1.个性化排名
前面对电影数据集的处理只考虑了明确的反馈,通过观察到的等级进行了训练和测试。这种方法有两个缺点:
- 在实际应用中,大多数的反馈都是隐式的,显式的反馈往往需要更高的收集成本。
- 未被观察的哪些用户-项目交互可能用于预测用户的喜好但是被忽略了,当这些缺失不是随机导致的而是由于用户的喜好导致的这些方法将不在适用。很显然,未观测的这些用户-项目对是用户真实的负反馈(用户对这些不感兴趣才没看)和缺失值(正常随机的缺失,跟喜好无关,将来有可能会看)的结合体。如果简单的忽略其实是不对的。
为了解决这个问题,针对从隐式反馈生成排名推荐列表的一类推荐模型已获得普及。通常, 可以使用逐点、逐对以及逐列的方法优化个性化排名模型。逐点方法一次只考虑一次交互,并训练分类器或回归器来预测个人偏好。矩阵分解和AutoRec使用逐点目标进行了优化。 逐对方法为每一个用户考虑一对项目并且致力于为这对项目最优排序。通常, 逐对方法更适合于排序任务,因为预测一对的顺序会使人联想到排序。逐列方法将整列的项目近似排序, 如直接优化排名指标:Normalized Discounted Cumulative Gain (NDCG)。然而, 列表方法比点方法或成对方法更加复杂且计算量大。
1.1 贝叶斯个性化排序
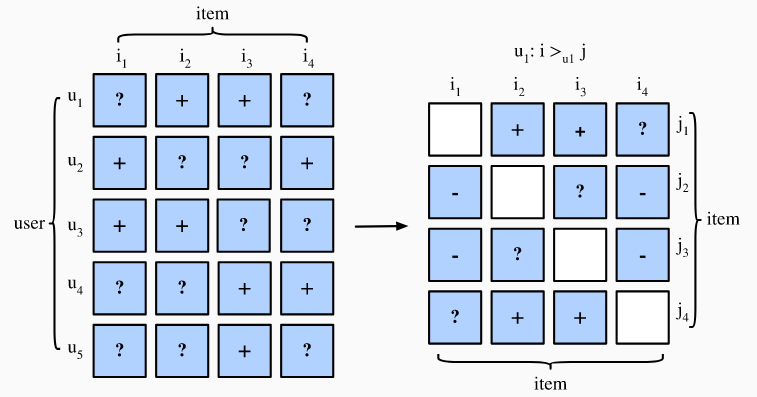
贝叶斯个性化排序(BPR)是从最大后验估计量得出的成对个性化排序损失。它已在许多现有推荐模型中广泛使用。BPR的训练数据包含正对和负对(缺失值)。假设用户相较于那些为观察到的项目更加喜欢正对的项目。
形式上,训练的数据有 #card=math&code=%28u%2C%20i%2C%20j%29)这个形式的元祖组成, 代表用户
喜欢项目
的程度超过项目
。 BPR的贝叶斯公式旨在最大程度上提高后验概率:
%20%20%5Cpropto%20%20p(%3E_u%20%5Cmid%20%5CTheta)%20p(%5CTheta)%0A#card=math&code=p%28%5CTheta%20%5Cmid%20%3E_u%20%29%20%20%5Cpropto%20%20p%28%3E_u%20%5Cmid%20%5CTheta%29%20p%28%5CTheta%29%0A)
是一个表示任意推荐模型的参数,
代表用户
对所有项目的期望排名。 我们可以制定最大后验估计量,以得出针对个性化排名任务的通用优化准则:
%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%20%5Cpropto%20%5Cln%20p(%3Eu%20%5Cmid%20%5CTheta)%20p(%5CTheta)%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%3D%20%5Cln%20%5Cprod%7B(u%2C%20i%2C%20j%20%5Cin%20D)%7D%20%5Csigma(%5Chat%7By%7D%7Bui%7D%20-%20%5Chat%7By%7D%7Buj%7D)%20p(%5CTheta)%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%3D%20%5Csum%7B(u%2C%20i%2C%20j%20%5Cin%20D)%7D%20%5Cln%20%5Csigma(%5Chat%7By%7D%7Bui%7D%20-%20%5Chat%7By%7D%7Buj%7D)%20%2B%20%5Cln%20p(%5CTheta)%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%3D%20%5Csum%7B(u%2C%20i%2C%20j%20%5Cin%20D)%7D%20%5Cln%20%5Csigma(%5Chat%7By%7D%7Bui%7D%20-%20%5Chat%7By%7D%7Buj%7D)%20-%20%5Clambda%5CTheta%20%5C%7C%5CTheta%20%5C%7C%5E2%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%5Ctext%7BBPR-OPT%7D%20%3A%20%26%3D%20%5Cln%20p%28%5CTheta%20%5Cmid%20%3E_u%29%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%20%5Cpropto%20%5Cln%20p%28%3E_u%20%5Cmid%20%5CTheta%29%20p%28%5CTheta%29%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%3D%20%5Cln%20%5Cprod%7B%28u%2C%20i%2C%20j%20%5Cin%20D%29%7D%20%5Csigma%28%5Chat%7By%7D%7Bui%7D%20-%20%5Chat%7By%7D%7Buj%7D%29%20p%28%5CTheta%29%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%3D%20%5Csum%7B%28u%2C%20i%2C%20j%20%5Cin%20D%29%7D%20%5Cln%20%5Csigma%28%5Chat%7By%7D%7Bui%7D%20-%20%5Chat%7By%7D%7Buj%7D%29%20%2B%20%5Cln%20p%28%5CTheta%29%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%26%3D%20%5Csum%7B%28u%2C%20i%2C%20j%20%5Cin%20D%29%7D%20%5Cln%20%5Csigma%28%5Chat%7By%7D%7Bui%7D%20-%20%5Chat%7By%7D%7Buj%7D%29%20-%20%5Clambda_%5CTheta%20%5C%7C%5CTheta%20%5C%7C%5E2%0A%5Cend%7Baligned%7D%0A)
%20%5Cmid%20i%20%5Cin%20I%5E%2Bu%20%5Cwedge%20j%20%5Cin%20I%20%5Cbackslash%20I%5E%2B_u%20%5C%7D#card=math&code=D%20%3A%3D%20%5C%7B%28u%2C%20i%2C%20j%29%20%5Cmid%20i%20%5Cin%20I%5E%2B_u%20%5Cwedge%20j%20%5Cin%20I%20%5Cbackslash%20I%5E%2B_u%20%5C%7D)是训练集,
表示 用户
喜欢的项目,
代表所有项目, 以及
代表用户不喜欢的项目。 和  分别为用户
对于
和
的预测分数。 先验
#card=math&code=p%28%5CTheta%29) 是一个均值为0并且方差-协方差矩阵为的的正太分布。这里我们让 .
我们将实现基类mxnet.gluon.loss.Loss并重写该forward方法以构造贝叶斯个性化排名损失。BPR损失的实现如下。
from mxnet import gluon, np, npxnpx.set_np()class BPRLoss(gluon.loss.Loss):def __init__(self, weight=None, batch_axis=0, **kwargs):super(BPRLoss, self).__init__(weight=None, batch_axis=0, **kwargs)def forward(self, positive, negative):distances = positive - negativeloss = - np.sum(np.log(npx.sigmoid(distances)), 0, keepdims=True)return loss
1.2 铰链损失
排名的铰链损失与gluon库中提供的 铰链损失不同,后者经常用于分类器,例如SVMs。 在推荐系统中用于排名的损失具有以下形式。
%7D%20%5Cmax(%20m%20-%20%5Chat%7By%7D%7Bui%7D%20%2B%20%5Chat%7By%7D%7Buj%7D%2C%200)%0A#card=math&code=%20%5Csum%7B%28u%2C%20i%2C%20j%20%5Cin%20D%29%7D%20%5Cmax%28%20m%20-%20%5Chat%7By%7D%7Bui%7D%20%2B%20%5Chat%7By%7D_%7Buj%7D%2C%200%29%0A)
是安全边际的大小。它目的是将负项目推向正项目。与BPR相似,它旨在优化正负样本之间的相关距离,而不是绝对输出,使其非常适合推荐系统。
class HingeLossbRec(gluon.loss.Loss):def __init__(self, weight=None, batch_axis=0, **kwargs):super(HingeLossbRec, self).__init__(weight=None, batch_axis=0,**kwargs)def forward(self, positive, negative, margin=1):distances = positive - negativeloss = np.sum(np.maximum(- distances + margin, 0))return loss
2. 神经协作过滤
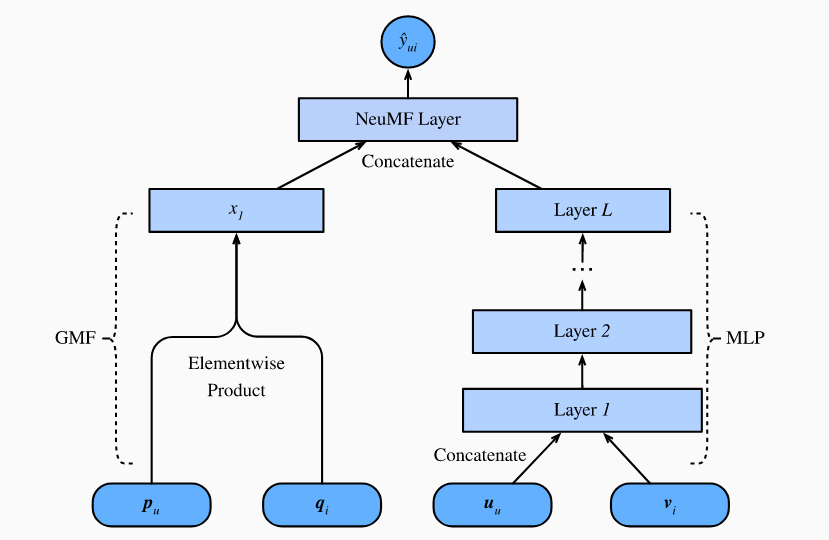
通过神经协作过滤(NCF)框架,用于带有隐式反馈的推荐。隐式反馈在推荐系统中无处不在。点击,购买和观看等操作是常见的隐式反馈,易于收集并指示用户的偏好。这里我们将介绍的模型称为NeuMF,是神经矩阵分解(neural matrix factorization)的缩写,旨在通过隐式反馈解决个性化排名任务。该模型利用神经网络的灵活性和非线性来代替矩阵分解的点积,旨在增强模型的表达能力。具体而言,该模型有两个子网络构成,包括广义矩阵分解(GMF)和MLP,并通过两个路径(而非简单的内部乘积)对相互作用进行建模。将这两个网络的输出连接起来以进行最终的预测分数计算。与AutoRec中的评分预测任务不同,此模型基于隐式反馈为每个用户生成一个排名推荐列表。我们将使用个性化排序损失来训练此模型。
3. NeuMF模型
如前所述, NeuMF 将两个子网结合在一起。 GMF是矩阵分解的通用神经网络版本,其中输入是用户和项目潜在因子的元素乘积。它由两个神经层组成:
%2C%0A#card=math&code=%5Cmathbf%7Bx%7D%20%3D%20%5Cmathbf%7Bp%7Du%20%5Codot%20%5Cmathbf%7Bq%7D_i%20%5C%5C%0A%5Chat%7By%7D%7Bui%7D%20%3D%20%5Calpha%28%5Cmathbf%7Bh%7D%5E%5Ctop%20%5Cmathbf%7Bx%7D%29%2C%0A)
表示向量的 Hadamard乘积,就是元素乘积。
并且
分别对应于用户和项目的潜在矩阵。
是
的
行以及
是
的第
行。
和
表示激活功能和输出层的权重。
是预测的用户
给项目
的评分。
该模型的另一个组件是MLP。为了丰富模型的灵活性, MLP子网不与GMF分享用户和项目的嵌入。它使用用户和项目嵌入的串联作为输入。通过复杂的连接和非线性转换,它能够估计用户和项目之间的复杂交互。更准确地说,MLP子网定义为:
%7D%20%26%3D%20%5Cphi1(%5Cmathbf%7BU%7D_u%2C%20%5Cmathbf%7BV%7D_i)%20%3D%20%5Cleft%5B%20%5Cmathbf%7BU%7D_u%2C%20%5Cmathbf%7BV%7D_i%20%5Cright%5D%20%5C%5C%0A%5Cphi%5E%7B(2)%7D(z%5E%7B(1)%7D)%20%20%26%3D%20%5Calpha%5E1(%5Cmathbf%7BW%7D%5E%7B(2)%7D%20z%5E%7B(1)%7D%20%2B%20b%5E%7B(2)%7D)%20%5C%5C%0A%26…%20%5C%5C%0A%5Cphi%5E%7B(L)%7D(z%5E%7B(L-1)%7D)%20%26%3D%20%5Calpha%5EL(%5Cmathbf%7BW%7D%5E%7B(L)%7D%20z%5E%7B(L-1)%7D%20%2B%20b%5E%7B(L)%7D))%20%5C%5C%0A%5Chat%7By%7D%7Bui%7D%20%26%3D%20%5Calpha(%5Cmathbf%7Bh%7D%5E%5Ctop%5Cphi%5EL(z%5E%7B(L-1)%7D))%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0Az%5E%7B%281%29%7D%20%26%3D%20%5Cphi1%28%5Cmathbf%7BU%7D_u%2C%20%5Cmathbf%7BV%7D_i%29%20%3D%20%5Cleft%5B%20%5Cmathbf%7BU%7D_u%2C%20%5Cmathbf%7BV%7D_i%20%5Cright%5D%20%5C%5C%0A%5Cphi%5E%7B%282%29%7D%28z%5E%7B%281%29%7D%29%20%20%26%3D%20%5Calpha%5E1%28%5Cmathbf%7BW%7D%5E%7B%282%29%7D%20z%5E%7B%281%29%7D%20%2B%20b%5E%7B%282%29%7D%29%20%5C%5C%0A%26…%20%5C%5C%0A%5Cphi%5E%7B%28L%29%7D%28z%5E%7B%28L-1%29%7D%29%20%26%3D%20%5Calpha%5EL%28%5Cmathbf%7BW%7D%5E%7B%28L%29%7D%20z%5E%7B%28L-1%29%7D%20%2B%20b%5E%7B%28L%29%7D%29%29%20%5C%5C%0A%5Chat%7By%7D%7Bui%7D%20%26%3D%20%5Calpha%28%5Cmathbf%7Bh%7D%5E%5Ctop%5Cphi%5EL%28z%5E%7B%28L-1%29%7D%29%29%0A%5Cend%7Baligned%7D%0A)
和
分别表示权重矩阵,偏差向量和激活函数。
表示相应层的功能。
表示相应层的输出。
为了融合GMF和MLP的结果,NeuMF串联了两个子网的倒数第二层,以创建一个可以传递到其他层的特征向量,而不是简单地相加。 然而,用矩阵投影输出 以及 sigmoid 激活函数。预测层的公式为:
%7D)%5D).%0A#card=math&code=%5Chat%7By%7D_%7Bui%7D%20%3D%20%5Csigma%28%5Cmathbf%7Bh%7D%5E%5Ctop%5B%5Cmathbf%7Bx%7D%2C%20%5Cphi%5EL%28z%5E%7B%28L-1%29%7D%29%5D%29.%0A)
下图说明了NeuMF的模型架构。
from d2l import mxnet as d2lfrom mxnet import autograd, gluon, np, npxfrom mxnet.gluon import nnimport mxnet as mxfrom plotly import express as pximport pandas as pdimport randomimport sysnpx.set_np()
4. 模型定义
以下代码实现了NeuMF模型。它由广义矩阵分解模型和具有不同用户和项目嵌入向量的多层感知器组成。MLP的结构由参数控制nums_hiddens。ReLU用作默认激活功能。
class NeuMF(nn.Block):def __init__(self, num_factors, num_users, num_items, nums_hiddens,**kwargs):super(NeuMF, self).__init__(**kwargs)self.P = nn.Embedding(num_users, num_factors)self.Q = nn.Embedding(num_items, num_factors)self.U = nn.Embedding(num_users, num_factors)self.V = nn.Embedding(num_items, num_factors)self.mlp = nn.Sequential()for num_hiddens in nums_hiddens:self.mlp.add(nn.Dense(num_hiddens, activation='relu', use_bias=True))self.prediction_layer = nn.Dense(1, activation='sigmoid', use_bias=False)def forward(self, user_id, item_id):p_mf = self.P(user_id)q_mf = self.Q(item_id)gmf = p_mf * q_mfp_mlp = self.U(user_id)q_mlp = self.V(item_id)mlp = self.mlp(np.concatenate([p_mlp, q_mlp], axis=1))con_res = np.concatenate([gmf, mlp], axis=1)return self.prediction_layer(con_res)
5. 带有负采样的自定义数据集
对于成对排名损失,重要的一步是负采样。对于每个用户,用户未与之交互的项目是候选项目(未观察到的条目)。以下功能将用户身份和候选项目作为输入,并从该用户的候选集中为每个用户随机抽取否定项目。在训练阶段,该模型可确保用户喜欢的商品的排名高于他不喜欢或未与之互动的商品。
class PRDataset(gluon.data.Dataset):
def __init__(self, users, items, candidates, num_items):
self.users = users
self.items = items
self.cand = candidates
self.num_items = num_items
def __len__(self):
return len(self.users)
def __getitem__(self, idx):
pos_items = set(self.cand[int(self.users[idx])])
while True:
indices = random.randint(0, num_items - 1)
if (indices not in pos_items):
break
return self.users[idx], self.items[idx], indices
6. 评估器
在本节中,我们采用按时间分割策略来构造训练和测试集。使用两种评估方法来评估模型的有效性:在给定截止时间的点击率 (
)以及 ROC曲线下的面积 (AUC)。为每一个用户指定位置的点击率
表示推荐的项目是否在前
排名列表中。正式定义如下:
%2C%0A#card=math&code=%5Ctext%7BHit%7D%40%5Cell%20%3D%20%5Cfrac%7B1%7D%7Bm%7D%20%5Csum%7Bu%20%5Cin%20%5Cmathcal%7BU%7D%7D%20%5Ctextbf%7B1%7D%28rank%7Bu%2C%20g_u%7D%20%3C%3D%20%5Cell%29%2C%0A)
表示一种指标函数:如果给定项目在前
列表中则返回1否则返回0。
表示项目在用户
推荐列表中的排名
(理想排名为 1)。
使用用户数。
是用户集。
AUC的定义如下:
%2C%0A#card=math&code=%5Ctext%7BAUC%7D%20%3D%20%5Cfrac%7B1%7D%7Bm%7D%20%5Csum%7Bu%20%5Cin%20%5Cmathcal%7BU%7D%7D%20%5Cfrac%7B1%7D%7B%7C%5Cmathcal%7BI%7D%20%5Cbackslash%20S_u%7C%7D%20%5Csum%7Bj%20%5Cin%20I%20%5Cbackslash%20Su%7D%20%5Ctextbf%7B1%7D%28rank%7Bu%2C%20gu%7D%20%3C%20rank%7Bu%2C%20j%7D%29%2C%0A)
是项目集。
是用户
的候选项目。注意,还可以使用许多其他评估协议,例如精度,召回率和归一化折现累积增益(NDCG)。
以下函数计算每个用户的点击数和AUC。
def hit_and_auc(rankedlist, test_matrix, k):
hits_k = [(idx, val) for idx, val in enumerate(rankedlist[:k]) if val in set(test_matrix)]
hits_all = [(idx, val) for idx, val in enumerate(rankedlist) if val in set(test_matrix)]
max_num = len(rankedlist) - 1
auc = 1.0 * (max_num - hits_all[0][0]) / max_num if len(hits_all) > 0 else 0
return len(hits_k), auc
然后,总命中率和AUC的计算如下。
def evaluate_ranking(net, test_input, seq, candidates, num_users, num_items,
devices):
ranked_list, ranked_items, hit_rate, auc = {}, {}, [], []
all_items = set([i for i in range(num_users)])
for u in range(num_users):
neg_items = list(all_items - set(candidates[int(u)]))
x, scores = [], []
item_ids = neg_items
user_ids = [u] * len(neg_items)
x.extend([np.array(user_ids)])
if seq is not None:
x.append(seq[user_ids, :])
x.extend([np.array(item_ids)])
test_data_iter = gluon.data.DataLoader(gluon.data.ArrayDataset(*x),
shuffle=False, last_batch="keep",batch_size=1024)
for index, values in enumerate(test_data_iter):
x = [gluon.utils.split_and_load(v, devices, even_split=False) for v in values]
scores.extend([list(net(*t).asnumpy()) for t in zip(*x)])
scores = [item for sublist in scores for item in sublist]
item_scores = list(zip(item_ids, scores))
ranked_list[u] = sorted(item_scores, key=lambda t: t[1], reverse=True)
ranked_items[u] = [r[0] for r in ranked_list[u]]
temp = hit_and_auc(ranked_items[u], test_input[u], 50)
hit_rate.append(temp[0])
auc.append(temp[1])
return np.mean(np.array(hit_rate)), np.mean(np.array(auc))
7. 模型训练和评估
训练功能定义如下。我们以成对方式训练模型。
def train_ranking(net, train_iter, test_iter, loss, trainer, test_seq_iter,
num_users, num_items, num_epochs, devices, evaluator, candidates, eval_step=1):
timer, hit_rate, auc, data = d2l.Timer(), 0, 0, []
for epoch in range(num_epochs):
metric, l = d2l.Accumulator(3), 0.
for i, values in enumerate(train_iter):
input_data = []
for v in values:
input_data.append(gluon.utils.split_and_load(v, devices))
with autograd.record():
p_pos = [net(*t) for t in zip(*input_data[0:-1])]
p_neg = [net(*t) for t in zip(*input_data[0:-2], input_data[-1])]
ls = [loss(p, n) for p, n in zip(p_pos, p_neg)]
for l in ls:
l.backward(retain_graph=False)
l += sum([l.asnumpy() for l in ls]).mean()/len(devices)
trainer.step(values[0].shape[0])
metric.add(l, values[0].shape[0], values[0].size)
timer.stop()
with autograd.predict_mode():
if (epoch + 1) % eval_step == 0:
hit_rate, auc = evaluator(net, test_iter, test_seq_iter,
candidates, num_users, num_items, devices)
data.append((epoch + 1, hit_rate, auc))
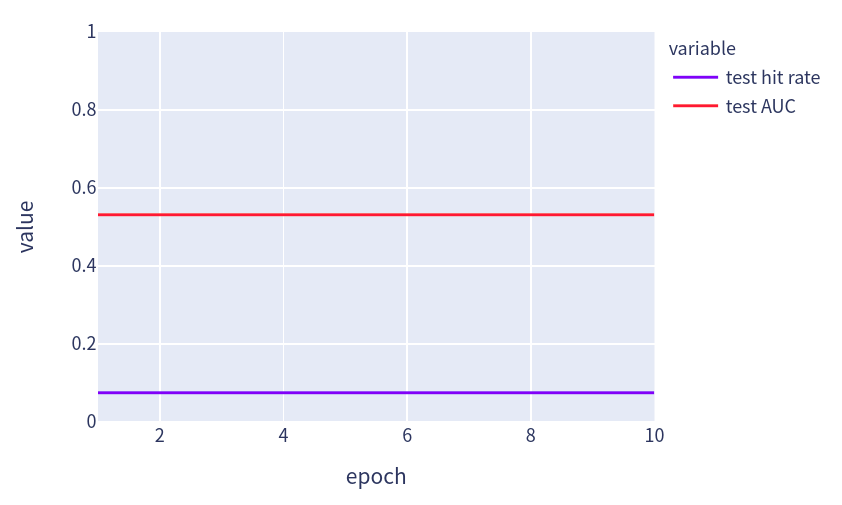
print(f'[epoch {epoch + 1:>2}] test hit rate: {float(hit_rate):.3f}; test AUC: {float(auc):.3f}')
print(f'train loss {metric[0] / metric[1]:.3f}, test hit rate {float(hit_rate):.3f}, test AUC {float(auc):.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {str(devices)}')
fig = px.line(pd.DataFrame(data, columns=['epoch', 'test hit rate', 'test AUC']), x='epoch', y=[ 'test hit rate', 'test AUC'], width=580, height=400)
fig.show()
我们可以加载MovieLens 100k数据集并训练模型。由于MovieLens数据集中只有等级,但准确性有所下降,因此我们将这些等级二进制化为零和一。如果用户对某项进行评分,我们会将隐式反馈视为1,否则视为零。对项目进行评分的动作可以视为提供隐式反馈的一种形式。在这里,我们将数据集拆分为以下seq-aware模式:用户最新互动的项目被排除在测试之外。
batch_size = 1024
df, num_users, num_items = d2l.read_data_ml100k()
train_data, test_data = d2l.split_data_ml100k(df, num_users, num_items, 'seq-aware')
users_train, items_train, ratings_train, candidates = d2l.load_data_ml100k(
train_data, num_users, num_items, feedback="implicit")
users_test, items_test, ratings_test, test_iter = d2l.load_data_ml100k(
test_data, num_users, num_items, feedback="implicit")
train_iter = gluon.data.DataLoader(
PRDataset(users_train, items_train, candidates, num_items ),
batch_size, True, last_batch="rollover", num_workers=d2l.get_dataloader_workers()
)
然后,我们创建并初始化模型。我们使用具有恒定隐藏大小10的三层MLP。以下代码训练模型。
devices = d2l.try_all_gpus()
net = NeuMF(10, num_users, num_items, nums_hiddens=[10, 10, 10])
net.initialize(ctx=devices, force_reinit=True, init=mx.init.Normal(0.01))
lr, num_epochs, wd, optimizer = 0.01, 10, 1e-5, 'adam'
loss = d2l.BPRLoss()
trainer = gluon.Trainer(net.collect_params(), optimizer, {"learning_rate": lr, 'wd': wd})
train_ranking(net, train_iter, test_iter, loss, trainer, None, num_users,
num_items, num_epochs, devices, evaluate_ranking, candidates)

8. 参考
https://d2l.ai/chapter_recommender-systems/neumf.html#the-neumf-model
9.代码

若有收获,就点个赞吧
0 人点赞
