聚合分类
- Bucket Aggregation - 一些满足特定条件的文档的集合
- terms:根据某个值统计
- text类型需要根据有keyword才行,否则需要设置fielddata设置true
- 优化:keyword类型字段,打开eager_global_ordinals:true
- 当有新数据写入缓存到cache
- terms:根据某个值统计
GET accounts/_search{"size": 0,"aggs": {"genderBucket": {"terms": { "field": "gender.keyword" },"aggs": {"ageBucket": { "terms": { "field": "age","order": { "_key": "asc" } } } } } }
数字类型:
range、Date Range
// rangepost employees/_search{"size":0,"aggs":{"salary_range":{"range":{"field":"salary","ranges":[{"to":10000},{"from": 10000,"to":20000},{"key":">20000","from":20000}]}}}}
Histogram、Date Histogram
post employee/_search{"size":0,"aggs":{"salsry_histogram":{"field":"salary","interval":5000, //分桶区间"extended_bounds":{"min":0,"max":100000}}}}
支持嵌套
- Matric Aggregation - 一些数学运算,可以对文档字段进行统计分析
- 单值:min / max / sum / avg / cardinality(类似distinct count)
- 多值:
- stats,extended stats 输出多值
- percentile,percentile rank 百分比
- top hits 排在前面的示例
Terms聚合性能优化
- 开启预加载:eager_global_ordinals
适合索引不断有新的文档写入,对聚合性能有要求的
PUT accounts/_mapping{"properties": {"gender":{"type": "text","eager_global_ordinals": true}}}
GET accounts/_search{"size": 0,"aggs": {"genderBucket": {"terms": {"field": "gender.keyword",""},"aggs": {"ageBucket": {"terms": {"field": "age","size": 30,"order": {"_key": "asc"}}},"old":{"top_hits": {"size": 3,"sort": [{"age":{"order": "desc"}}]}}}}}}// rangePOST accounts/_search{"size": 0,"aggs": {"age_range": {"range": {"field": "age","ranges": [{"to": 20},{"from": 20,"to": 25},{"from": 25,"to": 30}]}}}}// 直方图POST accounts/_search{"size": 0,"aggs": {"age_histogram": {"histogram": {"field": "age","interval": 5,"extended_bounds": {"min": 15,"max": 50}}}}}
Pipeline Aggregation - 对其他的聚合结果进行二次聚合
- 支持对聚合分析结果,再次进行聚合分析
- 根据分析结果输出位置不同,分两类
- sibling-结果和现有分析结果同级
- Max,min,avg & sum bucket
- Stats,Extended Status Bucket
- Percentiles Bucket
- Parent - 结果内嵌到现有聚合分析的结果中
- Derivative(求导)
- Cumulative Sum(累计)
- Moving Function(滑动窗口)
- sibling-结果和现有分析结果同级
- buckets_path:在员工数最多的工种里,找出平均工资最低的工种
post employees/_search{"size":0,"aggs":{"jobs":{"terms":{"field":"job.keyword","size":10},"aggs":{"avg_salary":{"avg":{"field":"salary"}}}},"min_salary_by_job":{"min_bucket":{"buckets_path":"jobs>avg_salary"}}}}
Matrix Aggregation - 支持对多个字段的操作并提供一个结果矩阵
SELECT COUNT(*) -> Metric:统计运算FROM carsGROUP BY brand -> Bucket:分组,一组满足条件的文档
作用范围与排序
- ES聚合分析的默认作用范围是query的查询结果集
- ES支持以下方式改变聚合的作用范围:
- Filter
- post_filter
- Global
指定order,按照count和key进行排序
min聚合分析的执行流程
- 1、请求到达Coordinating Node,到所有分片上获取最小值,再将结果求最小值返回
- terms aggregation
- 返回值
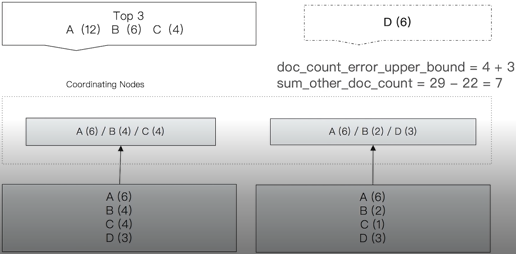
- doc_count_error_upper_bound:被遗漏的term分桶,包含的文档,有可能的最大值
- sum_other_doc_count:除了返回结果bucket的terms以外,其他terms的文档总数(总数-返回的总数)
- terms结果不正确案例:
- terms不准确问题解决:提升shard_size的参数
- 原因:无法获取数据全貌
- 原理:每次从shard上额外多获取数据,提升准确率
- shard_size默认设定:size*1.5+10
- 返回值

若有收获,就点个赞吧
0 人点赞
