基于bulk优化更新操作
普通的update
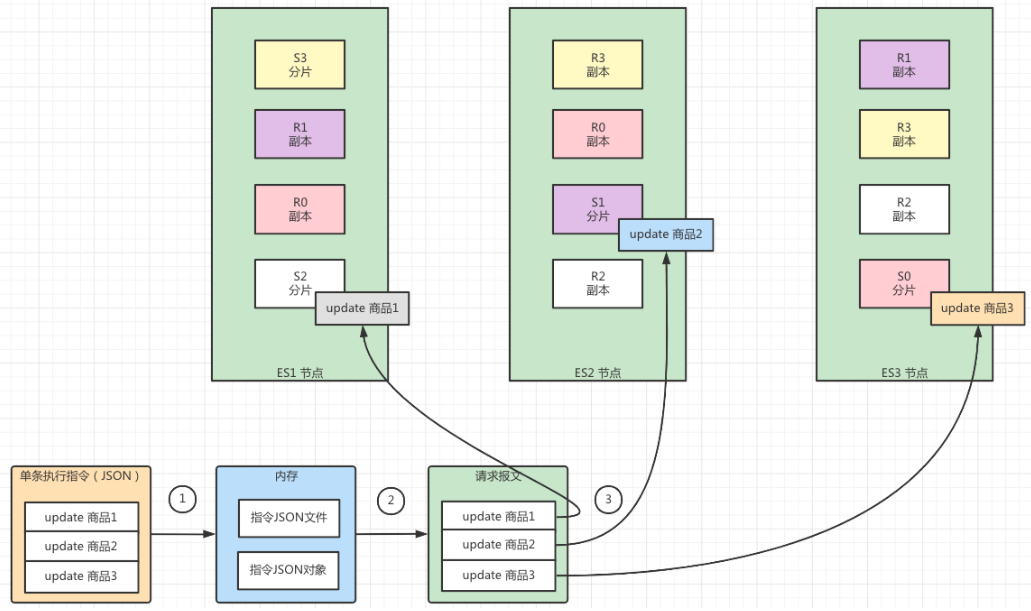
执行流程
- 将执行商品状态更新的命令行简化为三条指令:update 商品1 ,update 商品2,update 商品3。我们会采用单条指令的方式逐一处理上述3条指令。Elasticsearch在执行这些命令之前,会将其序列化并再加入到内存中,将命令行的原始指令JSON文件和解析之后的JSONArray(指令JSON对象)
- 接下来会根据指令JSON对象生成对应的请求报文,这里可以看到针对一个指令会生成一条对应的指令报文
- 最后,Elasticsearch会根据路由算法将这些报文分发到不同的节点中的不同分片中执行,从而达到更新索引文档的目的
存在问题
- 如果是更新海量的数据,那么批量索引指令中的指令就会增加。指令增加的结果就是内存中保存的JSON文件和指令对象会增大,因此需要消耗大量的内存,这种做法是必会对系统性能有所影响。
bulk批量更新
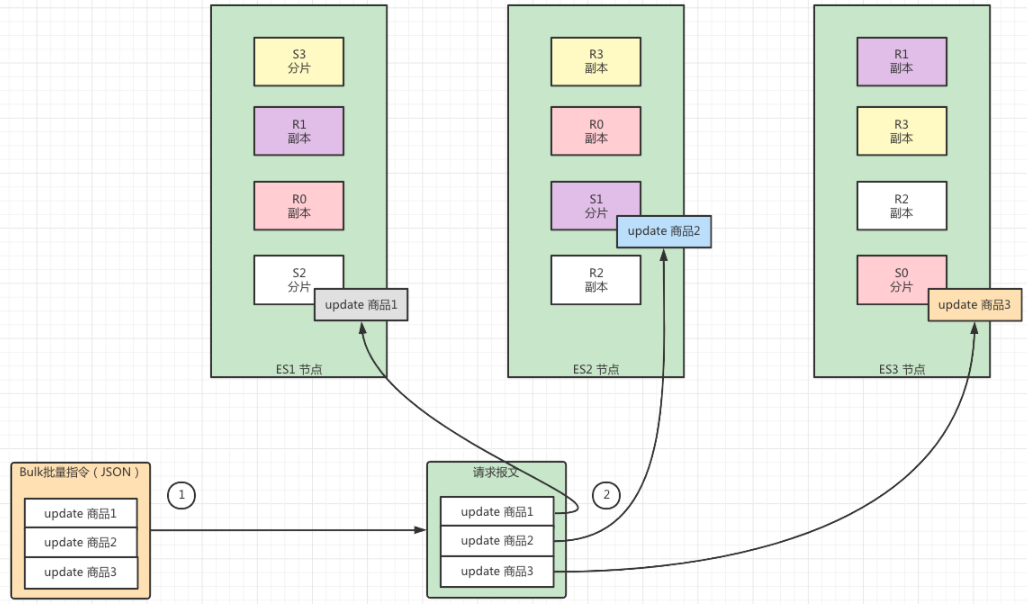
执行流程
- Bulk批量执行指令的方式会根据指令的情况,生成对应的JSON文件。这个文件不用解析成指令对象,也不会在内存中单独保存。
- Elasticsearch 系统根据指令内容逐条读取,同时生成对应的报文信息,然后进行路由、分发、执行就可以了。
Bulk API
特性
基本特性
- 可以批量对多个索引进行增加或者删除等操作,减少网络请求次数,可以显著的提高索引的速度
- CURD只能对单条数据进行操作,换句话说如果要对多条数据进行操作就需要在Bulk请求中包含多条指令
多个指令操作之间的结果互不影响。例如:一次Bulk请求包含新增和删除两个指令,如果删除指令失败,是不会影响新增指令执行的,反之亦然。
支持的操作
create
- 文档不存在时,创建
- index
- 创建新文档,如果已经存在则会替换旧的
- update
- 更新文档
delete
bulk请求报文通常是成对出现的JSON字符串:第一行字符串表示要执行的指令(create、index、update),第二行字符串是指令执行的内容,字符串之间通过换行符分隔
示例
POST _bulk{"index":{"_index":"member","_id":1}}{"doc":{"id":1,"name":"tom","age":18}}{"create":{"_index":"member","_id":2}}{"doc":{"id":2,"name":"lili"}}{"delete":{"_index":"member","_id":"3"}}{"update":{"_index:"member","_id":22}}{"doc":{"name":"bobo"}}
为什么bulk请求的JSON结构更高效
普通请求的JSON结构
JOSN结构
[{"action":{"meta_data"},"data":{}},{"action":{"meta_data"},"data":{}}]
在路由过程中,协调节点收到该请求之后,需要先对该JSON字符串进行序列化,将其序列化为JSONArray。同时会拷贝到一份数据到内存中,内存中就会同时存在一份JSON文本数据和一份JSON对象数据。
然后再解析出JSONArray中的每个JSON对象,也就是每个指令对象,然后构造请求报文,并使用路由算法将请求路由到其他节点上,最后执行
bulk API 的 json
协调节点收到Bulk请求之后,直接按照换行符对指令进行分隔。除了delete指令以外的指令都是每两个字符串组成一条指令
- 通过这种方式获取多个指令,拿到指令以后读取metadata的信息进行路由处理
- 去掉了将JSON文件和JSON对象存放到内存中的步骤,既减少了内存的占用,又降低了网络传输,特别是在海量数据更新的场景,这种请求方式就显得格外有利

若有收获,就点个赞吧
0 人点赞
