原理
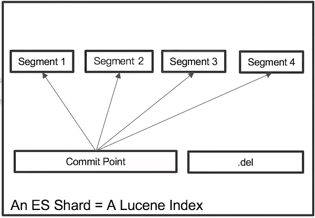
- ES分片:es中最小的工作单元、是一个lucene的Index
- 倒排索引不可变性
- 好处:
- 无需考虑并发写文件得到问题,避免了锁机制带来的性能问题
- 一旦读入内核的文件系统缓存,便留在那里。只要文件系统有足够的空间,大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能
- 缓存容易生成和维护、数据可以被压缩
- 挑战:如果让一个新的文档可以被搜索,需要reindex
- 好处:
- Lucene Index
- 在Lucene中,单个倒排索引文件被称为Segment。Segment是自包含的,不可变更的。多个Segments汇总在一起,称为Lucene的Index,其对应的就是ES的Shard
- 当有新文档写入时,会生成新的Segment,查询时会同事查询所有的Segments,并且对结果汇总。Lucene中有一个文件,用来记录所有Segments信息,叫做Commit Point
- 删除的文档信息,保存在“.del”文件中
- 什么是Refresh
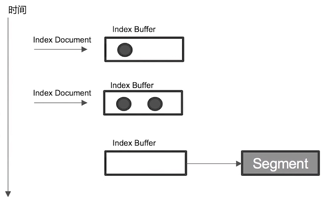
- 将Index buffer写入Segement的过程叫做Refresh。Refresh不执行fsync操作
- Refresh频率:默认1秒发生一次,可通过index.refresh_interval配置。Refresh后,数据就可以被搜索到了。这也是为什么Elasticsearch被称为进实时搜索
- 如果系统有大量的数据写入,那就会产生很多的Segment
- Index Buffer被占满时,会出发Refresh,默认值是JVM的10%
- 什么是Transaction Log
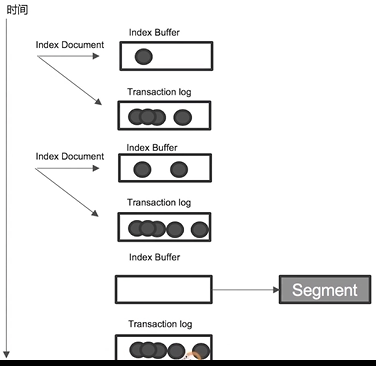
- Segment写入磁盘的过程相对耗时,借助文件系统缓存,Refresh时,先将Segment写入缓存以开放查询
- 为保证数据不丢失。所以在Index文档时,同时写Transaction Log,高版本开始,Transaction Log默认罗盘(低版本每隔5s进行一次罗盘)。每个分片有一个Transaction Log
- 在ES Refresh时,Index Buffer被清空,Transaction log不会清空
- 什么是Flush
ES Flush & Lucene Commit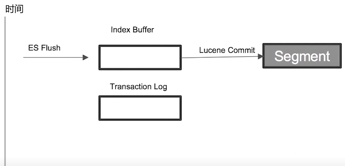
- 调用Refresh,Index Buffer清空并且Refresh
- 调用fsync,将缓存中的Segements写入磁盘,并更新commit point
- 清空(删除)Transaction Log
- 默认30分钟调用一次
- Transaction Log满时出发Flush(默认512MB)
- Merge操作
- Segment 很多,需要被定期合并:减少Segments、删除已经删除的文档(.del中文档)
- ES和Lucene会自动进行Merge操作
- POST my_index/_forcemerge

若有收获,就点个赞吧
0 人点赞
