慢查询优化思路
添加索引
- 避免索引字段使用函数,尽量在程序端完成计算
- 避免发生隐式转换,这要注意条件查询的类型区别,比如字符串类型需要加引号;
- order by 字段需要走索引,否则会发生 filesort;
- 当全表扫描成本低于使用索引成本,需要重新选择区分度大的条件选项;
- 联合索引的使用顺序基于索引字段的建立顺序。
索引添加方式:
simple nested loop
- 相当于是上层循环
- Block nested loop
- 首先将驱动表的数据放入join buffer缓存中,然后和关联表进行比较查询
- 优点:使用内存,速度快
- 缺点:join buffer大小是256KB
- Index nested loop
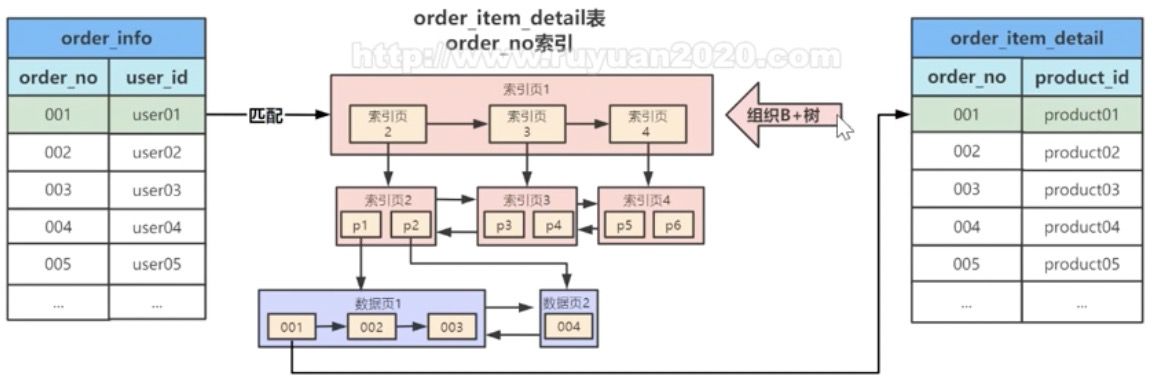
- 匹配次数由原来的 驱动表行数被驱动表行数 =》 驱动表行数 * 被驱动表高度
如果join关联字段使用啦索引,就使用index nested loop 否则使用 block nested loop
多表联查优化
多表联查的语句一定要在连接字段添加索引,这非常重要;
- 永远是小表驱动大表,合理地选择你的驱动表。
- 要知道优化的目标是尽可能减少 JOIN 中 Nested Loop 的循环次数,从而保证“永远用小结果集驱动大结果集(这一点很重要)”。A JOIN B,其中,A为驱动,A 中每一行和 B 进行循环JOIN,看是否满足条件,所以当 A 为小结果集时,越快,那么:
- 尽量不要嵌套太多的 JOIN 语句,连表的数量越多,性能消耗越大,业务复杂性也会越高,MySQL 不是 Oracle,这一点需要你切记;
-
通过拆分冷热数据优化慢日志
比如 A 系统只需要近一年的数据,但是这个扫描条件没办法添加合适的索引,所以将之前的数据进行归档,在某些特定的条件下,能有效地减少扫描行数,大大加快 SQL 语句的执行时间
拆分冷热数据,针对特定场景的慢日志是有效果的,也有利于数据管理,根据我的经验,可以设立定时任务,按照每天/每周/每月的频率,指定业务低峰时期执行数据归档,执行完成后邮件/微信通知即可。
通过读写分离进行优化
当主库的负载增多,我们有必要做读写分离:将定时的慢日志剥离出主库,转而查询没有提供服务的从库,从另一个角度降低了慢日志对于主数据库的影响,现阶段比较成熟的数据库读写分离方案大概有 3 种:
其实,SQL 优化是一个漫长的工作,如果你想高效地完成,就需要一个长期的机制,这个机制的核心就是加强与研发的互动,具体怎么做呢?
- 建立 DB——应用负责人机制
- 这点非常重要,是一切的基础。简单来说,就是针对每个库都要有一个相应的负责人,如果一个库存在多个人调用的情况下(核心库)就需要包含多个负责人。
- 过滤慢日志,发送邮件 TOP
- 通过第一步建立的负责人对应机制,然后通过程序/脚本过滤指定的库的 TOP N 慢 SQL,按照一定时期发送给相应的研发负责人,让他们进行跟踪优化(定时期可以是一天、一周或者半个月,按照机制进行即可)
- 建立追踪机制
- DBA 根据慢日志建立追踪机制表,比如,记录每个慢 SQL 的优化进度、是否可以优化、最终期限……
场景分析
分页查询优化
业务要根据时间范围查询交易记录,接口原始的SQL如下,trade_info上有索引idx_status_create_time(status,create_time)
select * from trade_info where status = 0 and create_time >= '2020-10-01 00:00:00' and create_time <= '2020-10-07 23:59:59' order by id desc limit 102120, 20;
覆盖索引优化
- 对于典型的分页limit m, n来说,越往后翻页越慢,也就是m越大会越慢,因为要定位m位置需要扫描的数据越来越多,导致IO开销比较大,这里可以利用辅助索引的覆盖扫描来进行优化,先获取id,这一步就是索引覆盖扫描,不需要回表 ``` select * from trade_info a ,
(select id from trade_info where status = 0 and create_time >= ‘2020-10-01 00:00:00’ and create_time <= ‘2020-10-07 23:59:59’ order by id desc limit 102120, 20) as b //这一步走的是索引覆盖扫描,不需要回表 where a.id = b.id;
<a name="Z9YAc"></a>
#### 分而治之
- 营销系统有一批过期的优惠卷要失效,核心SQL如下:
— 需要更新的数据量500w update coupons set status = 1 where status =0 and create_time >= ‘2020-10-01 00:00:00’ and create_time <= ‘2020-10-07 23:59:59’;
- 速度慢:在Oracle里更新500w数据是很快,因为可以利用多个cpu core去执行,但是MySQL就需要注意了,一个SQL只能使用一个cpu core去处理,如果SQL很复杂或执行很慢,就会阻塞后面的SQL请求,造成活动连接数暴增,MySQL CPU 100%,相应的接口Timeout
- 主从延迟:主从复制架构,而且做了业务读写分离,更新500w数据需要5分钟,Master上执行了5分钟,binlog传到了slave也需要执行5分钟,那就是Slave延迟5分钟,在这期间会造成业务脏数据,比如重复下单等
- 优化思路:**先获取where条件中的最小id和最大id,然后分批次去更新,每个批次1000条,这样既能快速完成更新,又能保证主从复制不会出现延迟**
<a name="tkBDC"></a>
#### 前缀索引
- 业务发展初期,为了快速实现功能,对一些数据表字段的长度定义都比较宽松,比如用户表users的昵称nickname定义为varchar(128),而且有业务接口需要通过nickname查询,系统运行了一段时间之后,查询users表最大的nickname长度为30,这个时候就可以创建前缀索引来减小索引的长度提升性能。
- 优化索引前
— nickname varchar(128) DEFAULT NULL定义的执行计划
mysql> explain select * from users where nickname = ‘Laaa’;
+——+——————-+———-+——————+———+———————-+———————+————-+———-+———+————
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+——+——————-+———-+——————+———+———————-+———————+————-+———-+———+————
| 1 | SIMPLE | users | NULL | ref | idx_nickname | idx_nickname | 515 | const | 1 | 100.00 | NULL |
- key_len=515,由于表和列都是utf8mb4字符集,每个字符占4个字节,变长数据类型+2Bytes,允许NULL额外+1Bytes,即128 x 4 + 2 + 1 = 515Bytes
- 优化
— 创建前缀索引,前缀长度为30 mysql> create index idx_nickname_part on users(nickname(30)); — 查看执行计划 mysql> explain select * from users where nickname = ‘Laaa’; +——+——————-+———-+——————+———+————————————————+—————————-+————-+- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +——+——————-+———-+——————+———+————————————————+—————————-+————-+- | 1 | SIMPLE | users | NULL | ref | idx_nickname_part,idx_nickname | idx_nickname_part | 123 | const | 1 | 100.00 | Using where |
<a name="UmKAg"></a>
#### 跳跃索引
- 一般情况下,如果表users有复合索引idx_status_create_time,我们都知道,单独用create_time去查询,MySQL优化器是不走索引,所以还需要再创建一个单列索引idx_create_time
- MySQL 8.0也实现Oracle类似的索引跳跃扫描,在优化器选项也可以看到skip_scan=on。
mysql> explain select id, user_id,status, phone from users where create_time >=’2021-01-02 23:01:00’ and create_time <= ‘2021-01-03 23:01:00’; +——+——————-+———-+——————+———+———————-+———+————-+———+————+—————+—— | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +——+——————-+———-+——————+———+———————-+———+————-+———+————+—————+—— | 1 | SIMPLE | users | NULL | range | idx_status_create_time | idx_status_create_time | NULL | NULL | 15636 | 11.11 | Using where; Using index for skip scan|
```
- 适合复合索引前导列唯一值少,后导列唯一值多的情况,如果前导列唯一值变多了,则MySQL CBO不会选择索引跳跃扫描,取决于索引列的数据分表情况。

若有收获,就点个赞吧
0 人点赞
