nil {c.Resources.CpuQuota = *r.CPU.Quota}if r.CPU.Period != nil {c.Resources.CpuPeriod = *r.CPU.Period}if r.CPU.RealtimeRuntime != nil {c.Resources.CpuRtRuntime = *r.CPU.RealtimeRuntime}if r.CPU.RealtimePeriod != nil {c.Resources.CpuRtPeriod = *r.CPU.RealtimePeriod}if r.CPU.Cpus != "" {c.Resources.CpusetCpus = r.CPU.Cpus}if r.CPU.Mems != "" {c.Resources.CpusetMems = r.CPU.Mems}}if r.Pids != nil {c.Resources.PidsLimit = r.Pids.Limit}if r.BlockIO != nil {if r.BlockIO.Weight != nil {c.Resources.BlkioWeight = *r.BlockIO.Weight}if r.BlockIO.LeafWeight != nil {c.Resources.BlkioLeafWeight = *r.BlockIO.LeafWeight}if r.BlockIO.WeightDevice != nil {for _, wd := range r.BlockIO.WeightDevice {var weight, leafWeight uint16if wd.Weight != nil {weight = *wd.Weight}if wd.LeafWeight != nil {leafWeight = *wd.LeafWeight}weightDevice := configs.NewWeightDevice(wd.Major, wd.Minor, weight, leafWeight)c.Resources.BlkioWeightDevice = append(c.Resources.BlkioWeightDevice, weightDevice)}}if r.BlockIO.ThrottleReadBpsDevice != nil {for _, td := range r.BlockIO.ThrottleReadBpsDevice {rate := td.RatethrottleDevice := configs.NewThrottleDevice(td.Major, td.Minor, rate)c.Resources.BlkioThrottleReadBpsDevice = append(c.Resources.BlkioThrottleReadBpsDevice, throttleDevice)}}if r.BlockIO.ThrottleWriteBpsDevice != nil {for _, td := range r.BlockIO.ThrottleWriteBpsDevice {rate := td.RatethrottleDevice := configs.NewThrottleDevice(td.Major, td.Minor, rate)c.Resources.BlkioThrottleWriteBpsDevice = append(c.Resources.BlkioThrottleWriteBpsDevice, throttleDevice)}}if r.BlockIO.ThrottleReadIOPSDevice != nil {for _, td := range r.BlockIO.ThrottleReadIOPSDevice {rate := td.RatethrottleDevice := configs.NewThrottleDevice(td.Major, td.Minor, rate)c.Resources.BlkioThrottleReadIOPSDevice = append(c.Resources.BlkioThrottleReadIOPSDevice, throttleDevice)}}if r.BlockIO.ThrottleWriteIOPSDevice != nil {for _, td := range r.BlockIO.ThrottleWriteIOPSDevice {rate := td.RatethrottleDevice := configs.NewThrottleDevice(td.Major, td.Minor, rate)c.Resources.BlkioThrottleWriteIOPSDevice = append(c.Resources.BlkioThrottleWriteIOPSDevice, throttleDevice)}}}for _, l := range r.HugepageLimits {c.Resources.HugetlbLimit = append(c.Resources.HugetlbLimit, &configs.HugepageLimit{Pagesize: l.Pagesize,Limit: l.Limit,})}if r.Network != nil {if r.Network.ClassID != nil {c.Resources.NetClsClassid = *r.Network.ClassID}for _, m := range r.Network.Priorities {c.Resources.NetPrioIfpriomap = append(c.Resources.NetPrioIfpriomap, &configs.IfPrioMap{Interface: m.Name,Priority: int64(m.Priority),})}}}// append the default allowed devices to the end of the listc.Resources.Devices = append(c.Resources.Devices, allowedDevices...)return c, nil}func stringToCgroupDeviceRune(s string) (rune, error) {switch s {case "a":return 'a', nilcase "b":return 'b', nilcase "c":return 'c', nildefault:return 0, fmt.Errorf("invalid cgroup device type %q", s)}}
2.1.1.4) libcontainer/specconv/spec_linux.go#setupUserNamespace
func setupUserNamespace(spec *specs.Spec, config *configs.Config) error {create := func(m specs.LinuxIDMapping) configs.IDMap {return configs.IDMap{HostID: int(m.HostID),ContainerID: int(m.ContainerID),Size: int(m.Size),}}if spec.Linux != nil {for _, m := range spec.Linux.UIDMappings {config.UidMappings = append(config.UidMappings, create(m))}for _, m := range spec.Linux.GIDMappings {config.GidMappings = append(config.GidMappings, create(m))}}rootUID, err := config.HostRootUID()if err != nil {return err}rootGID, err := config.HostRootGID()if err != nil {return err}for _, node := range config.Devices {node.Uid = uint32(rootUID)node.Gid = uint32(rootGID)}return nil}
2.1.1.5) libcontainer/specconv/spec_linux.go#createHooks
func createHooks(rspec *specs.Spec, config *configs.Config) {config.Hooks = &configs.Hooks{}if rspec.Hooks != nil {for _, h := range rspec.Hooks.Prestart {cmd := createCommandHook(h)config.Hooks.Prestart = append(config.Hooks.Prestart, configs.NewCommandHook(cmd))}for _, h := range rspec.Hooks.Poststart {cmd := createCommandHook(h)config.Hooks.Poststart = append(config.Hooks.Poststart, configs.NewCommandHook(cmd))}for _, h := range rspec.Hooks.Poststop {cmd := createCommandHook(h)config.Hooks.Poststop = append(config.Hooks.Poststop, configs.NewCommandHook(cmd))}}}
2.1.2) utils_linux.go#loadFactory
会根据context中的信息来确定使用哪些:
- cgroupManager
- intelRdtManager
- CriuPath
- NewuidmapPath
- NewgidmapPath ```go var errEmptyID = errors.New(“container id cannot be empty”)
// loadFactory returns the configured factory instance for execing containers. func loadFactory(context *cli.Context) (libcontainer.Factory, error) { root := context.GlobalString(“root”) abs, err := filepath.Abs(root) if err != nil { return nil, err }
// We default to cgroupfs, and can only use systemd if the system is a// systemd box.cgroupManager := libcontainer.CgroupfsrootlessCg, err := shouldUseRootlessCgroupManager(context)if err != nil {return nil, err}if rootlessCg {cgroupManager = libcontainer.RootlessCgroupfs}if context.GlobalBool("systemd-cgroup") {if systemd.UseSystemd() {cgroupManager = libcontainer.SystemdCgroups} else {return nil, fmt.Errorf("systemd cgroup flag passed, but systemd support for managing cgroups is not available")}}intelRdtManager := libcontainer.IntelRdtFsif !intelrdt.IsCatEnabled() && !intelrdt.IsMbaEnabled() {intelRdtManager = nil}// We resolve the paths for {newuidmap,newgidmap} from the context of runc,// to avoid doing a path lookup in the nsexec context. TODO: The binary// names are not currently configurable.newuidmap, err := exec.LookPath("newuidmap")if err != nil {newuidmap = ""}newgidmap, err := exec.LookPath("newgidmap")if err != nil {newgidmap = ""}
// ** NOTICE ** // return libcontainer.New(abs, cgroupManager, intelRdtManager, libcontainer.CriuPath(context.GlobalString(“criu”)), libcontainer.NewuidmapPath(newuidmap), libcontainer.NewgidmapPath(newgidmap)) // ** NOTICE ** // }
<a name="4b7269a2"></a>#### 2.1.2.1) libcontainer/factory_linux.go#New```go// New returns a linux based container factory based in the root directory and// configures the factory with the provided option funcs.func New(root string, options ...func(*LinuxFactory) error) (Factory, error) {if root != "" {if err := os.MkdirAll(root, 0700); err != nil {return nil, newGenericError(err, SystemError)}}l := &LinuxFactory{Root: root,InitPath: "/proc/self/exe",InitArgs: []string{os.Args[0], "init"},Validator: validate.New(),CriuPath: "criu",}Cgroupfs(l)for _, opt := range options {if opt == nil {continue}if err := opt(l); err != nil {return nil, err}}return l, nil}// Cgroupfs is an options func to configure a LinuxFactory to return containers// that use the native cgroups filesystem implementation to create and manage// cgroups.func Cgroupfs(l *LinuxFactory) error {l.NewCgroupsManager = func(config *configs.Cgroup, paths map[string]string) cgroups.Manager {return &fs.Manager{Cgroups: config,Paths: paths,}}return nil}
2.1.3) libcontainer/factory_linux.go#Create
func (l *LinuxFactory) Create(id string, config *configs.Config) (Container, error) {if l.Root == "" {return nil, newGenericError(fmt.Errorf("invalid root"), ConfigInvalid)}if err := l.validateID(id); err != nil {return nil, err}if err := l.Validator.Validate(config); err != nil {return nil, newGenericError(err, ConfigInvalid)}containerRoot, err := securejoin.SecureJoin(l.Root, id)if err != nil {return nil, err}if _, err := os.Stat(containerRoot); err == nil {return nil, newGenericError(fmt.Errorf("container with id exists: %v", id), IdInUse)} else if !os.IsNotExist(err) {return nil, newGenericError(err, SystemError)}if err := os.MkdirAll(containerRoot, 0711); err != nil {return nil, newGenericError(err, SystemError)}if err := os.Chown(containerRoot, unix.Geteuid(), unix.Getegid()); err != nil {return nil, newGenericError(err, SystemError)}c := &linuxContainer{id: id,root: containerRoot,config: config,initPath: l.InitPath,initArgs: l.InitArgs,criuPath: l.CriuPath,newuidmapPath: l.NewuidmapPath,newgidmapPath: l.NewgidmapPath,cgroupManager: l.NewCgroupsManager(config.Cgroups, nil),}if intelrdt.IsCatEnabled() || intelrdt.IsMbaEnabled() {c.intelRdtManager = l.NewIntelRdtManager(config, id, "")}c.state = &stoppedState{c: c}return c, nil}// stoppedState represents a container is a stopped/destroyed state.type stoppedState struct {c *linuxContainer}
2.2) utils_linux.go#runner.run(在当前container中运行一个Process)
runner#action为create。
type runner struct {init boolenableSubreaper boolshouldDestroy booldetach boollistenFDs []*os.FilepreserveFDs intpidFile stringconsoleSocket stringcontainer libcontainer.Containeraction CtActnotifySocket *notifySocketcriuOpts *libcontainer.CriuOpts}
传入的Process是spec的Process。
1、首先根据spec里面process的配置信息调用newProcess创建process对象。
2、其次将listen fd加入process的环境变量和需要在新进程保持打开的文件列表中。
3、调用setupIO来处理io和tty相关配置,对于create来说,这里就是修改当前进程的io,chown用户/组权限。
4、创建一个signalHandler来处理tty和signal。
5、调用container.Start(process)来启动process进程–即进入container的阶段。
func (r *runner) run(config *specs.Process) (int, error) {if err := r.checkTerminal(config); err != nil {r.destroy()return -1, err}// ********************************** NOTICE ********************************** //// 将specs.Process转为libcontainer.Processprocess, err := newProcess(*config, r.init)// ********************************** NOTICE ********************************** //if err != nil {r.destroy()return -1, err}if len(r.listenFDs) > 0 {process.Env = append(process.Env, fmt.Sprintf("LISTEN_FDS=%d", len(r.listenFDs)), "LISTEN_PID=1")process.ExtraFiles = append(process.ExtraFiles, r.listenFDs...)}baseFd := 3 + len(process.ExtraFiles)for i := baseFd; i < baseFd+r.preserveFDs; i++ {process.ExtraFiles = append(process.ExtraFiles, os.NewFile(uintptr(i), "PreserveFD:"+strconv.Itoa(i)))}rootuid, err := r.container.Config().HostRootUID()if err != nil {r.destroy()return -1, err}rootgid, err := r.container.Config().HostRootGID()if err != nil {r.destroy()return -1, err}var (detach = r.detach || (r.action == CT_ACT_CREATE))// Setting up IO is a two stage process. We need to modify process to deal// with detaching containers, and then we get a tty after the container has// started.handler := newSignalHandler(r.enableSubreaper, r.notifySocket)// ********************************** NOTICE ********************************** //tty, err := setupIO(process, rootuid, rootgid, config.Terminal, detach, r.consoleSocket)// ********************************** NOTICE ********************************** //if err != nil {r.destroy()return -1, err}defer tty.Close()switch r.action {case CT_ACT_CREATE:// ********************************** NOTICE ********************************** //err = r.container.Start(process)// ********************************** NOTICE ********************************** //case CT_ACT_RESTORE:err = r.container.Restore(process, r.criuOpts)case CT_ACT_RUN:err = r.container.Run(process)default:panic("Unknown action")}if err != nil {r.destroy()return -1, err}if err := tty.waitConsole(); err != nil {r.terminate(process)r.destroy()return -1, err}if err = tty.ClosePostStart(); err != nil {r.terminate(process)r.destroy()return -1, err}if r.pidFile != "" {if err = createPidFile(r.pidFile, process); err != nil {r.terminate(process)r.destroy()return -1, err}}status, err := handler.forward(process, tty, detach)if err != nil {r.terminate(process)}if detach {return 0, nil}r.destroy()return status, err}// newProcess returns a new libcontainer Process with the arguments from the// spec and stdio from the current process.func newProcess(p specs.Process, init bool) (*libcontainer.Process, error) {lp := &libcontainer.Process{Args: p.Args,Env: p.Env,// TODO: fix libcontainer's API to better support uid/gid in a typesafe way.User: fmt.Sprintf("%d:%d", p.User.UID, p.User.GID),Cwd: p.Cwd,Label: p.SelinuxLabel,NoNewPrivileges: &p.NoNewPrivileges,AppArmorProfile: p.ApparmorProfile,Init: init,}if p.ConsoleSize != nil {lp.ConsoleWidth = uint16(p.ConsoleSize.Width)lp.ConsoleHeight = uint16(p.ConsoleSize.Height)}if p.Capabilities != nil {lp.Capabilities = &configs.Capabilities{}lp.Capabilities.Bounding = p.Capabilities.Boundinglp.Capabilities.Effective = p.Capabilities.Effectivelp.Capabilities.Inheritable = p.Capabilities.Inheritablelp.Capabilities.Permitted = p.Capabilities.Permittedlp.Capabilities.Ambient = p.Capabilities.Ambient}for _, gid := range p.User.AdditionalGids {lp.AdditionalGroups = append(lp.AdditionalGroups, strconv.FormatUint(uint64(gid), 10))}for _, rlimit := range p.Rlimits {rl, err := createLibContainerRlimit(rlimit)if err != nil {return nil, err}lp.Rlimits = append(lp.Rlimits, rl)}return lp, nil}// setupIO modifies the given process config according to the options.func setupIO(process *libcontainer.Process, rootuid, rootgid int, createTTY, detach bool, sockpath string) (*tty, error) {if createTTY {process.Stdin = nilprocess.Stdout = nilprocess.Stderr = nilt := &tty{}if !detach {parent, child, err := utils.NewSockPair("console")if err != nil {return nil, err}process.ConsoleSocket = childt.postStart = append(t.postStart, parent, child)t.consoleC = make(chan error, 1)go func() {if err := t.recvtty(process, parent); err != nil {t.consoleC <- err}t.consoleC <- nil}()} else {// the caller of runc will handle receiving the console masterconn, err := net.Dial("unix", sockpath)if err != nil {return nil, err}uc, ok := conn.(*net.UnixConn)if !ok {return nil, fmt.Errorf("casting to UnixConn failed")}t.postStart = append(t.postStart, uc)socket, err := uc.File()if err != nil {return nil, err}t.postStart = append(t.postStart, socket)process.ConsoleSocket = socket}return t, nil}// when runc will detach the caller provides the stdio to runc via runc's 0,1,2// and the container's process inherits runc's stdio.if detach {if err := inheritStdio(process); err != nil {return nil, err}return &tty{}, nil}return setupProcessPipes(process, rootuid, rootgid)}
2.2.1) libcontainer/container_linux.go#linuxContainer.Start
func (c *linuxContainer) Start(process *Process) error {c.m.Lock()defer c.m.Unlock()if process.Init {if err := c.createExecFifo(); err != nil {return err}}// ********************************** NOTICE ********************************** //if err := c.start(process); err != nil {// ********************************** NOTICE ********************************** //if process.Init {c.deleteExecFifo()}return err}return nil}
2.2.1.1) libcontainer/container_linux.go#linuxContainer.start
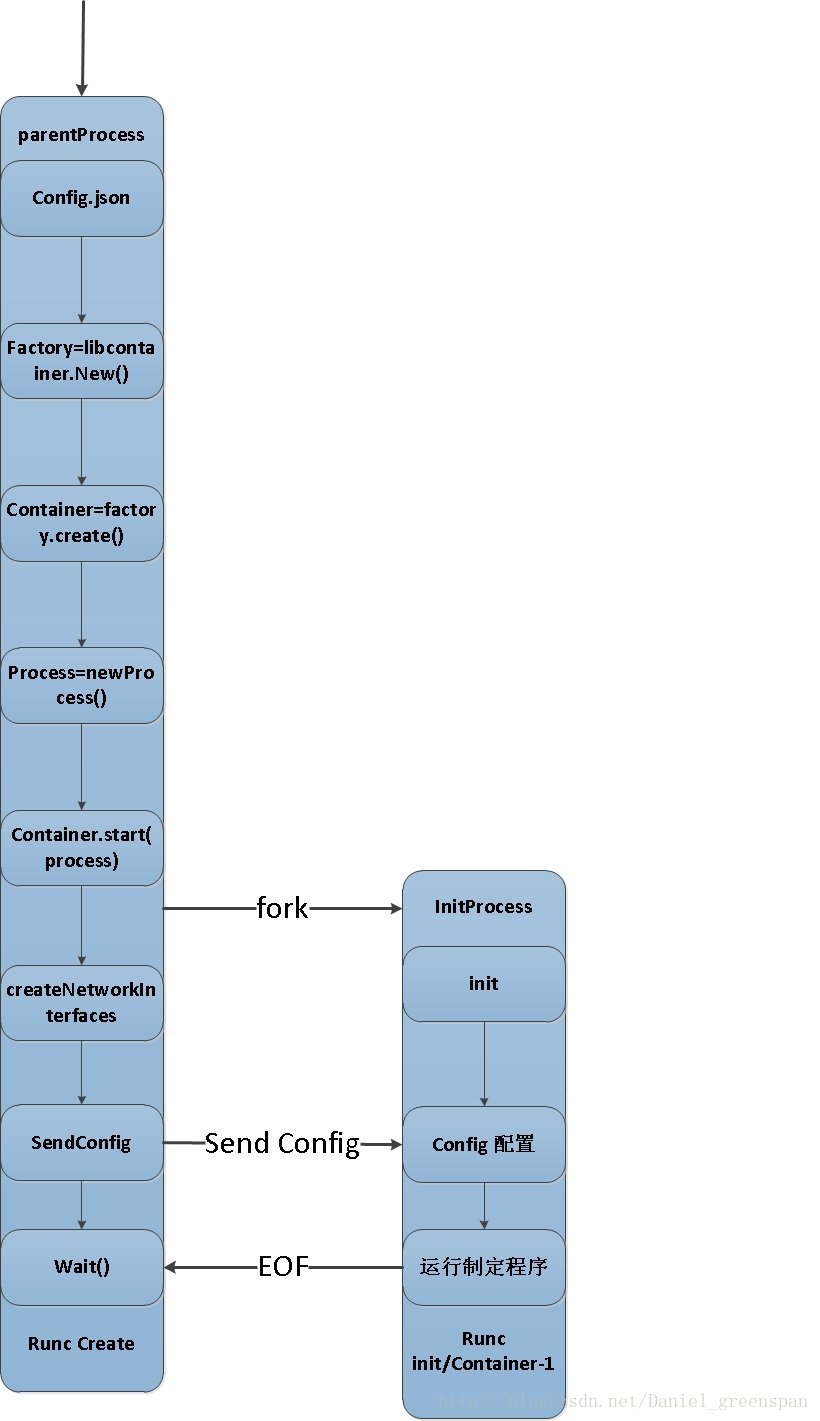
func (c *linuxContainer) start(process *Process) error {// ********************************** NOTICE ********************************** //// 启动parent进程parent, err := c.newParentProcess(process)// ********************************** NOTICE ********************************** //if err != nil {return newSystemErrorWithCause(err, "creating new parent process")}// ********************************** NOTICE ********************************** //if err := parent.start(); err != nil {// ********************************** NOTICE ********************************** //// terminate the process to ensure that it properly is reaped.if err := ignoreTerminateErrors(parent.terminate()); err != nil {logrus.Warn(err)}return newSystemErrorWithCause(err, "starting container process")}// generate a timestamp indicating when the container was startedc.created = time.Now().UTC()if process.Init {c.state = &createdState{c: c,}// ********************************** NOTICE ********************************** //// 更新statestate, err := c.updateState(parent)// ********************************** NOTICE ********************************** //if err != nil {return err}c.initProcessStartTime = state.InitProcessStartTimeif c.config.Hooks != nil {s, err := c.currentOCIState()if err != nil {return err}for i, hook := range c.config.Hooks.Poststart {if err := hook.Run(s); err != nil {if err := ignoreTerminateErrors(parent.terminate()); err != nil {logrus.Warn(err)}return newSystemErrorWithCausef(err, "running poststart hook %d", i)}}}}return nil}
2.2.1.1.1) libcontainer/container_linux.go#linuxContainer.newParentProcess
创建一个initProcess,里面既有init进程的信息,也有spec里面指定的process的信息。
1、创建一对pipe——parentPipe和childPipe,打开rootDir。
2、创建一个command,命令为runc init自身(通过/proc/self/exe软链接实现);标准io为当前进程的;工作目录为Rootfs;用ExtraFiles在新进程中保持打开childPipe和rootDir,并添加对应的环境变量。
3、调用newInitProcess进一步将parent process和command封装为initProcess。主要工作为添加初始化类型环境变量,将namespace、uid/gid映射等配置信息用bootstrapData封装为一个io.Reader等。
parentProcess是一个接口类型。
func (c *linuxContainer) newParentProcess(p *Process) (parentProcess, error) {parentPipe, childPipe, err := utils.NewSockPair("init")if err != nil {return nil, newSystemErrorWithCause(err, "creating new init pipe")}// ********************************** NOTICE ********************************** //cmd, err := c.commandTemplate(p, childPipe)// ********************************** NOTICE ********************************** //if err != nil {return nil, newSystemErrorWithCause(err, "creating new command template")}if !p.Init {return c.newSetnsProcess(p, cmd, parentPipe, childPipe)}// We only set up fifoFd if we're not doing a `runc exec`. The historic// reason for this is that previously we would pass a dirfd that allowed// for container rootfs escape (and not doing it in `runc exec` avoided// that problem), but we no longer do that. However, there's no need to do// this for `runc exec` so we just keep it this way to be safe.if err := c.includeExecFifo(cmd); err != nil {return nil, newSystemErrorWithCause(err, "including execfifo in cmd.Exec setup")}// ********************************** NOTICE ********************************** //return c.newInitProcess(p, cmd, parentPipe, childPipe)// ********************************** NOTICE ********************************** //}
2.2.1.1.1.1) libcontainer/container_linux.go#linuxContainer.commandTemplate
这里的initPath、initArgs是:
InitPath: “/proc/self/exe”,
InitArgs: []string{os.Args[0], “init”},
func (c *linuxContainer) commandTemplate(p *Process, childPipe *os.File) (*exec.Cmd, error) {cmd := exec.Command(c.initPath, c.initArgs[1:]...)cmd.Args[0] = c.initArgs[0]cmd.Stdin = p.Stdincmd.Stdout = p.Stdoutcmd.Stderr = p.Stderrcmd.Dir = c.config.Rootfsif cmd.SysProcAttr == nil {cmd.SysProcAttr = &syscall.SysProcAttr{}}cmd.Env = append(cmd.Env, fmt.Sprintf("GOMAXPROCS=%s", os.Getenv("GOMAXPROCS")))cmd.ExtraFiles = append(cmd.ExtraFiles, p.ExtraFiles...)if p.ConsoleSocket != nil {cmd.ExtraFiles = append(cmd.ExtraFiles, p.ConsoleSocket)cmd.Env = append(cmd.Env,fmt.Sprintf("_LIBCONTAINER_CONSOLE=%d", stdioFdCount+len(cmd.ExtraFiles)-1),)}cmd.ExtraFiles = append(cmd.ExtraFiles, childPipe)cmd.Env = append(cmd.Env,fmt.Sprintf("_LIBCONTAINER_INITPIPE=%d", stdioFdCount+len(cmd.ExtraFiles)-1),)// NOTE: when running a container with no PID namespace and the parent process spawning the container is// PID1 the pdeathsig is being delivered to the container's init process by the kernel for some reason// even with the parent still running.if c.config.ParentDeathSignal > 0 {cmd.SysProcAttr.Pdeathsig = syscall.Signal(c.config.ParentDeathSignal)}return cmd, nil}
2.2.1.1.1.2) libcontainer/container_linux.go#linuxContainer.newInitProcess
调用newInitProcess进一步将parent process和command封装为initProcess。主要工作为添加初始化类型环境变量,将namespace、uid/gid映射等配置信息用bootstrapData封装为一个io.Reader等。
func (c *linuxContainer) newInitProcess(p *Process, cmd *exec.Cmd, parentPipe, childPipe *os.File) (*initProcess, error) {cmd.Env = append(cmd.Env, "_LIBCONTAINER_INITTYPE="+string(initStandard))nsMaps := make(map[configs.NamespaceType]string)for _, ns := range c.config.Namespaces {if ns.Path != "" {nsMaps[ns.Type] = ns.Path}}_, sharePidns := nsMaps[configs.NEWPID]// ********************************** NOTICE ********************************** //data, err := c.bootstrapData(c.config.Namespaces.CloneFlags(), nsMaps)// ********************************** NOTICE ********************************** //if err != nil {return nil, err}init := &initProcess{cmd: cmd,childPipe: childPipe,parentPipe: parentPipe,manager: c.cgroupManager,intelRdtManager: c.intelRdtManager,// ********************************** NOTICE ********************************** //config: c.newInitConfig(p),// ********************************** NOTICE ********************************** //container: c,process: p,bootstrapData: data,sharePidns: sharePidns,}c.initProcess = initreturn init, nil}
2.2.1.1.1.2.1) libcontainer/container_linux.go#linuxContainer.bootstrapData(发给init进程的数据)
// bootstrapData encodes the necessary data in netlink binary format// as a io.Reader.// Consumer can write the data to a bootstrap program// such as one that uses nsenter package to bootstrap the container's// init process correctly, i.e. with correct namespaces, uid/gid// mapping etc.func (c *linuxContainer) bootstrapData(cloneFlags uintptr, nsMaps map[configs.NamespaceType]string) (io.Reader, error) {// create the netlink messager := nl.NewNetlinkRequest(int(InitMsg), 0)// write cloneFlagsr.AddData(&Int32msg{Type: CloneFlagsAttr,Value: uint32(cloneFlags),})// write custom namespace pathsif len(nsMaps) > 0 {nsPaths, err := c.orderNamespacePaths(nsMaps)if err != nil {return nil, err}r.AddData(&Bytemsg{Type: NsPathsAttr,Value: []byte(strings.Join(nsPaths, ",")),})}// write namespace paths only when we are not joining an existing user ns_, joinExistingUser := nsMaps[configs.NEWUSER]if !joinExistingUser {// write uid mappingsif len(c.config.UidMappings) > 0 {if c.config.RootlessEUID && c.newuidmapPath != "" {r.AddData(&Bytemsg{Type: UidmapPathAttr,Value: []byte(c.newuidmapPath),})}b, err := encodeIDMapping(c.config.UidMappings)if err != nil {return nil, err}r.AddData(&Bytemsg{Type: UidmapAttr,Value: b,})}// write gid mappingsif len(c.config.GidMappings) > 0 {b, err := encodeIDMapping(c.config.GidMappings)if err != nil {return nil, err}r.AddData(&Bytemsg{Type: GidmapAttr,Value: b,})if c.config.RootlessEUID && c.newgidmapPath != "" {r.AddData(&Bytemsg{Type: GidmapPathAttr,Value: []byte(c.newgidmapPath),})}if requiresRootOrMappingTool(c.config) {r.AddData(&Boolmsg{Type: SetgroupAttr,Value: true,})}}}if c.config.OomScoreAdj != nil {// write oom_score_adjr.AddData(&Bytemsg{Type: OomScoreAdjAttr,Value: []byte(fmt.Sprintf("%d", *c.config.OomScoreAdj)),})}// write rootlessr.AddData(&Boolmsg{Type: RootlessEUIDAttr,Value: c.config.RootlessEUID,})return bytes.NewReader(r.Serialize()), nil}
2.2.1.1.1.2.2) libcontainer/container_linux.go#linuxContainer.newInitConfig(Process转initConfig)
func (c *linuxContainer) newInitConfig(process *Process) *initConfig {cfg := &initConfig{Config: c.config,Args: process.Args,Env: process.Env,User: process.User,AdditionalGroups: process.AdditionalGroups,Cwd: process.Cwd,Capabilities: process.Capabilities,PassedFilesCount: len(process.ExtraFiles),ContainerId: c.ID(),NoNewPrivileges: c.config.NoNewPrivileges,RootlessEUID: c.config.RootlessEUID,RootlessCgroups: c.config.RootlessCgroups,AppArmorProfile: c.config.AppArmorProfile,ProcessLabel: c.config.ProcessLabel,Rlimits: c.config.Rlimits,}if process.NoNewPrivileges != nil {cfg.NoNewPrivileges = *process.NoNewPrivileges}if process.AppArmorProfile != "" {cfg.AppArmorProfile = process.AppArmorProfile}if process.Label != "" {cfg.ProcessLabel = process.Label}if len(process.Rlimits) > 0 {cfg.Rlimits = process.Rlimits}cfg.CreateConsole = process.ConsoleSocket != nilcfg.ConsoleWidth = process.ConsoleWidthcfg.ConsoleHeight = process.ConsoleHeightreturn cfg}
2.2.1.1.2) 【parent】libcontainer/process_linux.go#initProcess.start
1、异步启动cmd.Start()(等同于调用runc init)来启动init进程。
2、将spec中process指定的ops指定为initProcess。
3、将前面创建bootstrapData从parentPipe传出去(init进程会从childPipe接收到这些数据,reverse出写入的内容,进行namespace相关的配置)
4、调用execSetns(),这个方法名看似是进行namespace的配置,实际上则是等待上面init进程的执行,并在parentPipe等待并解析出从childPipe传回的pid(谁的pid),找到该pid对应的进程,并将cmd.Process对应的进程替换为该进程。
5、为checkpoint做准备,保存cmd.Process进程的标准IO文件描述符。
6、应用cgroup配置
7、创建容器中的network interface。
8、将容器的配置文件内容spec从parentPipe发送给init进程。
9、下面与init进程进行同步,一个for循环状态机,通过解析parentPipe传回的sync Type来执行相应的操作。按正常的时间顺序,如下:
procReady,继续配置cgroup(Set与Apply的区别?)、oom、rlimits;如果配置中没有mount namespace(Why?),则执行prestart钩子;往parentPipe写入procRun状态。
procHooks,执行prestart钩子,往parentPipe写入procResume状态。(这个应该不是标准create的流程,resume?)
procError,just error and exit
10、进行一些是否成功run和resume的判断,进行错误处理。
11、关闭parentPipe,返回nil or err。
func (p *initProcess) start() error {defer p.parentPipe.Close()err := p.cmd.Start()p.process.ops = pp.childPipe.Close()if err != nil {p.process.ops = nilreturn newSystemErrorWithCause(err, "starting init process command")}// Do this before syncing with child so that no children can escape the// cgroup. We don't need to worry about not doing this and not being root// because we'd be using the rootless cgroup manager in that case.if err := p.manager.Apply(p.pid()); err != nil {return newSystemErrorWithCause(err, "applying cgroup configuration for process")}if p.intelRdtManager != nil {if err := p.intelRdtManager.Apply(p.pid()); err != nil {return newSystemErrorWithCause(err, "applying Intel RDT configuration for process")}}defer func() {if err != nil {// TODO: should not be the responsibility to call herep.manager.Destroy()if p.intelRdtManager != nil {p.intelRdtManager.Destroy()}}}()if _, err := io.Copy(p.parentPipe, p.bootstrapData); err != nil {return newSystemErrorWithCause(err, "copying bootstrap data to pipe")}childPid, err := p.getChildPid()if err != nil {return newSystemErrorWithCause(err, "getting the final child's pid from pipe")}// Save the standard descriptor names before the container process// can potentially move them (e.g., via dup2()). If we don't do this now,// we won't know at checkpoint time which file descriptor to look up.fds, err := getPipeFds(childPid)if err != nil {return newSystemErrorWithCausef(err, "getting pipe fds for pid %d", childPid)}p.setExternalDescriptors(fds)// Do this before syncing with child so that no children// can escape the cgroupif err := p.manager.Apply(childPid); err != nil {return newSystemErrorWithCause(err, "applying cgroup configuration for process")}if p.intelRdtManager != nil {if err := p.intelRdtManager.Apply(childPid); err != nil {return newSystemErrorWithCause(err, "applying Intel RDT configuration for process")}}// Now it's time to setup cgroup namesapceif p.config.Config.Namespaces.Contains(configs.NEWCGROUP) && p.config.Config.Namespaces.PathOf(configs.NEWCGROUP) == "" {if _, err := p.parentPipe.Write([]byte{createCgroupns}); err != nil {return newSystemErrorWithCause(err, "sending synchronization value to init process")}}// Wait for our first child to exitif err := p.waitForChildExit(childPid); err != nil {return newSystemErrorWithCause(err, "waiting for our first child to exit")}defer func() {if err != nil {// TODO: should not be the responsibility to call herep.manager.Destroy()}}()if err := p.createNetworkInterfaces(); err != nil {return newSystemErrorWithCause(err, "creating network interfaces")}if err := p.sendConfig(); err != nil {return newSystemErrorWithCause(err, "sending config to init process")}var (sentRun boolsentResume bool)ierr := parseSync(p.parentPipe, func(sync *syncT) error {switch sync.Type {case procReady:// set rlimits, this has to be done here because we lose permissions// to raise the limits once we enter a user-namespaceif err := setupRlimits(p.config.Rlimits, p.pid()); err != nil {return newSystemErrorWithCause(err, "setting rlimits for ready process")}// call prestart hooksif !p.config.Config.Namespaces.Contains(configs.NEWNS) {// Setup cgroup before prestart hook, so that the prestart hook could apply cgroup permissions.if err := p.manager.Set(p.config.Config); err != nil {return newSystemErrorWithCause(err, "setting cgroup config for ready process")}if p.intelRdtManager != nil {if err := p.intelRdtManager.Set(p.config.Config); err != nil {return newSystemErrorWithCause(err, "setting Intel RDT config for ready process")}}if p.config.Config.Hooks != nil {s, err := p.container.currentOCIState()if err != nil {return err}// initProcessStartTime hasn't been set yet.s.Pid = p.cmd.Process.Pids.Status = "creating"for i, hook := range p.config.Config.Hooks.Prestart {if err := hook.Run(s); err != nil {return newSystemErrorWithCausef(err, "running prestart hook %d", i)}}}}// Sync with child.if err := writeSync(p.parentPipe, procRun); err != nil {return newSystemErrorWithCause(err, "writing syncT 'run'")}sentRun = truecase procHooks:// Setup cgroup before prestart hook, so that the prestart hook could apply cgroup permissions.if err := p.manager.Set(p.config.Config); err != nil {return newSystemErrorWithCause(err, "setting cgroup config for procHooks process")}if p.intelRdtManager != nil {if err := p.intelRdtManager.Set(p.config.Config); err != nil {return newSystemErrorWithCause(err, "setting Intel RDT config for procHooks process")}}if p.config.Config.Hooks != nil {s, err := p.container.currentOCIState()if err != nil {return err}// initProcessStartTime hasn't been set yet.s.Pid = p.cmd.Process.Pids.Status = "creating"for i, hook := range p.config.Config.Hooks.Prestart {if err := hook.Run(s); err != nil {return newSystemErrorWithCausef(err, "running prestart hook %d", i)}}}// Sync with child.if err := writeSync(p.parentPipe, procResume); err != nil {return newSystemErrorWithCause(err, "writing syncT 'resume'")}sentResume = truedefault:return newSystemError(fmt.Errorf("invalid JSON payload from child"))}return nil})if !sentRun {return newSystemErrorWithCause(ierr, "container init")}if p.config.Config.Namespaces.Contains(configs.NEWNS) && !sentResume {return newSystemError(fmt.Errorf("could not synchronise after executing prestart hooks with container process"))}if err := unix.Shutdown(int(p.parentPipe.Fd()), unix.SHUT_WR); err != nil {return newSystemErrorWithCause(err, "shutting down init pipe")}// Must be done after Shutdown so the child will exit and we can wait for it.if ierr != nil {p.wait()return ierr}return nil}
2.2.1.1.2.1) libcontainer/process_linux.go#initProcess.createNetworkInterfaces
func (p *initProcess) createNetworkInterfaces() error {for _, config := range p.config.Config.Networks {strategy, err := getStrategy(config.Type)if err != nil {return err}n := &network{Network: *config,}if err := strategy.create(n, p.pid()); err != nil {return err}p.config.Networks = append(p.config.Networks, n)}return nil}
2.2.1.1.2.2) libcontainer/process_linux.go#initProcess.sendConfig
func (p *initProcess) sendConfig() error {// send the config to the container's init process, we don't use JSON Encode// here because there might be a problem in JSON decoder in some cases, see:// https://github.com/docker/docker/issues/14203#issuecomment-174177790return utils.WriteJSON(p.parentPipe, p.config)}
2.2.1.1.3) 【child】init.go#Action(容器init进程,与上一步不是顺序关系,而是异步通信)
2.2.1.1.3.1) libcontainer/nsenter/nsenter.go#nsexec
在init.go文件中有一行:_ "github.com/opencontainers/runc/libcontainer/nsenter"
// +build linux,!gccgopackage nsenter/*#cgo CFLAGS: -Wallextern void nsexec();void __attribute__((constructor)) init(void) {nsexec();}*/import "C"
nsenter
The nsenter package registers a special init constructor that is called before
the Go runtime has a chance to boot. This provides us the ability to setns on
existing namespaces and avoid the issues that the Go runtime has with multiple
threads. This constructor will be called if this package is registered,
imported, in your go application.
The nsenter package will import "C" and it uses cgo
package. In cgo, if the import of “C” is immediately preceded by a comment, that comment,
called the preamble, is used as a header when compiling the C parts of the package.
So every time we import package nsenter, the C code function nsexec() would be
called. And package nsenter is only imported in init.go, so every time the runc
init command is invoked, that C code is run.
Because nsexec() must be run before the Go runtime in order to use the
Linux kernel namespace, you must import this library into a package if
you plan to use libcontainer directly. Otherwise Go will not execute
the nsexec() constructor, which means that the re-exec will not cause
the namespaces to be joined. You can import it like this:
import _ "github.com/opencontainers/runc/libcontainer/nsenter"
nsexec() will first get the file descriptor number for the init pipe
from the environment variable _LIBCONTAINER_INITPIPE (which was opened
by the parent and kept open across the fork-exec of the nsexec() init
process). The init pipe is used to read bootstrap data (namespace paths,
clone flags, uid and gid mappings, and the console path) from the parent
process. nsexec() will then call setns(2) to join the namespaces
provided in the bootstrap data (if available), clone(2) a child process
with the provided clone flags, update the user and group ID mappings, do
some further miscellaneous setup steps, and then send the PID of the
child process to the parent of the nsexec() “caller”. Finally,
the parent nsexec() will exit and the child nsexec() process will
return to allow the Go runtime take over.
NOTE: We do both setns(2) and clone(2) even if we don’t have any
CLONE_NEW* clone flags because we must fork a new process in order to
enter the PID namespace.
2.2.1.1.3.1.1) libcontainer/nsenter/nsexec.c
1、拿到childPipe(根据环境变量)
2、读取bootstrapData,C中的数据结构如下:
struct nlconfig_t {char *data;/* Process settings. */uint32_t cloneflags;char *oom_score_adj;size_t oom_score_adj_len;/* User namespace settings. */char *uidmap;size_t uidmap_len;char *gidmap;size_t gidmap_len;char *namespaces;size_t namespaces_len;uint8_t is_setgroup;/* Rootless container settings. */uint8_t is_rootless_euid; /* boolean */char *uidmappath;size_t uidmappath_len;char *gidmappath;size_t gidmappath_len;};
3、runc中命名空间隔离的实现文件nsexec.c 发现并没有简单实用clone实现。而是因为selinux问题,内核版本等问题,并没有简单使用clone实现,而是配合其他namespace API实现
Namespace API提供了三种系统调用接口:
● clone():创建新的进程
● setns():允许指定进程加入特定的namespace
● unshare():将指定进程移除指定的namespace
nsexec.c分别使用这三种接口,对于一般新建命名空间,使用unshare()实现;对于已有的命名空间,使用setns()实现。

void nsexec(void){int pipenum;jmp_buf env;int sync_child_pipe[2], sync_grandchild_pipe[2];struct nlconfig_t config = { 0 };/** If we don't have an init pipe, just return to the go routine.* We'll only get an init pipe for start or exec.*/pipenum = initpipe();if (pipenum == -1)return;/* Parse all of the netlink configuration. */nl_parse(pipenum, &config);/* Set oom_score_adj. This has to be done before !dumpable because* /proc/self/oom_score_adj is not writeable unless you're an privileged* user (if !dumpable is set). All children inherit their parent's* oom_score_adj value on fork(2) so this will always be propagated* properly.*/update_oom_score_adj(config.oom_score_adj, config.oom_score_adj_len);/** Make the process non-dumpable, to avoid various race conditions that* could cause processes in namespaces we're joining to access host* resources (or potentially execute code).** However, if the number of namespaces we are joining is 0, we are not* going to be switching to a different security context. Thus setting* ourselves to be non-dumpable only breaks things (like rootless* containers), which is the recommendation from the kernel folks.*/if (config.namespaces) {if (prctl(PR_SET_DUMPABLE, 0, 0, 0, 0) < 0)bail("failed to set process as non-dumpable");}/* Pipe so we can tell the child when we've finished setting up. */if (socketpair(AF_LOCAL, SOCK_STREAM, 0, sync_child_pipe) < 0)bail("failed to setup sync pipe between parent and child");/** We need a new socketpair to sync with grandchild so we don't have* race condition with child.*/if (socketpair(AF_LOCAL, SOCK_STREAM, 0, sync_grandchild_pipe) < 0)bail("failed to setup sync pipe between parent and grandchild");/* TODO: Currently we aren't dealing with child deaths properly. *//** Okay, so this is quite annoying.** In order for this unsharing code to be more extensible we need to split* up unshare(CLONE_NEWUSER) and clone() in various ways. The ideal case* would be if we did clone(CLONE_NEWUSER) and the other namespaces* separately, but because of SELinux issues we cannot really do that. But* we cannot just dump the namespace flags into clone(...) because several* usecases (such as rootless containers) require more granularity around* the namespace setup. In addition, some older kernels had issues where* CLONE_NEWUSER wasn't handled before other namespaces (but we cannot* handle this while also dealing with SELinux so we choose SELinux support* over broken kernel support).** However, if we unshare(2) the user namespace *before* we clone(2), then* all hell breaks loose.** The parent no longer has permissions to do many things (unshare(2) drops* all capabilities in your old namespace), and the container cannot be set* up to have more than one {uid,gid} mapping. This is obviously less than* ideal. In order to fix this, we have to first clone(2) and then unshare.** Unfortunately, it's not as simple as that. We have to fork to enter the* PID namespace (the PID namespace only applies to children). Since we'll* have to double-fork, this clone_parent() call won't be able to get the* PID of the _actual_ init process (without doing more synchronisation than* I can deal with at the moment). So we'll just get the parent to send it* for us, the only job of this process is to update* /proc/pid/{setgroups,uid_map,gid_map}.** And as a result of the above, we also need to setns(2) in the first child* because if we join a PID namespace in the topmost parent then our child* will be in that namespace (and it will not be able to give us a PID value* that makes sense without resorting to sending things with cmsg).** This also deals with an older issue caused by dumping cloneflags into* clone(2): On old kernels, CLONE_PARENT didn't work with CLONE_NEWPID, so* we have to unshare(2) before clone(2) in order to do this. This was fixed* in upstream commit 1f7f4dde5c945f41a7abc2285be43d918029ecc5, and was* introduced by 40a0d32d1eaffe6aac7324ca92604b6b3977eb0e. As far as we're* aware, the last mainline kernel which had this bug was Linux 3.12.* However, we cannot comment on which kernels the broken patch was* backported to.** -- Aleksa "what has my life come to?" Sarai*/switch (setjmp(env)) {/** Stage 0: We're in the parent. Our job is just to create a new child* (stage 1: JUMP_CHILD) process and write its uid_map and* gid_map. That process will go on to create a new process, then* it will send us its PID which we will send to the bootstrap* process.*/case JUMP_PARENT:{int len;pid_t child, first_child = -1;bool ready = false;/* For debugging. */prctl(PR_SET_NAME, (unsigned long)"runc:[0:PARENT]", 0, 0, 0);/* Start the process of getting a container. */child = clone_parent(&env, JUMP_CHILD);if (child < 0)bail("unable to fork: child_func");/** State machine for synchronisation with the children.** Father only return when both child and grandchild are* ready, so we can receive all possible error codes* generated by children.*/while (!ready) {enum sync_t s;int ret;syncfd = sync_child_pipe[1];close(sync_child_pipe[0]);if (read(syncfd, &s, sizeof(s)) != sizeof(s))bail("failed to sync with child: next state");switch (s) {case SYNC_ERR:/* We have to mirror the error code of the child. */if (read(syncfd, &ret, sizeof(ret)) != sizeof(ret))bail("failed to sync with child: read(error code)");exit(ret);case SYNC_USERMAP_PLS:/** Enable setgroups(2) if we've been asked to. But we also* have to explicitly disable setgroups(2) if we're* creating a rootless container for single-entry mapping.* i.e. config.is_setgroup == false.* (this is required since Linux 3.19).** For rootless multi-entry mapping, config.is_setgroup shall be true and* newuidmap/newgidmap shall be used.*/if (config.is_rootless_euid && !config.is_setgroup)update_setgroups(child, SETGROUPS_DENY);/* Set up mappings. */update_uidmap(config.uidmappath, child, config.uidmap, config.uidmap_len);update_gidmap(config.gidmappath, child, config.gidmap, config.gidmap_len);s = SYNC_USERMAP_ACK;if (write(syncfd, &s, sizeof(s)) != sizeof(s)) {kill(child, SIGKILL);bail("failed to sync with child: write(SYNC_USERMAP_ACK)");}break;case SYNC_RECVPID_PLS:{first_child = child;/* Get the init_func pid. */if (read(syncfd, &child, sizeof(child)) != sizeof(child)) {kill(first_child, SIGKILL);bail("failed to sync with child: read(childpid)");}/* Send ACK. */s = SYNC_RECVPID_ACK;if (write(syncfd, &s, sizeof(s)) != sizeof(s)) {kill(first_child, SIGKILL);kill(child, SIGKILL);bail("failed to sync with child: write(SYNC_RECVPID_ACK)");}/* Send the init_func pid back to our parent.** Send the init_func pid and the pid of the first child back to our parent.* We need to send both back because we can't reap the first child we created (CLONE_PARENT).* It becomes the responsibility of our parent to reap the first child.*/len = dprintf(pipenum, "{\"pid\": %d, \"pid_first\": %d}\n", child, first_child);if (len < 0) {kill(child, SIGKILL);bail("unable to generate JSON for child pid");}}break;case SYNC_CHILD_READY:ready = true;break;default:bail("unexpected sync value: %u", s);}}/* Now sync with grandchild. */ready = false;while (!ready) {enum sync_t s;int ret;syncfd = sync_grandchild_pipe[1];close(sync_grandchild_pipe[0]);s = SYNC_GRANDCHILD;if (write(syncfd, &s, sizeof(s)) != sizeof(s)) {kill(child, SIGKILL);bail("failed to sync with child: write(SYNC_GRANDCHILD)");}if (read(syncfd, &s, sizeof(s)) != sizeof(s))bail("failed to sync with child: next state");switch (s) {case SYNC_ERR:/* We have to mirror the error code of the child. */if (read(syncfd, &ret, sizeof(ret)) != sizeof(ret))bail("failed to sync with child: read(error code)");exit(ret);case SYNC_CHILD_READY:ready = true;break;default:bail("unexpected sync value: %u", s);}}exit(0);}/** Stage 1: We're in the first child process. Our job is to join any* provided namespaces in the netlink payload and unshare all* of the requested namespaces. If we've been asked to* CLONE_NEWUSER, we will ask our parent (stage 0) to set up* our user mappings for us. Then, we create a new child* (stage 2: JUMP_INIT) for PID namespace. We then send the* child's PID to our parent (stage 0).*/case JUMP_CHILD:{pid_t child;enum sync_t s;/* We're in a child and thus need to tell the parent if we die. */syncfd = sync_child_pipe[0];close(sync_child_pipe[1]);/* For debugging. */prctl(PR_SET_NAME, (unsigned long)"runc:[1:CHILD]", 0, 0, 0);/** We need to setns first. We cannot do this earlier (in stage 0)* because of the fact that we forked to get here (the PID of* [stage 2: JUMP_INIT]) would be meaningless). We could send it* using cmsg(3) but that's just annoying.*/if (config.namespaces)join_namespaces(config.namespaces);/** Deal with user namespaces first. They are quite special, as they* affect our ability to unshare other namespaces and are used as* context for privilege checks.** We don't unshare all namespaces in one go. The reason for this* is that, while the kernel documentation may claim otherwise,* there are certain cases where unsharing all namespaces at once* will result in namespace objects being owned incorrectly.* Ideally we should just fix these kernel bugs, but it's better to* be safe than sorry, and fix them separately.** A specific case of this is that the SELinux label of the* internal kern-mount that mqueue uses will be incorrect if the* UTS namespace is cloned before the USER namespace is mapped.* I've also heard of similar problems with the network namespace* in some scenarios. This also mirrors how LXC deals with this* problem.*/if (config.cloneflags & CLONE_NEWUSER) {if (unshare(CLONE_NEWUSER) < 0)bail("failed to unshare user namespace");config.cloneflags &= ~CLONE_NEWUSER;/** We don't have the privileges to do any mapping here (see the* clone_parent rant). So signal our parent to hook us up.*//* Switching is only necessary if we joined namespaces. */if (config.namespaces) {if (prctl(PR_SET_DUMPABLE, 1, 0, 0, 0) < 0)bail("failed to set process as dumpable");}s = SYNC_USERMAP_PLS;if (write(syncfd, &s, sizeof(s)) != sizeof(s))bail("failed to sync with parent: write(SYNC_USERMAP_PLS)");/* ... wait for mapping ... */if (read(syncfd, &s, sizeof(s)) != sizeof(s))bail("failed to sync with parent: read(SYNC_USERMAP_ACK)");if (s != SYNC_USERMAP_ACK)bail("failed to sync with parent: SYNC_USERMAP_ACK: got %u", s);/* Switching is only necessary if we joined namespaces. */if (config.namespaces) {if (prctl(PR_SET_DUMPABLE, 0, 0, 0, 0) < 0)bail("failed to set process as dumpable");}/* Become root in the namespace proper. */if (setresuid(0, 0, 0) < 0)bail("failed to become root in user namespace");}/** Unshare all of the namespaces. Now, it should be noted that this* ordering might break in the future (especially with rootless* containers). But for now, it's not possible to split this into* CLONE_NEWUSER + [the rest] because of some RHEL SELinux issues.** Note that we don't merge this with clone() because there were* some old kernel versions where clone(CLONE_PARENT | CLONE_NEWPID)* was broken, so we'll just do it the long way anyway.*/if (unshare(config.cloneflags & ~CLONE_NEWCGROUP) < 0)bail("failed to unshare namespaces");/** TODO: What about non-namespace clone flags that we're dropping here?** We fork again because of PID namespace, setns(2) or unshare(2) don't* change the PID namespace of the calling process, because doing so* would change the caller's idea of its own PID (as reported by getpid()),* which would break many applications and libraries, so we must fork* to actually enter the new PID namespace.*/child = clone_parent(&env, JUMP_INIT);if (child < 0)bail("unable to fork: init_func");/* Send the child to our parent, which knows what it's doing. */s = SYNC_RECVPID_PLS;if (write(syncfd, &s, sizeof(s)) != sizeof(s)) {kill(child, SIGKILL);bail("failed to sync with parent: write(SYNC_RECVPID_PLS)");}if (write(syncfd, &child, sizeof(child)) != sizeof(child)) {kill(child, SIGKILL);bail("failed to sync with parent: write(childpid)");}/* ... wait for parent to get the pid ... */if (read(syncfd, &s, sizeof(s)) != sizeof(s)) {kill(child, SIGKILL);bail("failed to sync with parent: read(SYNC_RECVPID_ACK)");}if (s != SYNC_RECVPID_ACK) {kill(child, SIGKILL);bail("failed to sync with parent: SYNC_RECVPID_ACK: got %u", s);}s = SYNC_CHILD_READY;if (write(syncfd, &s, sizeof(s)) != sizeof(s)) {kill(child, SIGKILL);bail("failed to sync with parent: write(SYNC_CHILD_READY)");}/* Our work is done. [Stage 2: JUMP_INIT] is doing the rest of the work. */exit(0);}/** Stage 2: We're the final child process, and the only process that will* actually return to the Go runtime. Our job is to just do the* final cleanup steps and then return to the Go runtime to allow* init_linux.go to run.*/case JUMP_INIT:{/** We're inside the child now, having jumped from the* start_child() code after forking in the parent.*/enum sync_t s;/* We're in a child and thus need to tell the parent if we die. */syncfd = sync_grandchild_pipe[0];close(sync_grandchild_pipe[1]);close(sync_child_pipe[0]);close(sync_child_pipe[1]);/* For debugging. */prctl(PR_SET_NAME, (unsigned long)"runc:[2:INIT]", 0, 0, 0);if (read(syncfd, &s, sizeof(s)) != sizeof(s))bail("failed to sync with parent: read(SYNC_GRANDCHILD)");if (s != SYNC_GRANDCHILD)bail("failed to sync with parent: SYNC_GRANDCHILD: got %u", s);if (setsid() < 0)bail("setsid failed");if (setuid(0) < 0)bail("setuid failed");if (setgid(0) < 0)bail("setgid failed");if (!config.is_rootless_euid && config.is_setgroup) {if (setgroups(0, NULL) < 0)bail("setgroups failed");}/* ... wait until our topmost parent has finished cgroup setup in p.manager.Apply() ... */if (config.cloneflags & CLONE_NEWCGROUP) {uint8_t value;if (read(pipenum, &value, sizeof(value)) != sizeof(value))bail("read synchronisation value failed");if (value == CREATECGROUPNS) {if (unshare(CLONE_NEWCGROUP) < 0)bail("failed to unshare cgroup namespace");} elsebail("received unknown synchronisation value");}s = SYNC_CHILD_READY;if (write(syncfd, &s, sizeof(s)) != sizeof(s))bail("failed to sync with patent: write(SYNC_CHILD_READY)");/* Close sync pipes. */close(sync_grandchild_pipe[0]);/* Free netlink data. */nl_free(&config);/* Finish executing, let the Go runtime take over. */return;}default:bail("unexpected jump value");}/* Should never be reached. */bail("should never be reached");}
2.2.1.1.3.2) init.go#Action
Action: func(context *cli.Context) error {factory, _ := libcontainer.New("")if err := factory.StartInitialization(); err != nil {// as the error is sent back to the parent there is no need to log// or write it to stderr because the parent process will handle thisos.Exit(1)}panic("libcontainer: container init failed to exec")},
// StartInitialization is an internal API to libcontainer used during the reexec of the// container.//// Errors:// Pipe connection error// System errorStartInitialization() error
2.2.1.1.3.3) libcontainer/factory_linux.go#LinuxFactory.StartInitialization
1、从环境变量中解析出childPipe、rootDir的fd以及initType(默认为standard,有时间看一下还有其他什么特别的初始化方式),并清除当前进程的所有环境变量。
2、设置一个trap以及panic recover,如果初始化容器失败,会往childPipe中写入procError。
3、调用newContainerInit创建一个init对象(两种类型,standard or setns,下面以standard为例),首先从childPipe中获取config配置文件,从配置文件中读取环境变量并设置到当前进程。构造一个linuxStandardInit对象,主要包括pipe、parentPid、config和rootDir等字段。
4、调用linuxStandardInit对象的Init方法进行初始化。
// StartInitialization loads a container by opening the pipe fd from the parent to read the configuration and state// This is a low level implementation detail of the reexec and should not be consumed externallyfunc (l *LinuxFactory) StartInitialization() (err error) {var (pipefd, fifofd intconsoleSocket *os.FileenvInitPipe = os.Getenv("_LIBCONTAINER_INITPIPE")envFifoFd = os.Getenv("_LIBCONTAINER_FIFOFD")envConsole = os.Getenv("_LIBCONTAINER_CONSOLE"))// Get the INITPIPE.pipefd, err = strconv.Atoi(envInitPipe)if err != nil {return fmt.Errorf("unable to convert _LIBCONTAINER_INITPIPE=%s to int: %s", envInitPipe, err)}var (pipe = os.NewFile(uintptr(pipefd), "pipe")it = initType(os.Getenv("_LIBCONTAINER_INITTYPE")))defer pipe.Close()// Only init processes have FIFOFD.fifofd = -1if it == initStandard {if fifofd, err = strconv.Atoi(envFifoFd); err != nil {return fmt.Errorf("unable to convert _LIBCONTAINER_FIFOFD=%s to int: %s", envFifoFd, err)}}if envConsole != "" {console, err := strconv.Atoi(envConsole)if err != nil {return fmt.Errorf("unable to convert _LIBCONTAINER_CONSOLE=%s to int: %s", envConsole, err)}consoleSocket = os.NewFile(uintptr(console), "console-socket")defer consoleSocket.Close()}// clear the current process's environment to clean any libcontainer// specific env vars.os.Clearenv()defer func() {// We have an error during the initialization of the container's init,// send it back to the parent process in the form of an initError.if werr := utils.WriteJSON(pipe, syncT{procError}); werr != nil {fmt.Fprintln(os.Stderr, err)return}if werr := utils.WriteJSON(pipe, newSystemError(err)); werr != nil {fmt.Fprintln(os.Stderr, err)return}}()defer func() {if e := recover(); e != nil {err = fmt.Errorf("panic from initialization: %v, %v", e, string(debug.Stack()))}}()// ********************************** NOTICE ********************************** //i, err := newContainerInit(it, pipe, consoleSocket, fifofd)// ********************************** NOTICE ********************************** //if err != nil {return err}// ********************************** NOTICE ********************************** //// If Init succeeds, syscall.Exec will not return, hence none of the defers will be called.return i.Init()// ********************************** NOTICE ********************************** //}
2.2.1.1.3.3.1) libcontainer/init_linux.go#newContainerInit
1、从pipe中读出initConfig
2、构造一个linuxStandardInit对象。
func newContainerInit(t initType, pipe *os.File, consoleSocket *os.File, fifoFd int) (initer, error) {var config *initConfigif err := json.NewDecoder(pipe).Decode(&config); err != nil {return nil, err}if err := populateProcessEnvironment(config.Env); err != nil {return nil, err}switch t {case initSetns:return &linuxSetnsInit{pipe: pipe,consoleSocket: consoleSocket,config: config,}, nilcase initStandard:return &linuxStandardInit{pipe: pipe,consoleSocket: consoleSocket,parentPid: unix.Getppid(),config: config,fifoFd: fifoFd,}, nil}return nil, fmt.Errorf("unknown init type %q", t)}type linuxStandardInit struct {pipe *os.FileconsoleSocket *os.FileparentPid intfifoFd intconfig *initConfig}
2.2.1.1.3.1.1.1) libcontainer/standard_init_linux.go#linuxStandardInit.Init
1、首先是针对Session keyring的一些配置,不是很清楚这里的Session是什么?
2、配置console和tty。如果配置文件中指定有Console字段,则从该字段中获取tty的slave路径创建一个linuxConsole对象,调用其dupStdio打开slave设备,将其fd复制(dup3)到当前进程的标准IO。如果console对象创建好以后,便调用ioctl的TIOCSCTTY分配控制终端,这里应该是和4.3+BSD系统保持兼容。(关于tty和console的进一步内容,有时间转发一篇更详细的或者自己总结一篇也行,对这一部分也挺感兴趣)
3、调用setupNetwork配置容器的网络。奇怪网络不是在前面配置过了吗,还是调用同样的函数。。。存疑?
4、调用setupRoute配置容器的静态路由信息。
5、selinux,调用label.Init()检查selinux是否被启动以及是否检查过,并将结果存入全局变量。此处的label并非是用户label,而是selinux相关的processLabel。
6、如果设置了mount namespace,则调用setupRootfs在新的mount namespace中配置设备、挂载点以及文件系统。
7、根据需要配置hostname、apparmor、processLabel、sysctl、readonlyPath、maskPath。这些都是一些feature,对容器启动本身没有太多影响。
8、获取父进程的退出信号量。
9、通过管道与父进程进行同步,先发出procReady再等待procRun。
10、初始化seccomp。
11、调用finalizeNamespace根据config配置将需要的特权capabilities加入白名单,设置user namespace,关闭不需要的文件描述符。
12、恢复parent进程的death信号量并检查当前父进程pid是否为我们原来记录的。不是的话,kill ourself
13、检查config里面需要执行的命令是否存在。注意:create虽然不会执行命令,但是会检查命令路径是否正确,该错误类型也会在create期间返回。
- 到此,与父进程之间的同步已经完成,关闭pipe。
- 尝试以只写方式打开fifo管道,并往管道中写入“0” 。该操作会一直保持阻塞,直到管道的另一端以读方式打开,并读取内容。至此,create操作流程已经结束。ref : FIFO管道
14、下面实际上是start的时候才会触发的操作了,阻塞清除后,根据config配置初始化seccomp,并调用syscall.Exec执行config里面指定的命令(执行的从parent传过来的initConfig中的Args数组)。
如果是start,那么runc会以只读方式打开fifo管道,读取内容,如果长度大于0,则读取到Create流程中最后写入的“0”,也同时恢复阻塞了Create的init进程,执行最后调用用户进程部分。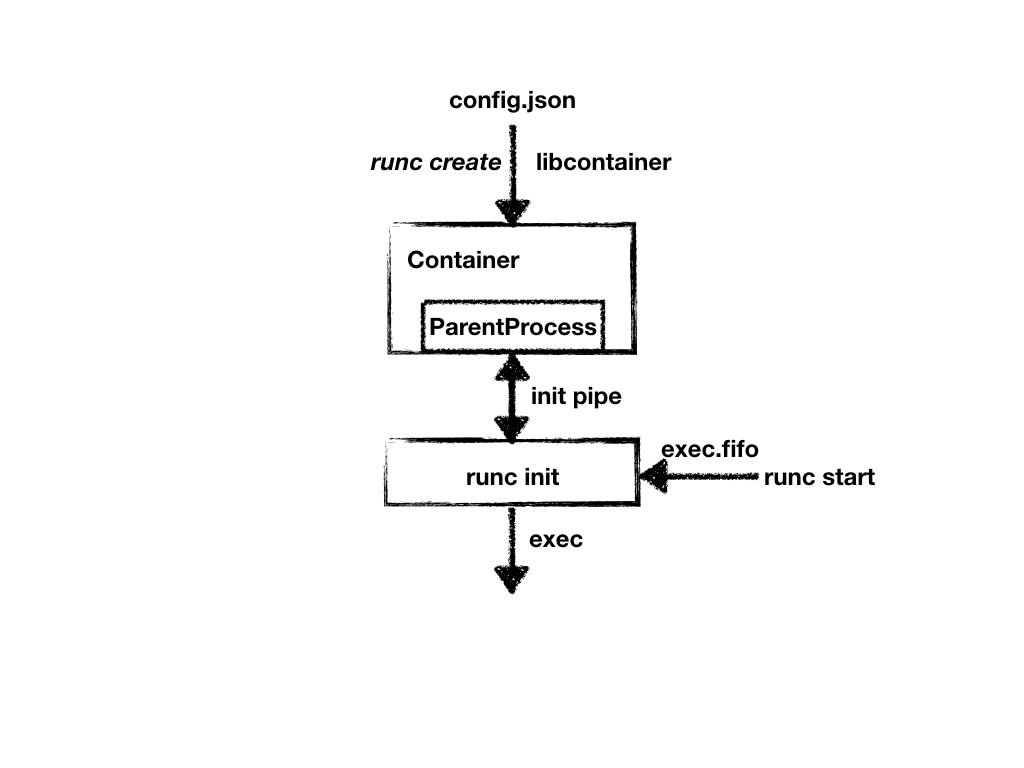
func (l *linuxStandardInit) Init() error {runtime.LockOSThread()defer runtime.UnlockOSThread()if !l.config.Config.NoNewKeyring {ringname, keepperms, newperms := l.getSessionRingParams()// Do not inherit the parent's session keyring.if sessKeyId, err := keys.JoinSessionKeyring(ringname); err != nil {// If keyrings aren't supported then it is likely we are on an// older kernel (or inside an LXC container). While we could bail,// the security feature we are using here is best-effort (it only// really provides marginal protection since VFS credentials are// the only significant protection of keyrings).//// TODO(cyphar): Log this so people know what's going on, once we// have proper logging in 'runc init'.if errors.Cause(err) != unix.ENOSYS {return errors.Wrap(err, "join session keyring")}} else {// Make session keyring searcheable. If we've gotten this far we// bail on any error -- we don't want to have a keyring with bad// permissions.if err := keys.ModKeyringPerm(sessKeyId, keepperms, newperms); err != nil {return errors.Wrap(err, "mod keyring permissions")}}}if err := setupNetwork(l.config); err != nil {return err}if err := setupRoute(l.config.Config); err != nil {return err}label.Init()if err := prepareRootfs(l.pipe, l.config); err != nil {return err}// Set up the console. This has to be done *before* we finalize the rootfs,// but *after* we've given the user the chance to set up all of the mounts// they wanted.if l.config.CreateConsole {if err := setupConsole(l.consoleSocket, l.config, true); err != nil {return err}if err := system.Setctty(); err != nil {return errors.Wrap(err, "setctty")}}// Finish the rootfs setup.if l.config.Config.Namespaces.Contains(configs.NEWNS) {if err := finalizeRootfs(l.config.Config); err != nil {return err}}if hostname := l.config.Config.Hostname; hostname != "" {if err := unix.Sethostname([]byte(hostname)); err != nil {return errors.Wrap(err, "sethostname")}}if err := apparmor.ApplyProfile(l.config.AppArmorProfile); err != nil {return errors.Wrap(err, "apply apparmor profile")}for key, value := range l.config.Config.Sysctl {if err := writeSystemProperty(key, value); err != nil {return errors.Wrapf(err, "write sysctl key %s", key)}}for _, path := range l.config.Config.ReadonlyPaths {if err := readonlyPath(path); err != nil {return errors.Wrapf(err, "readonly path %s", path)}}for _, path := range l.config.Config.MaskPaths {if err := maskPath(path, l.config.Config.MountLabel); err != nil {return errors.Wrapf(err, "mask path %s", path)}}pdeath, err := system.GetParentDeathSignal()if err != nil {return errors.Wrap(err, "get pdeath signal")}if l.config.NoNewPrivileges {if err := unix.Prctl(unix.PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0); err != nil {return errors.Wrap(err, "set nonewprivileges")}}// Tell our parent that we're ready to Execv. This must be done before the// Seccomp rules have been applied, because we need to be able to read and// write to a socket.if err := syncParentReady(l.pipe); err != nil {return errors.Wrap(err, "sync ready")}if err := label.SetProcessLabel(l.config.ProcessLabel); err != nil {return errors.Wrap(err, "set process label")}defer label.SetProcessLabel("")// Without NoNewPrivileges seccomp is a privileged operation, so we need to// do this before dropping capabilities; otherwise do it as late as possible// just before execve so as few syscalls take place after it as possible.if l.config.Config.Seccomp != nil && !l.config.NoNewPrivileges {if err := seccomp.InitSeccomp(l.config.Config.Seccomp); err != nil {return err}}if err := finalizeNamespace(l.config); err != nil {return err}// finalizeNamespace can change user/group which clears the parent death// signal, so we restore it here.if err := pdeath.Restore(); err != nil {return errors.Wrap(err, "restore pdeath signal")}// Compare the parent from the initial start of the init process and make// sure that it did not change. if the parent changes that means it died// and we were reparented to something else so we should just kill ourself// and not cause problems for someone else.if unix.Getppid() != l.parentPid {return unix.Kill(unix.Getpid(), unix.SIGKILL)}// Check for the arg before waiting to make sure it exists and it is// returned as a create time error.name, err := exec.LookPath(l.config.Args[0])if err != nil {return err}// Close the pipe to signal that we have completed our init.l.pipe.Close()// Wait for the FIFO to be opened on the other side before exec-ing the// user process. We open it through /proc/self/fd/$fd, because the fd that// was given to us was an O_PATH fd to the fifo itself. Linux allows us to// re-open an O_PATH fd through /proc.fd, err := unix.Open(fmt.Sprintf("/proc/self/fd/%d", l.fifoFd), unix.O_WRONLY|unix.O_CLOEXEC, 0)if err != nil {return newSystemErrorWithCause(err, "open exec fifo")}if _, err := unix.Write(fd, []byte("0")); err != nil {return newSystemErrorWithCause(err, "write 0 exec fifo")}// Close the O_PATH fifofd fd before exec because the kernel resets// dumpable in the wrong order. This has been fixed in newer kernels, but// we keep this to ensure CVE-2016-9962 doesn't re-emerge on older kernels.// N.B. the core issue itself (passing dirfds to the host filesystem) has// since been resolved.// https://github.com/torvalds/linux/blob/v4.9/fs/exec.c#L1290-L1318unix.Close(l.fifoFd)// Set seccomp as close to execve as possible, so as few syscalls take// place afterward (reducing the amount of syscalls that users need to// enable in their seccomp profiles).if l.config.Config.Seccomp != nil && l.config.NoNewPrivileges {if err := seccomp.InitSeccomp(l.config.Config.Seccomp); err != nil {return newSystemErrorWithCause(err, "init seccomp")}}if err := syscall.Exec(name, l.config.Args[0:], os.Environ()); err != nil {return newSystemErrorWithCause(err, "exec user process")}return nil}
2.2.1.1.3.1.1.1.1) libcontainer/rootfs_linux.go#prepareRootfs
// prepareRootfs sets up the devices, mount points, and filesystems for use// inside a new mount namespace. It doesn't set anything as ro. You must call// finalizeRootfs after this function to finish setting up the rootfs.func prepareRootfs(pipe io.ReadWriter, iConfig *initConfig) (err error) {config := iConfig.Configif err := prepareRoot(config); err != nil {return newSystemErrorWithCause(err, "preparing rootfs")}hasCgroupns := config.Namespaces.Contains(configs.NEWCGROUP)setupDev := needsSetupDev(config)for _, m := range config.Mounts {for _, precmd := range m.PremountCmds {if err := mountCmd(precmd); err != nil {return newSystemErrorWithCause(err, "running premount command")}}if err := mountToRootfs(m, config.Rootfs, config.MountLabel, hasCgroupns); err != nil {return newSystemErrorWithCausef(err, "mounting %q to rootfs %q at %q", m.Source, config.Rootfs, m.Destination)}for _, postcmd := range m.PostmountCmds {if err := mountCmd(postcmd); err != nil {return newSystemErrorWithCause(err, "running postmount command")}}}if setupDev {if err := createDevices(config); err != nil {return newSystemErrorWithCause(err, "creating device nodes")}if err := setupPtmx(config); err != nil {return newSystemErrorWithCause(err, "setting up ptmx")}if err := setupDevSymlinks(config.Rootfs); err != nil {return newSystemErrorWithCause(err, "setting up /dev symlinks")}}// Signal the parent to run the pre-start hooks.// The hooks are run after the mounts are setup, but before we switch to the new// root, so that the old root is still available in the hooks for any mount// manipulations.// Note that iConfig.Cwd is not guaranteed to exist here.if err := syncParentHooks(pipe); err != nil {return err}// The reason these operations are done here rather than in finalizeRootfs// is because the console-handling code gets quite sticky if we have to set// up the console before doing the pivot_root(2). This is because the// Console API has to also work with the ExecIn case, which means that the// API must be able to deal with being inside as well as outside the// container. It's just cleaner to do this here (at the expense of the// operation not being perfectly split).if err := unix.Chdir(config.Rootfs); err != nil {return newSystemErrorWithCausef(err, "changing dir to %q", config.Rootfs)}if config.NoPivotRoot {err = msMoveRoot(config.Rootfs)} else if config.Namespaces.Contains(configs.NEWNS) {err = pivotRoot(config.Rootfs)} else {err = chroot(config.Rootfs)}if err != nil {return newSystemErrorWithCause(err, "jailing process inside rootfs")}if setupDev {if err := reOpenDevNull(); err != nil {return newSystemErrorWithCause(err, "reopening /dev/null inside container")}}if cwd := iConfig.Cwd; cwd != "" {// Note that spec.Process.Cwd can contain unclean value like "../../../../foo/bar...".// However, we are safe to call MkDirAll directly because we are in the jail here.if err := os.MkdirAll(cwd, 0755); err != nil {return err}}return nil}
2.2.1.1.4) libcontainer/container_linux.go#linuxContainer.updateState
func (c *linuxContainer) updateState(process parentProcess) (*State, error) {if process != nil {c.initProcess = process}state, err := c.currentState()if err != nil {return nil, err}err = c.saveState(state)if err != nil {return nil, err}return state, nil}func (c *linuxContainer) saveState(s *State) error {f, err := os.Create(filepath.Join(c.root, stateFilename))if err != nil {return err}defer f.Close()return utils.WriteJSON(f, s)}const stateFilename = "state.json"

若有收获,就点个赞吧
0 人点赞
