一、知识梳理(作业,标注哪些会,哪些不熟,哪些不会)
二、Azkaban
1、环境安装(参照昨天的文档)
总结:配置文件写错了(直接粘贴我的文档) mysql的驱动包使用 8.0 的版本。
2、Azkaban的使用
1)Azkaban的Flow1.0 (编写脚本的老版本)
1. azkaban的job流文件,后缀是.job
1) type属性 必须赋值
值有:command,java,pig
2. azkaban执行的job必须要提前打包,打包的格式必须是zip格式
3. 流文件里的书写格式:
1)一定要注意行末不要有空格
2)编码集的问题,如果在window上实在不行,可以上传到linux进行zip压缩,然后下载到windows上,再上传到azkaban
举例:编写一个简单的job:
第一步:编写first.job
type=command
command=echo 'hello,'$JAVA_HOME'';
确保我们的脚本中的每一行没有空格: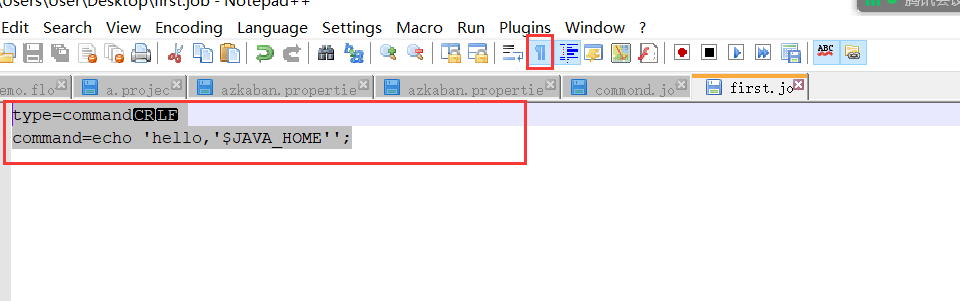
第二步:将我们的job进行压缩,zip
第三步:上传到azkaban的平台上:
http://bigdata01:8081
先创建项目(如果之前有项目,可以不创建)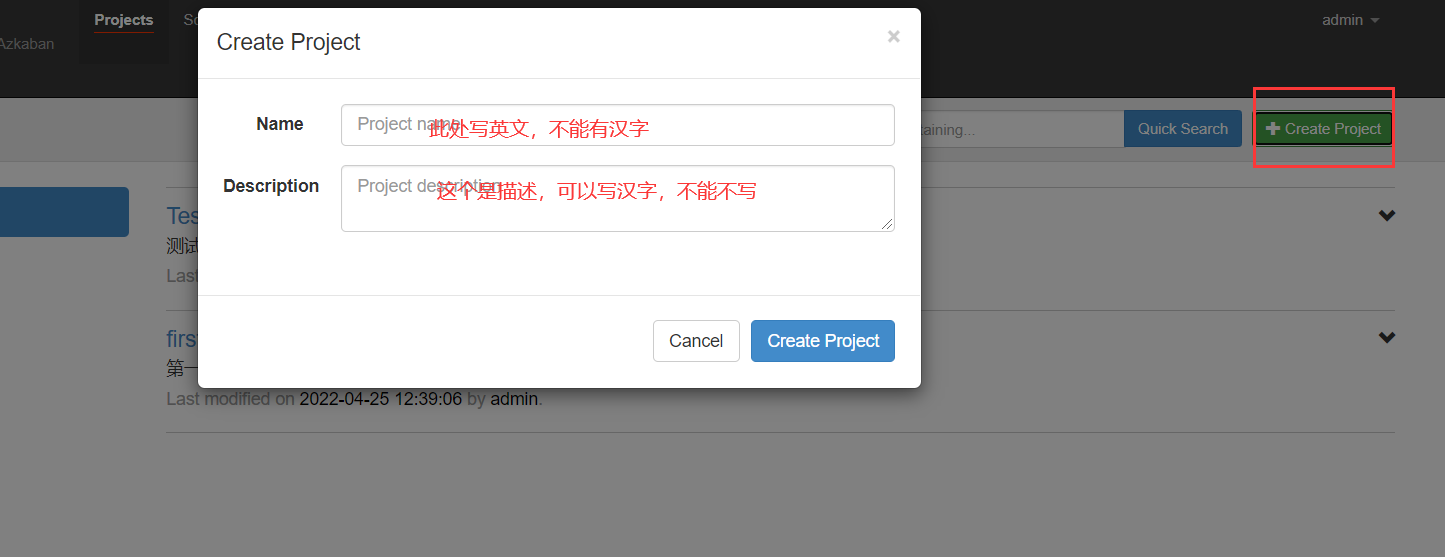
打开项目,上传压缩包: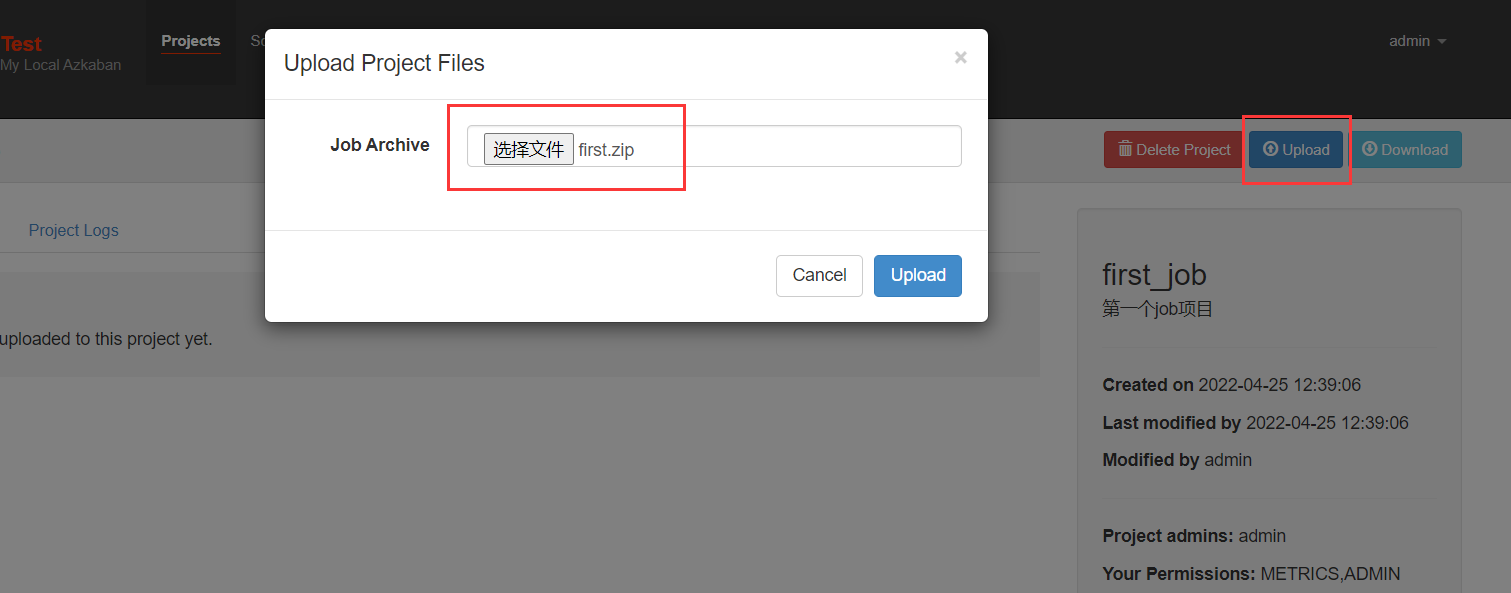
接着执行该job任务:

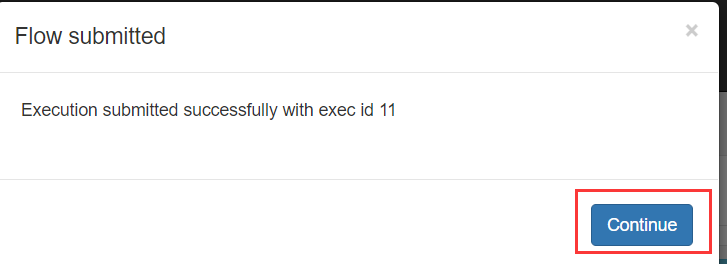


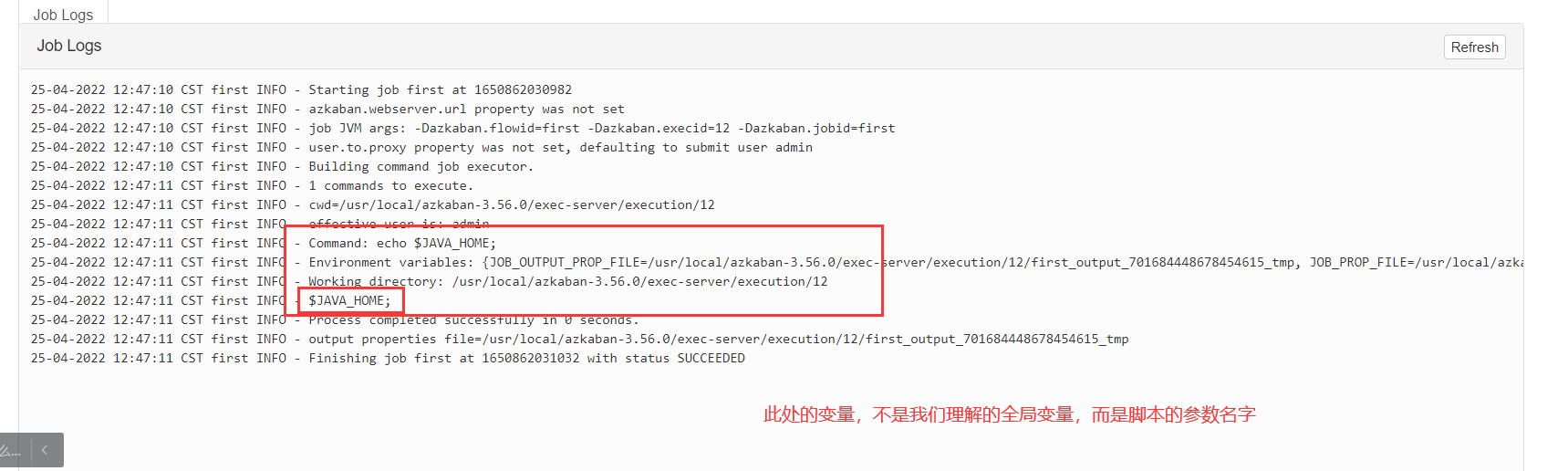
如果你出现了这个错误: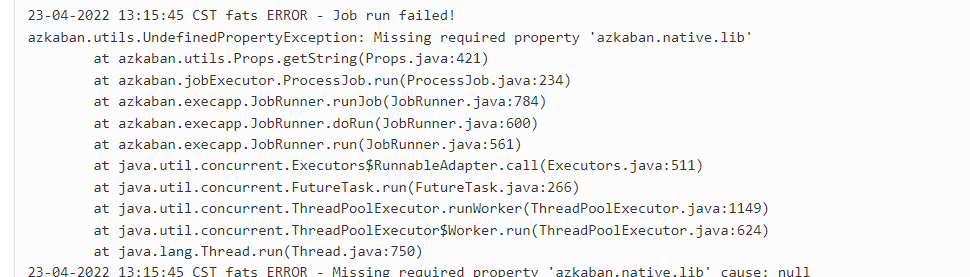
修改exec-server中的一个配置即可:
修改exec-server 中的 azkaban.properties
azkaban.jobtype.plugin.dir=/usr/local/azkaban-3.56.0/exec-server/plugins/jobtypes
重启exec-server 即可。
进入bin
shutdown-exec.sh
start-exec.sh
2)Azkaban的Flow2.0 (编写脚本的新版本)
Azkaban 可以 调度 我们shell脚本,mr任务,hive的hql语句,设置定时任务,设置工作流等。
Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用 Flow 2.0,因为 Flow 1.0 会在将来的版本被移除。Flow 2.0 的主要设计思想是提供 1.0 所没有的流级定义。用户可以将属于给定流的所有 job / properties 文件合并到单个流定义文件中,其内容采用 YAML 语法进行定义,同时还支持在流中再定义流,称为为嵌入流或子流。
演示:
第一个案例:
第一步,编写 flow文件 ,比如 simple.flow
nodes:
- name: jobA
type: command
config:
command: echo "this is a simple test"
- name: jobB
type: command
config:
command: echo "this is a jobB!"
第二步:编写一个project 文件 ,比如 a.project
azkaban-flow-version: 2.0
第三步:打包成zip文件,上传至我们的项目中(可以是老项目,也可以重新创建一个新项目)
执行一下,查看结果,后面的步骤跟flow1 是一样的。
目前企业中普遍使用第二种写法。
理论(主要学习yaml的语法):
1. 大小写敏感
2. 使用缩进表示层级关系 ;
3. 缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级;
4. 使用#表示注释 ;
5. 字符串默认不用加单双引号,但单引号和双引号都可以使用,双引号表示不需要对特殊字符进行转义;
6. YAML 中提供了多种常量结构,包括:整数,浮点数,字符串,NULL,日期,布尔,时间。
具体的细节:
编写yaml (yml) 就好比是 以前写的 xml
4.3.2 对象的写法
# value 与 : 符号之间必须要有一个空格
key: value
4.3.3 map的写法
# 写法一 同一缩进的所有键值对属于一个map
key:
key1: value1
key2: value2
# 写法二
{key1: value1, key2: value2}
4.3.4 数组的写法
# 写法一 使用一个短横线加一个空格代表一个数组项
- a
- b
- c
# 写法二
[a,b,c]
4.3.5 单双引号
s1: '内容\n 字符串'
s2: "内容\n 字符串"
转换后:
{ s1: '内容\\n 字符串', s2: "内容\n 字符串" }
4.3.6 特殊符号
一个 YAML 文件中可以包括多个文档,使用 `---` 进行分割。
4.3.7 配置引用
Flow 2.0 建议将公共参数定义在 `config` 下,并通过 `${}` 进行引用。
第二个案例:多任务串联
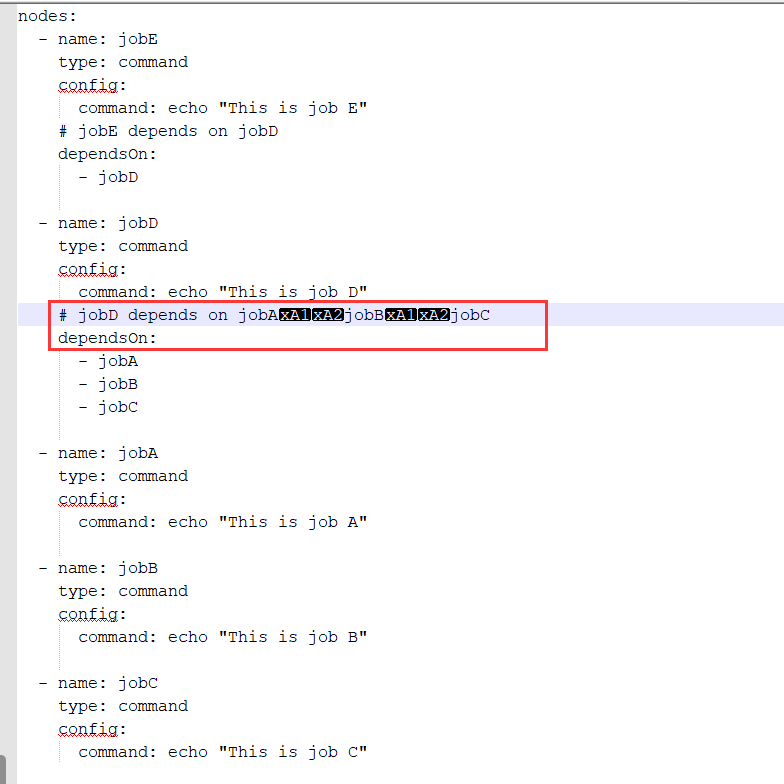
第一步:创建文件 second.flow
nodes:
- name: jobE
type: command
config:
command: echo "This is job E"
# jobE depends on jobD
dependsOn:
- jobD
- name: jobD
type: command
config:
command: echo "This is job D"
# jobD depends on jobA jobB jobC
dependsOn:
- jobA
- jobB
- jobC
- name: jobA
type: command
config:
command: echo "This is job A"
- name: jobB
type: command
config:
command: echo "This is job B"
- name: jobC
type: command
config:
command: echo "This is job C"
第二步:创建 second.project
azkaban-flow-version: 2.0
第三步:压缩上传,执行
注意:
1、出现字符集问题,请用notepad++将文件修改为utf-8 的字符集,然后删除特殊字符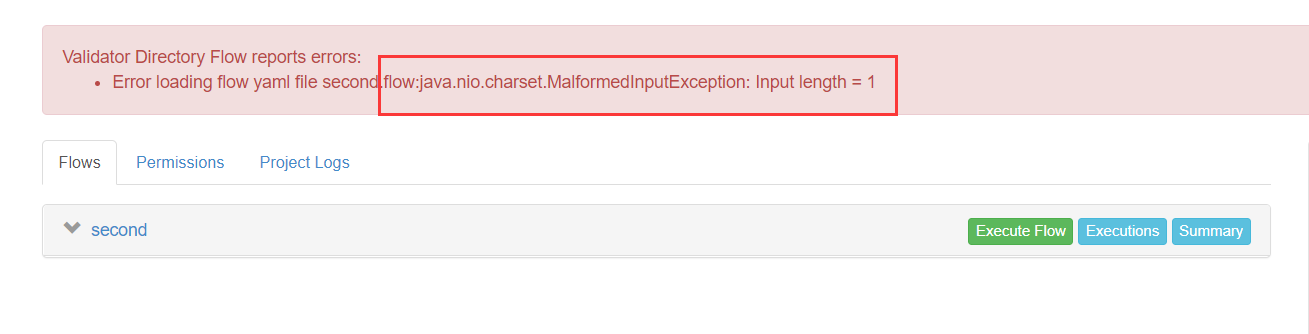
将文件从ansi 格式修改为 utf-8 with out bom 格式 即可,删除里面的特殊字符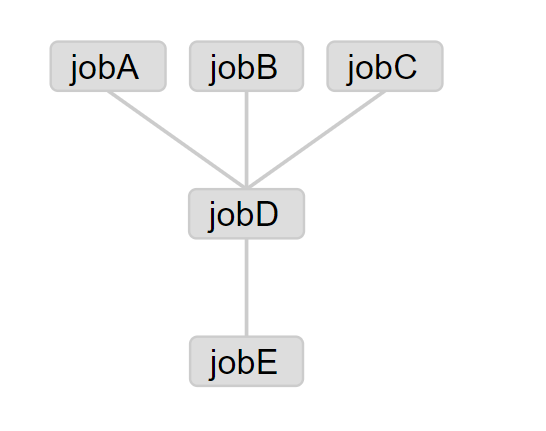
2、dependsOn:
- jobA
此处的-只要一个,不要写两个,要有空格隔开。
第三个案例:
编写脚本:
third.flow
nodes:
- name: jobC
type: command
config:
command: echo "This is job C"
dependsOn:
- embedded_flow
- name: embedded_flow
type: flow
config:
prop: value
nodes:
- name: jobB
type: command
config:
command: echo "This is job B ${prop}"
dependsOn:
- jobA
- name: jobA
type: command
config:
command: echo "This is job A"
third.project:
azkaban-flow-version: 2.0

编写文件的时候,注意字符集(gbk —> utf-8 )
关于定时任务:
azkaban的重试机制:
# 重试次数
retries: 3
# 每次重试时间间隔
retry.backoff: 10000
案例:
nodes:
- name: jobA
type: command
config:
command: echo "this is a simple test"
retries: 3
retry.backoff: 10000
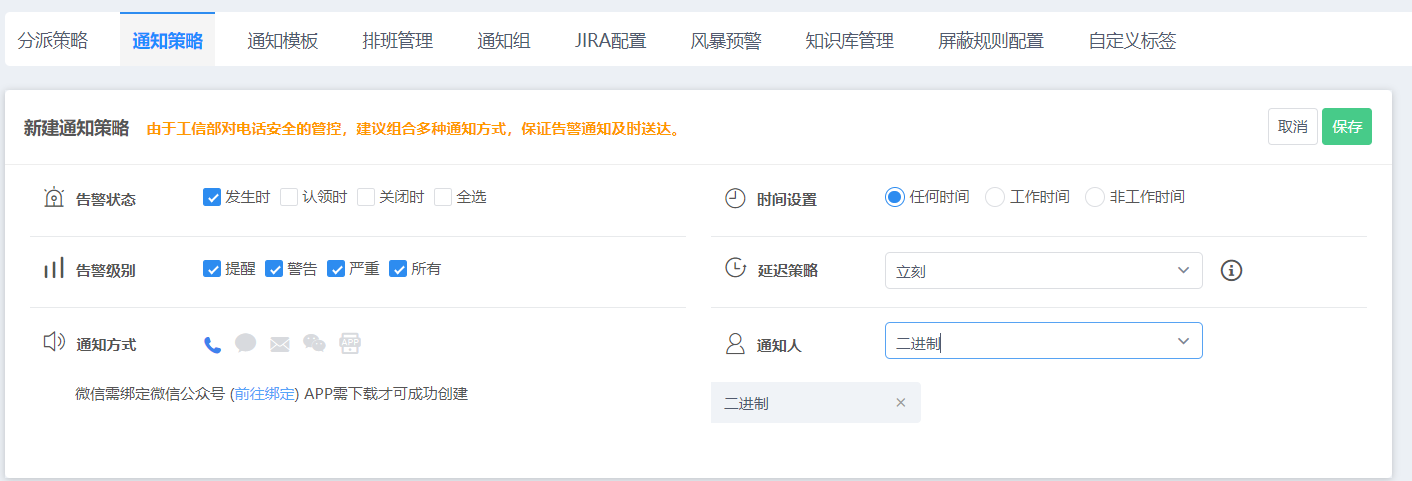
3) azkaban的报警机制(运维)
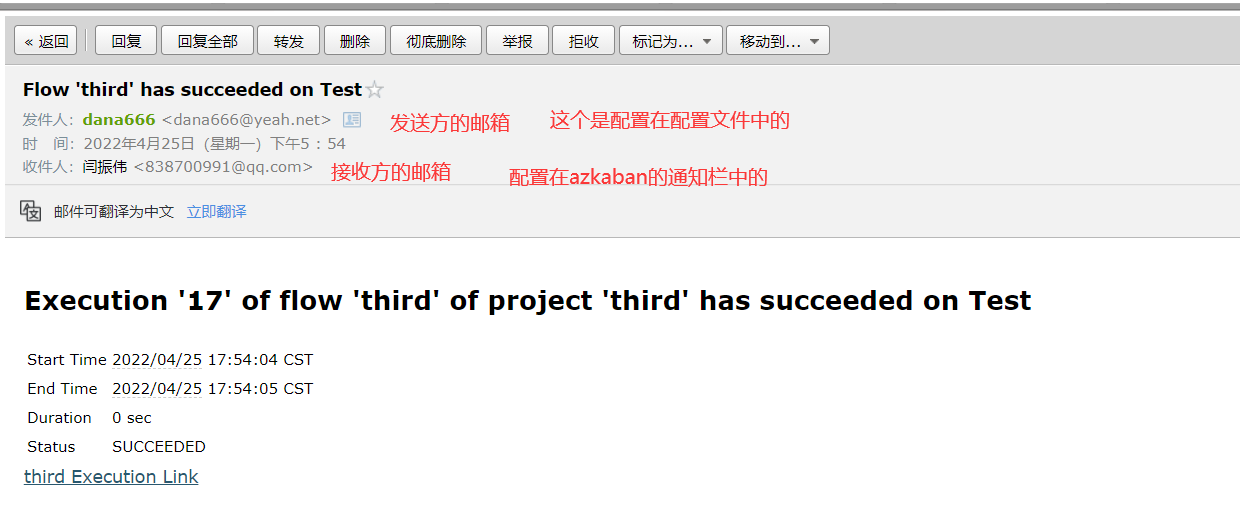
1、邮箱通知
第一步:找一个你经常使用的邮箱,获取秘钥: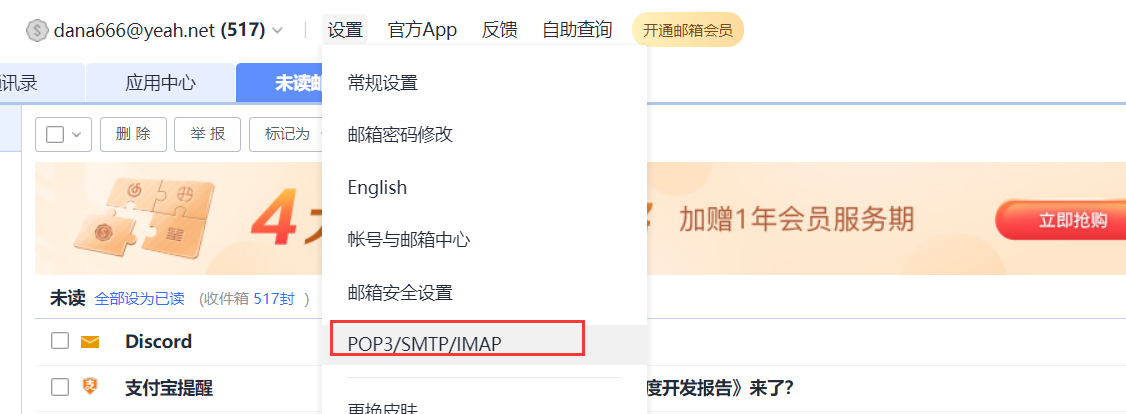
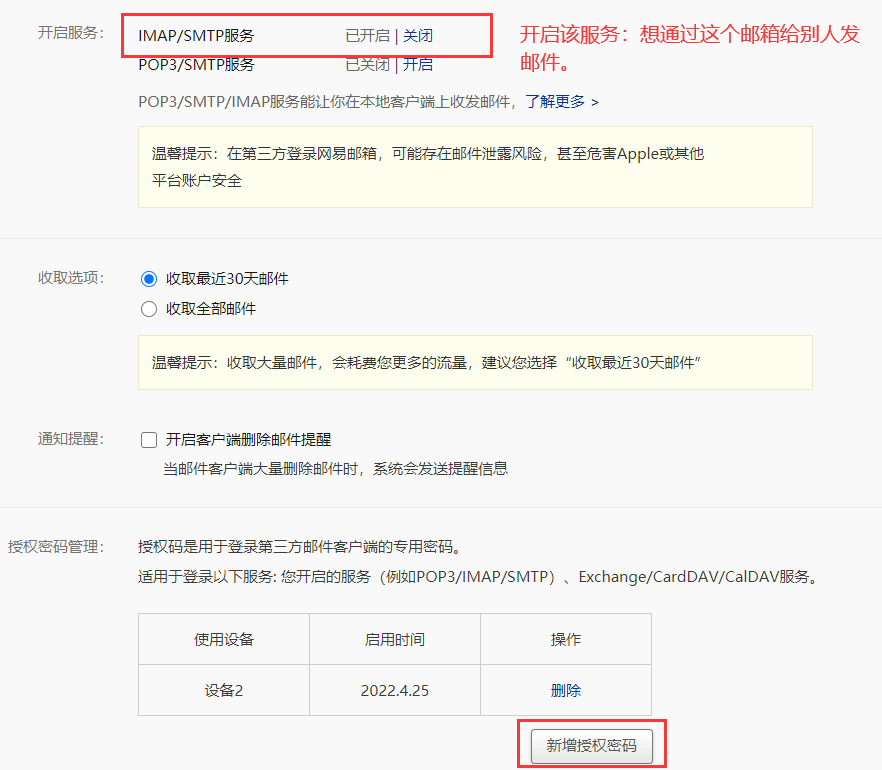
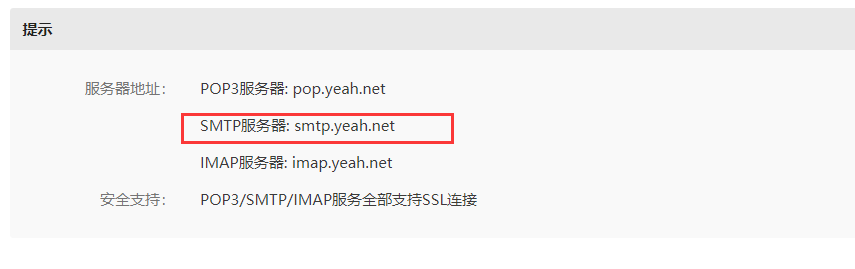
接着进行配置:
在azkaban的 web-server 端,进行邮箱的配置:
mail.sender=dana666@yeah.net
mail.host=smtp.yeah.net
mail.user=dana666@yeah.net
mail.password=XDBXQZLWMDKQTCVO
2、电话通知
需要借助于第三方平台:https://www.aiops.com/ 注册,登录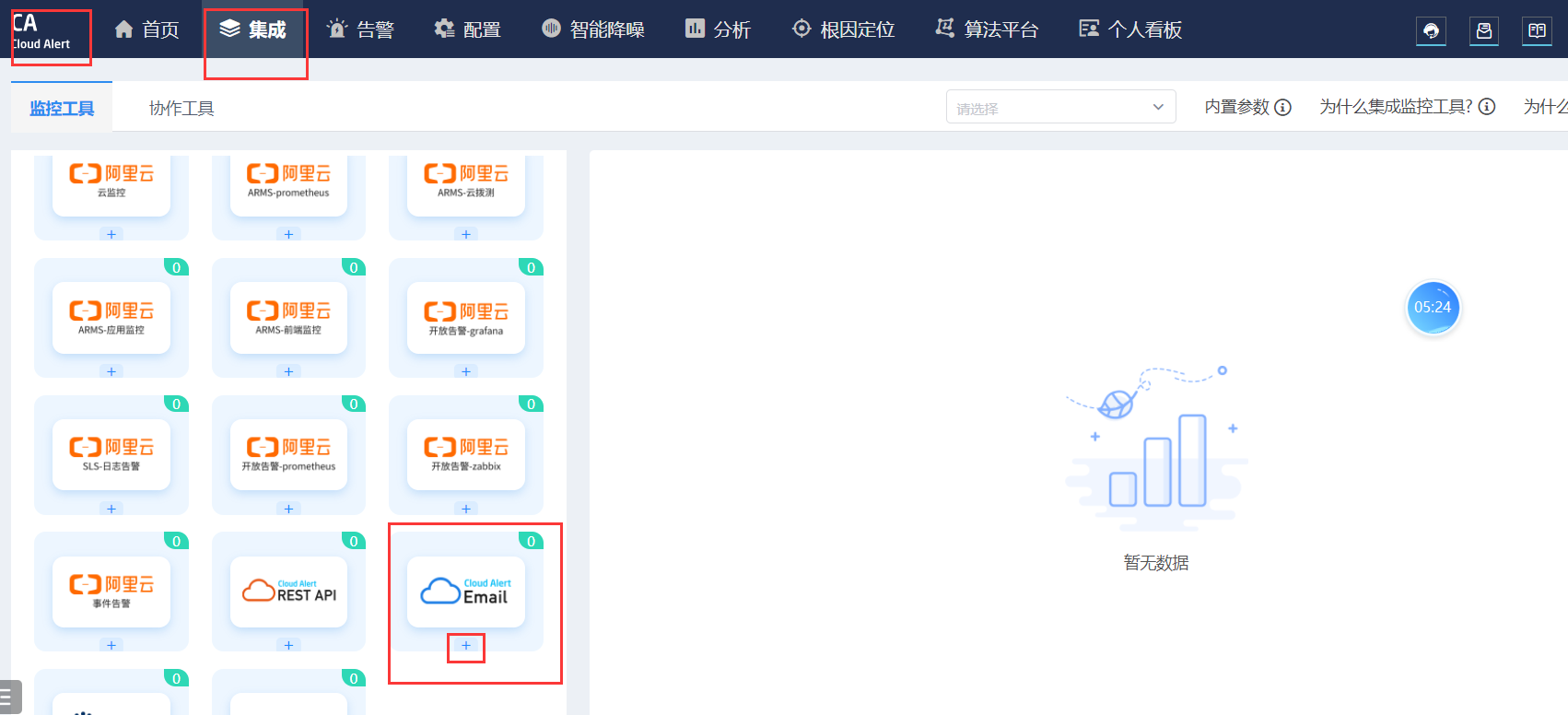
记得提交保存。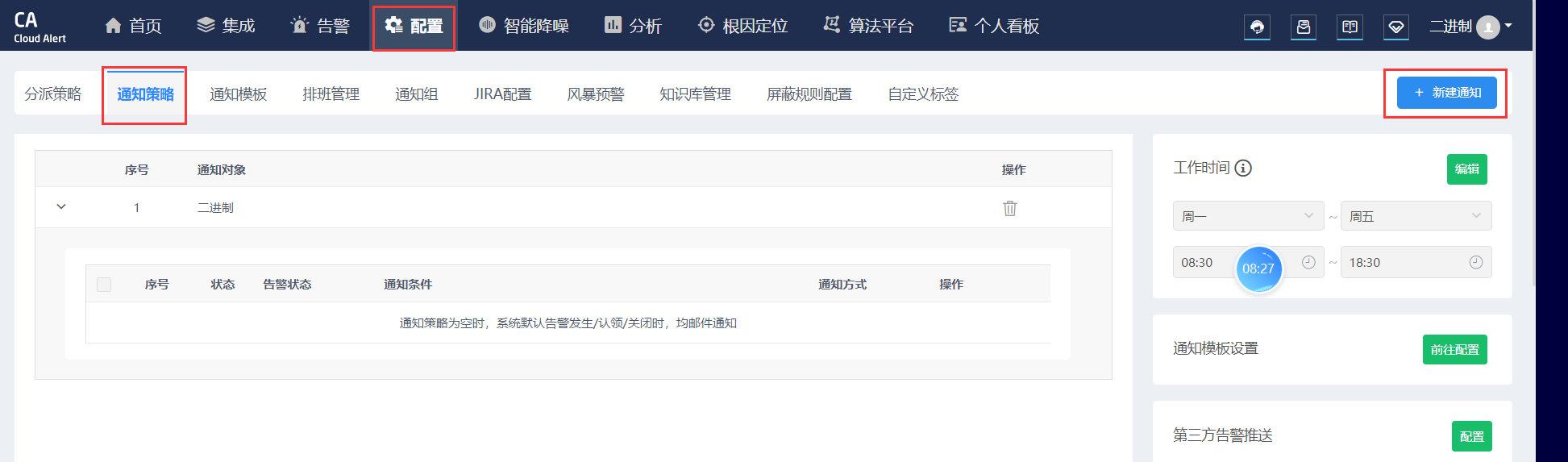
接着,拷贝该平台给你的邮箱。
二、superset
官网:https://superset.apache.org/
作用:不需要编写任何的代码就可以将mysql中的数据展示为各种图标(数据改变,图标也跟着变。)
安装步骤:
1、下载:
https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
2、安装 miniconda(它是py的集成环境)
3、上传,安装 (/home/soft)
bash Miniconda3-latest-Linux-x86_64.sh
安装过程中,会先让你查看协议,一直摁回车即可,到头以后,问你是否同意该协议? 你输入 yes.
后面 让你指定安装的路径, [/root/miniconda3] >>> /usr/local/miniconda3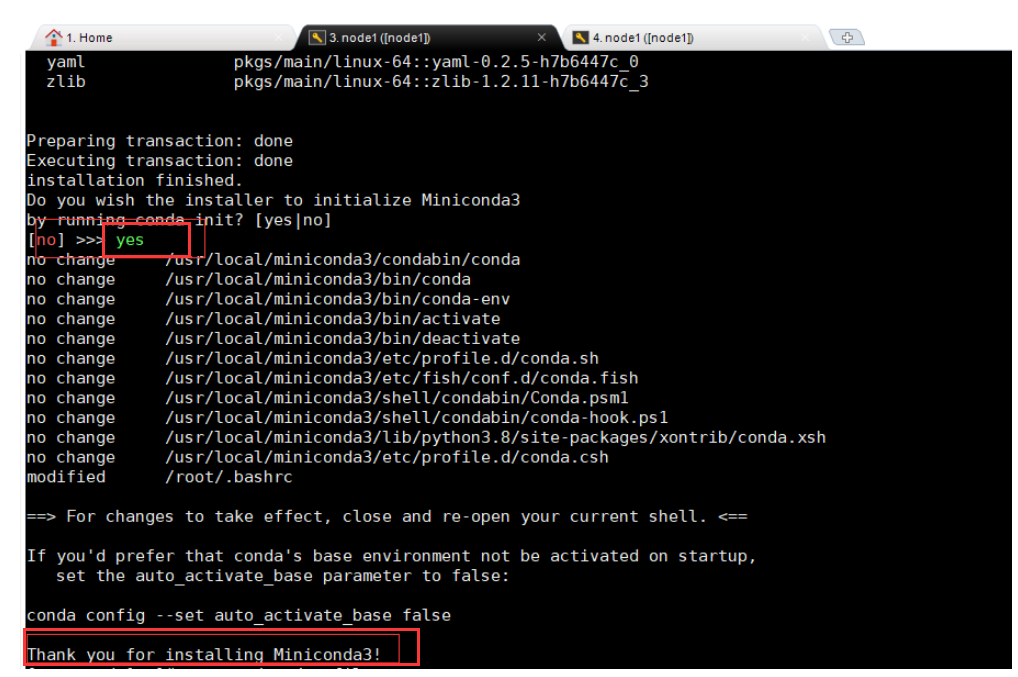
4、修改环境变量 /etc/profile
export CONDA_HOME=/usr/local/miniconda3
export PATH=$PATH:$CONDA_HOME/bin
一定要 source /etc/profile
5、取消激活base环境
conda config --set auto_activate_base false
6、配置python3.6环境
第一步:
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --set show_channel_urls yes
查看执行效果:
查看下.condarc文件,是否是如下配置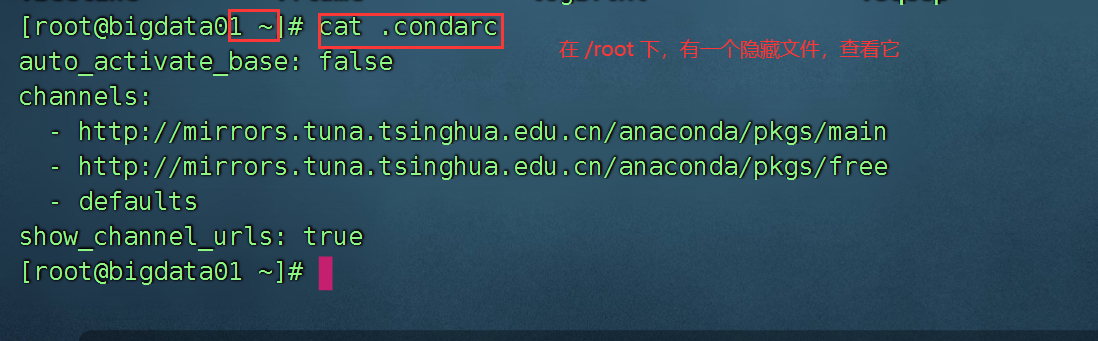
第二步:创建superset环境
conda create -n superset python=3.6
不要执行文档中的后面几个说明的命令,那个是说明命令的用法的。
第三步:激活superset环境
source activate
conda activate superset
7、superset的部署
1)安装依赖:
yum install -y python-setuptools
yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel
2)安装(更新)setuptools和pip
pip install --upgrade setuptools pip -i https://pypi.douban.com/simple/
说明:pip是python的包管理工具,可以和centos中的yum类比。
3) 安装superset
pip install apache-superset -i https://pypi.douban.com/simple/
看到这个successful即可: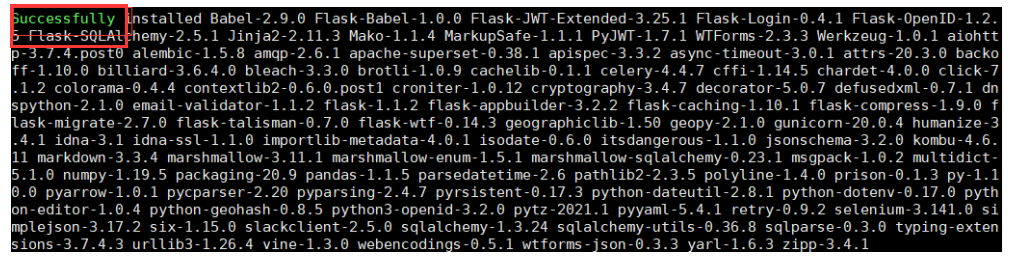
4) 初始化数据库:
superset db upgrade
会遇到错误: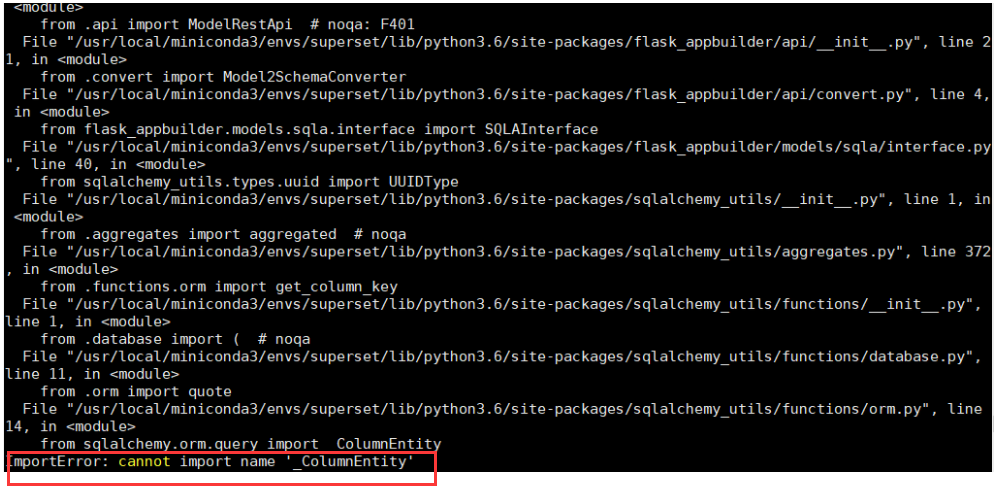
ImportError: cannot import name '_ColumnEntity'
这个错误:
解决方案:
pip install tushare --upgrade
pip install sqlalchemy==1.3.24
记得,一样看一下前面是否有:(superset)

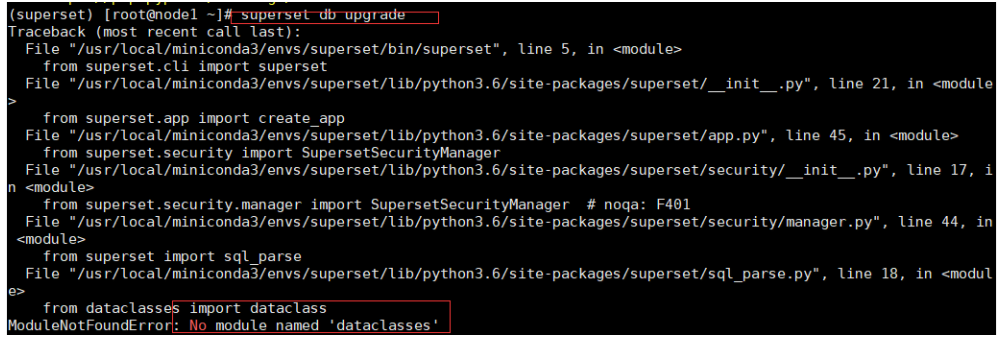
上面错误的解决方案:
pip install dataclasses
如果执行这个命令,报红了,网速有点慢造成的。
解决办法:
pip install dataclasses -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install dataclasses
如果不再报错,继续初始化我们的数据库:
superset db upgrade
如果以上都没有错误,就说明这一步结束了。
创建管理员:
export FLASK_APP=superset
flask fab create-admin
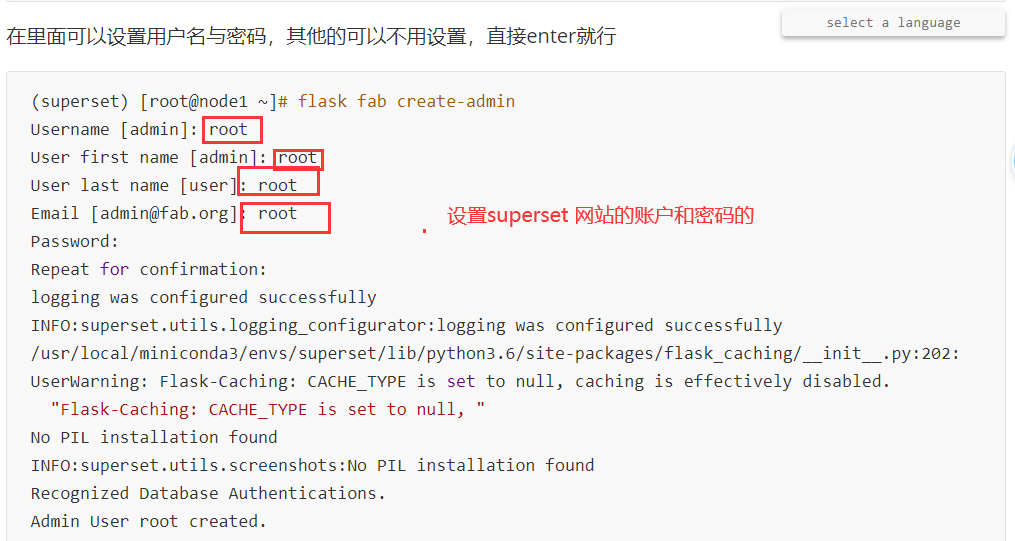
在superset 环境下,进行初始化:
superset init

启动superset环境:
pip install gunicorn -i https://pypi.douban.com/simple/
gunicorn -w 1 -t 120 -b bigdata01:8787 "superset.app:create_app()"
一定要确保是在 superset的环境里面启动的,否则会失败的,如何判定当前的环境呢?
看 ,如果不在,怎么进入呢?conda activate superset
,如果不在,怎么进入呢?conda activate superset
通过浏览器访问surset : http://192.168.32.100:8787
账户和密码都是root。

若有收获,就点个赞吧
0 人点赞
