数据模型
哈希表
- 键-值存储的数据结构
- 哈希冲突
-
有序数组
数据更新插入成本高
-
搜索树
二叉搜索数
- 每个节点的左儿子小于父节点,父节点又小于右儿子
- 查询更新时间复杂度O(log(N))
N叉数
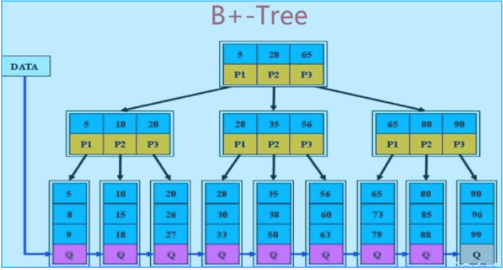

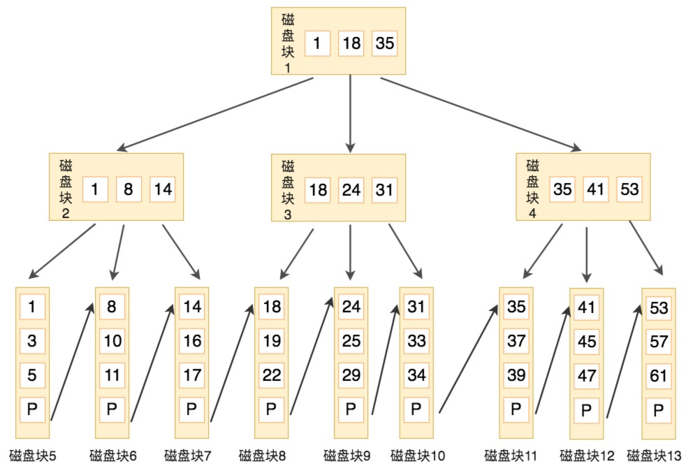
- 非叶子节点仅用来索引,数据都保存在叶子节点中
- 所有叶子节点均有一个链指针指向下一个叶子节点
- 磁盘读写代价低
- 查询效率稳定O(logn)
- 方便进行范围查询
- MySQL中的InnoDB引擎使用B+Tree结构来存储索引,可以尽量减少数据查询时磁盘IO次数,同时树的高度直接影响了查询的性能,一般树的高度维持在 3~4 层。
B+Tree由三部分组成:根root、枝branch以及Leaf叶子,其中root和branch不存储数据,只存储指针地址,数据全部存储在Leaf Node,同时Leaf Node之间用双向链表链接每个Leaf Node是三部分组成的,即前驱指针p_prev,数据data以及后继指针p_next,同时数据data是有序的,默认是升序ASC,分布在B+tree右边的键值总是大于左边的,同时从root到每个Leaf的距离是相等的,也就是访问任何一个Leaf Node需要的IO是一样的,即索引树的高度Level + 1次IO操作
存储结构
表空间
- 系统表空间
- 独占表空间
- 通用表空间
- 临时表空间
- undo表空间
- 段
- 数据段
- 索引段
- 回滚段
- 区
- 64个连续的页组成,即1M
- 页
- 默认16KB
- InnoDB按页为单位来读写数据
- 页写满了,会发生页分裂
- 操作系统管理磁盘的最小单位是磁盘块,是操作系统读写磁盘的最小单位
-
主键索引-聚簇索引
叶子节点存储该行记录
索引维护
叶子节点存储该行主键
- 回表
- 覆盖索引——减少回表
- 最左前缀 原则
- 联合索引最左N个字段,或者字符串的最左M个字符
索引下推
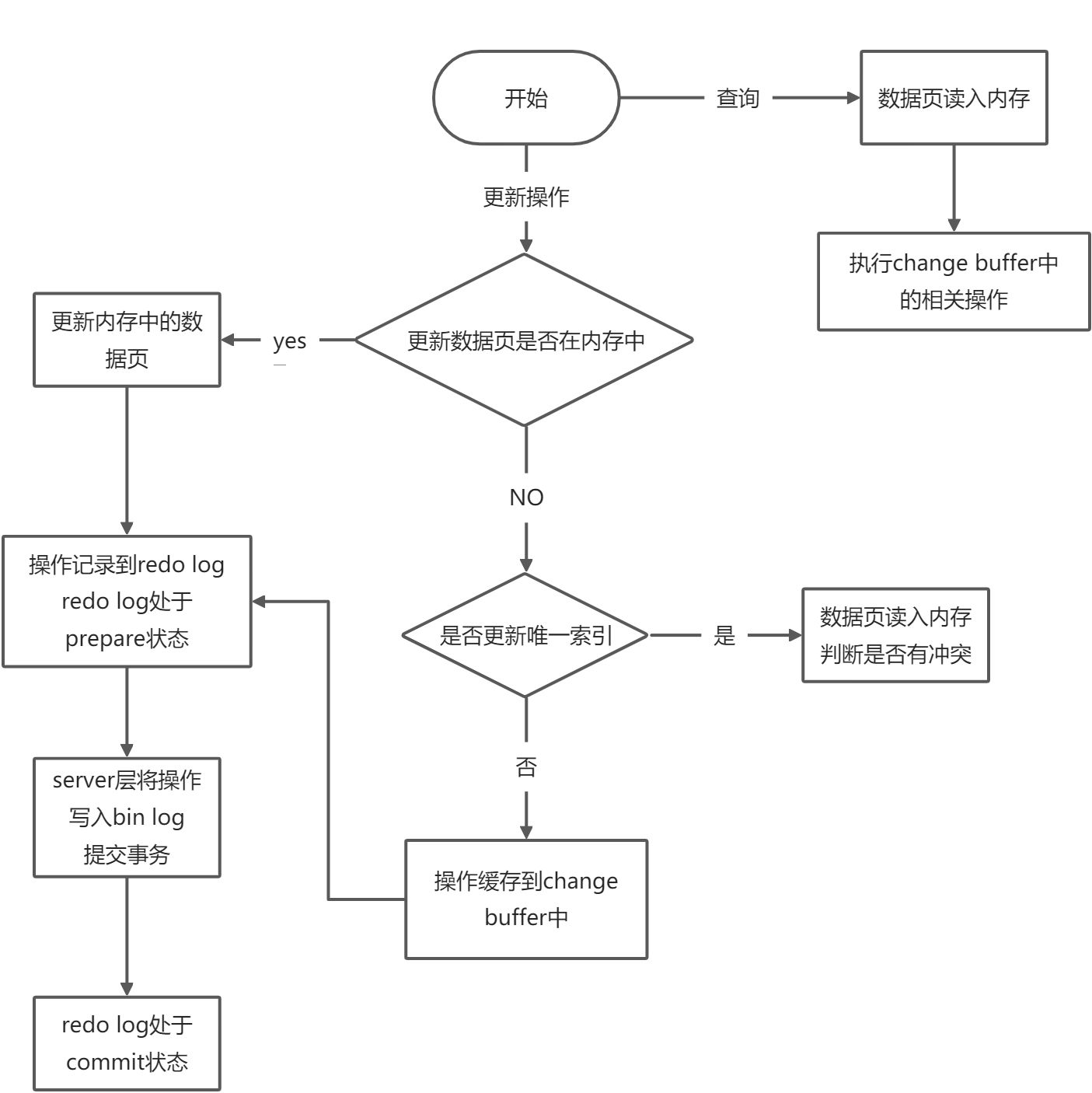
更新过程
- 如果数据页在内存中就直接更新,否则的话,在不影响数据一致性的前提下,InooDB会将这些更新操作缓存在change buffer中
- 将对数据页的操作记录到redo log,然后告诉server层更新成功
- 下次查询访问这个数据页,先读入数据页到内存,然后执行change buffer中的相关操作
- Change Buffer的Merge
- 将change buffer中的操作应用到原数据页,得到最新结果的过程称为merge
- 访问这个数据页会触发Merge
- 系统定期Merge
- 数据库正常关闭时候Merge
- 磁盘上的change buffer在系统表空间,内存中的change buffer在InnoDB的buffer pool中
- 参数innodb_change_buffer_max_size来动态设置change buffer的大小
- 这个参数设置为50的时候,表示change buffer的大小最多只能占用buffer pool的50%
- 在一个数据页merge之前,change buffer记录的变更越多,收益旧越大
- 脏页:内存数据页和磁盘数据页内容不一致
- flush:脏页落盘
- 落盘规则:内存中的数据页落盘,如果数据页不在内存,就从磁盘读取内存,用redo log记录更新内存中的数据页,而后落盘
- 落盘时机
- 当redo log写满后,也就是write pos追上了check point,mysql就必须去进行flush操作,将数据落盘
- mysql空闲时候
- mysql正常关闭时候
- 内存不够用的时候
- InnoDB用buffer pool管理内存
- 脏页影响
- 一个查询要淘汰的脏页太多,会拖慢响应时间(系统”抖动“)
- redo log写满,更新操作全部会堵住,影响系统正常运行
- InnoDB刷脏页的控制策略
- InnoDB应该根据机器的IO能力,来控制刷脏页的力度
- 对应的mysql参数:innodb_io_capacity,建议设置成磁盘的IOPS
- 可以使用fio工具来测试获取
- 对应的mysql参数:innodb_io_capacity,建议设置成磁盘的IOPS
- 如果发现脏页旁边的数据页也是脏页,会一起刷掉
- innodb_flush_neighbors为0,则禁掉此规则,mysql8.0这个参数默认0
- InnoDB应该根据机器的IO能力,来控制刷脏页的力度
- flush:脏页落盘
前缀索引
alter table sys_user add index1(email(6));

若有收获,就点个赞吧
0 人点赞
