一、周考
1、SQL题目
#创建用户表create table user(userid int primary key auto_increment,username varchar(20) not null,password varchar(18) not null,address varchar(100),phone varchar(11));#创建分类表create table category(cid varchar(32) PRIMARY KEY ,cname varchar(100) not null #分类名称);#商品表CREATE TABLE products (pid VARCHAR(32) PRIMARY KEY,NAME VARCHAR(40),price DOUBLE(7,2),category_id VARCHAR(32),CONSTRAINT fk_products_category_id FOREIGN KEY(category_id) REFERENCES category(cid));#订单表CREATE TABLE orders(oid VARCHAR(32) PRIMARY KEY ,totalprice DOUBLE(12,2),userid INT ,CONSTRAINT fk_orders_userId FOREIGN KEY(userid) REFERENCES USER(userid) #外键);#订单项表create table orderitem(oid varchar(32), #订单idpid varchar(32), #商品idnum int , #购买商品数量primary key (oid, pid), #主键constraint fk_orderitem_oid foreign key(oid) references orders(oid),constraint fk_orderitem_pid foreign key(pid) references products(pid));1、查询用户的订单,没有用户的订单不显示select * from order inner join user on order.userid=user.userid;select * from order ,user where order.userid=user.userid;2、查询所有用户的订单详情select * from user left join order user.userid= order.userid;3、查询所有订单的用户select * from user right join order on user.userid= order.userid;select * from order left join user on user.userid= order.userid;4、查询用户为张三的订单详情select * from order,orderitem where order.oid = orderitem.oid and order.userid = (select userid from user where name ='张三');5、查询出订单的金额大于300的所有用户信息select * from user , order where user.userid=order.userid and order.totalprice>300;select * from user,(select * from order where totalprice>300) owhere user.userid = o.userid;6、查询订单大于300的订单信息及其关联的用户信息select * from (select * from order where totalprice>300) o left join user on o.userid=user.userid;
2、SQL题目
有3 个表:【基础】
Student 学生表(学号,姓名,性别,年龄,组织部门)
id name sex age dept
Course 课程表(编号,课程名称)
id name
Sc 选课表(学号,课程编号,成绩)
stu_id sc_id score
1、查询计算机原理的学生学号以及姓名
select * from student,course,sc where student.id=sc.stu_id and sc.sc_id=course.id
and course.name = '计算机原理';
2、查询周星驰选修了的课程的名字
select * from student,course,sc where student.id=sc.stu_id and sc.sc_id=course.id
and student.name = '周星驰';
3、选修了5门课程的学生的学号和名字
select id,name from student where id in (select stu_id from sc group by sc_id having count(1)>5 );
3、shell编程
1、计算100以内的偶数的和
第一种写法:
#!/bin/bash
sum=0
for num in {1..100}
do
if [ $[ num % 2 ] -eq 0 ]
then
sum=$(( sum + num ))
fi
done
echo $sum
第二种:
#!/bin/bash
sum=0
for(( num=0;num<=100;num+=2))
do
sum=$(( sum + num ))
done
echo $sum
第三种写法:
#!/bin/bash
num=0
while[ $num -le 100 ]
do
sum=$((sum+num))
$num=$((num+2))
done
4、shell 编程
#!/bin/bash
read -p "输入账户:" username
read -p "输入密码" password
if [ $username == 'root' ] && [ $password == '123456' ]
then
echo "登录成功"
else
echo "登录失败"
fi
第二种写法:
#!/bin/bash
read -p "输入账户:" username
read -p "输入密码" password
if [ $username == 'root' -a $password == '123456' ]
then
echo "登录成功"
else
echo "登录失败"
fi
-a 等同于 &&
-o 等同于 ||
二、Yum源
1、yum源安装文件
yum install -y ntpdate
yum install -y zip/unzip
以上方式可以总结为:使用yum源进行安装,你需要一个软件,这个时候可以从互联网上下载并安装,你只需要给一个名字,我就可以帮助你下载并安装,一步搞定,前提是可以联网。
2、linux的软件安装:
1)、安装 .tar.gz \ .bz2 等这些二进制文件 (类似于notepad++,绿色的,只要解压配置即可使用)
2)、通过yum源进行安装,必须联网而且yum源很重要。下载的地方称之为yum源,这个网址的网速非常的关键。(类似于maven)
3)、通过rpm安装包进行安装(类似于exe文件的安装)
关于rpm安装方式的几个常见的命令:
查询一下所有的rpm 安装包: rpm -qa
从众多的安装包中过滤要看的数据: rpm -qa | grep jdk
安装: rpm -ivh xxxx.rpm
卸载: rpm -e xxxxx.rpm
强制卸载: rpm -e xxxxx.rpm --nodeps
3、修改yum源
yum 源安装本质上还是 rpm安装,自动的帮你下载rpm以及安装rpm,而且还会判断rpm是否需要依赖其他的安装包。
为什么要修改yum? 因为国外的源地址不够快,为了提高效率。
选用阿里云的yum源:
1、cd /etc/yum.repos.d/
2、备份一下:cp CentOS-Base.repo CentOS-Base.repo.bak
3、下载阿里云镜像到本地:
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
4、清除yum的缓存
yum clean all
yum makecache
4、使用yum源
1、yum search 关键字 比如: yum search ifconfig 查看这个服务是在哪个软件中的,不是所有的服务名字都跟软件名字一样。
zip 发现没有这个命令 yum install zip
unzip 没有这个命令 yum install unzip
2、yum install 后面跟上软件的名字 安装此软件
安装的时候老提示你是否需要安装???? 每次都需要输入一个y,如果不想每次都问你,你可以加一个 -y
yum -y install 软件的名字
3、软件的升级 yum -y update 软件的名字
4、卸载 yum -y remove 软件的名字
5、 清除缓存以及旧的安装包 yum clean all
6、查看可以使用的yum源 yum repolist
三、安装jdk
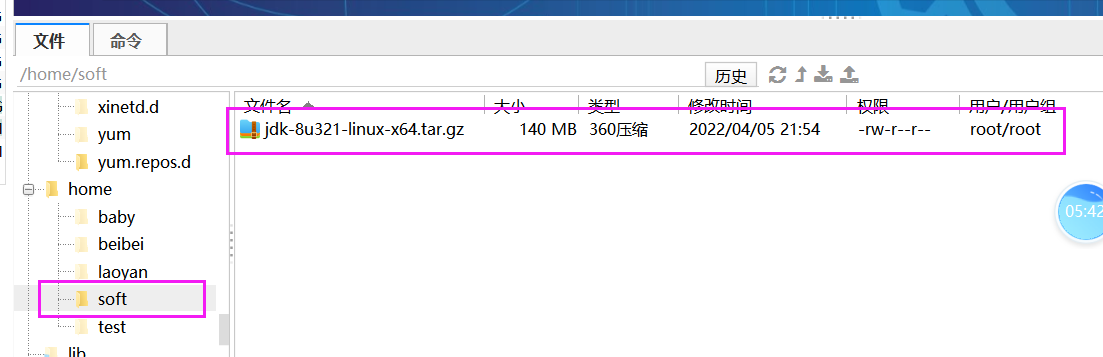
1、创建一个公共的文件夹,将来把所有的安装包文件全部放入到这个里面
/home/soft 下
2、上传jdk的安装包
3、解压缩到 /usr/local 下
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /usr/local
4、对刚解压的文件进行重命名
cd /usr/local/
mv jdk1.8.0_321 jdk
5、配置环境变量 /etc/profile 下
可以使用notepad++ 进行修改
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
6、重新导入,让环境变量生效
source /etc/profile
7、验证该变量是否配置成功
java -version
四、虚拟机的克隆
1、准备工作
克隆之前确保几样东西:
1、防火墙都关闭
2、配置了固定IP
3、安装了jdk
4、yum源进行了修改
5、时间进行了同步
2、进行快照
快照的意思是为当前的linux进行一个备份,将来随时可以回滚到备份的状态。<br />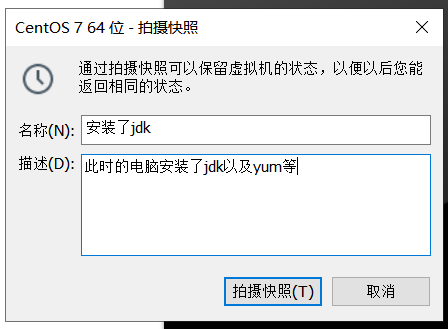
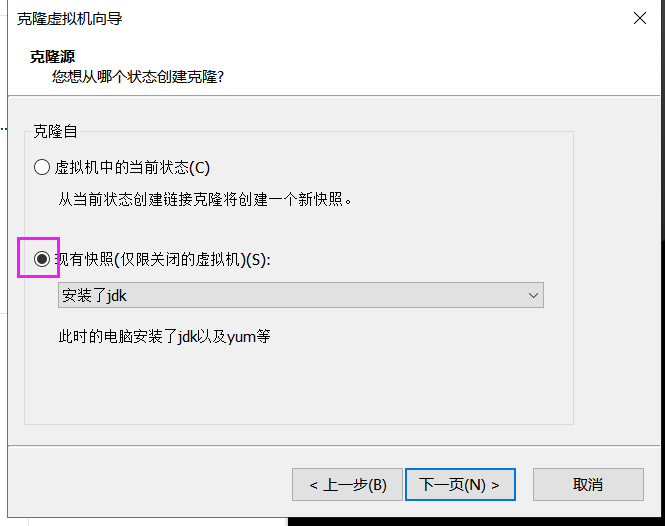
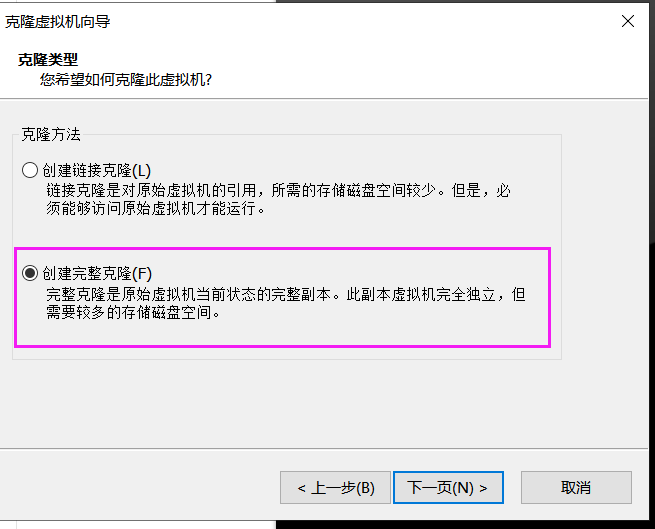
3、克隆
4、修复克隆带来的后果
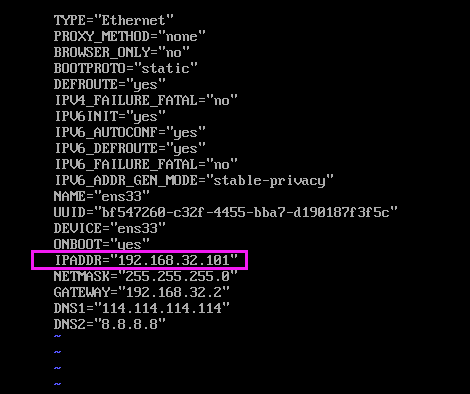
1)、修改IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改ip地址为一个新的地址 192.168.32.101
记得重启网卡服务: systemctl restart network
2) 修改主机名
1、临时修改 hostname bigdata02
2、永久修改
1) hostnamectl set-hostname bigdata02
2) vi /etc/hostname
3) 修改域名和IP的映射关系
vi /etc/hosts
192.168.32.100 bigdata01
192.168.32.101 bigdata02
将来我就可以通过主机名来代替我的IP地址了。
修改了第二台,记得把第一台也改一下,内容一模一样。
五、SCP 远程拷贝
cp 将一个文件(文件夹)拷贝到另一个文件夹
如果将A电脑上的文件拷贝到B电脑,cp肯定不行的,需要使用scp
举例:
scp /etc/hosts root@bigdata01:/etc/ 拷贝文件
scp -r /usr/local/jdk/ root@bigdata01:/usr/local/ 拷贝文件夹,一定要带 -r (递归)
简化:
scp /etc/hosts bigdata01:/etc/ root用户可以省略,前提条件是本机的用户名和远程的用户名一样,用户名可以省略。
先进入到/usr/local
scp -r jdk bigdata01:$PWD 用$PWD 表示当前的工作路径
六、SSH免密登录
以上scp进行拷贝的时候,每次都需要输入密码,非常的烦恼,是否可以做免密登录。
bigdata01上,我想免密登录bigdata02,怎么做?
在bigdata01上的任意一个文件夹下执行该命令:
ssh-keygen -t rsa
作用是生成一个公钥和私钥
直接敲击三次回车即可生成。
生成的位置在:/root/.ssh
接着在bigdata01 这个linux ,拷贝公钥给 bigdata02
ssh-copy-id bigdata02 需要输入bigdata02的密码
将公钥拷贝到了 bigdata02中的 /root/.ssh/authorized_keys 文件中去了
免密测试: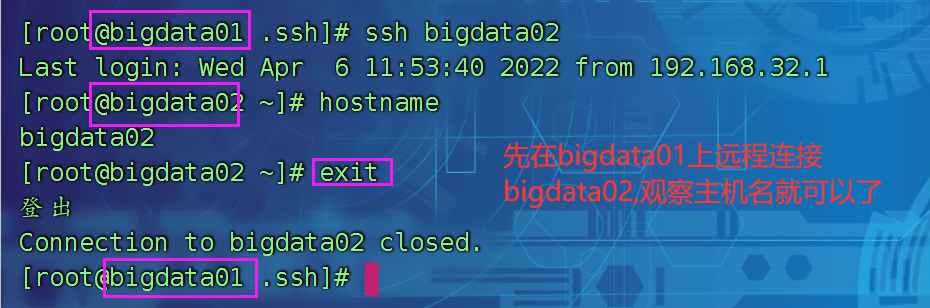
ssh免密登录是单向的,一个bigdata01 可以免密登录到 bigdata02上,不代表bigdata02 可以远程免密登录bigdata01
免密登录的原理: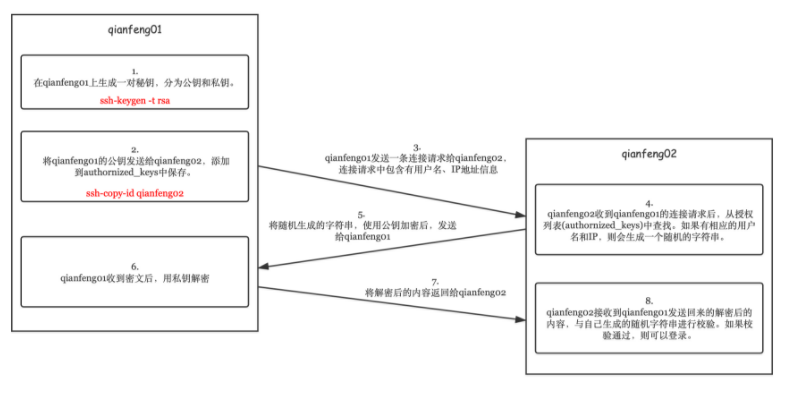
在01上生成一个公钥和私钥,将公钥拷贝到 02 上。
当01需要远程连接02 电脑的时候,需要携带用户名以及IP地址。
02电脑收到01的连接请求后,会使用公钥,生成一个加密的字符串给01
01接收到这个加密的字符串以后,使用私钥进行解密,将解密以后的结果返回给02.
02拿到解密的结果,然后给之前的没有加密的字符串进行比对,发现结果正确,就可以让01远程免密连接自己了。
七、linux中的定时任务
比如:我们的服务器,经常性的时间不对,我们每一次都需要手动的进行互联网时间的同步,如果可以写一个定时任务,每一分钟进行同步一次就好了。
crontab —linux中的定时器
cron服务的相关命令:
启动定时任务的服务: service crond start
关闭定时任务的服务: service crond stop
重启定时任务的服务: service crond restart
重新载入定时任务的配置: service crond reload
查看定时任务的状态: service crond status
定时任务的配置文件在哪里?
/var/spool/cron/ 这个文件夹下会有一个文件,你当前是什么用户,这个目录下就有一个对应的名字的文件等着你。
一个用户最多只能有一个定时任务的文件存在。
如何生成定时任务呢?
crontab -e 进入后即可进行编写,使用方法跟vi编辑器一样。
进行编辑,一定是在插入状态下
编写一个简单的定时任务:每隔一分钟在test.txt中追加一个 Good moring.
*/1 * * * * echo "Good morning." >> /tmp/test.txt
tail -f /tmp/test.txt 可以查看滚动的日志文件
定时任务的语法:
格式如下:
* * * * * user-name command to be executed
共有六部分组成,分别表示:
分 时 日 月 星期 要运行的命令
解析:
minute: 一小时中的哪一分钟 [0~59]
hour: 一天中的哪个小时 [0~23]
day: 一月中的哪一天 [1~31]
month: 一年中的哪一月 [1~12]
week: 一周中的哪一天 [0~6] 0表示星期天
commands: 执行的命令
书写注意事项
1 全都不能为空,必须填入,不知道的值使用通配符*表示任何时间
2 每个时间字段都可以指定多个值,不连续的值用,间隔,连续的值用-间隔。
3 命令应该给出绝对路径
4 用户必须具有运行所对应的命令或程序的权限
5 */num 表示频率
练习:
1、每天早上6点
0 6 * * *
2、每隔两个小时
0 */2 * * *
3、晚上11点到早上8点之间每隔2个小时和早上八点
0 23-8/2,8 * * *
4、周一到周五,下午五点半
30 17 * * 1-5
5、每月的1,10,22 的 4:15分
15 4 1,10,22 * *
6、每周的周六周日1:10分
10 1 * * 6,0
7、每天18:00 到 23:00 每隔 30分钟
0,30 18-22 * * *
0 23 * * *
8、每星期六的下午11点
0 23 * * 6
有专门写表达式的网站: https://www.bejson.com/othertools/cron/
实战:
crontab -e 然后编辑保存:
*/30 * * * * ntpdate -u ntp.api.bz
如果我们的服务器都不能联网,又想时间同步,可以指定一台服务器的时间为基本当做时间服务器,其他服务器跟它进行同步,也是可以行的。
八、关于Hadoop
Hadoop 的创始人道格·卡丁:他是lucene 的创始人,面临这检索中的相关问题,根据谷歌的三篇论文进行的研发:
GFS --> HDFS
MapReduce --> MapReduce
BigTable --> Hbase
hadoop有三个版本:
apache 版本,我们目前使用的
Cloudera 版本--商用版
Hortonworks -- 聚集了很多hadoop的源码开发人员
官网:hadoop.apache.org
Hadoop 是一个集中式的框架,三部分组成 HDFS、MapReduce 、Yarn
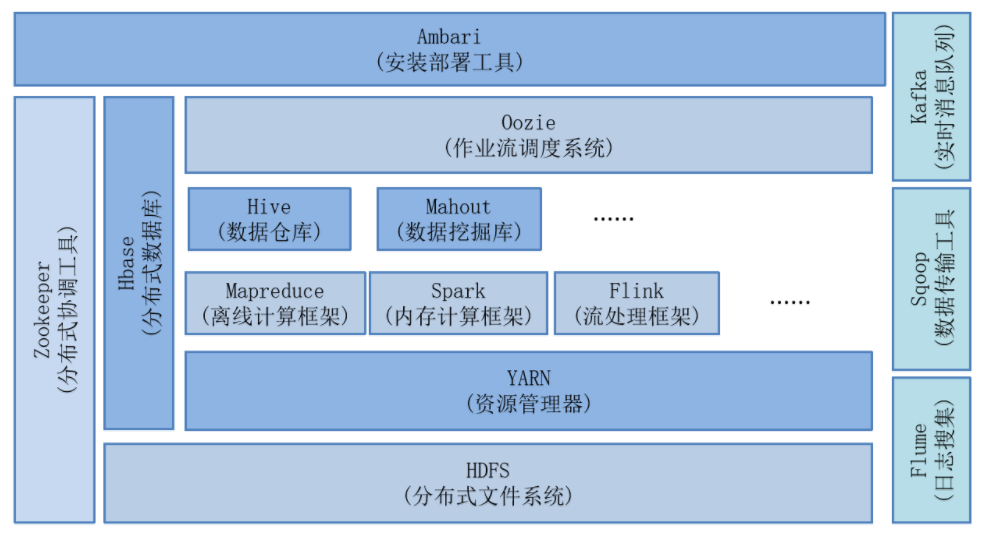
九、环境搭建
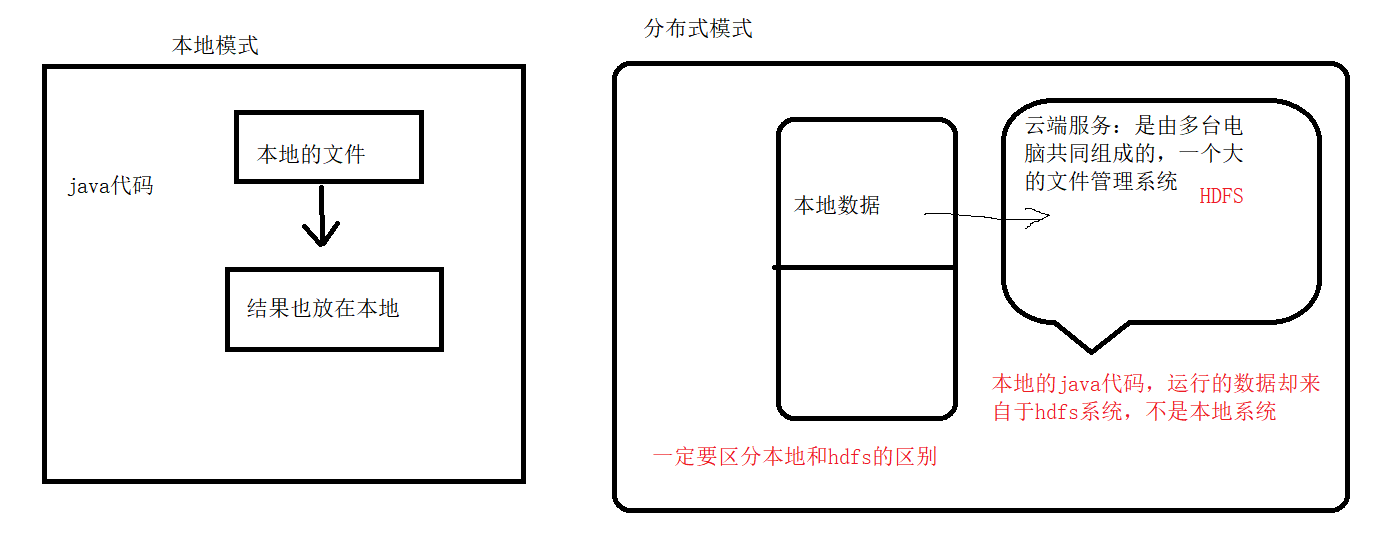
1、本地模式
1) 上传安装包 /home/soft 下,上传 hadoop-3.3.1.tar.gz
2) 解压缩 /usr/local
tar -zxf hadoop-3.3.1.tar.gz -C /usr/local
3) 重命名 (非必须的)
进入 /usr/local 文件夹下,进行 mv hadoop-3.3.1 hadoop
4) 修改环境变量 /etc/profile
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
5) 刷新一下你的环境变量
source /etc/profile
6) 验证是否成功 hadoop version 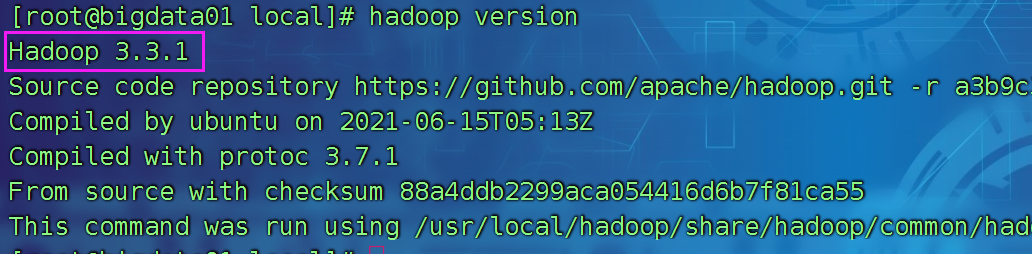
7) 使用一下,测测
编写一个workcount的案例:词语个数统计
在 /home 路径下
创建一个文件夹 mkdir input
在input 文件夹中,创建一个a.txt 文件
touch a.txt
里面随便输入一些单词:
hadoop java bigdata
hello world java bigdata
name hadoop version hello
final shell shell hello
接着开始执行:
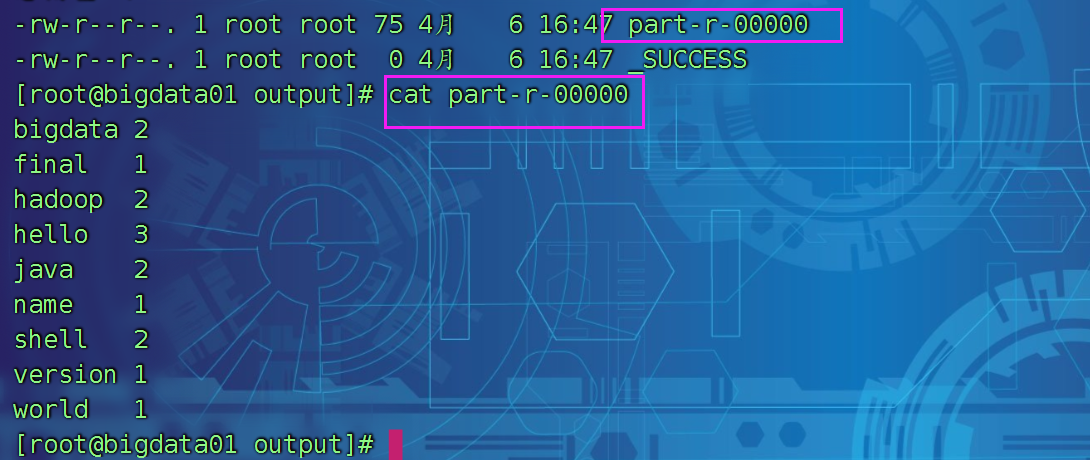
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount input/* output
执行hadoop中的一个jar包,jar包中有很多程序,我要执行 wordcount 我的数据来源是 input 文件夹下的所有内容
我执行出来的结果放在 output 文件夹下,output文件夹必须不能存在,否则报错。

还可以这样测试:测试pi的值:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 100

简单了解一下:以扔飞镖的方式测试pi的值。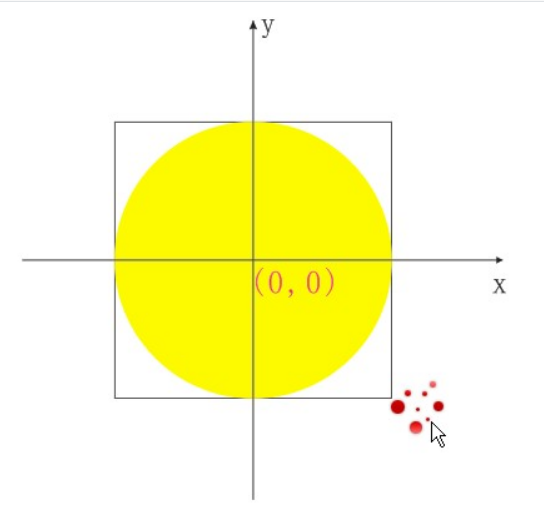
方块的长度1 ,圆的面积就是 pi0.50.5= 0.25pi 扔中的概率是多少? 圆的面积/方块的面积= 0.25pi/1
第一个参数10 代表的是10个map任务,每个任务扔100次,执行的任务数越多,扔的次数越多,测算的pi的值越接近真实的pi的值。
2、伪分布模式
伪分布模式:它是按照全分布模式进行配置的,但是的的确确只有一台服务器,所以称之为伪分布模式。
进行配置:
环境准备工作:
1、安装了jdk
2、安装了hadoop
3、关闭了防火墙
4、免密登录
自己对自己免密
ssh-copy-id bigdata01 选择yes 输入密码
测试免密是否成功: ssh bigdata01
5、修改linux的一个安全机制
vi /etc/selinux/config
修改里面的 SELINUX=disabled
6、设置host映射
伪分布的配置:
1) core-site.xml 在hadoop家目录下的 etc/hadoop 下
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
2、修改 hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
3、修改hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
# Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4、namenode格式化
注意事项:
我们在core-site.xml中配置过hadoop.tmp.dir的路径,在集群格式化的时候需要保证在这个路径不存在!如果之前存在数据,先将其删除,再进行格式化!
hdfs namenode -format
5、启动hdfs
start-dfs.sh
启动如果成功,可以使用jps查看java 进程
如果看到如下进程,说明OK
6、继续查看网站是否可以正常访问:
http://192.168.32.100:9870
7、进行测试
1、准备一些数据
数据还使用之前的即可
2、将这些数据存放到hdfs平台上
hdfs dfs -put input /
将本地的input文件夹,上传到hdfs平台上的根路径下
3、执行任务
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
此处虽然命令跟之前一模一样,但是数据来源和执行的结果存放的位置已经发生了变化,都在hdfs平台上。
4、查看运行结果
hdfs dfs -cat /output/*
3、全分布模式

若有收获,就点个赞吧
0 人点赞
