HashSet
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, java.io.Serializable
特点
- HashSet 底层是用 HashMap 实现的;
- Set 不能添加重复的元素;
初始化:
/*** Constructs a new, empty set; the backing <tt>HashMap</tt> instance has* default initial capacity (16) and load factor (0.75).*/public HashSet() {map = new HashMap<>();}
思考
已知,Set 不能添加重复的元素。则下面的运行结果分别是怎样的呢?(Person 是自定义类)
Set set = new HashSet();set.add("jack"); // 1. 添加成功set.add("jack"); // 2. 添加失败set.add(new Person("jack")); // 3. 添加成功set.add(new Person("jack")); // 4. 添加成功set.add(new String("tom")); // 5. 添加成功set.add(new String("tom")); // 6. 添加失败
- 序号1,2的结果是由于 Set不能添加重复的元素,所以当添加重复的常量字符串时,会添加失败;
- 序号3,4则是由于 new 关键字创建的对象引用不同,存放 Set 集合中的是对象引用地址,所以会添加成功;
- 5,6 有什么不一样呢?两个新建的 String 类型的对象为什么不能放到 Set 集合中?
答案:通过下面 add() 方法的分析,判断元素是否相等的逻辑为:if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
condition: ① && (② || ③)
① 要添加元素的 hash 值是否相等
② 对象的引用相同
③ 根据 equals() 方法判断是否相等
由于 String 内部重写了 equals() 方法,所以这里添加第二个 new String(“tom”) 时会判断 Set 中已经存在了相同的 String 对象,所以才会添加失败;
添加元素分析
- HashSet 底层的实现是 HashMap(数组 + 链表/红黑树),其中给数组声明为 table,table 中存放的元素是链表的第一个节点;
- 添加一个元素时,先得到其 hash 值,然后根据 hash 值转成一个数组的索引;
- 判断 table 该索引位置是否已经有存放元素;如果没有,直接加入;
- 如果有,则调用 equals 方法依次比较该索引位置的链表元素值,如果相同,就放弃添加;如果不同,则添加在最后;
- 在 Java 8 中,如果一条链表的元素个数达到 TREEIFY_THRESHOLD(默认为 8),并且 table 的大小大于等于 MIN_TREEIFY_CAPACITY(默认为 64),就会将链表树化,转化成红黑树;
add() 方法源码分析
// Dummy value to associate with an Object in the backing Map// private static final Object PRESENT = new Object(); 静态共享常量,占位public boolean add(E e) {return map.put(e, PRESENT)==null;}
- 执行 map.put() ```java public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
- 首先根据要添加的元素 key 计算出 hash 值;2. 执行 putval()- key : 要添加的元素;- hash:根据 key 计算的 hash 值,根据 hash 再计算 key 存放 table 中的索引;- value:PRESENT = new Object(); 静态共享常量,起占位作用;- table:HashMap 中存放节点的数组;- threshold:容量 * 负载因子(0.75);```java// The next size value at which to resize (capacity * load factor).int threshold;
/*** Implements Map.put and related methods.** @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i; // 定义辅助变量// 0. 这里是判断table是否初始化,table = null or table.length = 0 初始化tableif ((tab = table) == null || (n = tab.length) == 0) // table:存放元素的Node[]数组n = (tab = resize()).length; // resize():扩容-数组为空给table初始化16个空间// 根据key的hash值计算索引值,将table中该索引位置的结点赋值给p,并判断p是否为空if ((p = tab[i = (n - 1) & hash]) == null)//若p为null(当前位置没有元素)则创建新的结点Node保存当前要添加的数据,存储到当前索引位置tab[i] = newNode(hash, key, value, null);else {// 这里说明table当前索引位置的结点已经存在数据,下面分情况判断添加元素Node<K,V> e; K k;// 1. 判断要添加的元素(key)与table中当前索引位置的Node结点是否相同// condition: ① hash 值相等 && (② 引用相同 || ③ equals判断相等)if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))e = p;// 2. 判断当前索引位置元素结点是否是红黑树类型else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 3. 说明当前索引位置结点为链表,且第一个结点与要添加的元素key不同,就遍历链表判断key是否存在else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {// 如果key和链表中所有节点元素都不相同,则添加到链表最后p.next = newNode(hash, key, value, null);// 添加元素后判断当前链表是否已经有了8个节点,够8个则将当前链表转成红黑树// 这里调用treeifyBin()方法会判断table大小是否足够64个,到达64个才会树化// 不满 64 个空间,会先给 table 扩容if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break; // 退出 for 循环}// 如果要添加的元素key在链表中已经存在,则直接退出循环// condition: ① hash 值相等 && (② 引用相同 || ③ equals判断相等)if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))break;p = e; // 当前节点后移}}// 要添加的元素 key 已存在,则将重复的元素返回if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount; // 修改次数// 添加元素成功,table长度加1, 判断是否扩容if (++size > threshold)resize();afterNodeInsertion(evict); // HashMap 没有实现该方法, 供子类实现扩充功能// return null 表示要添加的元素在table中不存在, 添加成功return null;}
扩容机制
HashMap 名词介绍:
- table:HashMap 中存放元素的数组;
- threshold:临界值、阈值,达到临界值时就会给 table 扩容;
- loadFactor:table 的 加载因子,默认为 0.75 (The load factor for the hash table.);
- HashSet 底层是 HashMap,第一次添加元素时,table 数组默认会扩容到 16(1 << 4),默认初始化临界值 threshold 为 16 * loadFactor(0.75) = 12
- 如果 HashSet 的元素个数达到 threshold 临界值,就会对 table 扩容 16 2 = 32,新的临界值 threshold = 32 loadFactor
- 在 Java 8 中,如果一条链表的元素个数达到 TREEIFY_THRESHOLD(默认为 8),并且 table 的大小大于等于 MIN_TREEIFY_CAPACITY(默认为 64),就会将链表树化,转化成红黑树;若 table 的元素个数不到 64,就会对 table 进行扩容;
// 树化-将数组中的链表转成红黑树 final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; // 树化判断,table 数组的长度是否达到 64,未达到则进行数组扩容 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { // 树化 TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }阿里巴巴编码规约
【强制】关于 hashCode 和 equals 的处理,遵循如下规则:
- 只要覆写 equals,就必须覆写 hashCode。
- 因为 Set 存储的是不重复的对象,依据 hashCode 和 equals 进行判断,所以 Set 存储的对象必须覆 写这两个方法。
如果自定义对象作为 Map 的键,那么必须覆写 hashCode 和 equals。
说明:String 已覆写 hashCode 和 equals 方法,所以我们可以愉快地使用 String 对象作为 key 来使用。
LinkedHashSet
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable补充:这里 HashSet 已经实现了 Set 接口,这里为什么还要重复声明实现 Set 接口呢?
I've asked Josh Bloch, and he informs me that it was a mistake. He used to think, long ago, that there was some value in it, but he since "saw the light". Clearly JDK maintainers haven't considered this to be worth backing out later.说明
- LinkedHashSet 继承自 HashSet,是HashSet 的子类,且直接实现了 Set 接口;
- LinkedHashSet 底层是一个 LinkedHashMap(HashMap 的子类),底层维护了一个数组 + 双向链表;
- LinkedHashSet 有序, 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的;
-
存储过程
在 LinkedHashSet 中维护了一个 hash 表和双向链表(LinkedHashSet 有 head 和 tail);
- 每一个结点有 before 和 after 属性,这样可以形成双向链表;
- 在添加一个元素时,先求 hash 值,再求索引,确定该元素在 table 中的位置,然后将添加的元素加入到双向链表中(如果已经存在,不添加,原则和 HashSet 一样);
tail.next = newElement;
newElement.pre = null;
tail = newElement;
- 由于添加元素时依次形成了双向链表,所以在遍历 LinkedHashSet 时可以根据双向链表确保插入顺序和取出顺序一致;
对象构造过程
以无参构造作为参考:/** * @author zhangshuaiyin * @date 2021-04-19 09:38 */ public class C extends B{ public static void main(String[] args) { LinkedHashSet<Object> linkedHashSet = new LinkedHashSet<>(); linkedHashSet.add(1); linkedHashSet.add(2); linkedHashSet.add(3); linkedHashSet.add(4); linkedHashSet.add(5); System.out.println(linkedHashSet); } }public LinkedHashSet() { super(16, .75f, true); }
调用父类 HashSet 的构造器,HashSet 存储对象实际上用的时 HashMap 中的 数组 table + 链表;
HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); // 16 0.75 }HashSet 底层创建了 LinkedHashMap 对象作为存储对象的 map
public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); //16 0.75 accessOrder = false; }LinkedHashMap 构造器调用父类 HashMap 的构造器创建对象
public HashMap(int initialCapacity, float loadFactor) { //16 0.75 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }至此,LinkedHashSet 初始化完成,底层存储结构是 LinkedHashMap;
debug 查看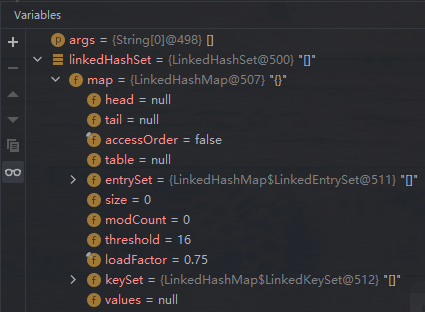
添加元素分析
public boolean add(E e) { return map.put(e, PRESENT)==null; }调用了 map 的 put 方法,后面同上面 HashSet 插入元素的 putVal 方法:当第一次添加元素时,会给 map 中的数组 table 扩容到 16;这时给 LinkedHashMap 的 head 和 tail 都指向当前元素;
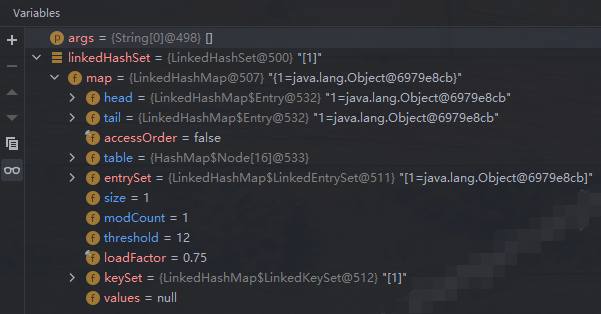
table 存储类型为 HashMap$Node[],而存储元素的类型为 LinkedHashMap$Entry,这里是因为 Entry 继承了 Node,且新增了 before、after 属性,分别指向双向链表的前一个结点和后一个结点。
// LinkedHashMap static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } // HashMap static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; // 在 Set 中添加的元素存储到 key 属性中 V value; // 在 Set 中 value 默认赋值为 PRESENT Node<K,V> next; // 链表的下一个元素,Set 中没用 // 构造器、内部方法等省略 // ... }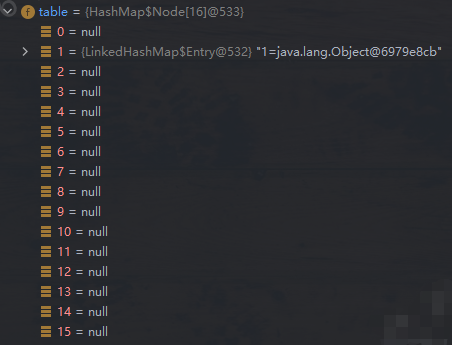
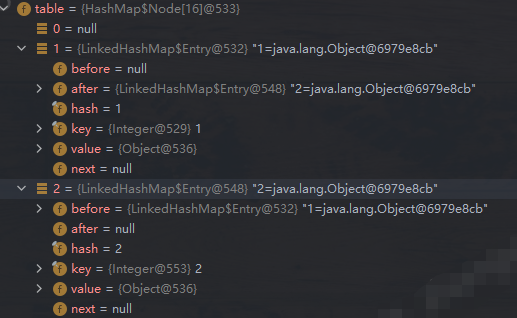
继续添加元素时,新添加的元素的 before 指向上一个添加的元素,上一个添加的元素的 after 指向新添加的元素;同时LinkedHashMap 的 head 和 tail 分别指向上一个添加的元素和新添加的元素;

TreeSet
- TreeSet 可以用于排序;
- 当使用无参构造器创建 TreeSet 是按照默认规则排序的;
- 可以使用指定排序规则的构造器使 TreeSet 按照指定规则排序;
- TreeSet 底层是用 TreeMap 实现的;
排序比较分析
```java // 这里使用 Comparator接口类型的实现类 作为参数的构造器,这里定义了排序规则 TreeSettreeSet = new TreeSet<>((s1, s2) -> s1.compareTo(s2));
treeSet.add(“a”); treeSet.add(“b”); treeSet.add(“c”);
还可以让引用类型实现 Comparable 接口,实现 compareTo 方法完成排序规则。
<a name="gDh1i"></a>
### 初始化
```java
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
添加元素
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
put() 方法
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) { // 初始化根节点
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) { // 按照指定规则进行排序
do { // 遍历树结点排序
parent = t;
// 这里会调用构造函数指定的排序方法进行比较
cmp = cpr.compare(key, t.key);
// 要添加的元素比当前节点小,遍历左结点(参考构造方法提供的规则)
if (cmp < 0)
t = t.left;
// 要添加的元素比当前节点大,遍历右结点
else if (cmp > 0)
t = t.right;
else // 按照规则相等(不一定是元素相同),替换 value(Map的方法)
return t.setValue(value);
} while (t != null);
}
else { // 按照默认规则排序
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}

若有收获,就点个赞吧
0 人点赞
