自然语言推理是通过已知的前提文本来确定能否推断目的文本。也就是说,自然语言推理用于确定一对文本序列之间的关系:
- 蕴含: 可以通过前提推断出假设。
- 矛盾: 可以推断出与假设相反。
- 中立: 所有其他情况。
自然语言推理也可以理解为识别文本的蕴含的任务。
For example, 下面一对文本可以使用 蕴含物 进行标注因为 假设中的”显示出喜欢”可以通过前提中的 “相互拥抱”中推断出来。
前提: 两个女人互相拥抱。
假设: 两个女人显示出喜欢。
下面是一个展示矛盾的例子,“运行编码示例”表示“没有睡觉”而不是“睡觉了”。
前提:一个男人正在运行 《Dive into Deep Learning》的编码示例。
假设: 这个男人正在睡觉。
下面的例子展示中立关系,因为从给我们演奏并看不出有不有名。
前提: 音乐家们正在为我们演奏。
假设: 音乐家们都很有名。
自然语言推理一直是理解自然语言的中心主题。它具有从信息检索到开放域问题解答的广泛应用。为了研究这个问题,我们将从研究一种流行的自然语言推理基准数据集开始。
1. 斯坦福大学自然语言推理(SNLI)数据集
斯坦福自然语言推理(SNLI)语料库是 500,000 标记为英语的句子对。下载数据集到本地。
import collectionsfrom d2l import mxnet as d2lfrom mxnet import gluon, np, npximport osimport reimport zipfilenpx.set_np()d2l.DATA_HUB['SNLI'] = ('https://nlp.stanford.edu/projects/snli/snli_1.0.zip','9fcde07509c7e87ec61c640c1b2753d9041758e4')data_dir = d2l.download_extract('SNLI')
1.1 读取数据
原始SNLI数据集包含的信息比我们在实验中真正需要的信息丰富得多。定义一个函数用于获取数据集的部分数据,返回需要的前提,假设以及对应的标签。
def read_snli(data_dir, is_train):"""读取SNLI数据集"""def extract_text(s):# 移除括号s = re.sub('\\(', '', s)s = re.sub('\\)', '', s)# 使用一个空格替换两个以上连续空格s = re.sub('\\s{2,}', ' ', s)return s.strip()# 设置标签0:蕴含,1:矛盾,2:无关label_set = {'entailment': 0, 'contradiction': 1, 'neutral': 2}file_name = os.path.join(data_dir, 'snli_1.0_train.txt' if is_train else 'snli_1.0_test.txt')with open(file_name, 'r') as f:rows = [row.split('\t') for row in f.readlines()[1:]]premises = [extract_text(row[1]) for row in rows if row[0] in label_set]hypotheses = [extract_text(row[2]) for row in rows if row[0] in label_set]labels = [label_set[row[0]] for row in rows if row[0] in label_set]return premises, hypotheses, labels
现在让我们打印第一个 3 对的前提和假设,以及它们的标签(“ 0”,“ 1”和“ 2”分别对应于“蕴涵”,“矛盾”和“中立”)。
train_data = read_snli(data_dir, is_train=True)for x0, x1, y in zip(train_data[0][:3], train_data[1][:3], train_data[2][:3]):print('premise:', x0)print('hypothesis:', x1)print('label:', y)

例子1,骑马跳过飞机看不出是否要参加比赛,因此无关标签为2:
前提:一个人骑着马跳过一架故障飞机。
假设:一个人正在训练他的马参加比赛。
标签:2
例子2,正在骑马不可能能正在用餐,很显然是矛盾的,标签为1:
前提:一个人骑着马跳过一架故障飞机。
假设:一个人正在用餐,点了煎蛋。
标签:1
例子3,骑马跳过飞机,那么可以推断其在户外骑马(一定是户外么。。),标签为0:
前提:一个人骑着马跳过一架故障飞机。
假设:一个人在户外骑马。
标签:0
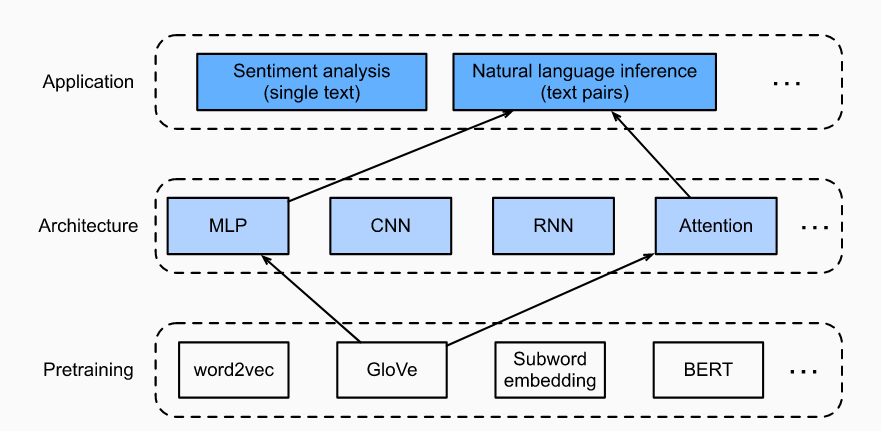
加载测试集,训练集约 550,000 对,测试集大约有 10,000 对。对于数据集来说,三种标签数量是均衡的。
test_data = read_snli(data_dir, is_train=False)for data in [train_data, test_data]:print([[row for row in data[2]].count(i) for i in range(3)])
1.2 数据加载
通过继承gluon的Dataset类编写我们的SNLIDataset类,用于加载数据。通过numsteps限定文本序列的长度,以便序列形状相同,长的截取,不足的用pad标签补足。`_getitem`方法可以通过索引访问数据的前提,假设和标签。
class SNLIDataset(gluon.data.Dataset):def __init__(self, dataset, num_steps, vocab=None):self.num_steps = num_stepsall_premise_tokens = d2l.tokenize(dataset[0])all_hypothesis_tokens = d2l.tokenize(dataset[1])if vocab is None:self.vocab = d2l.Vocab(all_premise_tokens + all_hypothesis_tokens,min_freq=5, reserved_tokens=['<pad>'])else:self.vocab = vocabself.premises = self._pad(all_premise_tokens)self.hypotheses = self._pad(all_hypothesis_tokens)self.labels = np.array(dataset[2])print('read ' + str(len(self.premises)) + ' examples')def _pad(self, lines):return np.array([d2l.truncate_pad(self.vocab[line], self.num_steps, self.vocab['<pad>'])for line in lines])def __getitem__(self, idx):return (self.premises[idx], self.hypotheses[idx]), self.labels[idx]def __len__(self):return len(self.premises)
1.3 获取数据迭代器
通过上面的类以及函数编写获取数据迭代器的函数。值得注意的是,我们必须使用从训练集中构造的词汇作为测试集中的词汇。结果,来自测试集的任何新令牌对于在训练集上训练的模型都是未知的。
def load_data_snli(batch_size, num_steps=50):num_workers = d2l.get_dataloader_workers()data_dir = d2l.download_extract('SNLI')train_data = read_snli(data_dir, True)test_data = read_snli(data_dir, False)train_set = SNLIDataset(train_data, num_steps)test_set = SNLIDataset(test_data, num_steps, train_set.vocab)train_iter = gluon.data.DataLoader(train_set, batch_size, shuffle=True,num_workers=num_workers)test_iter = gluon.data.DataLoader(test_set, batch_size, shuffle=False,num_workers=num_workers)return train_iter, test_iter, train_set.vocab
在这里,我们将批量大小设置为 128 和序列长度为 50 ,并调用该load_data_snli函数以获取数据迭代器和词汇表。然后我们打印词汇量。
train_iter, test_iter, vocab = load_data_snli(128, 50)len(vocab)
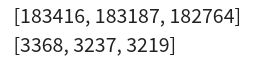
2. 注意力机制
使用“可分解的注意力模型”可以不适用循环层或是卷积层的情况下,在SNLI数据集上使用更少的参数达到了最佳结果。

我们只需将一个文本序列中的单词与另一个文本中的每个单词对齐,反之亦然,然后比较并汇总这些信息以预测前提和假设之间的逻辑关系。与机器翻译中源句子和目标句子之间的单词对齐类似,前提和假设之间的单词对齐可以通过注意力机制很好地完成。 下图描述了使用注意力机制的自然语言推理方法,一共三个步骤:
- Attending(注意,对齐)
- comparing(比较)
- aggregating(汇总)
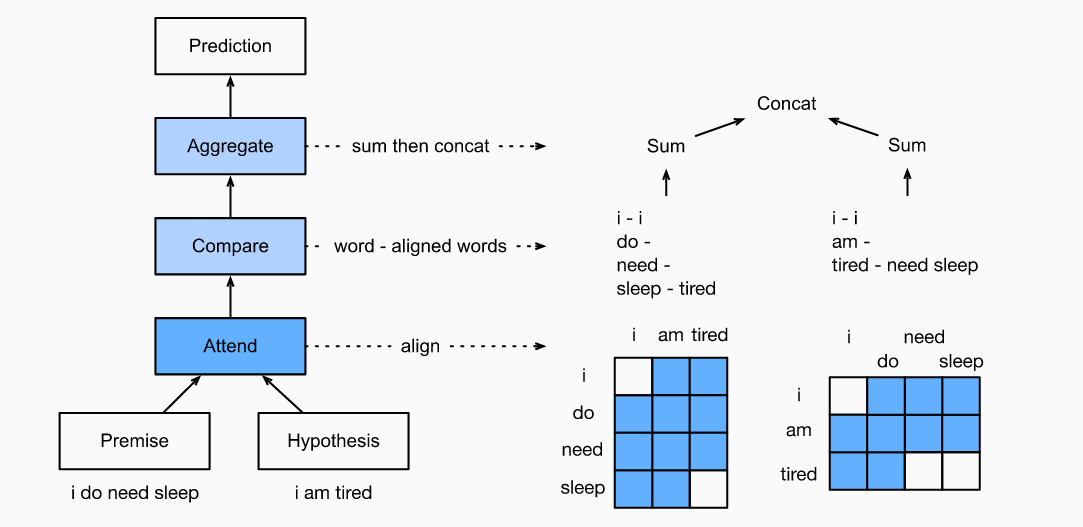
2.1 Attending(注意,对齐)
第一步是将一个文本序列中的单词与另一个序列中的每个单词对齐。假设前提是“i do need sleep”推断是 “i am tired”。由于语义的相似性,我们希望前提和推断中的两个“i”对齐,以及前提中的“need sleep”和推断中的“tired”对齐。 使用加权平均值进行的soft对齐,其中理想情况下,较大的权重与要对齐的单词相关联。
我们通过注意力机制详细描述这种soft对齐方法。前提和推断分别通过#card=math&code=%5Cmathbf%7BA%7D%20%3D%20%28%5Cmathbf%7Ba%7D1%2C%20%5Cldots%2C%20%5Cmathbf%7Ba%7D_m%29)和
#card=math&code=%5Cmathbf%7BB%7D%20%3D%20%28%5Cmathbf%7Bb%7D_1%2C%20%5Cldots%2C%20%5Cmathbf%7Bb%7D_n%29)表示,他们的词数分别为
和
,
(
) 分别为一个
维度的词向量。
在  计算注意力权重:
%5E%5Ctop%20f(%5Cmathbf%7Bb%7Dj)%0A#card=math&code=e%7Bij%7D%20%3D%20f%28%5Cmathbf%7Ba%7D_i%29%5E%5Ctop%20f%28%5Cmathbf%7Bb%7D_j%29%0A)
上式中的函数是下面的
mlp 函数。输出维度通过 num_hiddens参数指定。
def mlp(num_hiddens, flatten):net = nn.Sequential()net.add(nn.Dropout(0.2))net.add(nn.Dense(num_hiddens, activation='relu', flatten=flatten))net.add(nn.Dropout(0.2))net.add(nn.Dense(num_hiddens, activation='relu', flatten=flatten))return net
这里, 分别将
和
作为输入而不是将他们一起作为输入。只能使用
处理
应用(线性复杂度)而不能处理
应用(二次复杂度)。
进行权重的归一化处理,计算假设中所有但单词嵌入的加权平均值来获取与前提中索引为的单词进行对齐的假设的表示(representation):
%7D%7B%20%5Csum%7Bk%3D1%7D%5E%7Bn%7D%20%5Cexp(e%7Bik%7D)%7D%20%5Cmathbf%7Bb%7Dj.%0A#card=math&code=%5Cboldsymbol%7B%5Cbeta%7D_i%20%3D%20%5Csum%7Bj%3D1%7D%5E%7Bn%7D%5Cfrac%7B%5Cexp%28e%7Bij%7D%29%7D%7B%20%5Csum%7Bk%3D1%7D%5E%7Bn%7D%20%5Cexp%28e_%7Bik%7D%29%7D%20%5Cmathbf%7Bb%7D_j.%0A)
同样计算假设中索引为 对饮的对齐:
%7D%7B%20%5Csum%7Bk%3D1%7D%5E%7Bm%7D%20%5Cexp(e%7Bkj%7D)%7D%20%5Cmathbf%7Ba%7Di.%0A#card=math&code=%5Cboldsymbol%7B%5Calpha%7D_j%20%3D%20%5Csum%7Bi%3D1%7D%5E%7Bm%7D%5Cfrac%7B%5Cexp%28e%7Bij%7D%29%7D%7B%20%5Csum%7Bk%3D1%7D%5E%7Bm%7D%20%5Cexp%28e_%7Bkj%7D%29%7D%20%5Cmathbf%7Ba%7D_i.%0A)
下面的Attend 类,通过输入的前提 A计算其对齐假设 (beta) 以及 通过输入假设B计算对齐的前提 (alpha)。
class Attend(nn.Block):def __init__(self, num_hiddens, **kwargs):super(Attend, self).__init__(**kwargs)self.f = mlp(num_hiddens=num_hiddens, flatten=False)def forward(self, A, B):# `A`/`B`的形状为: (批量大小, 句子中的单词数, 词向量维度)# `f_A`/`f_B`的形状: (批量大小, 句子中的单词数,隐藏层单元数)f_A = self.f(A)f_B = self.f(B)# `e`的形状为: (批量大小, A中单词数, B中单词数)e = npx.batch_dot(f_A, f_B, transpose_b=True)#`beta`的形状为: (批量大小, A中单词数,向量维度), B与A中的每一个单词soft对齐beta = npx.batch_dot(npx.softmax(e), B)# `alpha`形状为: (批量大小, B中单词数,向量维度), A与B中的每一个单词soft对齐alpha = npx.batch_dot(npx.softmax(e.transpose(0, 2, 1)), A)return beta, alpha
2.2 comparing(比较)
将一个序列中的一个单词与与该单词进行软对齐的另一个序列进行比较。请注意,在soft对齐中,来自一个序列的所有单词(尽管注意力权重可能不同)将与另一个序列中的单词进行比较。在比较中, 我们将 一个句子的单词同另一个句子对齐的单词通过串联()输入到
函数中 (一个多层感知机):
%2C%20i%20%3D%201%2C%20%5Cldots%2C%20m%5C%5C%20%5Cmathbf%7Bv%7D%7BB%2Cj%7D%20%3D%20g(%5B%5Cmathbf%7Bb%7D_j%2C%20%5Cboldsymbol%7B%5Calpha%7D_j%5D)%2C%20j%20%3D%201%2C%20%5Cldots%2C%20n%0A#card=math&code=%5Cmathbf%7Bv%7D%7BA%2Ci%7D%20%3D%20g%28%5B%5Cmathbf%7Ba%7Di%2C%20%5Cboldsymbol%7B%5Cbeta%7D_i%5D%29%2C%20i%20%3D%201%2C%20%5Cldots%2C%20m%5C%5C%20%5Cmathbf%7Bv%7D%7BB%2Cj%7D%20%3D%20g%28%5B%5Cmathbf%7Bb%7D_j%2C%20%5Cboldsymbol%7B%5Calpha%7D_j%5D%29%2C%20j%20%3D%201%2C%20%5Cldots%2C%20n%0A)
表示前提中的单词
与假设中所有与单词
进行过soft对齐的单词之间的比较。类似的
表示假设中的单词
与前提中所有与单词
进行过soft对齐的单词之间的比较。下面的
Compare class定义了这一过程。
class Compare(nn.Block):def __init__(self, num_hiddens, **kwargs):super(Compare, self).__init__(**kwargs)self.g = mlp(num_hiddens=num_hiddens, flatten=False)def forward(self, A, B, beta, alpha):V_A = self.g(np.concatenate([A, beta], axis=2))V_B = self.g(np.concatenate([B, alpha], axis=2))return V_A, V_B
2.3 aggregating(汇总)
这是有两组比较向量 (
) 和
(
) 最后一步我们将信息汇总并推断出逻辑关系。首先对两个集合求和:
然后将 两个结果的串联输入到 函数中 (多层感知机) 来获取逻辑关系的分类结果:
.%0A#card=math&code=%5Chat%7B%5Cmathbf%7By%7D%7D%20%3D%20h%28%5B%5Cmathbf%7Bv%7D_A%2C%20%5Cmathbf%7Bv%7D_B%5D%29.%0A)
下面的 Aggregate 类定义了这一过程。
class Aggregate(nn.Block):def __init__(self, num_hiddens, num_outputs, **kwargs):super(Aggregate, self).__init__(**kwargs)self.h = mlp(num_hiddens=num_hiddens, flatten=True)self.h.add(nn.Dense(num_outputs))def forward(self, V_A, V_B):V_A = V_A.sum(axis=1)V_B = V_B.sum(axis=1)Y_hat = self.h(np.concatenate([V_A, V_B], axis=1))return Y_hat
2.4 定义模型
将上面的三部整合,定义了可分解注意力模型来共同训练这三个步骤。
class DecomposableAttention(nn.Block):def __init__(self, vocab, embed_size, num_hiddens, **kwargs):super(DecomposableAttention, self).__init__(**kwargs)self.embedding = nn.Embedding(len(vocab), embed_size)self.attend = Attend(num_hiddens)self.compare = Compare(num_hiddens)# 3中分类输出,蕴含,矛盾,无关self.aggregate = Aggregate(num_hiddens, 3)def forward(self, X):premises, hypotheses = XA = self.embedding(premises)B = self.embedding(hypotheses)beta, alpha = self.attend(A, B)V_A, V_B = self.compare(A, B, beta, alpha)Y_hat = self.aggregate(V_A, V_B)return Y_hat
3. 模型训练与评估
3.1 读取数据集
读取SNLI数据集 。批次大小和序列长度分别设置为 256 和 50 。
batch_size, num_steps = 256, 50train_iter, test_iter, vocab = d2l.load_data_snli(batch_size, num_steps)
3.2 创建模型
我们使用预先训练的 100 二维GloVe嵌入以表示输入token。创建一个模型实例,初始化其参数,并加载GloVe嵌入以初始化输入token的向量。
embed_size, num_hiddens, devices = 100, 200, d2l.try_all_gpus()net = DecomposableAttention(vocab, embed_size, num_hiddens)net.initialize(init.Xavier(), ctx=devices)glove_embedding = d2l.TokenEmbedding('glove.6b.100d')embeds = glove_embedding[vocab.idx_to_token]net.embedding.weight.set_data(embeds)
3.3 训练模型
定义一个函数用于接收多个批处理(例如小批处理中的前提和假设)。
def split_batch_multi_inputs(X, y, devices):X = list(zip(*[gluon.utils.split_and_load(feature, devices, even_split=False) for feature in X]))return (X, gluon.utils.split_and_load(y, devices, even_split=False))
下面在SNLI数据集上训练和评估模型。训练函数使用之前的。
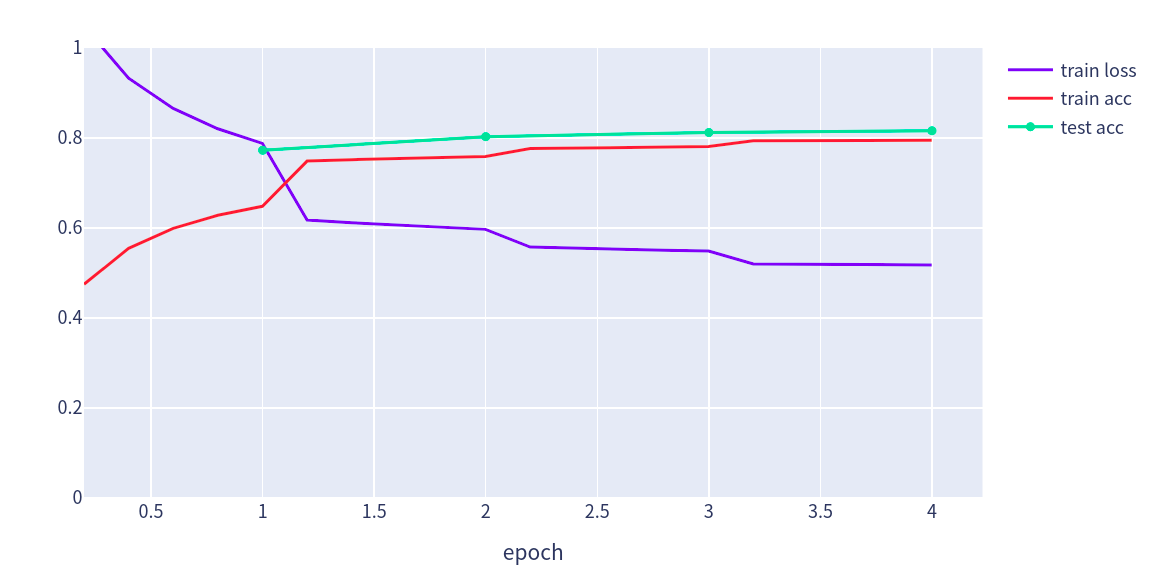
import plotly.graph_objs as godef accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.astype(y.dtype) == yreturn float(cmp.sum())def train_batch(net, features, labels, loss, trainer, devices, split_f=d2l.split_batch):X_shards, y_shards = split_f(features, labels, devices)with autograd.record():pred_shards = [net(X_shard) for X_shard in X_shards]ls = [loss(pred_shard, y_shard) for pred_shard, y_shardin zip(pred_shards, y_shards)]for l in ls:l.backward()# ignore_stale_grad代表可以使用就得梯度参数trainer.step(labels.shape[0], ignore_stale_grad=True)train_loss_sum = sum([float(l.sum()) for l in ls])train_acc_sum = sum(accuracy(pred_shard, y_shard)for pred_shard, y_shard in zip(pred_shards, y_shards))return train_loss_sum, train_acc_sumdef train(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus(), split_f=d2l.split_batch):num_batches, timer = len(train_iter), d2l.Timer()epochs_lst, loss_lst, train_acc_lst, test_acc_lst = [],[],[],[]for epoch in range(num_epochs):metric = d2l.Accumulator(4)for i, (features, labels) in enumerate(train_iter):timer.start()l, acc = train_batch(net, features, labels, loss, trainer, devices, split_f)metric.add(l, acc, labels.shape[0], labels.size)timer.stop()if (i + 1) % (num_batches // 5) == 0:epochs_lst.append(epoch + i / num_batches)loss_lst.append(metric[0] / metric[2])train_acc_lst.append(metric[1] / metric[3])test_acc_lst.append(d2l.evaluate_accuracy_gpus(net, test_iter, split_f))print(f"[epoch {epoch+1}] train loss: {metric[0] / metric[2]:.3f} train acc: {metric[1] / metric[3]:.3f}",f" test_loss: {test_acc_lst[-1]:.3f}")print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc_lst[-1]:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')fig = go.Figure()fig.add_trace(go.Scatter(x=epochs_lst, y=loss_lst, name='train loss'))fig.add_trace(go.Scatter(x=epochs_lst, y=train_acc_lst, name='train acc'))fig.add_trace(go.Scatter(x=list(range(1,len(test_acc_lst)+1)), y=test_acc_lst, name='test acc'))fig.update_layout(width=800, height=480, xaxis_title='epoch', yaxis_range=[0, 1])fig.show()
进行4个epoch的训练。
lr, num_epochs = 0.001, 4
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': lr})
loss = gluon.loss.SoftmaxCrossEntropyLoss()
train(net, train_iter, test_iter, loss, trainer, num_epochs, devices, split_batch_multi_inputs)

4. 模型使用
最后,定义预测函数以输出一对前提和假设之间的逻辑关系。
def predict_snli(net, vocab, premise, hypothesis):
premise = np.array(vocab[premise], ctx=d2l.try_gpu())
hypothesis = np.array(vocab[hypothesis], ctx=d2l.try_gpu())
label = np.argmax(net([premise.reshape((1, -1)),
hypothesis.reshape((1, -1))]), axis=1)
return 'entailment' if label == 0 else 'contradiction' if label == 1 else 'neutral'
我们可以使用经过训练的模型来获取样本对的自然语言推断结果。
predict_snli(net, vocab, ['he', 'is', 'good', '.'], ['he', 'is', 'bad', '.'])
# 'contradiction'
5. 参考
https://zhuanlan.zhihu.com/p/80883568
6.代码

若有收获,就点个赞吧
0 人点赞
