前面的几种推荐系统都是通过将任务抽象为矩阵完成,并没有考虑到用户的短期行为,人类的喜好是会随着生活学习经历而改变的,往往短期内的反馈最能代表一个人的兴趣。本篇介绍一种考虑用户交互顺序的推荐模型:序列感知推荐(sequence-aware recommender),它的输入是用户带有时间戳的交互列表。
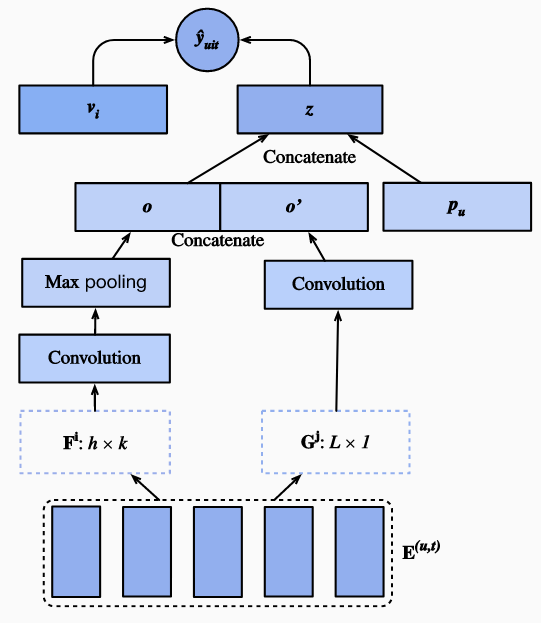
这里介绍的序列感知模型 Caser是 卷积序列嵌入推荐模型(convolutional sequence embedding recommendation model)的缩写,采用卷积神经网络捕获用户最近活动的动态模式影响。 Caser的主要组成部分为水平卷积网络和垂直卷积网络, 分别用于发现联级和点级的序列模式:
- 点级模式指示历史序列中的单个项目对目标项目的影响
- 联级模式则指示多个先前操作对后续目标的影响。
例如,同时购买牛奶和黄油会导致购买面粉的可能性高于仅购买其中之一。此外,用户的总体兴趣或长期偏好也会在最后的全连接层中进行建模,从而对用户兴趣进行更全面的建模。
Caser模型
在序列感知推荐系统中, 每一个用户都与项目集合中的一些项目组成的项目序列相关联。让 #card=math&code=S%5Eu%20%3D%20%28S1%5Eu%2C%20…%20S%7B%7CS_u%7C%7D%5Eu%29) 代表排序之后的项目序列。 Caser的目标是通过用户的一般口味和短期意图共同作用来推荐产品。 将前
个项目纳入考虑范围, 用户以往前
个时间步的互动可以构建成一个嵌入矩阵:
%7D%20%3D%20%5B%20%5Cmathbf%7Bq%7D%7BS%7Bt-L%7D%5Eu%7D%20%2C%20…%2C%20%5Cmathbf%7Bq%7D%7BS%7Bt-2%7D%5Eu%7D%2C%20%5Cmathbf%7Bq%7D%7BS%7Bt-1%7D%5Eu%7D%20%5D%5E%5Ctop%2C%0A#card=math&code=%5Cmathbf%7BE%7D%5E%7B%28u%2C%20t%29%7D%20%3D%20%5B%20%5Cmathbf%7Bq%7D%7BS%7Bt-L%7D%5Eu%7D%20%2C%20…%2C%20%5Cmathbf%7Bq%7D%7BS%7Bt-2%7D%5Eu%7D%2C%20%5Cmathbf%7Bq%7D%7BS%7Bt-1%7D%5Eu%7D%20%5D%5E%5Ctop%2C%0A)
代表项目嵌入以及
表示第
行。
%7D%20%5Cin%20%5Cmathbb%7BR%7D%5E%7BL%20%5Ctimes%20k%7D#card=math&code=%5Cmathbf%7BE%7D%5E%7B%28u%2C%20t%29%7D%20%5Cin%20%5Cmathbb%7BR%7D%5E%7BL%20%5Ctimes%20k%7D) 可以用来推断用户
在
步的时候的兴趣。我们将
%7D#card=math&code=%5Cmathbf%7BE%7D%5E%7B%28u%2C%20t%29%7D)看成一个图像数据输入到之后的两个卷积模块。
水平卷积层有 个水平过滤器
, 垂直卷积层有
垂直过滤器
。经过一系列的卷积池化处理,我们获得2个输出:
%7D%2C%20%5Cmathbf%7BF%7D)%20%5C%5C%0A%5Cmathbf%7Bo%7D’%3D%20%5Ctext%7BVConv%7D(%5Cmathbf%7BE%7D%5E%7B(u%2C%20t)%7D%2C%20%5Cmathbf%7BG%7D)%20%2C%0A#card=math&code=%5Cmathbf%7Bo%7D%20%3D%20%5Ctext%7BHConv%7D%28%5Cmathbf%7BE%7D%5E%7B%28u%2C%20t%29%7D%2C%20%5Cmathbf%7BF%7D%29%20%5C%5C%0A%5Cmathbf%7Bo%7D%27%3D%20%5Ctext%7BVConv%7D%28%5Cmathbf%7BE%7D%5E%7B%28u%2C%20t%29%7D%2C%20%5Cmathbf%7BG%7D%29%20%2C%0A)
是水平卷积网络的输出 以及
垂直神经网路的输出。这里为了简单起见,省略了卷积和池的操作信息。将它们串联起来,并馈入一个全连接神经层,以获取高层级表示。
%2C%0A#card=math&code=%5Cmathbf%7Bz%7D%20%3D%20%5Cphi%28%5Cmathbf%7BW%7D%5B%5Cmathbf%7Bo%7D%2C%20%5Cmathbf%7Bo%7D%27%5D%5E%5Ctop%20%2B%20%5Cmathbf%7Bb%7D%29%2C%0A)
%7D#card=math&code=%5Cmathbf%7BW%7D%20%5Cin%20%5Cmathbb%7BR%7D%5E%7Bk%20%5Ctimes%20%28d%20%2B%20kd%27%29%7D) 是权重矩阵,
是偏移。 学习的
向量表示用户的短期意图。
最后,预测函数将用户的一般兴趣和近期兴趣结合在一起:
是另一个项目嵌入矩阵。
是项目特定偏差。
是用户一般兴趣的嵌入矩阵。
是
的第
行 ,
是
的第
行。
可以通过BPR或铰链损失学习模型。Caser的体系结构如下图所示:
下面通过代码完成模型:
from d2l import mxnet as d2lfrom mxnet import gluon, np, npx, autograd, initfrom mxnet.gluon import nnimport mxnet as mxfrom plotly import express as pximport pandas as pdimport randomimport sysnpx.set_np()
2. 模型设计
以下代码实现了Caser模型。它由垂直卷积层,水平卷积层和全连接层组成。
class Caser(nn.Block):def __init__(self, num_factors, num_users, num_items, L=5, d=16,d_prime=4, drop_ratio=0.05, **kwargs):super(Caser, self).__init__(**kwargs)self.P = nn.Embedding(num_users, num_factors)self.Q = nn.Embedding(num_items, num_factors)self.d_prime, self.d = d_prime, d# 垂直卷积层self.conv_v = nn.Conv2D(d_prime, (L, 1), in_channels=1)# 水平卷积层self.conv_h, self.max_pool = nn.Sequential(), nn.Sequential()for i in range(L):self.conv_h.add(nn.Conv2D(d, (i+1, num_factors), in_channels=1))self.max_pool.add(nn.MaxPool1D(L - i ))# 全连接层self.fc1_dim_v, self.fc1_dim_h = d_prime * num_factors, d * Lself.fc = nn.Dense(in_units=d_prime * num_factors + d * L, activation='relu', units=num_factors)self.Q_prime = nn.Embedding(num_items, num_factors * 2)self.b = nn.Embedding(num_items, 1)self.dropout = nn.Dropout(drop_ratio)def forward(self, user_id, seq, item_id):item_embs = np.expand_dims(self.Q(seq), 1)user_emb = self.P(user_id)out, out_h, out_v, out_hs = None, None, None, []if self.d_prime:out_v = self.conv_v(item_embs)out_v = out_v.reshape(out_v.shape[0], self.fc1_dim_v)if self.d:for conv, maxp in zip(self.conv_h, self.max_pool):conv_out = np.squeeze(npx.relu(conv(item_embs)), axis=3)t = maxp(conv_out)pool_out = np.squeeze(t, axis=2)out_hs.append(pool_out)out_h = np.concatenate(out_hs, axis=1)out = np.concatenate([out_v, out_h], axis=1)z = self.fc(self.dropout(out))x = np.concatenate([z, user_emb], axis=1)q_prime_i = np.squeeze(self.Q_prime(item_id))b = np.squeeze(self.b(item_id))res = (x * q_prime_i).sum(1) + breturn res
3.负采样的顺序数据集
要处理顺序交互数据,我们需要重新实现Dataset类。以下代码创建一个名为的新数据集类 SeqDataset。在每个样本中, 对于输入的用户特征, 它的前 个交互项目做为序列(sequence)并且下一个交互项目作为目标(target)。 下图演示了一个用户的数据加载过程。假设该用户喜欢9部电影,我们按时间顺序组织这9部电影。 最后一个电影作为测试。剩下的8部电影,在每个样本序列为5个电影(
)时可以获得3个训练样本,序列的后一个电影作为目标项。负样本也包含在定制数据集中。
class SeqDataset(gluon.data.Dataset):
def __init__(self, user_ids, item_ids, L, num_users, num_items,
candidates):
user_ids, item_ids = np.array(user_ids), np.array(item_ids)
# 将userid排序,按照userid的顺序同时将item排序
sort_idx = np.array(sorted(range(len(user_ids)),
key=lambda k: user_ids[k]))
u_ids, i_ids = user_ids[sort_idx], item_ids[sort_idx]
temp, u_ids, self.cand = {}, u_ids.asnumpy(), candidates
self.num_items = num_items
[temp.setdefault(u_ids[i], []).append(i) for i, _ in enumerate(u_ids)]
temp = sorted(temp.items(), key=lambda x: x[0])
u_ids = np.array([i[0] for i in temp])
idx = np.array([i[1][0] for i in temp])
# 获取根据L长度进行处理之后的样本数
self.ns = ns = int(sum([c - L if c >= L + 1 else 1 for c
in np.array([len(i[1]) for i in temp])]))
self.seq_items = np.zeros((ns, L))
self.seq_users = np.zeros(ns, dtype='int32')
self.seq_tgt = np.zeros((ns, 1))
self.test_seq = np.zeros((num_users, L))
test_users, _uid = np.empty(num_users), None
for i, (uid, i_seq) in enumerate(self._seq(u_ids, i_ids, idx, L + 1)):
if uid != _uid:
self.test_seq[uid][:] = i_seq[-L:]
test_users[uid], _uid = uid, uid
self.seq_tgt[i][:] = i_seq[-1:]
self.seq_items[i][:], self.seq_users[i] = i_seq[:L], uid
def _win(self, tensor, window_size, step_size=1):
if len(tensor) - window_size >= 0:
for i in range(len(tensor), 0, - step_size):
if i - window_size >= 0:
yield tensor[i - window_size:i]
else:
break
else:
yield tensor
def _seq(self, u_ids, i_ids, idx, max_len):
for i in range(len(idx)):
stop_idx = None if i >= len(idx) - 1 else int(idx[i + 1])
for s in self._win(i_ids[int(idx[i]):stop_idx], max_len):
yield (int(u_ids[i]), s)
def __len__(self):
return self.ns
def __getitem__(self, idx):
pos = set(self.cand[int(self.seq_users[idx])])
i = random.randint(0, this.num_items - 1)
while i in pos:
i = random.randint(0, num_items - 1)
return (self.seq_users[idx], self.seq_items[idx], self.seq_tgt[idx], i)
4. 加载MovieLens 100K数据集
然后,我们以顺序感知模式读取和拆分MovieLens 100K数据集,并使用上面实现的顺序数据加载器加载训练数据。
TARGET_NUM, L, batch_size = 1, 3, 4096
df, num_users, num_items = d2l.read_data_ml100k()
train_data, test_data = d2l.split_data_ml100k(df, num_users, num_items,
'seq-aware')
users_train, items_train, ratings_train, candidates = d2l.load_data_ml100k(
train_data, num_users, num_items, feedback="implicit")
users_test, items_test, ratings_test, test_iter = d2l.load_data_ml100k(
test_data, num_users, num_items, feedback="implicit")
train_seq_data = SeqDataset(users_train, items_train, L, num_users,
num_items, candidates)
train_iter = gluon.data.DataLoader(train_seq_data, batch_size, True,
last_batch="rollover", num_workers=d2l.get_dataloader_workers())
test_seq_iter = train_seq_data.test_seq
train_seq_data[0]
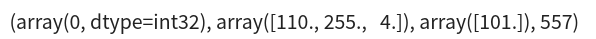
训练数据结构如上所示。第一个元素是用户身份,第二个列表指示该用户喜欢的最近3个项目,第三个元素为目标,最后一个元素是该用户未交互的一个项目。
5. 训练模型
现在,让我们训练模型。
def train_ranking(net, train_iter, test_iter, loss, trainer, test_seq_iter,
num_users, num_items, num_epochs, devices, evaluator, candidates, eval_step=1):
timer, hit_rate, auc, data = d2l.Timer(), 0, 0, []
for epoch in range(num_epochs):
metric, l = d2l.Accumulator(3), 0.
for i, values in enumerate(train_iter):
timer.start()
input_data = []
for v in values:
input_data.append(gluon.utils.split_and_load(v, devices))
with autograd.record():
p_pos = [net(*t) for t in zip(*input_data[0:-1])]
p_neg = [net(*t) for t in zip(*input_data[0:-2], input_data[-1])]
ls = [loss(p, n) for p, n in zip(p_pos, p_neg)]
for l in ls:
l.backward(retain_graph=False)
l += sum([l.asnumpy() for l in ls]).mean()/len(devices)
trainer.step(values[0].shape[0])
metric.add(l, values[0].shape[0], values[0].size)
timer.stop()
with autograd.predict_mode():
if (epoch + 1) % eval_step == 0:
hit_rate, auc = evaluator(net, test_iter, test_seq_iter,
candidates, num_users, num_items, devices)
data.append((epoch + 1, hit_rate, auc))
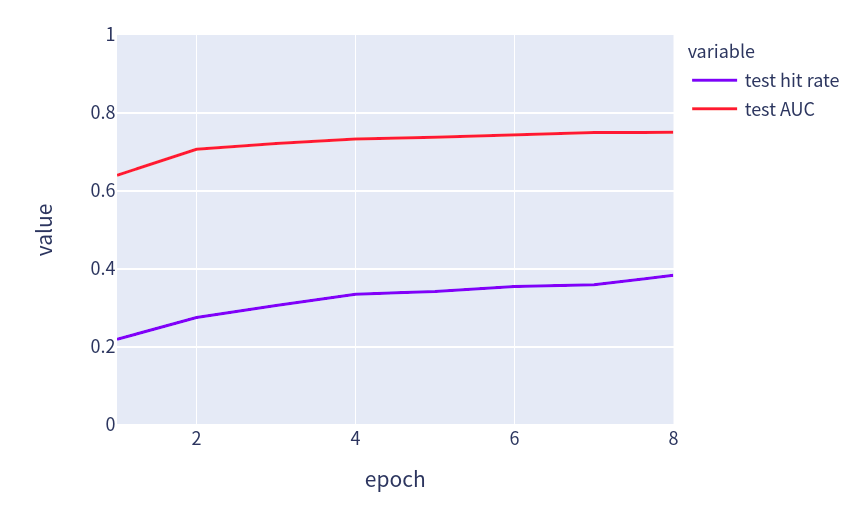
print(f'[epoch {epoch + 1:>2}] test hit rate: {float(hit_rate):.3f}; test AUC: {float(auc):.3f}')
print(f'train loss {metric[0] / metric[1]:.3f}, test hit rate {float(hit_rate):.3f}, test AUC {float(auc):.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {str(devices)}')
fig = px.line(pd.DataFrame(data, columns=['epoch', 'test hit rate', 'test AUC']), x='epoch', y=[ 'test hit rate', 'test AUC'], width=580, height=400, range_y=[0,1])
fig.show()
我们使用与NeuMF相同的设置,包括学习率,优化程序和 k ,在最后一节中,这样结果是可比的。
devices = d2l.try_all_gpus()
net = Caser(10, num_users, num_items, L)
net.initialize(ctx=devices, force_reinit=True, init=mx.init.Normal(0.01))
lr, num_epochs, wd, optimizer = 0.04, 8, 1e-5, 'adam'
loss = d2l.BPRLoss()
trainer = gluon.Trainer(net.collect_params(), optimizer, {"learning_rate": lr, 'wd': wd})
train_ranking(net, train_iter, test_iter, loss, trainer, test_seq_iter,num_users,
num_items, num_epochs, devices, d2l.evaluate_ranking, candidates, eval_step=1)

6. 参考
https://d2l.ai/chapter_recommender-systems/seqrec.html
7.代码

若有收获,就点个赞吧
0 人点赞
