之前有写过推荐的相关博客,通过皮尔森相关性、knn、以及矩阵分解进行处理,当时使用的矩阵分解为sklearn的集成方法,这里
1. 矩阵分解
矩阵分解是推荐系统公认的算法。矩阵分解是一种协同过滤模型。协同过滤从广义上讲,它是使用涉及多个用户、代理和数据源之间协作的技术对信息或模式进行过滤的过程。
详细的说,矩阵分解模型通过将用户-项目交互的矩阵(例如,评级矩阵)分解为两个相较低等级的矩阵的乘机,从而获取用户-项目交互的低等级结构。
用 用来表示
个用户 和
个项目的交互矩阵,
中的值代表评分。 用户-项目交互将分解为用户潜在矩阵
和项目潜在矩阵
,其中
是潜在因子的大小。让
表示
的第
行以及
表示
的第
行 。对于给定的项目
,
用于衡量项目具有的特征比如电影的流派和语言。对于给定的用户
,
衡量用户对项目相应特征的兴趣程度。这些潜在的因素可能是这些示例中明显的维度也许这些维度完全没法解释。 可以通过一下方程估计评级:
是形状与
相同的预测评级矩阵。该预测规则的一个主要问题是无法对用户/项目偏差进行建模。例如, 一些用户更加倾向于给出较高的分数,或者某些项目由于质量问题总是获得较低的评分,这些偏差在显示中很常见。为了捕获这些偏差,引入用户的特定偏差以及项目的特定偏差。具体来说,用户
给项目
预测评分为:
然后,我们通过最小化预测评分和真实评分之间的均方误差来训练矩阵分解模型。目标函数定义如下:
%20%5Cin%20%5Cmathcal%7BK%7D%7D%20%5C%7C%20%5Cmathbf%7BR%7D%7Bui%7D%20-%0A%5Chat%7B%5Cmathbf%7BR%7D%7D%7Bui%7D%20%5C%7C%5E2%20%2B%20%5Clambda%20(%5C%7C%20%5Cmathbf%7BP%7D%20%5C%7C%5E2F%20%2B%20%5C%7C%20%5Cmathbf%7BQ%7D%0A%5C%7C%5E2_F%20%2B%20b_u%5E2%20%2B%20b_i%5E2%20)%0A#card=math&code=%5Cunderset%7B%5Cmathbf%7BP%7D%2C%20%5Cmathbf%7BQ%7D%2C%20b%7D%7B%5Cmathrm%7Bargmin%7D%7D%20%5Csum%7B%28u%2C%20i%29%20%5Cin%20%5Cmathcal%7BK%7D%7D%20%5C%7C%20%5Cmathbf%7BR%7D%7Bui%7D%20-%0A%5Chat%7B%5Cmathbf%7BR%7D%7D%7Bui%7D%20%5C%7C%5E2%20%2B%20%5Clambda%20%28%5C%7C%20%5Cmathbf%7BP%7D%20%5C%7C%5E2_F%20%2B%20%5C%7C%20%5Cmathbf%7BQ%7D%0A%5C%7C%5E2_F%20%2B%20b_u%5E2%20%2B%20b_i%5E2%20%29%0A)
表示正则化率。正则项
#card=math&code=%5Clambda%20%28%5C%7C%20%5Cmathbf%7BP%7D%20%5C%7C%5E2F%20%2B%20%5C%7C%20%5Cmathbf%7BQ%7D%0A%5C%7C%5E2_F%20%2B%20b_u%5E2%20%2B%20b_i%5E2%20%29) 用于通过惩罚参数的大小来避免过度拟合。 每对
#card=math&code=%28u%2C%20i%29) 的被存储于
%20%5Cmid%20%5Cmathbf%7BR%7D%7Bui%7D%20%5Ctext%7B%20is%20known%7D%5C%7D#card=math&code=%5Cmathcal%7BK%7D%3D%5C%7B%28u%2C%20i%29%20%5Cmid%20%5Cmathbf%7BR%7D_%7Bui%7D%20%5Ctext%7B%20is%20known%7D%5C%7D)集合中。模型可以使用优化算法学习,比如SGD和Adam.
下图直观展示矩阵分解:
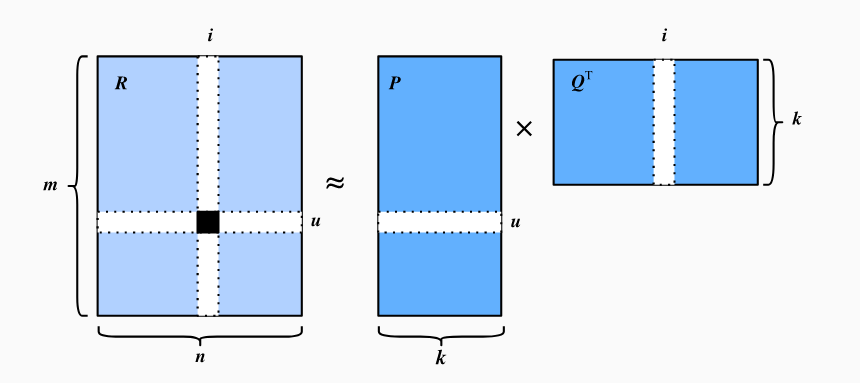
使用MovieLens数据集进行矩阵分解的训练。
2. MovieLens数据集
有许多可用于推荐研究的数据集。其中,MovieLens 数据集可能是最受欢迎的数据集之一。MovieLens是基于网络的非商业性电影推荐系统。它创建于1997年,由明尼苏达大学的研究实验室GroupLens运营,目的是收集电影收视率数据用于研究目的。MovieLens数据对于包括个性化推荐和社会心理学在内的多项研究至关重要。
我们将使用MovieLens 100K数据集,该数据集包括 100,000 收视率从1到5星不等,在1682部电影中有943位用户。已对其进行清理,以便每个用户至少对20部电影评分。还提供一些简单的人口统计信息,例如用户的年龄,性别,体裁和物品。
from d2l import mxnet as d2lfrom mxnet import gluon, np, autograd, npx, initimport mxnet as mxfrom mxnet.gluon import nnfrom plotly import express as px, graph_objs as goimport osimport pandas as pdnpx.set_np()
然后,我们下载MovieLens 100k数据集,并将加载为pandas的DataFrame
d2l.DATA_HUB['ml-100k'] = ('http://files.grouplens.org/datasets/movielens/ml-100k.zip','cd4dcac4241c8a4ad7badc7ca635da8a69dddb83')def read_data_ml100k():data_dir = d2l.download_extract('ml-100k')names = ['user_id', 'item_id', 'rating', 'timestamp']data = pd.read_csv(os.path.join(data_dir, 'u.data'), '\t', names=names, engine='python')num_users = data.user_id.unique().shape[0]num_items = data.item_id.unique().shape[0]return data, num_users, num_items
2.1 数据集统计
加载数据用于观察。
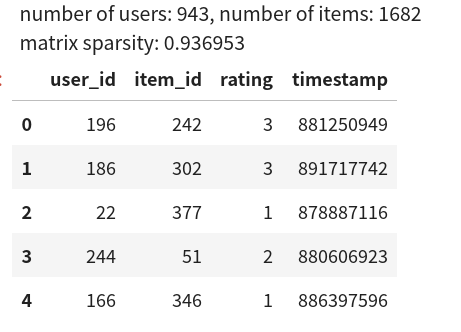
data, num_users, num_items = read_data_ml100k()sparsity = 1 - len(data) / (num_users * num_items)print(f'number of users: {num_users}, number of items: {num_items}')print(f'matrix sparsity: {sparsity:f}')data.head(5)
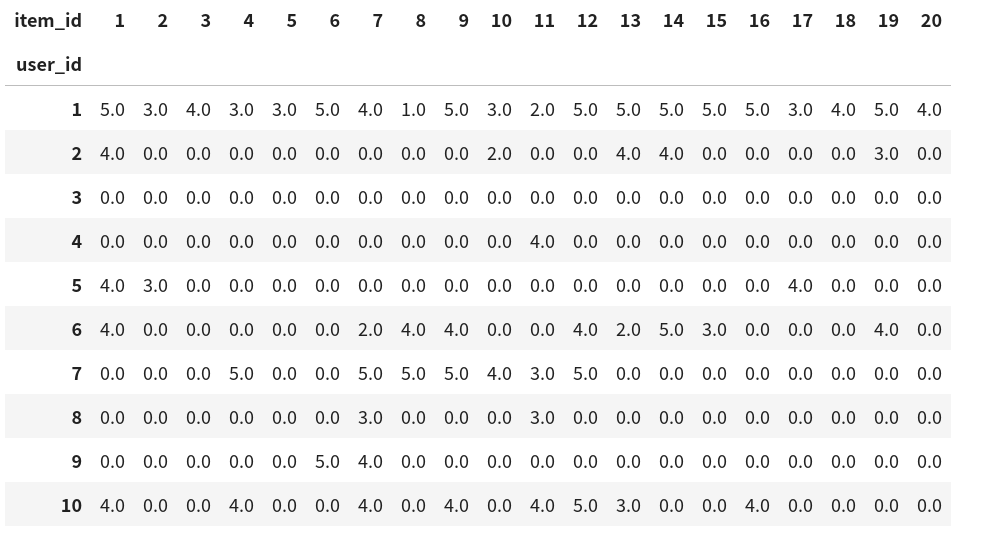
评分矩阵中的大多数值都是未知的,因为用户尚未对大多数电影进行评分。我们还显示了该数据集的稀疏性。稀疏度定义为 :#card=math&code=1%20-%20number%20of%20nonzero%20entries%20%2F%20%28%20number%20of%20users%20%2A%20number%20of%20items%29)。显然,交互矩阵非常稀疏(即稀疏度= 93.695%)。现实世界的数据集可能会遭受更大程度的稀疏性,并且一直是构建推荐系统的长期挑战。可行的解决方案是使用其他辅助信息(例如用户/项目功能)来减轻稀疏性。下面通过crosstab(或使用pivot)进行数据交叉,获取用户-项目交互矩阵形式,0都是没有数据的,可见数据非常稀疏。
pd.crosstab(data.user_id, data.item_id, values=data.rating, aggfunc=sum).fillna(0).iloc[:10,:20]
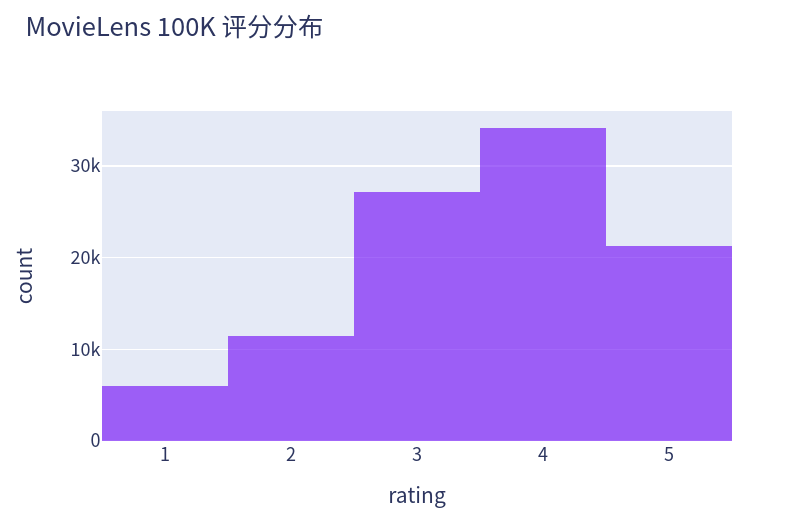
绘制评分的计数分布,如预期相仿,近视正太,大多数集中在3~4.
px.histogram(data, x='rating', width=580, height=400, opacity=0.7, title="MovieLens 100K 评分分布")
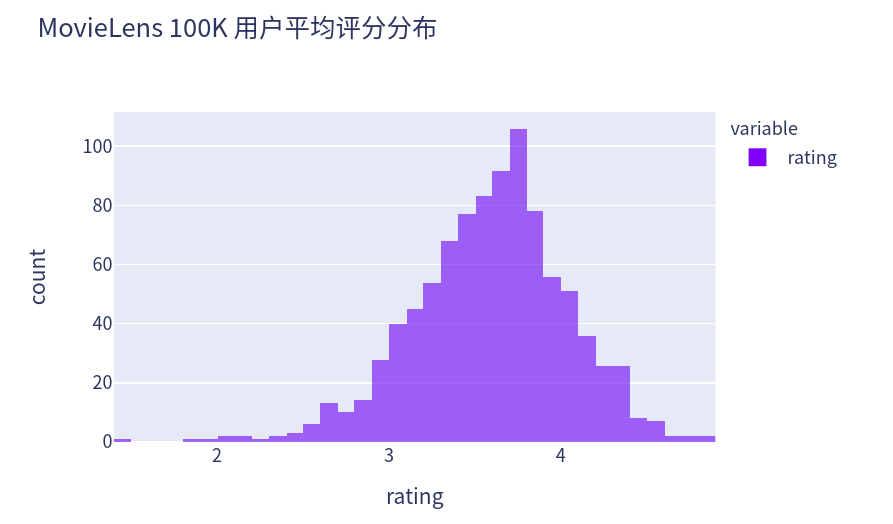
对每个用户求其平均评分,绘制平均评分的计数分布图,可见同样符合正太分布。
px.histogram(data.groupby('user_id')['rating'].mean(), width=580, height=400, opacity=0.7, title="MovieLens 100K 用户平均评分分布", labels={"value":"rating"})
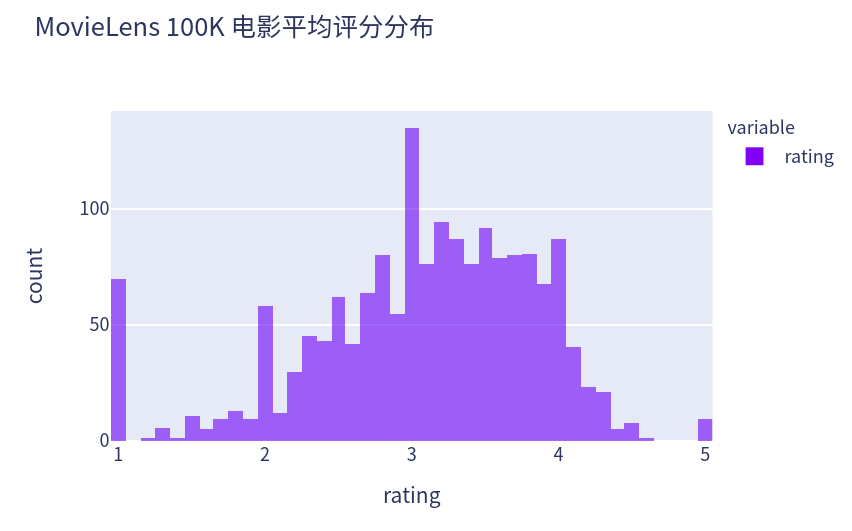
对每个电影求其平均评分,绘制平均评分的计数分布图,除去极好(全5分)以及极坏的(全5分)基本符合正太分布。
px.histogram(data.groupby('item_id')['rating'].mean(), width=580, height=400, opacity=0.7, title="MovieLens 100K 电影平均评分分布", labels={"value":"rating"})
2.2 分割数据集
我们将数据集分为训练集和测试集。以下功能提供了两种分割模式,包括random和seq-aware。在此 random模式下,该函数在不考虑时间戳的情况下随机拆分100k交互,默认情况下将90%的数据用作训练样本,其余10%用作测试样本。在该 seq-aware模式下,我们忽略了用户最近为测试评分的项目,以及用户的历史交互作为训练集。用户历史交互根据时间戳从最早到最新进行分类。此模式将在序列感知推荐部分中使用。
def split_data_ml100k(data, num_users, num_items, split_mode='random', test_ratio=0.1):if split_mode == 'seq-aware':train_items, test_items, train_list = {}, {}, []for line in data.itertuples():u, i, rating, time = line[1], line[2], line[3], line[4]train_items.setdefault(u, []).append((u, i, rating, time))if u not in test_items or test_items[u][-1] < time:test_items[u] = (i, rating, time)for u in range(1, num_users + 1):train_list.extend(sorted(train_items[u], key=lambda k: k[3]))test_data = [(key, *value) for key, value in test_items.items()]train_data = [item for item in train_list if item not in test_data]train_data = pd.DataFrame(train_data)test_data = pd.DataFrame(test_data)else:mask = [True if x == 1 else False for x in np.random.uniform(0, 1, (len(data))) < 1 - test_ratio]neg_mask = [not x for x in mask]train_data, test_data = data[mask], data[neg_mask]return train_data, test_data
2.3 加载数据
分割数据集后,为了方便起见,我们将训练集和测试集转换为列表和字典/矩阵。以下函数逐行读取数据帧,并枚举从零开始的用户/项索引。然后,该函数返回用户,项目,等级和记录交互的字典/矩阵的列表。我们可以将反馈的类型指定为explicit 或implicit。
def load_data_ml100k(data, num_users, num_items, feedback='explicit'):users, items, scores = [], [], []inter = np.zeros((num_items, num_users)) if feedback == 'explicit' else {}for line in data.itertuples():user_index, item_index = int(line[1] - 1), int(line[2] - 1)score = int(line[3]) if feedback == 'explicit' else 1users.append(user_index)items.append(item_index)scores.append(score)if feedback == 'implicit':inter.setdefault(user_index, []).append(item_index)else:inter[item_index, user_index] = scorereturn users, items, scores, inter
之后,我们将上述步骤放在一起,将在下一部分中使用。结果用Dataset和 包裹DataLoader。请注意,训练数据的last_batch设置为rollover模式(剩余样本将滚动到下一个epoch),并按顺序排序。
def split_and_load_ml100k(split_mode='seq-aware', feedback='explicit', test_ratio=0.1, batch_size=256):data, num_users, num_items = read_data_ml100k()train_data, test_data = split_data_ml100k(data, num_users, num_items, split_mode, test_ratio)train_u, train_i, train_r, _ = load_data_ml100k(train_data, num_users, num_items, feedback)test_u, test_i, test_r, _ = load_data_ml100k(test_data, num_users, num_items, feedback)train_set = gluon.data.ArrayDataset(np.array(train_u), np.array(train_i), np.array(train_r))test_set = gluon.data.ArrayDataset(np.array(test_u), np.array(test_i), np.array(test_r))train_iter = gluon.data.DataLoader( train_set, shuffle=True, last_batch='rollover',batch_size=batch_size)test_iter = gluon.data.DataLoader(test_set, batch_size=batch_size)return num_users, num_items, train_iter, test_iter
3.定义矩阵分解模型
首先,我们实现上述矩阵分解模型。可以使用创建用户和项目潜在因素nn.Embedding。的input_dim是项目/用户的数量,而(output_dim)是潜在因素的维度( k )。我们还可以 nn.Embedding通过将其设置output_dim为1来创建用户/项目偏好 。在该forward函数中,使用用户ID和项目ID来查找嵌入。
class MF(nn.Block):def __init__(self, num_factors, num_users, num_items, **kwargs):super(MF, self).__init__(**kwargs)self.P = nn.Embedding(input_dim=num_users, output_dim=num_factors)self.Q = nn.Embedding(input_dim=num_items, output_dim=num_factors)self.user_bias = nn.Embedding(num_users, 1)self.item_bias = nn.Embedding(num_items, 1)def forward(self, user_id, item_id):P_u = self.P(user_id)Q_i = self.Q(item_id)b_u = self.user_bias(user_id)b_i = self.item_bias(item_id)outputs = (P_u * Q_i).sum(axis=1) + np.squeeze(b_u) + np.squeeze(b_i)return outputs.flatten()
4. 评估定义
然后,我们实施RMSE(均方根误差)度量,该度量通常用于度量模型预测的评分得分与实际观察到的评分(基本事实)之间的差异:
%20%5Cin%20%5Cmathcal%7BT%7D%7D(%5Cmathbf%7BR%7D%7Bui%7D%20-%5Chat%7B%5Cmathbf%7BR%7D%7D%7Bui%7D)%5E2%7D%0A#card=math&code=%5Cmathrm%7BRMSE%7D%20%3D%20%5Csqrt%7B%5Cfrac%7B1%7D%7B%7C%5Cmathcal%7BT%7D%7C%7D%5Csum%7B%28u%2C%20i%29%20%5Cin%20%5Cmathcal%7BT%7D%7D%28%5Cmathbf%7BR%7D%7Bui%7D%20-%5Chat%7B%5Cmathbf%7BR%7D%7D_%7Bui%7D%29%5E2%7D%0A)
是由成对的用户和要评估的项目组成的集合。
是集合的大小。我们可以使用
mx.metric提供的RMSE函数功能。
def evaluator(net, test_iter, devices):rmse = mx.metric.RMSE() # 获取评估函数rmse_list = []for idx, (users, items, ratings) in enumerate(test_iter):u = gluon.utils.split_and_load(users, devices, even_split=False)i = gluon.utils.split_and_load(items, devices, even_split=False)r_ui = gluon.utils.split_and_load(ratings, devices, even_split=False)r_hat = [net(u, i) for u, i in zip(u, i)]rmse.update(labels=r_ui, preds=r_hat)rmse_list.append(rmse.get()[1])return float(np.mean(np.array(rmse_list)))
5.训练和评估
在训练功能上,我们采用 L2 体重下降引起的损失。重量衰减机制与 L2 正则化。
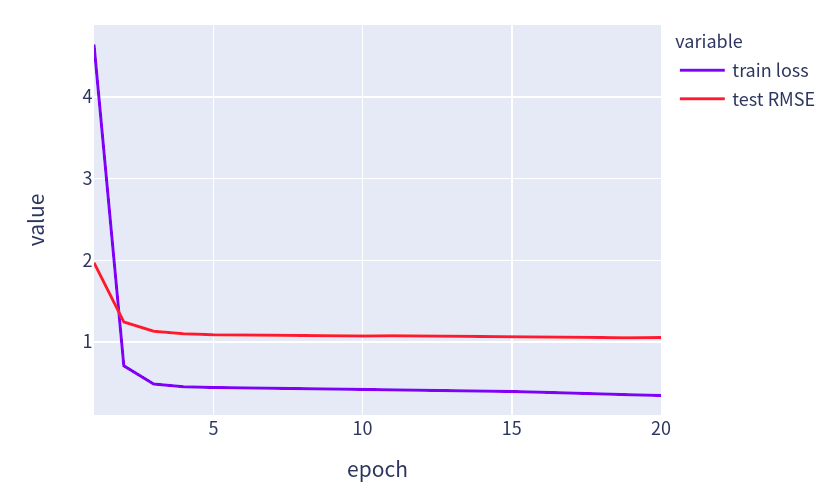
def train_recsys_rating(net, train_iter, test_iter, loss, trainer, num_epochs, devices=d2l.try_all_gpus(), evaluator=None,**kwargs):timer = d2l.Timer()data = []for epoch in range(num_epochs):metric, l = d2l.Accumulator(3), 0.for i, values in enumerate(train_iter):timer.start()input_data = []values = values if isinstance(values, list) else [values]for v in values:input_data.append(gluon.utils.split_and_load(v, devices))train_feat = input_data[0:-1] if len(values) > 1 else input_datatrain_label = input_data[-1]with autograd.record():preds = [net(*t) for t in zip(*train_feat)]ls = [loss(p, s) for p, s in zip(preds, train_label)][l.backward() for l in ls]l += sum([l.asnumpy() for l in ls]).mean() / len(devices)trainer.step(values[0].shape[0])metric.add(l, values[0].shape[0], values[0].size)timer.stop()if len(kwargs) > 0: # AutoRec中会用到这个test_rmse = evaluator(net, test_iter, kwargs['inter_mat'], devices)else:test_rmse = evaluator(net, test_iter, devices)train_l = l / (i + 1)data.append((epoch+1, train_l, test_rmse))print(f'train loss {metric[0] / metric[1]:.3f}, test RMSE {test_rmse:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {str(devices)}')fig = px.line(pd.DataFrame(data, columns=['epoch', 'train loss', 'test RMSE']), x='epoch', y=['train loss', 'test RMSE'], width=580, height=400)fig.show()
最后,让我们将所有事物放在一起并训练模型。在这里,我们将潜在因子维度设置为30。
devices = d2l.try_all_gpus()num_users, num_items, train_iter, test_iter = d2l.split_and_load_ml100k(test_ratio=0.1, batch_size=512)net = MF(30, num_users, num_items)net.initialize(ctx=devices, force_reinit=True, init=mx.init.Normal(0.01))lr, num_epochs, wd, optimizer = 0.002, 20, 1e-5, 'adam'loss = gluon.loss.L2Loss()trainer = gluon.Trainer(net.collect_params(), optimizer, {"learning_rate": lr, 'wd': wd})train_recsys_rating(net, train_iter, test_iter, loss, trainer, num_epochs, devices, evaluator)

下面,我们使用训练过的模型来预测用户(ID 20)可能对商品(ID 30)给予的评分。
scores = net(np.array([20], dtype='int', ctx=devices[0]), np.array([30], dtype='int', ctx=devices[0]))scores
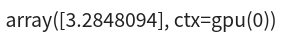
6. 参考
https://d2l.ai/chapter_recommender-systems/mf.html
7.代码

若有收获,就点个赞吧
0 人点赞
