到底是什么样的代码呢
话不多说,直接上代码:
new AbstractSpinBusiness() {@Overrideprotected boolean handle() {CompanyProfile updateProfile = getProfileForUpdateConf(staff, attrMap);return companyProfileDao.updateCompanyProfileConf(updateProfile) > 0;}}.spin(5);
简单介绍下,这段的意思是执行 handle() 里面的方法,并且设置了5次重试限制。
然后我们再来看看 AbstractSpinBusiness 这个抽象类
AbstractSpinBusiness.class**
import org.apache.log4j.Logger;public abstract class AbstractSpinBusiness {private Logger logger = Logger.getLogger(this.getClass());public void spin(int times){for(int i = 0; i < times; i++){if(handle()){return;}logger.debug(String.format("spin重试%s", i));}}/*** 执行主体* @return true:执行成功,不需要重试 false:执行失败*/protected abstract boolean handle();}
看到这里,好像也不过只是对 AbstractSpinBusiness 当中的 handle 的实现,并且运用在 spin 方法当中。可能细心的同学已经发现了这使用了模板的设计模式,如果能够发现,那么给你点个赞;如果没能发现,问题也不大,因为我在这里也并非是来讲模板设计模式。当然,模板设计模式也是十分重要且优秀的写法,在抽象业务、架构当中用的是遍地开花!
那么这个写法很优雅吗
回想一下我们最早学习 JDBC 的时候,我们需要手动获取 Connection,需要将参数设置到 PreparedStatement 当中,执行之后需要将对象再包装成我们想要的数据格式,这一系列的操作下来,我们可以发现,真正跟业务相贴切的就只是那一条SQL而已,其他的工作都只是一个辅助工作。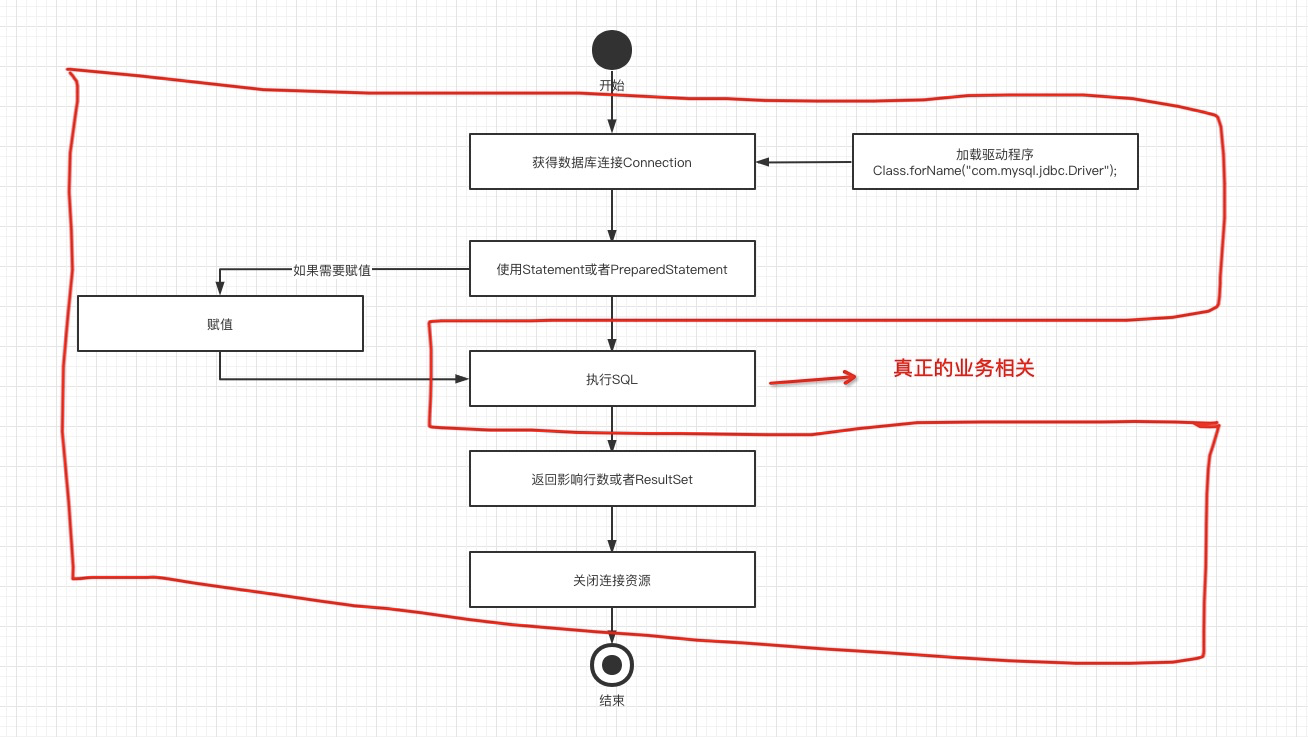
所以,像MyBatis、Hibernate等这类ORM框架才会孕育而生。开发人员在使用这些框架的时候,只需要关心我们自己的业务。例如MyBatis,我们只需要写好业务的SQL以及对应的Mapper,那么整合到业务的Service当中就可以,而其他的操作已经封装在框架中无感知执行。
回归到我们刚开始的那段代码当中。不难发现这简单的代码中,其实蕴含着同样的思想,那就是将业务代码和非业务代码独立开来。试想,如果有其他地方也需要使用类似的重试逻辑,那么是否又需要写一套重试的代码呢?
扩展
沿着这样的思路,在最近一次优化中使用了相同的写法。
目前系统中存在一些慢 SQL,SQL 的本身是比较简单,EXPLAIN 执行计划当中也没有什么问题,就只是单纯的 rows 比较多。问题在于业务中产生大量的参数,导致 in 里面的数据太多,造成SQL执行效率变低。那么比较直接的优化就是控制这里的参数,进行分批处理。(当然这里就不考虑网上说的子查询或者是 eq_range_index_dive_limit 参数之类)
要是你会怎么写
要是没有前面的引子,我想大家的代码大概会是这样
import com.google.common.collect.Lists;import java.util.List;public class Test {public static final int PARTITION_SIZE = 1000;public static void main(String[] args) {// 这里就模拟是业务参数List<Long> paramIds = Lists.newArrayList(1L,2L,3L);// 进行分隔List<List<Long>> partitionParamIds = Lists.partition(paramIds, PARTITION_SIZE);List<Object> resultList = Lists.newArrayListWithExpectedSize(paramIds.size());partitionParamIds.forEach(partition -> {// 执行具体的DAO操作,当然这里也是模拟resultList.addAll(new ObjectDao().getList(partition));});System.out.println(resultList.size());}}class ObjectDao {// 都说了是模拟模拟,不要挑刺了public List<Object> getList(List<Long> paramIds) {List<Object> resultList = Lists.newArrayList();for (Long paramId : paramIds) {resultList.add(paramId);}return resultList;}}
其实这样写本身也是比较简单整洁的,但是有没有发现,这里切片的动作和具体的业务代码还是混杂在一起,做不到一定意义上的职责分明。那是不是可以提供一个辅助类来做这些事情呢,所以我改写下。
import com.google.common.collect.Lists;import java.util.List;public class Test {public static void main(String[] args) {// 这里就模拟是业务参数List<Long> paramIds = Lists.newArrayList(1L,2L,3L);List<Object> resultList = new CommonDoPartition<>().partitionToQuery(paramIds,partition -> new ObjectDao().getList(partition));System.out.println(resultList.size());}}class ObjectDao {// 都说了是模拟模拟,不要挑刺了public List<Object> getList(List<Long> paramIds) {List<Object> resultList = Lists.newArrayList();for (Long paramId : paramIds) {resultList.add(paramId);}return resultList;}}
这里用到了一个 CommonDoPartition 类,我们来看下它是怎么实现的
CommonDoPartition.java**
import com.google.common.collect.Lists;import org.apache.commons.collections.CollectionUtils;import org.apache.log4j.Logger;import java.util.List;import java.util.function.Function;public class CommonDoPartition<T> {private final static Logger logger = Logger.getLogger(CommonDoPartition.class);public static final int PARTITION_SIZE = 1000;public <T, R> List<R> partitionToQuery(int partitionSize, List<T> all, Function<List<T>, List<R>> function) {if (CollectionUtils.isEmpty(all)) {logger.warn("no data to query");return Lists.newArrayList();}List<List<T>> partitions = Lists.partition(all, partitionSize);List<R> result = Lists.newArrayList();for (List<T> list : partitions) {List<R> resultList = function.apply(list);if (!CollectionUtils.isEmpty(resultList)) {result.addAll(resultList);}}return result;}public <T, R> List<R> partitionToQuery(List<T> all, Function<List<T>, List<R>> function) {return this.partitionToQuery(PARTITION_SIZE, all, function);}}
可以看到,分片的操作放到了这个公共方法当中,于是业务方只需要用 lambda 表达式支持他想要的业务逻辑就可以了,非业务性质工作都可以由这个工具类来完成。
再来扩展一下
既然实现了查询操作,同样也可以搞一下执行操作
public void partitionToDo(int partitionSize, List<T> all, Consumer<List<T>> consumer) {if (CollectionUtils.isEmpty(all)) {logger.warn("no data to consume");return;}List<List<T>> partitions = Lists.partition(all, partitionSize);for (List<T> list : partitions) {consumer.accept(list);}}public void partitionToDo(List<T> all, Consumer<List<T>> consumer) {this.partitionToDo(PARTITION_SIZE, all, consumer);}public <T, R> void partitionToQueryAndDo(int partitionSize, List<T> all, Function<List<T>, List<R>> function, Consumer<List<R>> consumer) {if (CollectionUtils.isEmpty(all)) {logger.warn("no data to consume");return;}List<List<T>> partitions = Lists.partition(all, partitionSize);List<R> resultList;for (List<T> list : partitions) {resultList = function.apply(list);consumer.accept(resultList);}}public <T, R> void partitionToQueryAndDo(List<T> all, Function<List<T>, List<R>> function, Consumer<List<R>> consumer) {this.partitionToQueryAndDo(PARTITION_SIZE, all, function, consumer);}
这里的 partitionToDo 是分批去执行某些任务,partitionToQueryAndDo 是结合了之前的分批查询某些数据,并且对这些数据进行操作。这些都是可以组合起来的例子。
作者:showyool 链接:https://juejin.cn/post/6875124307605864461 来源:掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
