主备基本原理
备库readonly
- 备库设置为readonly模式
readonly设置对超级权限用户无效,而备库用于同步更新的线程就是拥有超级权限的,所以不会影响数据同步
好处
有时候一些运营的查询会放到备库去查询,只读可以防止误操作
- 防止切换逻辑有bug,导致双写,造成主备数据不一致
-
流程
在备库B上通过change master命令,设置主库的ip、端口、用户名、密码、以及从哪个位置开始请求binlog(文件名和日志偏移量)
- 在备库B上执行start slave命令,这个时候备库会创建两个线程:io_thread、sql_thread,其中io_thread负责和主库建立连接
- 主库A校验完用户名密码后,按照要求的数据位置,读取binlog,发送给备库B
- 备库B拿到后放到中转文件relay_log
备库B的sql_thread读取relay_log文件,解析sql并执行
主库A上执行了一个事务,写入binlog,这个时刻记为T1
- 从库B接收到这条binlog写入relay log,这个时刻记为T2
从库B读取这条binlog,并执行完这个事务,这个时刻记为T3
延迟时间计算
T3-T1,就是从库B的延迟时间
在从库上执行show slave status命令,可以查看到这个时间,即seconds_behind_master
seconds_behind_master计算方式
每个binlog都会有一个字段记录在主库上的写入时间
-
主备库机器时间设置不一致怎么办
从库连接上主库后,会通过select unix_timestamp()函数来获取主库系统时间
如果从库发现主库的系统时间和自己的不一致,则在计算seconds_behind_master时候会减去系统时间的差值
主从延迟的原因
从库机器性能差
如果将多个从库部署在一个机器上,会导致因争抢资源,而使备库处理能力下降
备库配置低,IOPS能力不及主库,导致相同的磁盘读写压力,从库处理能力不及主库
从库压力大
通常运营后台的分析SQL会在从库执行,如果分析SQL的性能很低,会消耗大量的CPU资源,也会影响同步速度
大事务
主库上必须等事务执行完,才会写入binlog,然后发送给从库,如果事务实行时间比较久,会导致同步延迟
-
从库的并行复制能力
即sql_thread的并行处理能力,低版本的MySQL只支持单线程复制
主备切换策略
可靠性优先策略
切换流程
判断备库B的seconds_behind_master,如果小于某个值(2s)则进行下一步,否则重试这一步
- 将主库A设置为只读,即readonly=true
- 判断备库B的seconds_behind_master的值,直到等于0,进入下一步
- 将备库B改为可读可写状态,即readonly=false
-
缺点
步骤2之后,主备库都处于只读状态,直到切换完成,这段时候数据库服务不可用
-
可用性优先策略
切换流程
上述可靠性切换流程,将4、5步调整到最开始执行
即先进行主库切换,将备库的readonly设置为false,将请求切换到新的主库
缺点
-
从库并行辅助能力优化
问题来源
mysql5.6之前,辅助处理relay_log的sql_thread是单线程的,在主库并发高、TPS高,同步到备份库的redolog多
- 由于主库是多线程并发处理事务写入binlog,而备库是单线程处理主库的binlog
-
优化方案
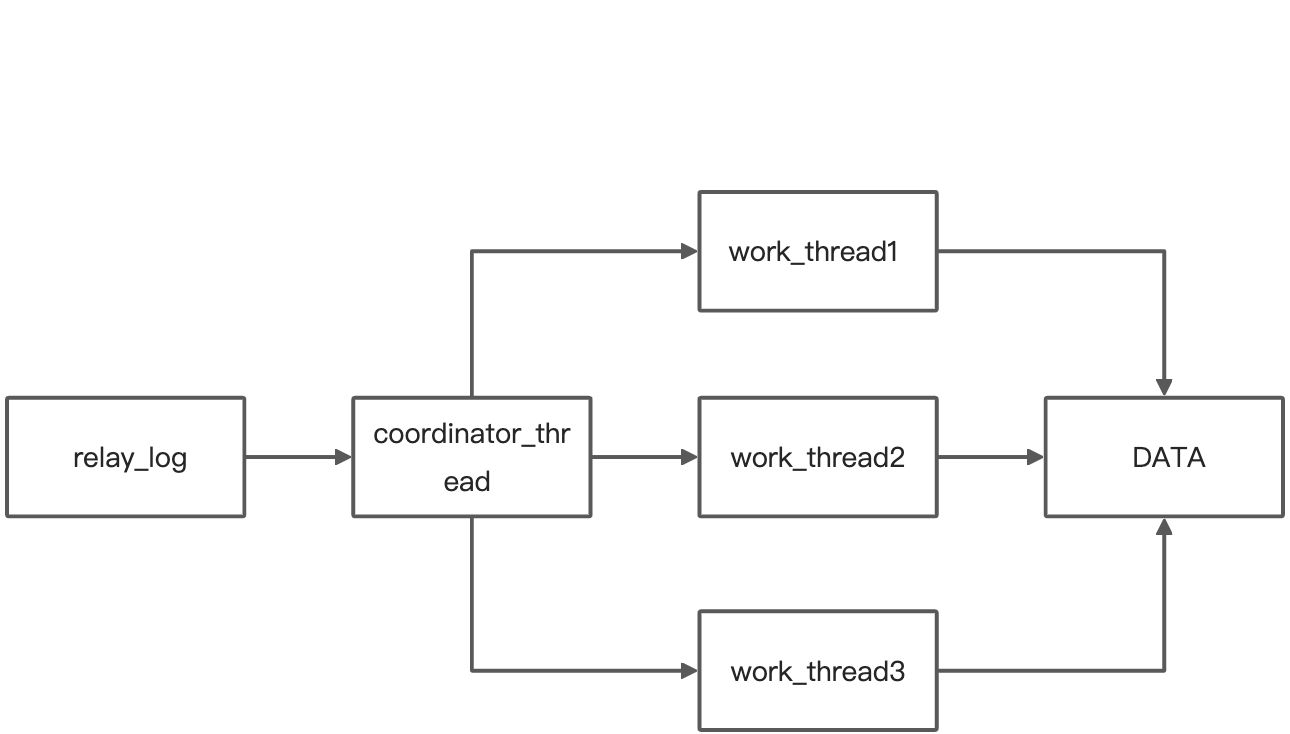
基本线程模型
MariaDB并行复制策略
利用redo log组提交的原理,“所有处于commit状态的事务可以并行”,表示已通过锁冲突检查
- 能够在一组里提交的事务一定不会修改同一行
- 主库上可以并行执行的事务,在从库上也可以
- 实现
- 在一组里提交的事务,有一个相同的commit id,下一组就是commit id +1
- commit id直接写到binlog里
- 传到从库上后,相同commit id的事务分发到多个work线程执行
- 这一组执行完后,coordinator再去取下一批
缺点
参数:slave-parallel-type
- DATABASE:使用mysql5.6版本的按库并行策略
- LOGICAL_CLOCK:使用类似MariaDB的策略
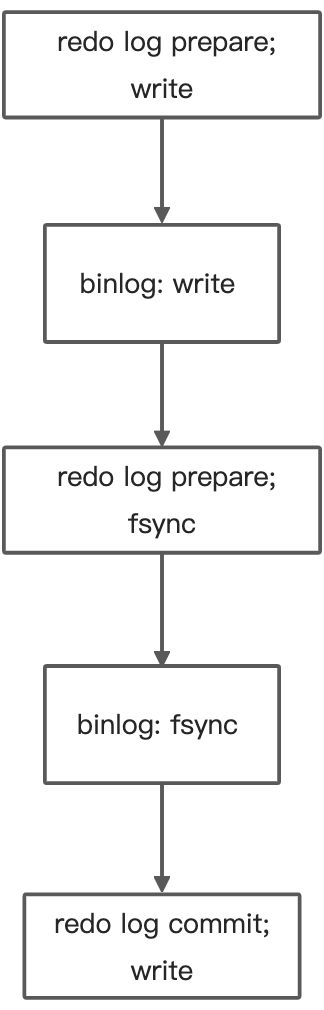
- 其实不要等redo log commit,其实党redo log处于prepared状态就表示已经通过锁冲突检验
- mysql5.7并行复制策略思想
- 同时处于prepared状态,在备库上也是可以并行执行的
- 处于prepare状态的事务,和处于committed状态之间的事务,也可以在备库并行执行
- bin_log的组提交,用于故意拉长binlog 从write到fsync的时间,提高写磁盘效率
- bin_log的组提交,也可以用来提升备库的并行复制能力
Mysql5.7.22的并行复制策略
- mysql5.7.22版本中新增加了一种并行复制策略,基于WRITESET的并行复制
新增加的参数binlog-transaction-dependency-tracking,用来控制是否启用这个新策略
-
解决方案
强制走主库
对于必须拿到最新数据的查询请求,发送到主库
- 对于允许拿到旧数据的,发送到从库
缺点:有些时候,比如金融类的业务,所有的查询都必须是查询到最新的数据,那所有的请求都走主库,从库就没有意义了
sleep方案
在执行查询之前,先执行一条类似select sleep(1)的命令
-
判断主备无延迟方案
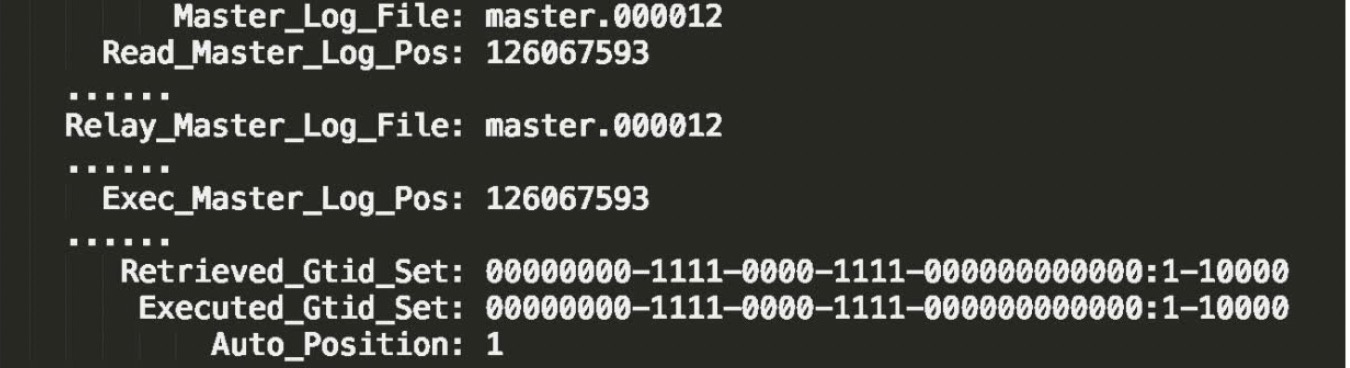
方法1:通过show slave status命令,拿到seconds_behand_master参数,来判断是否有延迟
- 方法2:通过对比位点确保主备无延迟
- Master_Log_File和Read_Master_Log_Pos,表示的是读到的主库的最新位点;
- Relay_Master_Log_File和Exec_Master_Log_Pos,表示的是备库执行的最新位点。
- 方法3:通过对比GTID集合确保主备无延迟
- Auto_Position=1,表示这对主备关系使用了GTID协议。
- Retrieved_Gtid_Set,是备库收到的所有日志的GTID集合;
- Executed_Gtid_Set,是备库所有已经执行完成的GTID集合。
对于中间状态,即主库已经发送binlog日志,但从库还没接收到binlog,这个情况并不适用
配合semi-sync方案
semi-sync方案设计
- 事务提交时候,主库将binlog发送给从库
- 从库收到binlog后相应ack给主库
- 然后主库才会返回客户端事务执行完成
- 缺点:这个方案对对一主一备场景成立。当有多个从库时候,主库收到一个ack就返回了,这时候如果查询发送到的是没返回ACK的从库,那可能查询到的依然不是最新数据
等主库位点方案
等GTID方案

若有收获,就点个赞吧
0 人点赞
