数据源(DataSource)简介
数据源,简单理解为数据源头,提供了应用程序所需要数据的位置。数据源保证了应用程序与目标数据之间交互的规范和协议,它可以是数据库,文件系统等等。其中数据源定义了位置信息,用户验证信息和交互时所需的一些特性的配置,同时它封装了如何建立与数据源的连接,向外暴露获取连接的接口。应用程序连接数据库无需关注其底层是如何建立的,也就是说应用业务逻辑与连接数据库操作是松耦合的。
JDBC(Java DataBase Connectivity)是Java中用于规范应用程序如何来访问数据库的应用程序接口(API),它提供了查询和更新数据库中数据的方法。在传统的jdbc年代,通常写一个通用的方法来封装与数据库的建立操作:
public Connection getConnection() throws SQLException {Connection conn = null;Properties connectionProps = new Properties();connectionProps.put("user", this.userName);connectionProps.put("password", this.password);//获取获取连接conn = DriverManager.getConnection("jdbc:" + this.dbms + "://" +this.serverName +":" + this.portNumber + "/",connectionProps);return conn;}
但是这有一个很大的问题:程序员需要自己去写建立连接的操作,且该方法已经与我们的应用程序是紧耦合的,在后续需要更改数据库时,需要程序员手动修改这里。在面对多数据源的情况下,该方法可能变成了简单工厂模式那种慵懒的样子,不符合设计模式中“对修改关闭,对扩展开放”的原则。
数据源(DataSource类)是对数据库以及对数据库交互操作的抽象,它封装了目标源的位置信息,验证信息和建立与关闭连接的操作。数据源可以看做程序中一个组件,它把传统中需要在代码里编写配置信息和获取连接等操作抽象出一个规范或者接口,这样不同的第三方可以自行实现该接口提供不同的策略。这样,数据源就是对应用程序是透明的,开发者只需为应用程序配置特定的数据源即可与数据库进行连接等操作。当需要更换数据库服务器或者更换数据库种类时,只需修改配置中信息即可,无需修改程序代码,它相当于代替了传统的DriverManager类。而数据源通常分为不提供连接和提供连接池的数据源。
下面是jdk官方提供的DataSource接口(数据源都需要直接或者间接实现DataSource接口):
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String username, String password)
throws SQLException;
}
像Spring提供的数据源“org.springframework.jdbc.datasource.DriverManagerDataSource”是不提供连接池的。该数据源对于应用程序的每一个连接请求都建立新的连接,当应用程序使用完毕后,再执行销毁操作。当与数据库交互频繁时,这种模式会严重影响程序的性能。时间和空间消耗大多数消耗在连接和销毁中,而非数据库处理,所以Spring官方建议我们仅在测试中使用该数据源,而开发应用程序则推荐使用第三方提供连接池的数据源。下面是Spring提供的数据源的继承关系:
public class DriverManagerDataSource extends AbstractDriverBasedDataSource {
}
public abstract class AbstractDriverBasedDataSource extends AbstractDataSource {
}
public abstract class AbstractDataSource implements DataSource {
}
下面是Spring提供的数据源的配置:
<!--配置数据源:数据源有非常多,可以使用第三方的,也可使使用Spring的-->
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=utf8"/>
<property name="username" value="root"/>
<property name="password" value="wujiahao269139"/>
</bean>
而市面上有很多优秀的提供连接池的数据源,如:c3p0、Druid 、DBCP、Hikari等等,如:在Spring中配置c3p0:
<!-- 数据源配置(c3p0) -->
<!--数据库连接池
c3p0 自动化操作(自动的加载配置文件 并且设置到对象里面)
-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<!-- 配置连接池属性 -->
<property name="driverClass" value="${jdbc.driver}"/>
<property name="jdbcUrl" value="${jdbc.url}"/>
<property name="user" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
<!-- c3p0连接池的私有属性 -->
<property name="maxPoolSize" value="30"/>
<property name="minPoolSize" value="10"/>
<!-- 关闭连接后不自动commit -->
<property name="autoCommitOnClose" value="false"/>
<!-- 获取连接超时时间 -->
<property name="checkoutTimeout" value="10000"/>
<!-- 当获取连接失败重试次数 -->
<property name="acquireRetryAttempts" value="2"/>
</bean>
Spring Boot整合默认的数据源(Hikari)
整合JDBC需要的启动器:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
在application.yaml中配置连接参数:
spring:
#连接数据库(jdbc),配置数据源
datasource:
username: root
password: wujiahao269139
url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.cj.jdbc.Driver
完成上述配置即可访问数据库了,且Spring Boot官方还为我们提供了一款优秀的数据源:Hikari
@SpringBootTest
class ApplicationTests {
@Autowired
DataSource dataSource;
@Test
public void test() {
System.out.println("Spring Boot官方提供的数据源:"+dataSource.getClass());
try {
Connection connection = dataSource.getConnection();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
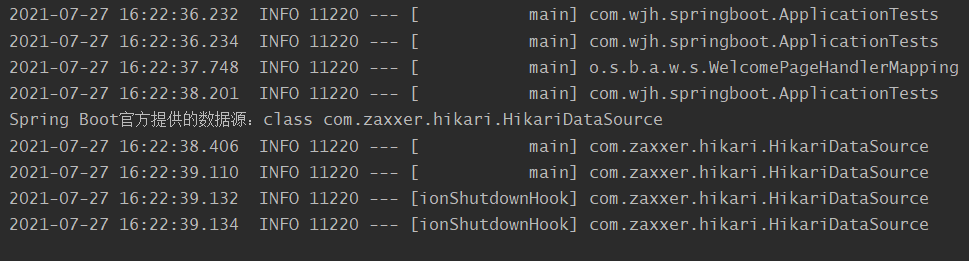
HikariDataSource 号称 Java WEB 当前速度最快的数据源,相比于传统的 C3P0 、DBCP、Tomcat jdbc 等连接池更加优秀,这是Spring Boot官方配置和推荐的数据源。
有了数据源,就可以调用它的“getConnection()”方法(重写于DataSource接口的getConnection方法)获取Connection了,然后可以使用原生的jdbc语句访问数据库,也可以使用MyBatis框架(后续会整合mybatis)访问数据库,除此之外,这里再介绍一种“用之不敌MyBatis,但弃之可惜”JdbcTemplate 类。
JdbcTemplate类是Spring对原生JDBC做的轻量级的封装,位于org.springframework.jdbc.core下,它主要提供一下几个方法访问数据库:
- execute方法:可以用于执行任何SQL语句,一般用于执行DDL语句;
- update方法及batchUpdate方法:update方法用于执行新增、修改、删除等语句;batchUpdate方法用于执行批处理相关语句;
- query方法及queryForXXX方法:用于执行查询相关语句;
- call方法:用于执行存储过程、函数相关语句。
上述方法的详情去JdbcTemplate类中查看即可,下面是这个类操作数据库的一个小例子:
/**
* Spring Boot 默认提供了数据源,默认提供了 org.springframework.jdbc.core.JdbcTemplate
* JdbcTemplate 中会自己注入数据源,用于简化 JDBC操作
* 还能避免一些常见的错误,使用起来也不用再自己来关闭数据库连接
*/
@SpringBootTest
class ApplicationTests {
@Autowired
JdbcTemplate jdbcTemplate;
@Test
public void test() {
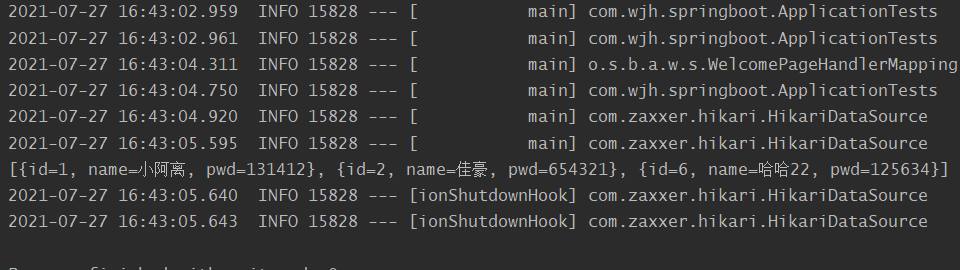
String sql="select * from user";
List<Map<String, Object>> list=jdbcTemplate.queryForList(sql);
System.out.println(list);
}
}
关于JdbcTemplate和MyBatis的一些区别的参考文章:
https://blog.51cto.com/u_15061944/2592659
https://www.cnblogs.com/ChenD/p/7080934.html
Spring Boot整合Druid数据源
Druid简介
Druid 是阿里巴巴开源的携带连接池的数据源,结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控。Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池,日志监控是Druid最特别的特点。Spring Boot 2.0 以上默认使用 Hikari 数据源,可以说 Hikari 与 Driud 都是当前 Java Web 上最优秀的数据源。
配置Druid
首先需要添加依赖:
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
然后需要再application.yaml中切换数据源和配置基本参数(基本固定,可根据需要改变参数值):
spring:
#连接数据库(jdbc),配置数据源
datasource:
username: root
password: wujiahao269139
url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority
#则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4j
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
Druid数据源的参数详解:https://www.jianshu.com/p/8f195f79f244
由于Druid配置的日志是log4j,因此还需要导入log4j的依赖:
编写并注册DruidDataSource组件
现在需要自己为 DruidDataSource 绑定全局配置文件中的参数,再注入到ioc容器中,而不再使用 Spring Boot 自动生成的DataSource;我们需要自己添加 DruidDataSource 组件到容器中,并绑定属性。
@Configuration
public class DruidConfig {
/**
* 将自定义的 Druid数据源添加到容器中,不再让 Spring Boot 自动创建
* 绑定全局配置文件中的 druid 数据源属性到 com.alibaba.druid.pool.DruidDataSource从而让它们生效
*
* @return DataSource
* @ConfigurationProperties(prefix = "spring.datasource"):作用就是将 全局配置文件中前缀
为 spring.datasource的属性值注入到 com.alibaba.druid.pool.DruidDataSource 的同名参数中
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
return new DruidDataSource();
}
}
测试后发现数据源切换成功:
@SpringBootTest
class ApplicationTests {
@Autowired
DataSource dataSource;
@Test
public void test() {
System.out.println(dataSource.getClass());
DruidDataSource druidDataSource= (DruidDataSource) dataSource;
System.out.println("druidDataSource 数据源最大连接数:" + druidDataSource.getMaxActive());
System.out.println("druidDataSource 数据源初始化连接数:" + druidDataSource.getInitialSize());
}
}

配置Druid数据源监控
Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看
编写访问Druid的servlet并注入ioc容器:
@Bean
public ServletRegistrationBean statViewServlet() {
//“/druid/*”是访问路径
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
// 这些参数可以在com.alibaba.druid.support.http.StatViewServlet的父类com.alibaba.druid.support.http.ResourceServlet中找到
Map<String, String> initParams = new HashMap<>();
//后台管理界面的登录账号
initParams.put("loginUsername", "admin");
//后台管理界面的登录密码
initParams.put("loginPassword", "123456");
//后台允许谁可以访问
// initParams.put("allow", "localhost"):表示只有本机可以访问
// initParams.put("allow", ""):为空或者为null时,表示允许所有访问
initParams.put("allow", "");
//deny:Druid后台示禁止此ip访问
initParams.put("wjh", "192.168.1.20");
//设置初始化参数
bean.setInitParameters(initParams);
return bean;
}
编写访问Druid的过滤器:
/**
* 配置 Druid 监控 之 web 监控的 filter
* WebStatFilter:用于配置Web和Druid数据源之间的管理关联监控统计
*
* @return
*/
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//exclusions:设置哪些请求进行过滤排除掉,从而不进行统计
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*,/jdbc/*");
bean.setInitParameters(initParams);
//"/*" 表示过滤所有请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
最终的DruidConfig.class配置如下:
@Configuration
public class DruidConfig {
/**
* 将自定义的 Druid数据源添加到容器中,不再让 Spring Boot 自动创建
* 绑定全局配置文件中的 druid 数据源属性到 com.alibaba.druid.pool.DruidDataSource从而让它们生效
*
* @return DataSource
* @ConfigurationProperties(prefix = "spring.datasource"):作用就是将 全局配置文件中前缀
* 为 spring.datasource的属性值注入到 com.alibaba.druid.pool.DruidDataSource 的同名参数中
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource() {
return new DruidDataSource();
}
/**
* 配置 Druid 监控管理后台的Servlet;
* 内置 Servlet 容器时没有web.xml文件,所以使用 Spring Boot 的注册 Servlet 方式
*
* @return ServletRegistrationBean
*/
@Bean
public ServletRegistrationBean statViewServlet() {
//“/druid/*”是访问路径
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
// 这些参数可以在com.alibaba.druid.support.http.StatViewServlet的父类com.alibaba.druid.support.http.ResourceServlet中找到
Map<String, String> initParams = new HashMap<>();
//后台管理界面的登录账号
initParams.put("loginUsername", "admin");
//后台管理界面的登录密码
initParams.put("loginPassword", "123456");
//后台允许谁可以访问
// initParams.put("allow", "localhost"):表示只有本机可以访问
// initParams.put("allow", ""):为空或者为null时,表示允许所有访问
initParams.put("allow", "");
//deny:Druid后台示禁止此ip访问
initParams.put("wjh", "192.168.1.20");
//设置初始化参数
bean.setInitParameters(initParams);
return bean;
}
/**
* 配置 Druid 监控 之 web 监控的 filter
* WebStatFilter:用于配置Web和Druid数据源之间的管理关联监控统计
*
* @return FilterRegistrationBean
*/
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//exclusions:设置哪些请求进行过滤排除掉,从而不进行统计
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*,/jdbc/*");
bean.setInitParameters(initParams);
//"/*" 表示过滤所有请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
效果展示
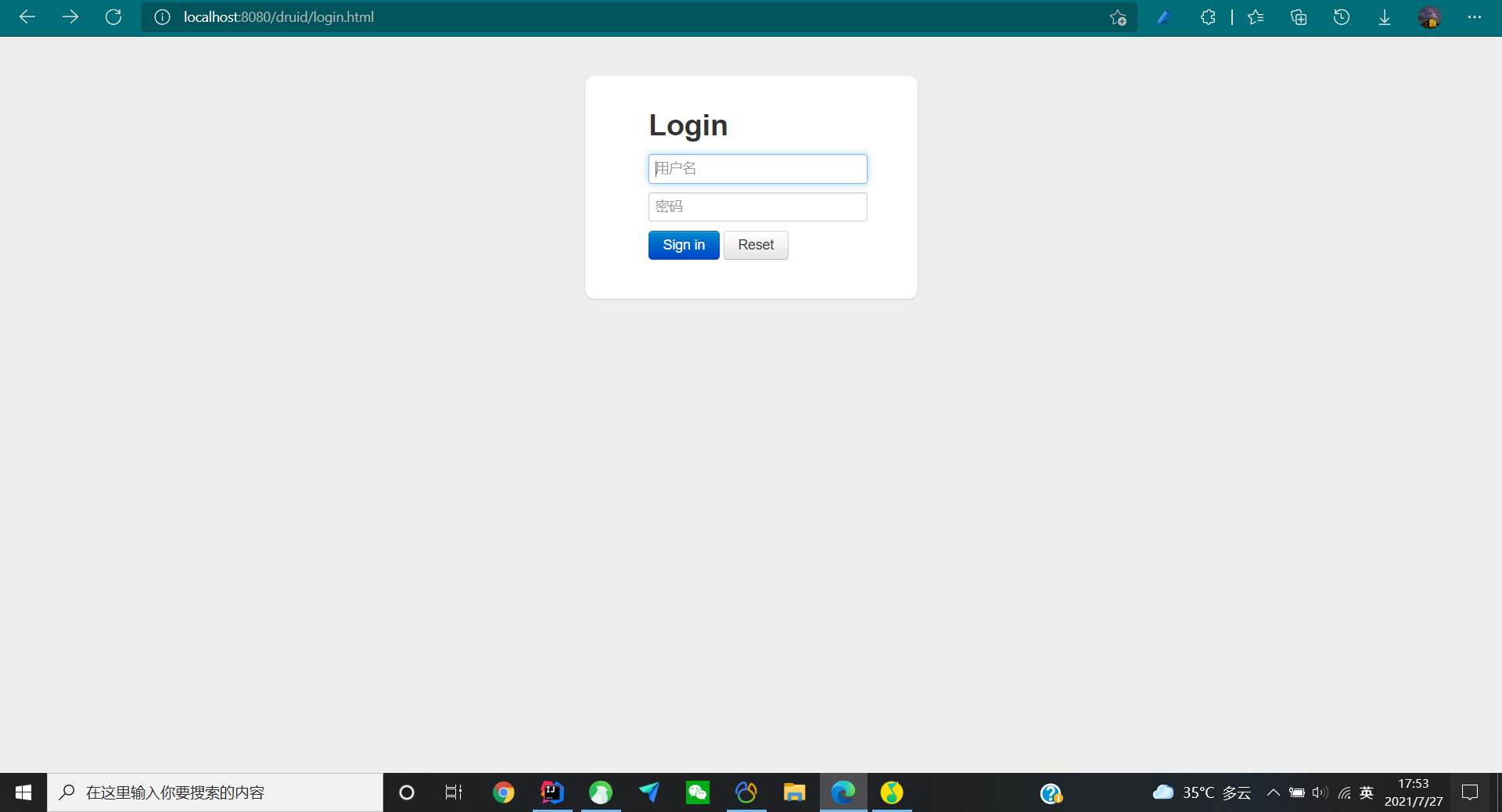

可见Druid后台提供强大的日志功能

若有收获,就点个赞吧
0 人点赞
