跨集群搜索
早期版本实现- Tribe Node
- Tribe Node 会以Client Node的方式加入每个集群。集群中的Master节点的任务变更需要Tribe Node的回应才能继续
- Tribe Node不保存Cluster State的信息,一旦重启,初始化很慢
-
Cross Cluster Search
推荐使用的跨集群搜索方式
允许任何节点扮演federated节点,以轻量的方式,将搜索请求进行代理
-
节点
节点是一个Elasticsearch实例,本质是一个Java进程
- 每个节点都有名字,通过配置文件配置,或者启动时候-E node.name=dn指定
- Coordinating Node
- 处理请求的节点,路由请求到正确的节点,例如创建索引的请求,需要路由到Master节点
- 所有节点默认都是Coordinating Node
- Data Node
- 可以保存数据的节点。节点启动后,默认就是数据节点。可以设置node.data:false禁止
- Data Node职责:保存分片数据。在数据扩展上启动了至关重要的作用(由master Node决定如何把分片分发到数据节点上)
- 通过增加数据节点,可以解决数据水平扩展和解决数据单点问题
- Master Node
- 职责:处理创建、删除索引等请求;决定分片分配到哪个节点;维护更新Cluster State
- Master Eligible Node & 选主流程
- 一个集群,支持配置多个Master Eligible节点。这些节点可以在必要时(如Master节点出现故障)参与选主流程,成为Master节点
- 每个节点启动后,默认就是一个Master Eligible节点,可以设置node.master:false禁止
- 当集群内第一个Master Eligible节点启动时,默认将自己选举为Master节点
- 选主流程:
- 互相ping对方,Node Id低的会成为被选举的节点
- 被选举的节点丢失后,会重新选
- 脑裂问题:分布式系统的经典网络问题,当网络出现问题,一个节点和其他节点无法链接
- 设定quorum(仲裁),,只有Master Eligible节点数大于quorum时,才进行选举
- 当3有个Master Eligible,设置discovery.zen.minium_master_nodes=2,即可避免脑裂
集群状态:
- 维护集群中的所有节点信息、所有的索引和其他相关的Mapping和Setting信息;分片的路由信息
- 每个节点都会保存集群状态信息,但只有Master节点才能修改集群状态信息并同步给其他节点
分片:
- 数据可用性:主分片丢失,副本分片可以promote成主分片;
- 提升读取性能:副本分片由主分片同步。通过增加replica个数,一定程度上可以提高读取的吞吐量
- 分片数设定
- 主分片过小,如果索引增长很快,集群无法通过增加节点实现对这个索引的数据扩展
- 主分片设置过大:导致单个shard容量很小,引发一个节点上有过多的分片,影响性能
- 副本分片数设置过多,会降低集群整体的写入性能
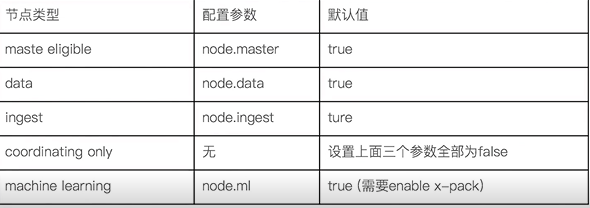
- 文档的分布式存储
- 文档会存储在具体的某个主分片和副本分片上
- 文档到分片得到映射算法
- 确保文档能均匀分布在所有分片上,充分利用硬件资源
- 潜在算法:
- 随机/Round Robin
- 维护文档到分片的映射关系
- 实时计算,通过文档自动计算需要存储到哪个分片
- es路由算法:shard = hash(_routing) % number_of_primary_shards
- Hash算法确保文档均匀分散到分片
- 默认的_routing值是文档id
- 可以自行定制routing数值,例如相同国家的商品都分配到指定的shard
- 索引创建后,primary shard数不能修改的原因
- 更新一个文档
- 删除一个文档
分布式搜索
两阶段
- Query
- 搜索请求到es节点后,节点以Coordinating Node的身份,向索引分片发送查询请求
- 被选中的分片进行查询排序,返回From+Size个排序后的文档ID和排序值给Coordinating Node
- Fetch
- Coordinating Node会将Query阶段每个分片返回得到排好序的文档ID列表,进行重新排序。选取From+Size个文档的ID
- 以multi get请求的方式,到相应的分片获取详细文档数据
- 性能问题
- 每个分片上都需要查找from+size
- 最终协调节点处理 number_of_shard*(from+ size)
- 深度分页
- ES有一条限定,默认限定到10000个文档
- 解决:Search After
- 实时获取下一页文档信息
- 不支持指定页数
- 只能往下翻页
- 相关性算分
- 问题:每个分片都是基于自己的分片上的数据进行相关度计算。这会导致打分偏离的情况,特别是数据量很少时。相关性算分在分片之间是互相独立
- 解决:
- 数据量不大时,将主分片数设置为1;当数据量足够大时,只要保证文档均匀分散在各个分片上,结果一般就不会出现骗偏差
- 使用dfs_query_then_fetch
- 在搜索的URL中指定参数“_search?search_type=dfs_query_then_fetch”
- 会把每个分片的词频和文档频率进行搜集,然后完整的进行一次相关性算分。耗费更多的CPU和内存

若有收获,就点个赞吧
0 人点赞
