主从复制原理
- 从节点会有一个IO线程和主节点建立TCP连接,请求主数据库的binlog日志
- 主数据库会有一个IO dump线程,处理从节点请求,响应binlog日志给他
从库把接收到的redolog日志写入到relay日志文件,从库上会有另外一个线程读取relay日志进行回放
步骤
确保主库和从库的service-id不同
- 主库打开binlog功能
创建从库账号
create user 'backup_user'@'192.168.31.%' identified by 'backup_123';grant replication slave on *.* to 'backup_user'@'192.168.31.%';flush privileges;
主库导出数据全量备份
/usr/local/mysql/bin/mysqldump --single-transaction -uroot -proot --master-data=2 -A > backup.sql- —master-data=2:备份的SQL文件里,要记录此时主库的binlog文件和position号
- 此时一定不能允许系统操作数据库
从库还原
长链接
-
异步
如上原理描述,binlog_dump线程负责将事务的binlog同步给从库
- 默认
-
半同步
binlog要同步到从库,事务才返回成功
- 主库提交事物后,当至少一有一个从库响应接收到啦binlog(写入 relay log),才相应客户端
- 主库如果等待时间超过临界值,则转为异步复制
mysql5.7中,半同步可能存在幻读
,mysql5.7.2版本后,对半同步辅助模式的改进,主要解决幻读
- 通过在主库配置参数:rpl_semi_sync_master_wait_point=AFTER_SYNC
-
GTID
定义
Global Transaction ID,即全局事务ID,每个事务都会有一个GTID一一对应
- 组成部分:GTID:server_uuid:gno
- server_uuid:是一个实例第一次启动时候自动生成的,全局唯一
- gno:是一个整数,初始值1,每次提交事务的时候分配给这个事务,并加一
- 使用:在启动一个mysql实例的时候,加上参数gtid_mode=on和enforce_gtid
-
生成方式
取决于session变量gtid_next的值
- gtid_next=automatic。
- 代表使用默认值,这是mysql会把server_uuid:gno分配给这个事务
- 记录binlog的时候先记录一行:SET@@SESSION.GTID_NEXT=’server_uuid:gno’;
- 然后将GTID放入本实例的GTID集合
- gtid_next是一个指定的gtid值,比如set gtid_next=’current_gtid’,指定为current_gtid,那么就有两种情况
- 如果current_gtid已经存在于当前实例的gtid集合,那么接下来执行的这个事务就会被忽略不执行
- 如果current_gtid没有存在于实例的gtid集合,那么就将这个gtid分配给接下来要执行的事务
- 也就是说不需要系统生成GTID
这个每个实例都维护了一个GTID集合,用来对应“已经执行过的事务”
数据延迟问题
原因
-
延迟时间
推荐使用percona-toolkit工具集里的pt-heartbeat
它会在主库里创建一个heartbeat表,然后会有一个线程定时更新表中的时间戳字段;从库会有一个线程负责检查heartbeat表里的时间戳字段,和当前时间对比一下就知道从库落后的时间了
解决方案
MYSQL5.7支持并行复制
- 在从库里设置slave_parallel_works>0,然后将slave_parallel_type设置为LOGICAL_CLOCK
在mycat或者sharding-Sphere中设置某些查询sql直接走主库
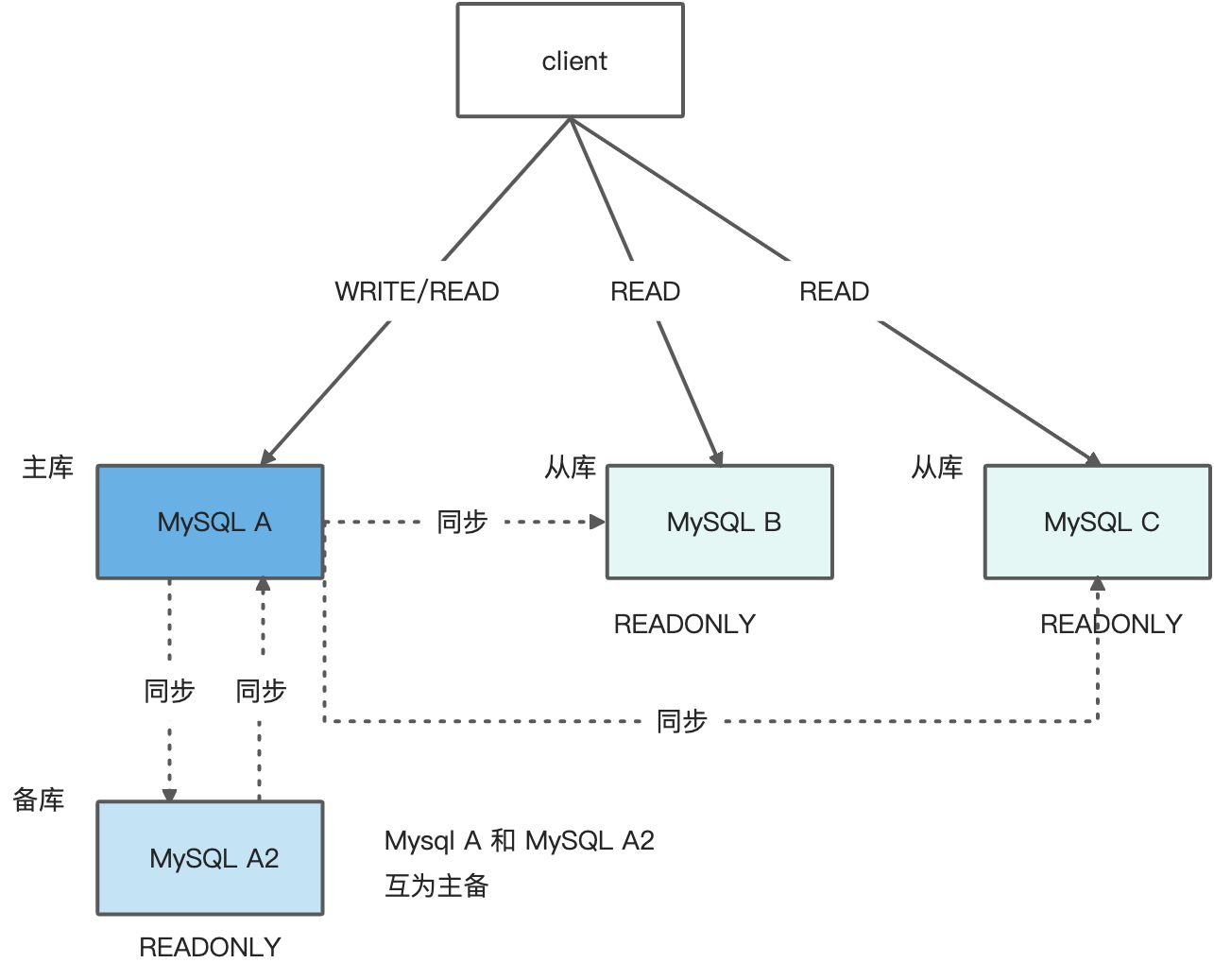
主库故障转移
主库A发生故障后,将Mysql A2设置为主库,此时还需要将从库B、C指向新的主库
基于位点的主备切换
将节点B设置为节点A2的从库
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$username MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_file MASTER_LOG_POS=$master_log_pos- MASTER_LOG_FILE和MASTER_LOG_POS,表示从主库MASTER_LOG_FILE文件的MASTER_LOG_POS位置的日志同步数据
同步位点寻找
- 等待新主库A2将中转日志同步完
- 在A2上执行show master status,得到当前A2上的最新File 和position
- 取原主库的故障时间T
使用mysqlbinlog工具,解析A2的File,得到T时刻的位点
mysqlbinlog File --stop-datetime=T --start-datetime=T- 其中end_log_pos后面的值就是T时刻的位点
- 但这个位点并不准确,因为这个时刻的binlog可能也已经同步到从库
- 所以如果直接从这个位点同步,可能会出现“主键冲突”
而主动跳过这个错误的方法有
将节点B设置为节点A2的从库
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1其中master_auto_position=1,表示主备关系使用GTID协议
- 主备切换逻辑
- 将现在新主库A2的gtid集合记为set_a,从库B的gtid集合记为set_b
- 实例B连接主库A2
- 实例B将自己的set_b发送给A2
- 实例A2计算出set_b和自己set_a的差集,也就是存在于set_a,但不存在set_b
- 实例A2判断自己是否这些差集的binlog
- 如果全部都有,则返回第一个不存在set_b的binlog日志,发送给实例B
- 否则,说明自己日志不完整,返回错误
- 然后实例B就按顺序读取binlog
- 使用GTID,不需要寻找点位了,主库会判断从哪里开始同步日志给从库,如果主库的日志不完整,就拒绝同步给从库,保证了日志的完整性

若有收获,就点个赞吧
0 人点赞
