1. 背景
排行榜在互联网场景很常见,特别是在教育和游戏竞技场景。通过排行榜,用户可以很直观的感知自己在业务排行中的名次,进而了解自己对特定知识的掌握程度。映射到技术实现上,其实就是按照某种维度进行排序,常见的排序实现有:
- 数据库:
order by xxx - 内存排序:依赖排序算法可以实现,也可以依赖 java8 中的 stream 进行排序
- redis 的 zset:分布式
这三种排序方式,均有各自的使用场景,不能单纯的说,实现排行榜就必须用 redis 的 zset!
| 排序方式 | 优势 | 劣势 |
|---|---|---|
| 数据库 | 实现简单,少数据量场景表现突出,多维度排序易于实现 | 大数据量,高并发场景下,表现出现瓶颈 |
| 内存 | - 少数据量场景表现突出 - 多维度非同种排序模式表现优秀 |
- 内存排序依赖具体算法,算法选择决定排序性能 - 对大数据量也比较敏感 - 每次请求,都需要计算排序,数据复用度不高 |
| redis | - 分布式存取 - zset底层是ziplist或者是skiplist,存取速度优秀 - zset有适用于各种场景的api,操作方便 |
- redis的网络请求模式是单线程,如果一次性读取大数量,会对网络通道阻塞 - 多维度非同种排序模式表现不好 |
每一种排序方式各有优劣,以下主要针对redis排序做下分享。
2. 一维排行榜
一维场景的排行榜,比较常见,实现起来也很简单,不需要多说。
存储:zset.add(key, value, score)
读取:zset.range(key, start, end) 或 zset.reverseRange(key, start, end)
3. 二维排行榜
从 redis 的 api 中发现,redis的排序依赖score,可以说不支持二维排序,难道遇到二维排序,redis就束手无策了吗?答案是否定的!
举例说明:在一个亲友群中(1000人),群主发了1个亿的红包,这一个亿分发到亲友手中的数值,有可能一样,有可能不一样,如果金额一样,那他们俩如何排序?
| 姓名 | 金额 |
|---|---|
| AAA | 3345443 |
| BBB | 456233 |
| CCC | 23423 |
| DDD | 23423 |
| EEE | 533 |
| FFF | 1 |
默认情况下,相同score的value排序规则:按照插入的value的字典序排序。
CCC和DDD这两人抢到红包的金额一样,当然可以按照插入的value的字典序排序,但如果想通过时间维度排序,如何改变排序行为呢?
| 姓名 | 金额 | 时间戳 |
|---|---|---|
| AAA | 3345443 | 123456 |
| BBB | 456233 | 123455 |
| CCC | 23423 | 123454 |
| DDD | 23423 | 123453 |
| EEE | 533 | 123452 |
| FFF | 1 | 123451 |
也就是说:抢到金额大的排到前面,相同金额的抢的晚的排到前面。即金额和时间均是降序排序。
从 java 中的 api 看,**zset.add(key, value, score)** 中的 score 是一个double 类型的小数,可以划分为整数和小数,如果我们把两个排序维度对应到整数和小数上,应该可以实现二维排序。
**
可以将金额和时间分别对应的 score的 整数部分和小数部分。这样金额和时间组成的二维 score 也是降序排序。
| 姓名 | 金额 | 时间戳 | score |
|---|---|---|---|
| AAA | 3345443 | 123456 | 3345443.123456 |
| BBB | 456233 | 123455 | 456233.123455 |
| CCC | 23423 | 123454 | 23423.123454 |
| DDD | 23423 | 123453 | 23423.123453 |
| EEE | 533 | 123452 | 533.123452 |
| FFF | 1 | 123451 | 1.123451 |
换一种要求:相同金额的抢的早的排到前面,也就是金额降序,时间升序。如何实现?
- 方案一:还是基于 redis,score = 金额.(未来时间戳-抢红包时间戳)。这样早抢的得到的score就更大,排序就更靠前。
- 方案二:内存排序(基于java8的stream实现:list.stream().sorted(Comparator.comparing(维度1).thenComparing(维度2).thenComparing(维度3).thenComparing(维度N));)
结论:在维度具有相同排序规则的情况下,可以将二维通过组合的方式降到一维来实现。
4. 三维及以上排行榜
4.1 二进制拆分
double类型存储格式: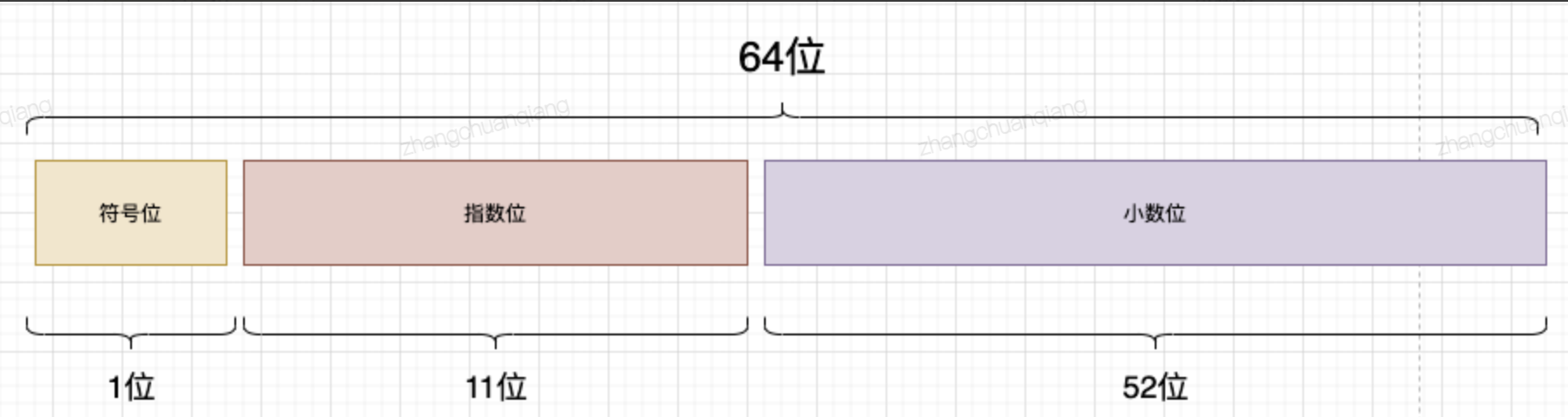
可以对63位进行分段拆分,将不同维度分布到分段中,进行score组织,位数不足的高位用0补充。
4.2 十进制拆分
相比较二进制拆分,该方法更容易操作和接受,建议采用这种方式。
1、确定每个维度数字最大范围(根据数据增长预留空间)。
2、维度组装,将各个维度的表数组装成一个大的数字。(不能超出double的最大范围)
5. 排行榜在魔卡服务中的应用
在魔卡中,排序规则是:按照获得经验值降序排序,如果经验值相同,则按照获得经验值的时间降序排序。即谁获得经验值越多,谁后获得,谁就排在前面。
这种场景很适合用二维度合并一维度的方式实现,具体实现细节,不做赘述。

若有收获,就点个赞吧
0 人点赞
