案例背景
- 一个百万日活的互联网公司
- 运营系统中,有一个 功能:通过各种条件筛选出大量用户,然后向这些用户推送消息
-
案例SQL
功能SQL
users表保存用户基本的核心数据
- user_extent_info表保存用户扩展信息,比如兴趣爱好、最近一次登陆时间、家庭住址等
select id,name from users where id IN (select user_id from user_extent_info where last_login_time=xxx)
案例SQL
上面的功能SQL可能会返回大量数据几十万条,所以会先进行一次count,然后分批查询出来进行操作
- select count(*) from users where id IN (select user_id from user_extent_info where last_login_time=xxx)
-
问题探究
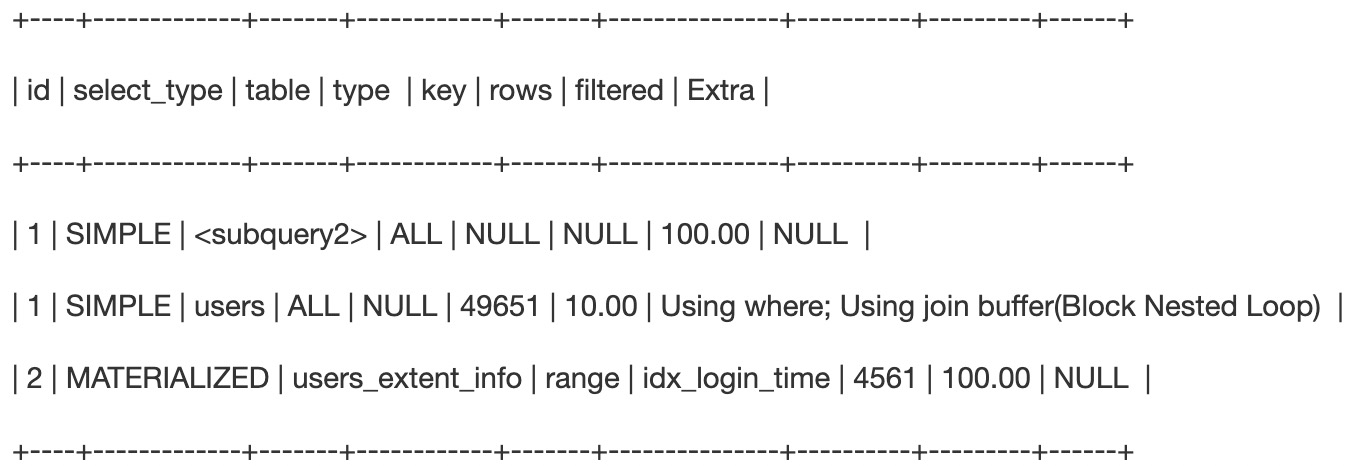
explain分析执行计划
执行计划分析
第三行,子查询使用到了idx_login_time这个索引,使用了Range类型的索引范围扫描,查询出4561条数据,没有做其他额外筛选,所以filtered是100%
- MATERIALIZED:表明对查询出的4561条数据进行了物化,物化成了一个临时表,这个临时表物化会将数据落盘
- 第二行,表示对users表进行了全表扫描,扫描了49651行,Extra中的“using join buffer”表示使用了join连接查询
第一行,表示对子查询进行了也就是物化的临时表,进行了全表扫描
show warnings
执行完explain后执行show warnings,获取更多信息
- show warnings返回信息中看到semi join
- 发现mysql自动把in查询优化成了semi join的半连接查询
-
优化结果
关闭半连接查询
- set optimizer_switch=’semijoin=off’
- 或者修改SQL,在不影响语意的情况下,换个写法,让其不走半连接查询

若有收获,就点个赞吧
0 人点赞
