现实中的特征交叉数据往往非常复制且非线性,并不仅限于二者的交互,分解机通常用于二阶特征交互,理论上将分解机也可以对更高阶进行建模,但是由于数值不稳定和计算复杂性高通常不使用。为了处理高级的交互关系,一个做法是将分解机和深度神经网络结合,用深度神经网可以应对非线性的情况,本篇介绍一个称为深度分解机器(DeepFM)的代表性模型,该模型将FM和深度神经网络相结合。
1. 模型架构
DeepFM 有并行的 FM组件以及deep组件组成。 FM和用于二阶特征交互的 2-way 分解机相同。 deep 模块是一个多层感知器,用于捕获高阶特征相互作用和非线性关系。 这两个分量共享相同的输入/嵌入并且在最终预测的时候将输出汇总。值得一提的是,DeepFM的理念类似于可同时记忆和概括的Wide&Deep架构。DeepFM与Wide&Deep模型相比的优势在于,它可以通过自动识别特征组合来减少手工特征工程的工作量。
为了简洁起见,我们省略了FM 的描述,并将FM的输出表示为 %7D#card=math&code=%5Chat%7By%7D%5E%7B%28FM%29%7D)。让
表示第
field的潜在特征向量。 deep组件的输入是使用稀疏分类特征输入查找的所有字段的密集嵌入的串联,表示为:
%7D%20%20%3D%20%5B%5Cmathbf%7Be%7D_1%2C%20%5Cmathbf%7Be%7D_2%2C%20…%2C%20%5Cmathbf%7Be%7D_f%5D%2C%0A#card=math&code=%5Cmathbf%7Bz%7D%5E%7B%280%29%7D%20%20%3D%20%5B%5Cmathbf%7Be%7D_1%2C%20%5Cmathbf%7Be%7D_2%2C%20…%2C%20%5Cmathbf%7Be%7D_f%5D%2C%0A)
是field数。 然后将其馈入以下神经网络:
%7D%20%20%3D%20%5Calpha(%5Cmathbf%7BW%7D%5E%7B(l)%7D%5Cmathbf%7Bz%7D%5E%7B(l-1)%7D%20%2B%20%5Cmathbf%7Bb%7D%5E%7B(l)%7D)%2C%0A#card=math&code=%5Cmathbf%7Bz%7D%5E%7B%28l%29%7D%20%20%3D%20%5Calpha%28%5Cmathbf%7BW%7D%5E%7B%28l%29%7D%5Cmathbf%7Bz%7D%5E%7B%28l-1%29%7D%20%2B%20%5Cmathbf%7Bb%7D%5E%7B%28l%29%7D%29%2C%0A)
是激活功能。
和
是
层的权重和偏差。让
表示预测的输出。DeepFM的最总预测是 FM 和 DNN输出的整合:
%7D%20%2B%20%5Chat%7By%7D%5E%7B(DNN)%7D)%2C%0A#card=math&code=%5Chat%7By%7D%20%3D%20%5Csigma%28%5Chat%7By%7D%5E%7B%28FM%29%7D%20%2B%20%5Chat%7By%7D%5E%7B%28DNN%29%7D%29%2C%0A)
是 sigmoid 函数。 DeepFM 模型结构见下图:
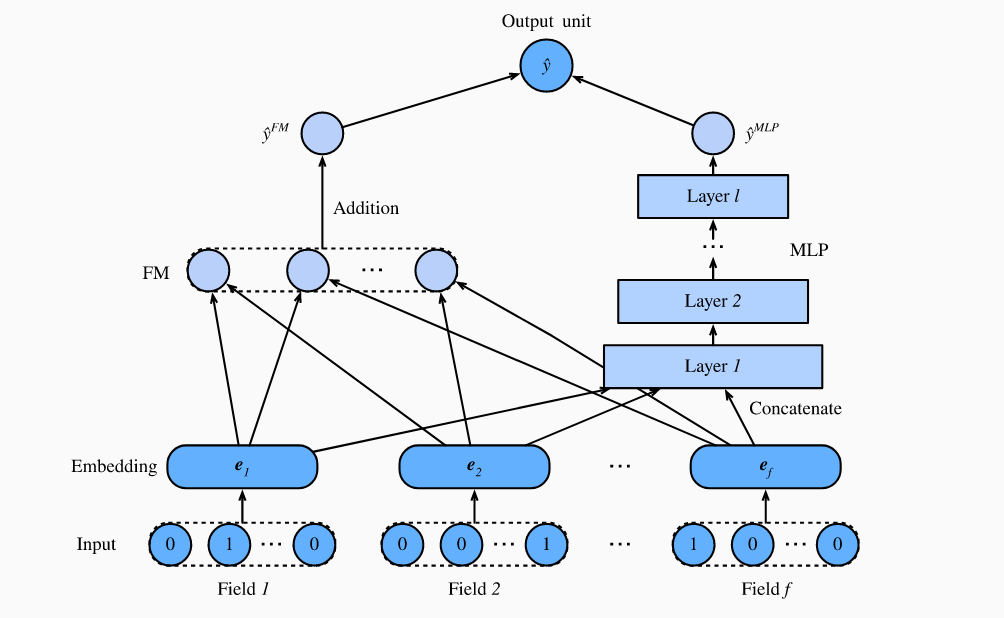
DeepFM不是将深度神经网络与FM相结合的唯一方法。我们还可以在特征相互作用上添加非线性层
from collections import defaultdictfrom d2l import mxnet as d2lfrom mxnet import gluon, np,npx,init,autogradfrom mxnet.gluon import nnfrom plotly import graph_objs as goimport pandas as pdimport sysimport osnpx.set_np()
2. DeepFM模型实现
DeepFM的实现与FM相似。我们保持FM部分不变,并使用MLP模块relu作为激活功能。Dropout也用于规范化模型。可以使用mlp_dims超参数调整MLP的神经元数量。
class DeepFM(nn.Block):def __init__(self, field_dims, num_factors, mlp_dims, drop_rate=0.1):super(DeepFM, self).__init__()num_inputs = int(sum(field_dims))self.embedding = nn.Embedding(num_inputs, num_factors)self.fc = nn.Embedding(num_inputs, 1)self.linear_layer = nn.Dense(1, use_bias=True)input_dim = self.embed_output_dim = len(field_dims) * num_factorsself.mlp = nn.Sequential()for dim in mlp_dims:self.mlp.add(nn.Dense(dim, 'relu', True, in_units=input_dim))self.mlp.add(nn.Dropout(rate=drop_rate))input_dim = dimself.mlp.add(nn.Dense(in_units=input_dim, units=1))def forward(self, x):embed_x = self.embedding(x)square_of_sum = np.sum(embed_x, axis=1) ** 2sum_of_square = np.sum(embed_x ** 2, axis=1)inputs = np.reshape(embed_x, (-1, self.embed_output_dim))x = self.linear_layer(self.fc(x).sum(1)) \+ 0.5 * (square_of_sum - sum_of_square).sum(1, keepdims=True) \+ self.mlp(inputs)x = npx.sigmoid(x)return x
3. 加载数据
使用之前的广告数据。
batch_size = 2048data_dir = d2l.download_extract('ctr')train_data = d2l.CTRDataset(os.path.join(data_dir, 'train.csv'))test_data = d2l.CTRDataset(os.path.join(data_dir, 'test.csv'),feat_mapper=train_data.feat_mapper,defaults=train_data.defaults)field_dims = train_data.field_dimstrain_iter = gluon.data.DataLoader(train_data, shuffle=True, last_batch='rollover', batch_size=batch_size,num_workers=d2l.get_dataloader_workers())test_iter = gluon.data.DataLoader(test_data, shuffle=False, last_batch='rollover', batch_size=batch_size,num_workers=d2l.get_dataloader_workers())
4. 训练
同样使用之前的训练函数进行训练。
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.astype(y.dtype) == yreturn float(cmp.sum())def train_batch(net, features, labels, loss, trainer, devices, split_f=d2l.split_batch):X_shards, y_shards = split_f(features, labels, devices)with autograd.record():pred_shards = [net(X_shard) for X_shard in X_shards]ls = [loss(pred_shard, y_shard) for pred_shard, y_shardin zip(pred_shards, y_shards)]for l in ls:l.backward()# ignore_stale_grad代表可以使用就得梯度参数trainer.step(labels.shape[0], ignore_stale_grad=True)train_loss_sum = sum([float(l.sum()) for l in ls])train_acc_sum = sum(accuracy(pred_shard, y_shard)for pred_shard, y_shard in zip(pred_shards, y_shards))return train_loss_sum, train_acc_sumdef train(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus(), split_f=d2l.split_batch):num_batches, timer = len(train_iter), d2l.Timer()epochs_lst, loss_lst, train_acc_lst, test_acc_lst = [],[],[],[]for epoch in range(num_epochs):metric = d2l.Accumulator(4)for i, (features, labels) in enumerate(train_iter):timer.start()l, acc = train_batch(net, features, labels, loss, trainer, devices, split_f)metric.add(l, acc, labels.shape[0], labels.size)timer.stop()if (i + 1) % (num_batches // 5) == 0:epochs_lst.append(epoch + i / num_batches)loss_lst.append(metric[0] / metric[2])train_acc_lst.append(metric[1] / metric[3])test_acc_lst.append(d2l.evaluate_accuracy_gpus(net, test_iter, split_f))if((epoch+1)%5==0):print(f"[epock {epoch+1}] train loss: {metric[0] / metric[2]:.3f} train acc: {metric[1] / metric[3]:.3f}",f" test_loss: {test_acc_lst[-1]:.3f}")print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc_lst[-1]:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')fig = go.Figure()fig.add_trace(go.Scatter(x=epochs_lst, y=loss_lst, name='train loss'))fig.add_trace(go.Scatter(x=epochs_lst, y=train_acc_lst, name='train acc'))fig.add_trace(go.Scatter(x=list(range(1,len(test_acc_lst)+1)), y=test_acc_lst, name='test acc'))fig.update_layout(width=580, height=400, xaxis_title='epoch', yaxis_range=[0, 1])fig.show()def train_fine_tuning(net, learning_rate, batch_size=64, num_epochs=5):train_iter = gluon.data.DataLoader(train_imgs.transform_first(train_augs), batch_size, shuffle=True)test_iter = gluon.data.DataLoader(test_imgs.transform_first(test_augs), batch_size)net.collect_params().reset_ctx(npx.gpu())net.hybridize()loss = gluon.loss.SoftmaxCrossEntropyLoss()trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': learning_rate, 'wd': 0.001})train(net, train_iter, test_iter, loss, trainer, num_epochs, [npx.gpu()])
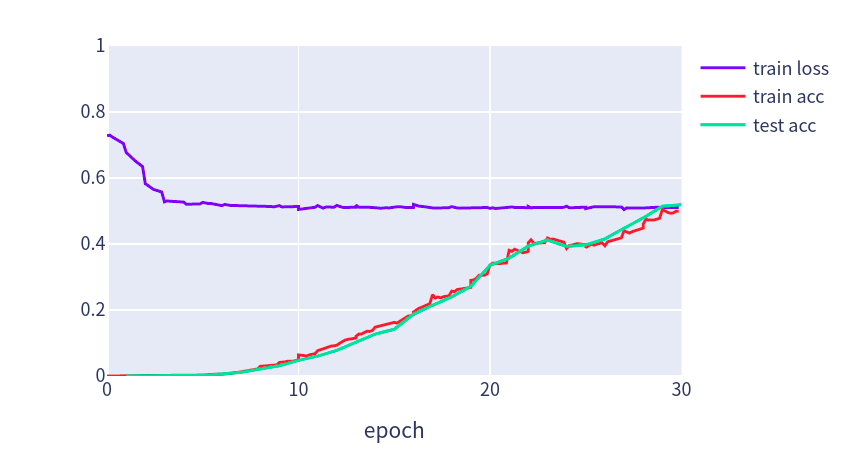
我们将DeepFM的MLP组件设置为具有金字塔结构(30-20-10)的三层密集网络。所有其他超参数与FM相同。与FM相比,DeepFM收敛更快,并且性能更高。
devices = d2l.try_all_gpus()
net = DeepFM(field_dims, num_factors=10, mlp_dims=[30, 20, 10])
net.initialize(init.Xavier(), ctx=devices)
lr, num_epochs, optimizer = 0.01, 30, 'adam'
trainer = gluon.Trainer(net.collect_params(), optimizer,
{'learning_rate': lr})
loss = gluon.loss.SigmoidBinaryCrossEntropyLoss()
train(net, train_iter, test_iter, loss, trainer, num_epochs, devices)

5.参考
https://d2l.ai/chapter_recommender-systems/deepfm.html
6.代码

若有收获,就点个赞吧
0 人点赞
