基本原理
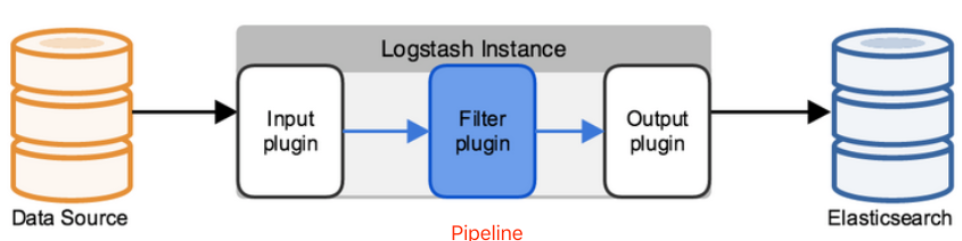
pipline
包括inout、filter、output三个处理步骤,它是通过队列进行管理
示例
日志打印输出
input{file{path => "E:/software/data/test.log"start_position => beginning}}filter{}output{stdout()}
mysql表数据同步
``` 执行命令: ./logstash-7.9.3/bin/logstash -f ./logstash-7.9.3/config/mysql.conf mysql.conf: input { jdbc {jdbc相关配置
jdbc_driver_library => “/home/admin/little-project-elasticsearch/mysql-connector-java-8.0.21.jar” jdbc_driver_class => “com.mysql.cj.jdbc.Driver” jdbc_connection_string => “jdbc:mysql://localhost:3306/elasticsearch?useUnicode=true&serverTimezone=GMT&characterEncoding=utf8&useOldAliasMetadataBehavior=true &allowMultiQueries=true” jdbc_user => “root” jdbc_password => “root”
要执行的 sql
statement => “SELECT * FROM t_goods_store”
使用递增列的值
use_column_value => true
递增字段的类型,numeric表示数值类型,timestamp 表示时间戳类型
tracking_column_type => “numeric”
递增字段的名称
tracking_column => “id”
同步点文件,这个文件记录了上次的同步点,重启时会读取这个文件,这个文件可以手动修改
last_run_metadata_path => “syncpoint_table” } }
filter {
# 转换成日期格式ruby {code => "event.set('openDate', event.get('open_date').time.localtime.strftime('%Y-%m-%d'))"}# 下划线转驼峰ruby {code => "event.set('storeName', event.get('store_name'));event.set('storeIntroduction', event.get('store_introduction'));event.set('storeBrand', event.get('store_brand'));event.set('storePhoto', event.get('store_photo'));event.set('storeTags', event.get('store_tags'));"}# 移除logstash生成的不需要的字段mutate {remove_field => ["tags","@version","@timestamp","open_date","store_name","store_introduction","store_brand","store_photo","store_tags"]}
}
output { elasticsearch {
# ES的IP地址及端口hosts => ["localhost:9200"]# 索引名称 可自定义index => "store_index"# 需要关联的数据库中有一个id字段,对应es中的iddocument_id => "%{id}"}stdout {# JSON格式输出,日志打印codec => json_lines}
logstash event
- 它是数据信息在Logstash中流转的形式
- 数据源的数据通过input进入到Logstash以后就会被转化为Logstash Event,这个Event会经过filter过滤最终event会通过output输出到目标数据源,也就是Elasticsearch中


若有收获,就点个赞吧
0 人点赞
