全局锁
- 对整个数据库实例加锁
- 加锁命令:flush tables with read lock,使整个数据库处于只读状态
- unlock tables:释放锁
- 异常自动释放
- 同等效果:set global readonly=true
- 此参数有时候会用来判断是主库还是备库
使用场景:全库逻辑备份
加锁:lock tables …read/write
-
元数据锁——MDL(Meta Data Lock)
当对一个表做增删改查操作时候,会加MDL读锁
- 当对表结构变更操作时候,加上MDL写锁
- 读锁之间不互斥
-
行锁
引擎层实现
- InnoDB 支持行锁,MYSIAM不支持
- 锁是锁的索引,不是数据
RC和RR的加锁基本一致,不同的是RR为了防止幻读会额外加上间隙锁。
两阶段锁协议:
在InnoDB事务中,行锁是在需要的时候加上,但并不是不需要了就立刻释 放,而是要等到事务结束时才释放
如果你的事务中需要锁多个行,要把 最可能造成锁冲突、最可能影响并发度的锁尽量往后放
死锁和死锁检测
死锁原因:当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致 这几个线程都进入无限等待的状态,称为死锁
死锁处理策略
InnoDB对于每个符合条件的记录是分步加锁的,即先加二级索引再加主键索引;其次是按记录逐条加锁的,即加完一条记录后,再加另外一条记录,直到所有符合条件的记录都加完锁
-
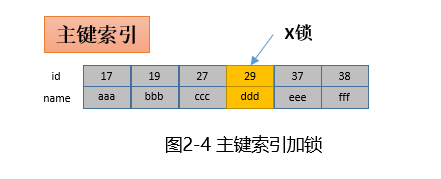
根据主键进行更新
update t set name=’xxx’ where id=29;只需要将主键上id=29的记录加上X锁即可(X锁称为互斥锁,加锁后本事务可以读和写,其他事务读和写会被阻塞)
-
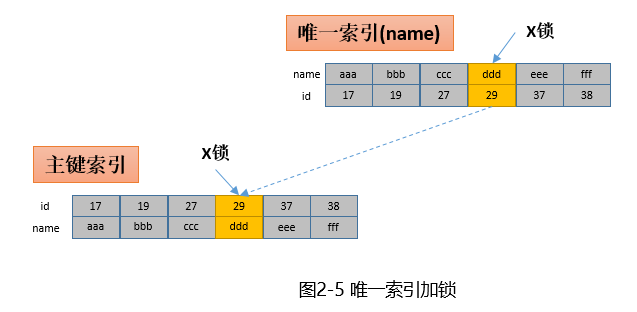
根据唯一索引进行更新
update t set name=’xxx’ where name=’ddd’;这里假设name是唯一的。InnoDB现在name索引上找到name=’ddd’的索引项(id=29)并加上加上X锁,然后根据id=29再到主键索引上找到对应的叶子节点并加上X锁。
- 一共两把锁,一把加在唯一索引上,一把加在主键索引上。这里需要说明的是加锁是一步步加的,不会同时给唯一索引和主键索引加锁。这种分步加锁的机制实际上也是导致死锁的诱因之一
-
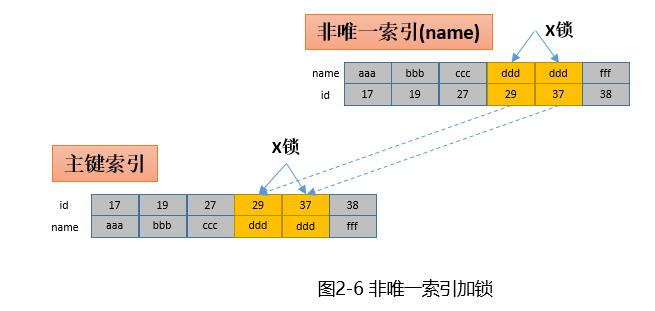
根据非唯一索引进行更新
update t set name=’xxx’ where name=’ddd’;这里假设name不唯一,即根据name可以查到多条记录(id不同)。和上面唯一索引加锁类似,不同的是会给所有符合条件的索引项加锁
- 在非唯一索引(name)上找到(ddd,29)的索引项,加上X锁;
- 根据(ddd,29)找到主键索引的(29,ddd)记录,加X锁;
- 在非唯一索引(name)上找到(ddd,37)的索引项,加上X锁;
- 根据(ddd,29)找到主键索引的(37,ddd)记录,加X锁;
加锁规则
两个原则

若有收获,就点个赞吧
0 人点赞
