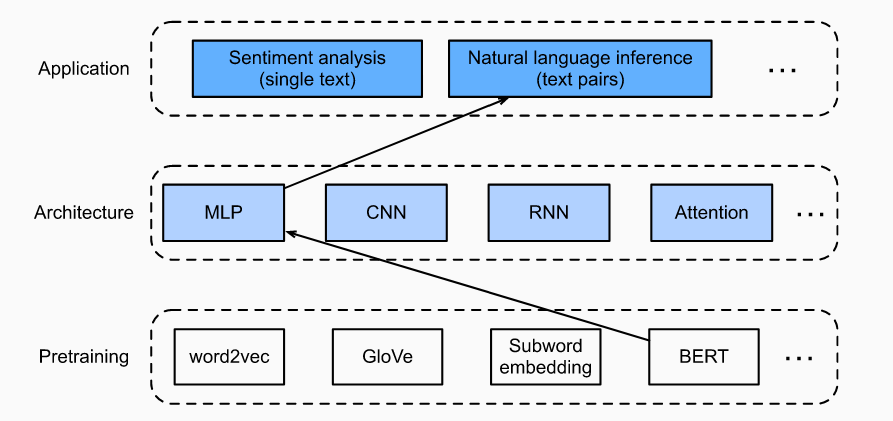
对于自然语言处理,可以设计很多模型,可以基于RNN、CNN、MLP甚至注意力机制。当在特定的环境下这写模型有用,但是并不通用,为每一个自然语言处理任务单独设计模型成本太高,之前有提到BERT模型,可以通过预训练BERT模型,然后针对不同类型的自然语言任务进行fine-tuning处理之后可以适配各种类型的nlp任务。
1.fine-tuning BERT
1.1 单一文字分类
单个文本分类以单个文本序列作为输入并输出其分类结果。除了我们在本章中研究的情感分析之外,语言可接受性语料库(CoLA)也可用于单个文本分类的数据集,可以判断给定的句子在语法上是否可以接受性。例如,“I should story ”可以接受,但是“I should studying.” 不行。
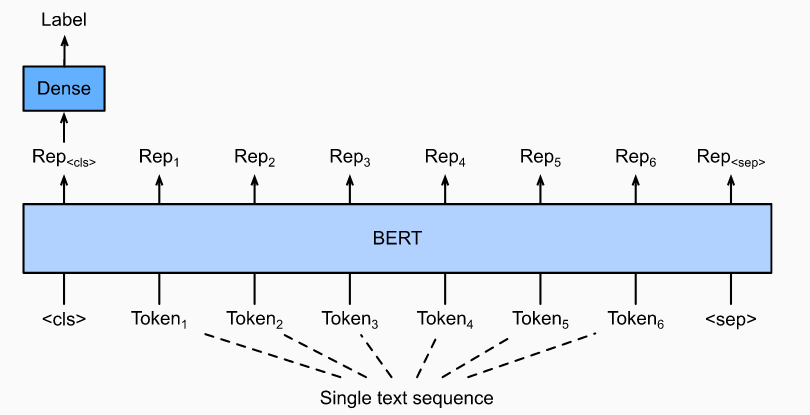
输入单个文本的表示形式,它将被馈送到一个完全连接的(密集)层组成的小型MLP中,以输出所有离散标签值的分布。
1.2 文本对分类或回归
自然语言推论。它属于文本对分类,即对文本进行分类的一种应用程序。
以一对文本为输入但输出一个连续值, 语义文本相似性是一种流行的文本对回归任务。此任务测量句子的语义相似性。例如,在语义文本相似性基准数据集中,一对句子的相似性分数是从0(无含义重叠)到5(含义等效)的序数标度。目的是预测这些分数。语义文本相似性基准数据集中的示例包括(句子1,句子2,相似性评分):
- “飞机正在起飞。”,“飞机正在起飞。”,5.000;
- “一个女人在吃东西。”,“一个女人在吃肉。”,3.000;
- “一个女人在跳舞。”,“一个男人在说话。”,0.000。
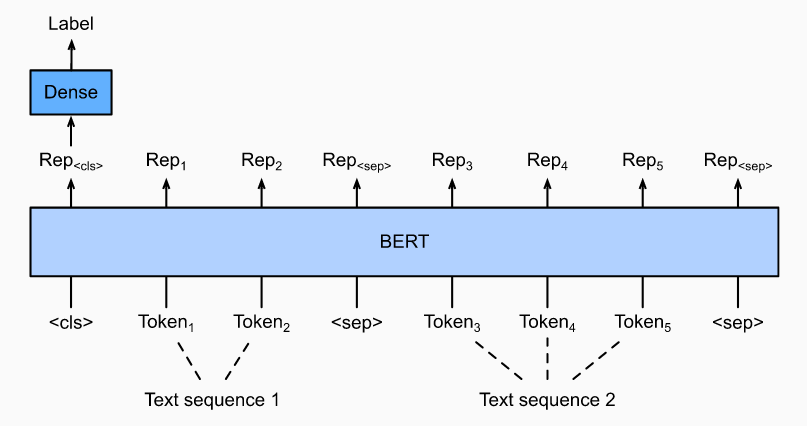
1.3 文字标记
处理token级别的任务,例如词性标注,为每一个token分配一个标签,词性标记根据单词在句子中的作用为每个单词分配词性标记(例如,形容词和定语)。
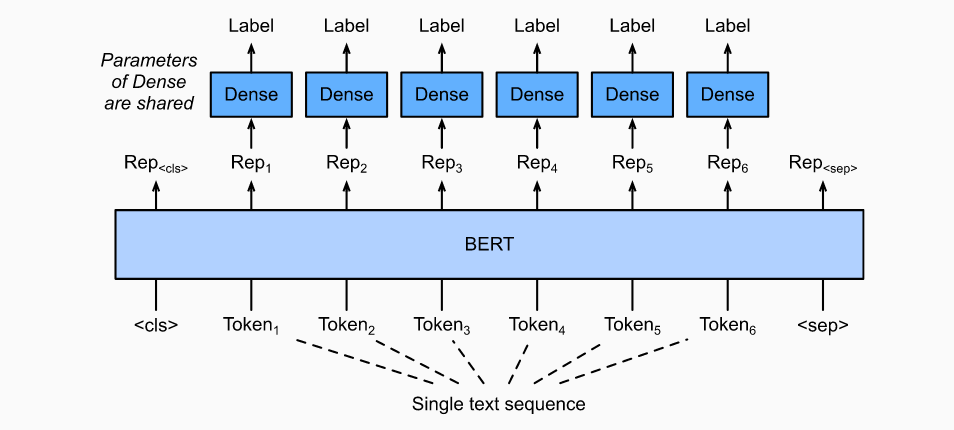
1.4 问答
作为另一个token级应用程序,问题回答反映了阅读理解的能力。例如,斯坦福问答数据集(SQuAD v1.1)由阅读文章和问题组成,其中每个问题的答案只是该问题与文章有关的一段文本(文本跨度)。SQuAD v1.1中的目标是在给定一对问题和段落的情况下,预测段落中文本范围的开始和结束。
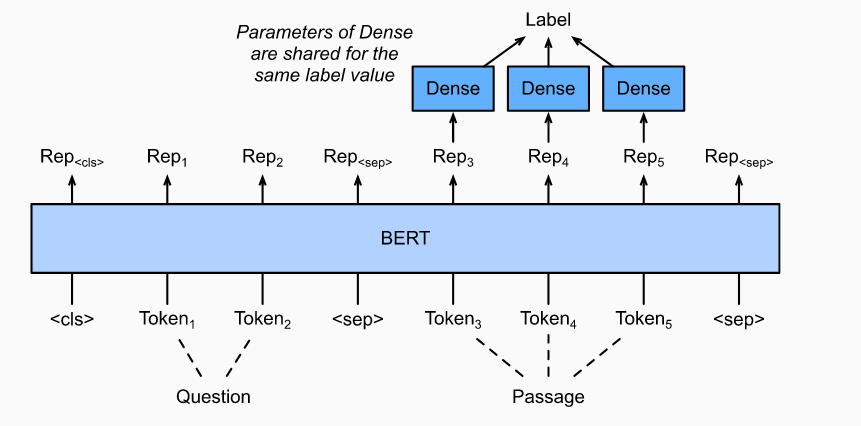
2. fine-tuning BERT 处理 自然语言推理任务
之前通过注意力机制进行了SNLI数据集上的自然语言推理。这里通过fine-tuning BERT来完成这一任务。自然语言推理是序列文本对分类的问题,对BERT进行微调仅需要基于多层感知机(MLP)即可。
我们将下载预训练的BERT小型版本,然后对其进行微调以在SNLI数据集上进行自然语言推理。
from d2l import mxnet as d2lfrom mxnet import autograd, gluon, np, npxfrom mxnet.gluon import nnfrom plotly import graph_objs as goimport multiprocessingimport jsonimport osnpx.set_np()
2.1 加载经过BERT预训练的数据集
原始BERT模型具有数亿个参数。在下面的内容中,我们提供了两种预训练的BERT版本:“ bert.base”与原始BERT基本模型差不多,后者需要大量的计算资源来进行微调,而“ bert.small”则是一个很小的版本,方便示范。两种预训练的BERT模型都包含定义词汇的vocab.json文件和预训练参数的“pretrained.params”文件。我们编写一个模型用于加载训练的BERT参数。
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.zip', '7b3820b35da691042e5d34c0971ac3edbd80d3f4')d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.zip', 'a4e718a47137ccd1809c9107ab4f5edd317bae2c')# 用于获取词汇表和BERT模型def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,num_heads, num_layers, dropout, max_len, devices):data_dir = d2l.download_extract(pretrained_model)# Define an empty vocabulary to load the predefined vocabularyvocab = d2l.Vocab()vocab.idx_to_token = json.load(open(os.path.join(data_dir, 'vocab.json')))vocab.token_to_idx = {token: idx for idx, token in enumerate(vocab.idx_to_token)}bert = d2l.BERTModel(len(vocab), num_hiddens, ffn_num_hiddens, num_heads,num_layers, dropout, max_len)# Load pretrained BERT parametersbert.load_parameters(os.path.join(data_dir, 'pretrained.params'),ctx=devices)return bert, vocab
为了能够在自用电脑上运行,使用小版本的BERT进行微调。
devices = d2l.try_all_gpus()bert, vocab = load_pretrained_model('bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,num_layers=2, dropout=0.1, max_len=512, devices=devices)
2.2 处理数据集
我们定义了一个自定义的数据集类SNLIBERTDataset,继承gluon的Dataset类,功能类满足几个功能:
__getitem__通过索引返回一组数据(前提和假设组合序列在词汇表中的ids, 前提和假设组合序列,长度),标签_truncate_pair_of_tokens方法根据输入的max_len剪切序列_mp_worker对序列进行特殊标注<CLS>, <SEP>,<SEP> ,<PAD>_preprocess通过多进程进行处理
class SNLIBERTDataset(gluon.data.Dataset):def __init__(self, dataset, max_len, vocab=None, workers=4):all_premise_hypothesis_tokens = [[p_tokens, h_tokens] for p_tokens, h_tokens in zip(*[d2l.tokenize([s.lower() for s in sentences])for sentences in dataset[:2]])]self.labels = np.array(dataset[2])self.vocab = vocabself.workers = workersself.max_len = max_len(self.all_token_ids, self.all_segments,self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)print('read ' + str(len(self.all_token_ids)) + ' examples')def _preprocess(self, all_premise_hypothesis_tokens):pool = multiprocessing.Pool(self.workers) # 使用进程out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)all_token_ids, all_segments, valid_lens = [], [], []for token_ids, segments, valid_len in out:all_token_ids.append(token_ids)all_segments.append(segments)valid_lens.append(valid_len)return (np.array(all_token_ids, dtype='int32'),np.array(all_segments, dtype='int32'),np.array(valid_lens))def _mp_worker(self, premise_hypothesis_tokens):p_tokens, h_tokens = premise_hypothesis_tokensself._truncate_pair_of_tokens(p_tokens, h_tokens)tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \* (self.max_len - len(tokens))segments = segments + [0] * (self.max_len - len(segments))valid_len = len(tokens)return token_ids, segments, valid_lendef _truncate_pair_of_tokens(self, p_tokens, h_tokens):# -3 为了给特殊标签留位置<CLS>', '<SEP>', 和 '<SEP>'while len(p_tokens) + len(h_tokens) > self.max_len - 3:if len(p_tokens) > len(h_tokens):p_tokens.pop()else:h_tokens.pop()def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx]), self.labels[idx]def __len__(self):return len(self.all_token_ids)
下载SNLI数据集后,我们通过实例化SNLIBERTDataset该类来生成训练和测试示例。在训练和测试自然语言推理过程中,将以小批量阅读此类示例。
# 本人6g显存这里使用256批次大小,不然显存会不够batch_size, max_len, num_workers = 256, 128, d2l.get_dataloader_workers()data_dir = d2l.download_extract('SNLI')train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)train_iter = gluon.data.DataLoader(train_set, batch_size, shuffle=True,num_workers=num_workers)test_iter = gluon.data.DataLoader(test_set, batch_size,num_workers=num_workers)
2.3 完善fine-tuning BERT 模型
对于自言语言推理的fine-tuning BERT模型只要在原本的基础上添加一个用于分类的MLP全连接层即可,用于判断蕴涵性,矛盾性和中立性。
class BERTClassifier(nn.Block):def __init__(self, bert):super(BERTClassifier, self).__init__()self.encoder = bert.encoderself.hidden = bert.hiddenself.output = nn.Dense(3)def forward(self, inputs):tokens_X, segments_X, valid_lens_x = inputsencoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)return self.output(self.hidden(encoded_X[:, 0, :]))
将BERT预训练模型传入BERTClassifier中完成模型创建。只需要将新创建的output层进行初始化。
net = BERTClassifier(bert)net.output.initialize(ctx=devices)
MaskLM类和 NextSentencePred类在其使用的MLP中均具有参数。这些参数是预训练BERT模型bert中参数的一部分,因此在net中也存在。但是,这些参数仅用于计算预训练期间的掩蔽语言建模损失和下一句预测损失。这两种损失函数无关的微调下游应用,BERT被微调时所采用的MLP但是MaskLM和NextSentencePred的参数不被更新(变得陈旧)。通过设置ignore_stale_grad=True来允许旧的梯度。使用之前的训练函数进行训练。
def split_batch_multi_inputs(X, y, devices):X = list(zip(*[gluon.utils.split_and_load(feature, devices, even_split=False) for feature in X]))return (X, gluon.utils.split_and_load(y, devices, even_split=False))def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.astype(y.dtype) == yreturn float(cmp.sum())def train_batch(net, features, labels, loss, trainer, devices, split_f=d2l.split_batch):X_shards, y_shards = split_f(features, labels, devices)with autograd.record():pred_shards = [net(X_shard) for X_shard in X_shards]ls = [loss(pred_shard, y_shard) for pred_shard, y_shardin zip(pred_shards, y_shards)]for l in ls:l.backward()# ignore_stale_grad代表可以使用就得梯度参数trainer.step(labels.shape[0], ignore_stale_grad=True)train_loss_sum = sum([float(l.sum()) for l in ls])train_acc_sum = sum(accuracy(pred_shard, y_shard)for pred_shard, y_shard in zip(pred_shards, y_shards))return train_loss_sum, train_acc_sumdef train(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus(), split_f=d2l.split_batch):num_batches, timer = len(train_iter), d2l.Timer()epochs_lst, loss_lst, train_acc_lst, test_acc_lst = [],[],[],[]for epoch in range(num_epochs):metric = d2l.Accumulator(4)for i, (features, labels) in enumerate(train_iter):timer.start()l, acc = train_batch(net, features, labels, loss, trainer, devices, split_f)metric.add(l, acc, labels.shape[0], labels.size)timer.stop()if (i + 1) % (num_batches // 5) == 0:epochs_lst.append(epoch + i / num_batches)loss_lst.append(metric[0] / metric[2])train_acc_lst.append(metric[1] / metric[3])test_acc_lst.append(d2l.evaluate_accuracy_gpus(net, test_iter, split_f))print(f"[epoch {epoch+1}] train loss: {metric[0] / metric[2]:.3f} train acc: {metric[1] / metric[3]:.3f}",f" test_loss: {test_acc_lst[-1]:.3f}")print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc_lst[-1]:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')fig = go.Figure()fig.add_trace(go.Scatter(x=epochs_lst, y=loss_lst, name='train loss'))fig.add_trace(go.Scatter(x=epochs_lst, y=train_acc_lst, name='train acc'))fig.add_trace(go.Scatter(x=list(range(1,len(test_acc_lst)+1)), y=test_acc_lst, name='test acc'))fig.update_layout(width=600, height=360, xaxis_title='epoch', yaxis_range=[0, 1])fig.show()
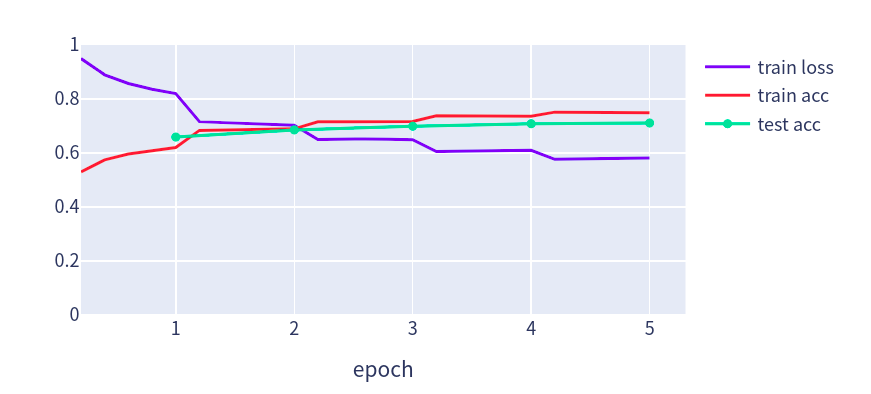
这里训练5个epochs,由于是分类问题使用Softmax交叉熵损失函数。
lr, num_epochs = 1e-4, 5trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': lr})loss = gluon.loss.SoftmaxCrossEntropyLoss()train(net, train_iter, test_iter, loss, trainer, num_epochs, devices, split_batch_multi_inputs)

3. 参考
https://d2l.ai/chapter_natural-language-processing-applications/finetuning-bert.html
4.代码

若有收获,就点个赞吧
0 人点赞
