一、有三个Hive的表,分别是A、B、C,数据如下,求三个表中互不重复的数据
提示: 不重复的数据,即在三张表中所有的数据加载一起时,只出现了一次
A.txt B.txt C.txt
1 2 1
2 3 2
3 11 3
4 12 11
5 14 5
6 15 6
7 16 7
8 18 8
9 35 20
6 30
7 40
直接写SQL:
1、创建三个txt文件,拷贝数据进去2、创建表,该表只有一个字段 比如叫 id如果想使用hive,只需要保证hdfs以及yarn进程开启即可。创建数据库:create database zuoye;create table a (id int);load data local inpath "/root/zuoyedata/a.txt" into table a;create table b(id int);load data local inpath "/root/zuoyedata/b.txt" into table b;create table c(id int);load data local inpath "/root/zuoyedata/c.txt" into table c;3、编写SQL语句:select id from (select id from aunion allselect id from bunion allselect id from c) t1 group by id having count(1) = 1;
二、有数据如下,求英雄出场次数Top3的出场次数及出场率(出场次数/总场次)
id heros
1 廉颇,镜,沈梦溪,李元芳,太乙真人
2 关羽,兰陵王,嬴政,虞姬,鲁班大师
3 梦琪,盘古,周瑜,狄仁杰,大乔
4 廉颇,澜,上官婉儿,公孙离,盾山
5 吕布,娜可露露路,姜子牙,公孙离,张飞
6 马超,猪八戒,狄仁杰,沈梦溪,太乙真人
7 吕布,盘古,嫦娥,公孙离,张飞
8 廉颇,橘右京,西施,虞姬,大乔
9 关羽,镜,姜子牙,狄仁杰,鲁班大师
10 梦琪,阿古朵,周瑜,后羿,蔡文姬
11 夏侯惇,娜可露露,不知火舞,孙尚香,太乙真人
12 猪八戒,镜,嫦娥,伽罗,孙膑
13 廉颇,镜,上官婉儿,马可波罗,蔡文姬
14 梦琪,裴擒虎,沈梦溪,虞姬,鲁班大师
15 梦琪,盘古,不知火舞,成吉思汗,太乙真人
16 夏侯惇,澜,周瑜,马可波罗,张飞
17 猪八戒,露娜,周瑜,狄仁杰,盾山
18 吕布,橘右京,西施,蒙伢,蔡文姬
19 吕布,赵云,西施,公孙离,张飞
20 廉颇,兰陵王,沈梦溪,虞姬,大乔
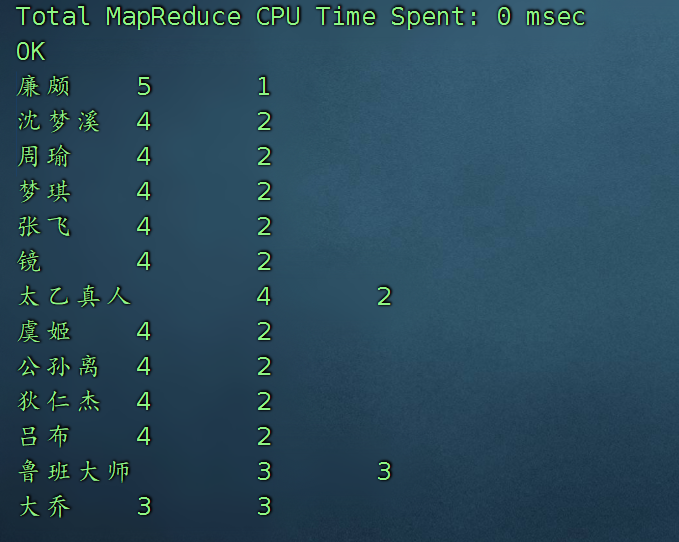
廉颇的总出场次数, 每一个英雄的出场次数
造数据:game.txt
创建表:
create table game(
id int,
heros array<string>
)row format delimited
fields terminated by '\t'
collection items terminated by ',' ;
加载数据:
load data local inpath "/root/zuoyedata/game.txt" into table game;
第一步:列转行
select id , name from game lateral view explode(heros) hero as name;

select name,count(1) from game lateral view explode(heros) hero as name group by name;
有欠缺的版本,因为20 是 手动搞出来的
select name,cc , cc/20 from (
select name,count(1) cc from game lateral view explode(heros) hero as name group by name ) t1
order by cc desc limit 3;
修改的版本:
select name,cc , cc/c2 from (
select name,count(1) cc from game lateral view explode(heros) hero as name group by name ) t1,
(select count(1) c2 from game) t2
order by cc desc limit 3;
升级版:
1、
select name, cc , dense_rank() over (order by cc desc) paiming from (
select name,count(1) cc from game lateral view explode(heros) hero as name group by name ) t1;
最终的SQL:
select * from (
select
name, cc , row_number() over (order by cc desc) paiming,
cc/ (sum(cc) over() / 5) bili
from (
select name,count(1) cc from game lateral view explode(heros) hero as name group by name ) t1
) t2 where paiming <= 3 order by paiming;

3、 有如下数据,表示1、2、3三名学生选修了a、b、c、d、e、f中的若干课程
id course
1 a
1 b
1 c
1 e
2 a
2 c
2 d
2 f
3 a
3 b
3 c
3 e
根据如上数据,查询出如下结果,其中1表示选修,0表示未选修
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
SQL语句:
create table zhoukao03 (
id int,
course string
)
row format delimited
fields terminated by '\t';
编写SQL语句:
select id ,
sum(case when course="a" then 1 else 0 end ) a,
sum(case when course="b" then 1 else 0 end ) b,
sum(case when course="c" then 1 else 0 end ) c,
sum(case when course="d" then 1 else 0 end ) d,
sum(case when course="e" then 1 else 0 end ) e,
sum(case when course="f" then 1 else 0 end ) f
from zhoukao03 group by id;
4、有如下数据
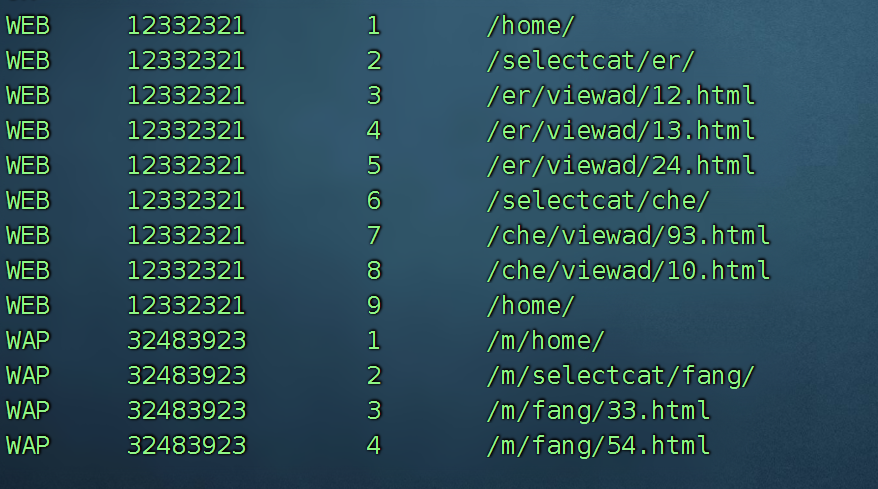
PLATFORM USER_ID CLICK_TIME CLICK_URL
WEB 12332321 2013-03-21 13:48:31.324 /home/
WEB 12332321 2013-03-21 13:48:32.954 /selectcat/er/
WEB 12332321 2013-03-21 13:48:46.365 /er/viewad/12.html
WEB 12332321 2013-03-21 13:48:53.651 /er/viewad/13.html
WEB 12332321 2013-03-21 13:49:13.435 /er/viewad/24.html
WEB 12332321 2013-03-21 13:49:35.876 /selectcat/che/
WEB 12332321 2013-03-21 13:49:56.398 /che/viewad/93.html
WEB 12332321 2013-03-21 13:50:03.143 /che/viewad/10.html
WEB 12332321 2013-03-21 13:50:34.265 /home/
WAP 32483923 2013-03-21 23:58:41.123 /m/home/
WAP 32483923 2013-03-21 23:59:16.123 /m/selectcat/fang/
WAP 32483923 2013-03-21 23:59:45.123 /m/fang/33.html
WAP 32483923 2013-03-22 00:00:23.984 /m/fang/54.html
WAP 32483923 2013-03-22 00:00:54.043 /m/selectcat/er/
WAP 32483923 2013-03-22 00:01:16.576 /m/er/49.html
…… …… …… ……
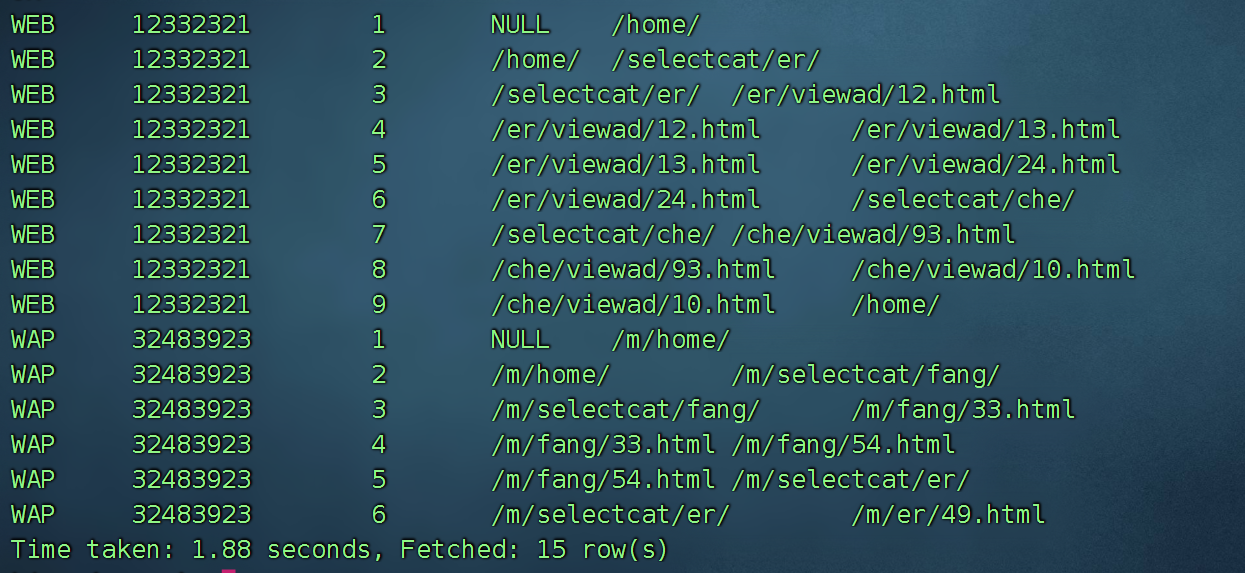
现需将数据整理成如下数据结构
PLATFORM USER_ID SEQ FROM_URL TO_URL
WEB 12332321 1 NULL /home/
WEB 12332321 2 /home/ /selectcat/er/
WEB 12332321 3 /selectcat/er/ /er/viewad/12.html
WEB 12332321 4 /er/viewad/12.html /er/viewad/13.html
WEB 12332321 5 /er/viewad/13.html /er/viewad/24.html
WEB 12332321 6 /er/viewad/24.html /selectcat/che/
WEB 12332321 7 /selectcat/che/ /che/viewad/93.html
WEB 12332321 8 /che/viewad/93.html /che/viewad/10.html
WEB 12332321 9 /che/viewad/10.html /home/
WAP 32483923 1 NULL /m/home/
WAP 32483923 2 /m/home/ /m/selectcat/fang/
WAP 32483923 3 /m/selectcat/fang/ /m/fang/33.html
WAP 32483923 4 /m/fang/33.html /m/fang/54.html
WAP 32483923 5 /m/fang/54.html /m/selectcat/er/
WAP 32483923 6 /m/selectcat/er/ /m/er/49.html
…… …… …… …… ……
说明:PLATFORM和USER_ID还是代表平台和用户ID;
SEQ字段代表用户按时间排序后的访问顺序,
FROM_URL和TO_URL分别代表用户从哪一页跳转到哪一页。
对于某个平台上某个用户的第一条访问记录,其FROM_URL是NULL(空值)。
直接使用
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
开始编写:
创建 web.txt
创建表:
CREATE TABLE ALLOG
(PLATFORM string,
USER_ID int,
VISITE_TIME string,
FROM_URL string)
row format delimited
fields terminated by '\t';
加载数据:
load data local inpath "/root/zuoyedata/web.txt" into table ALLOG;
编写SQL语句:
select
PLATFORM,
USER_ID ,
row_number() over (partition by user_id order by VISITE_TIME ) SEQ,
FROM_URL
from allog ;
继续修改:
select
PLATFORM,
USER_ID ,
row_number() over (partition by user_id order by VISITE_TIME ) SEQ,
LAG(FROM_URL,1,null) over(partition by user_id order by VISITE_TIME) as FROM_URL,
FROM_URL as TO_URL
from allog ;
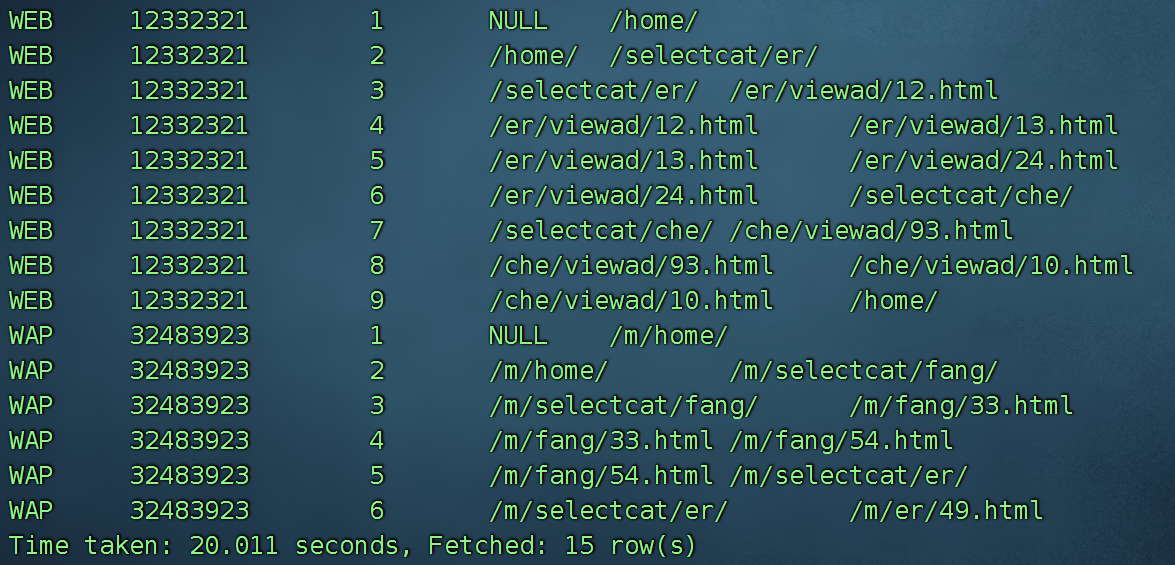
另一种写法,如何做:
select t1.PLATFORM,t1.USER_ID,t1.SEQ, t2.from_url, t1.from_url from
(
select *,row_number() over (partition by user_id order by VISITE_TIME ) SEQ from allog
) t1
left join
(
select *,row_number() over (partition by user_id order by VISITE_TIME ) SEQ from allog
) t2
on t1.user_id = t2.user_id and t1.SEQ = t2.SEQ+1;
5、Employee 表包含所有员工和他们的经理。每个员工都有一个 Id,并且还有一列是经理的 Id。
Id Name department managerId
101 john A NULL
102 dan A 101
103 james A 101
104 amy A 101
105 Anne A 101
…
请编写一个SQL查询来查找至少有4名直接下属的经理。
思路:根据managerId进行分组,进行count(1) ,如果值大于等于4 ,就说明这个经理的下属有4个人以上,根据经理的id,查询经理的其他信息。
select * from employee where id in (
select managerId from employee group by managerId having count(1) >= 4);
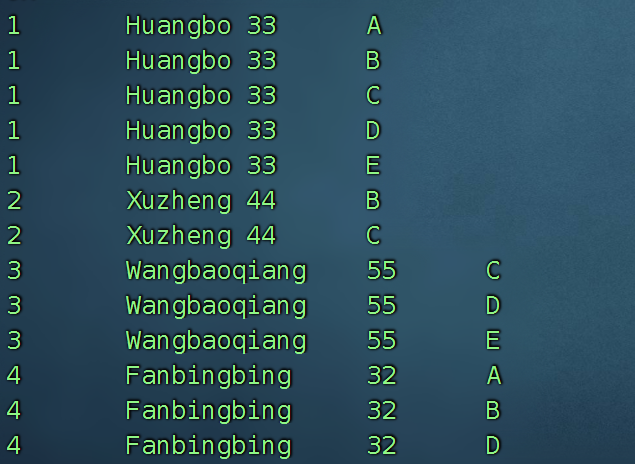
6、 现在有一份数据mingxing_favor表:
Id Name Age Favor
1 Huangbo 33 A,B,C,D,E
2 Xuzheng 44 B,C
3 Wangbaoqiang 55 C,D,E
4 Fanbingbing 32 A,B,D
求出每种爱好中年龄最大的人,如果有相同的年龄,请并列显示
创建表:
CREATE TABLE mingxing_favor
(
id int,
name string,
age int,
favor string)
row format delimited
fields terminated by '\t';
load 数据:
load data local inpath "/root/zuoyedata/mingxing.txt" into table mingxing_favor;
编写SQL:
先展开数据:
select id,name,age,xq from mingxing_favor lateral view explode (split(favor,',')) xingqu as xq ;
SQL:
select id,name,age,xq,
dense_rank() over(partition by xq order by age desc)
from mingxing_favor lateral view explode (split(favor,',')) xingqu as xq ;
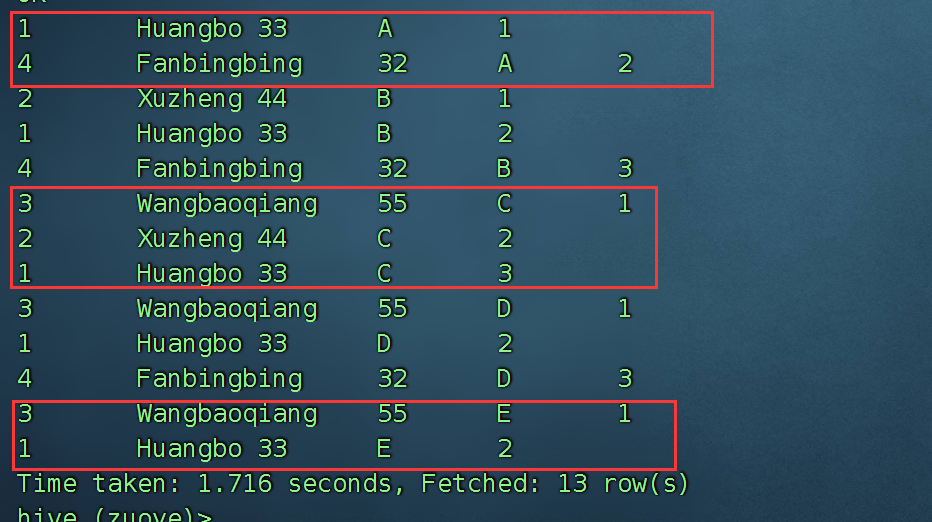
最终的SQL:
select id,name,age,xq from (
select id,name,age,xq,
dense_rank() over(partition by xq order by age desc) paiming
from mingxing_favor lateral view explode (split(favor,',')) xingqu as xq ) t1 where paiming=1;

7、我们有如下的用户访问数据:
userId visitDate visitCount
u01 2017/1/21 5
u02 2017/1/23 6
u03 2017/1/22 8
u04 2017/1/20 3
u01 2017/1/23 6
u01 2017/2/21 8
U02 2017/1/23 6
U01 2017/2/22 4
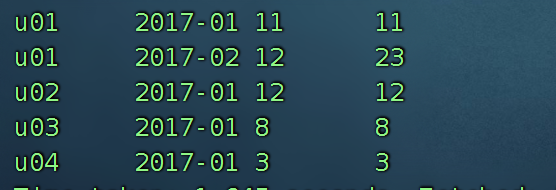
要求使用SQL统计出每个用户的累积访问次数,如下表所示:
用户id 月份 小计 累积
u01 2017-01 11 11
u01 2017-02 12 23
u02 2017-01 12 12
u03 2017-01 8 8
u04 2017-01 3 3
准备数据:visit.txt
创建表:
create table visitors(
userId string,
visitDate string,
visitCount int)
row format delimited fields terminated by ' ';
加载数据:
load data local inpath "/root/zuoyedata/visit.txt" into table visitors;
编写:
思路是根据用户和年月进行分组,同一年同一个月的放在一起,但是2017/1/21 如何获取年月日呢?
先将这个日期变为时间戳,再通过时间戳获取2017-01-21 这样的日期格式:
select unix_timestamp(); //获取当前的时间戳
select unix_timestamp('2017/1/21','yyyy/MM/dd') ;
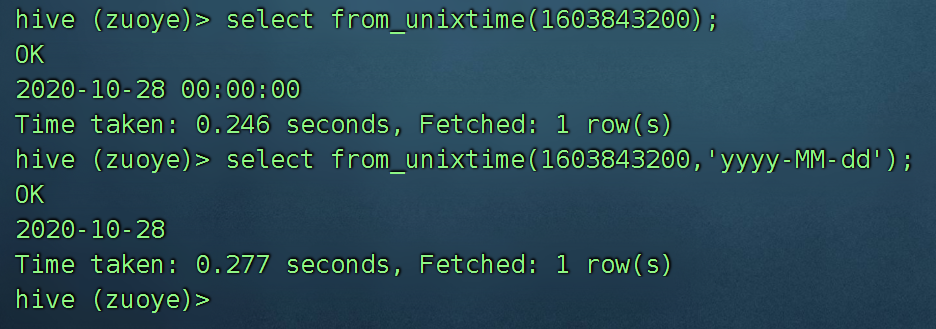
根据时间戳,指定输出日期的格式:
select from_unixtime(1603843200);
select from_unixtime(1603843200,'yyyy-MM-dd');
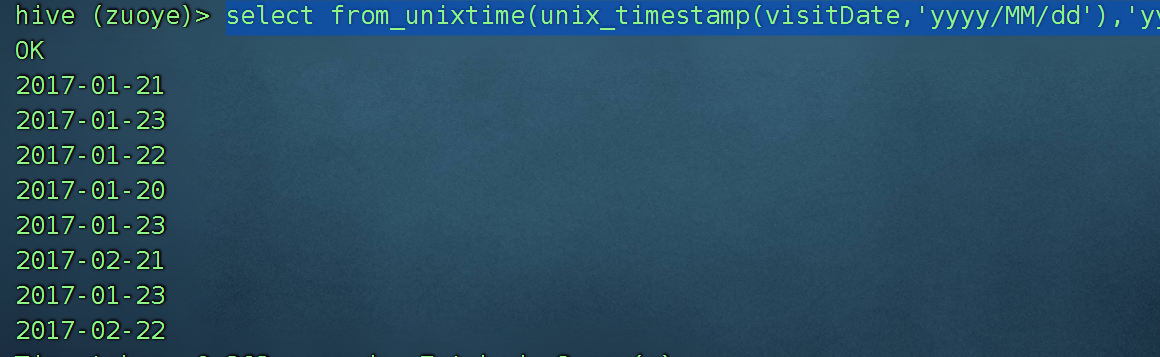
获取数据库中的日期字段:
select from_unixtime(unix_timestamp(visitDate,'yyyy/MM/dd'),'yyyy-MM-dd') from visitors;
拿到日期之后,可以进行字符串的切割:
select substring(from_unixtime(unix_timestamp(visitDate,'yyyy/MM/dd'),'yyyy-MM-dd'),1,7) from visitors;

select userId,substring(from_unixtime(unix_timestamp(visitDate,'yyyy/MM/dd'),'yyyy-MM-dd'),1,7),visitCount from visitors;
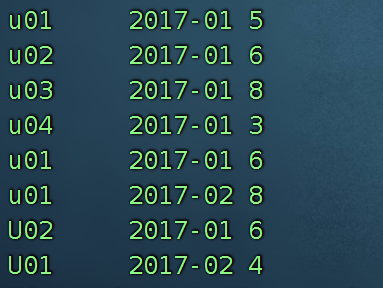
继续写:
select userId,dt,sum(visitCount) from (
select userId,substring(from_unixtime(unix_timestamp(visitDate,'yyyy/MM/dd'),'yyyy-MM-dd'),1,7) dt,visitCount from visitors ) t1 group by userId,dt;
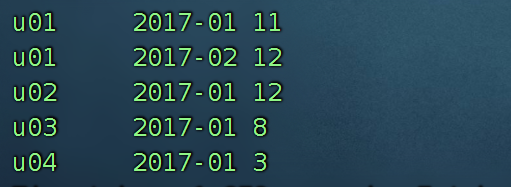
引入开窗函数:
select
userId,
dt,
s1,
sum(s1) over (partition by userId order by dt rows between UNBOUNDED PRECEDING and current row)
from (
select
userId,dt,sum(visitCount) s1
from (
select
userId,
substring(from_unixtime(unix_timestamp(visitDate,'yyyy/MM/dd'),'yyyy-MM-dd'),1,7) dt,
visitCount from visitors )
t1 group by userId,dt
)
t2 ;
8、有很多的天猫店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志, 访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称为shop,数据如下
u1 a
u2 b
u1 b
u1 a
u3 c
u4 b
u1 a
u2 c
u5 b
u4 b
u6 c
u2 c
u1 b
u2 a
u2 a
u3 a
u5 a
u5 a
u5 a
(1)每个店铺的UV(访客数) 一个客户不管来多少回,都只算一回。
(2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
第一步:造数据shop.txt
第二步:创建表
create table shop(user_id string,shop string) row format delimited fields terminated by '\t';
第三步加载数据:
load data local inpath "/root/zuoyedata/shop.txt" into table shop;
(1)每个店铺的UV(访客数) 一个客户不管来多少回,都只算一回。
select s1.shop,count(distinct user_id) from shop s1 group by s1.shop ;

也可以这么干:
select s1.shop,user_id from shop s1 group by s1.shop,user_id ;
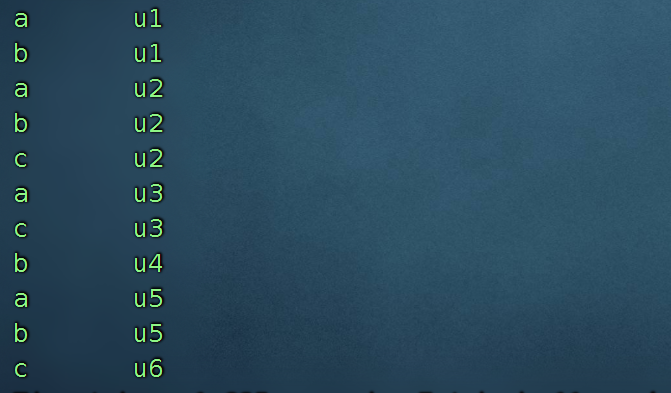
根据上面的结果集,然后再次的分组(按照店铺分组)
select t1.shop,count(1) from
(select s1.shop,user_id from shop s1 group by s1.shop,user_id )t1
group by t1.shop ;
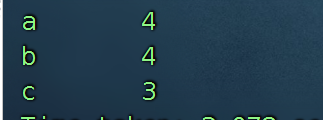
(2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
select
s.shop ,
s.user_id,
count(1) cs
from shop s
group by s.shop,s.user_id
;
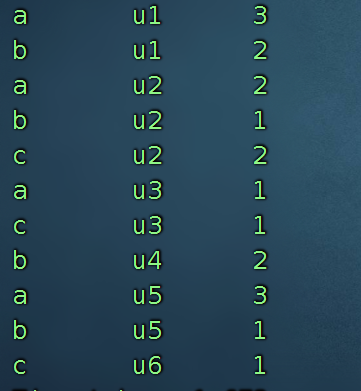
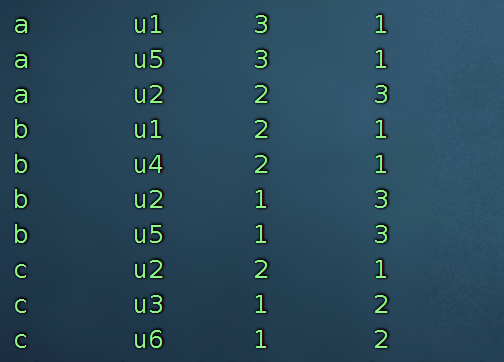
需要求出,a、b、c 三家店铺访问前三名的客户是谁,访问了多少次?
select * from (
select t1.shop ,
t1.user_id,
t1.cs,
rank() over (partition by t1.shop order by t1.cs desc ) paiming
from (
select
s.shop ,
s.user_id,
count(1) cs
from shop s
group by s.shop,s.user_id ) t1
) t2 where paiming <=3;
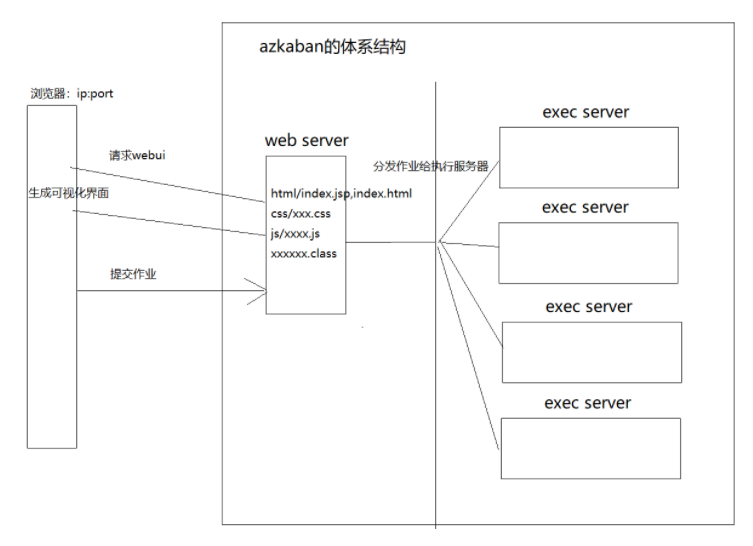
二、Azkaban理论
azkaban的作用其实就是将我们搭建数据的流程串联起来,并设置自动定时运行。
调度任务工具:
之前我们执行的shell命令,mr任务,hive任务,flume,sqoop等任务,都可以配置在Azkaban中,帮助我们执行这些任务,并且还可以编排这些任务,还可以定时执行这些任务。
常见的调度工具:Azkaban 以及 Oozie 两个。
Oozie 偏笨重一些,体积大,安装包都有1.x个G,功能非常的齐全。
体系结构:
- WebServer :暴露Restful API,提供分发作业和调度作业功能;
- ExecServer :对WebServer 暴露 API ,提供执行作业的功能;
- MySQL :数据存储,实现Web 和 Exec之间的数据共享和部分状态的同步。
三、Azkaban的安装
安装方式有两种:一种是下载源码,自行编译(需要依赖多个其他软件),如果你没有安装其他,可以直接解压编译过的软件。
以下方式演示的是已经编译过的软件的安装。
第一步:上传,解压 
上传至 /home/soft 下面,解压
unzip azkaban-3.56.0.zip 解压到当前路径下
mv azkaban-3.56.0 /usr/local/ 移动该文件夹至 /usr/local/ 下。
第二步:在mySQL中生成元数据:
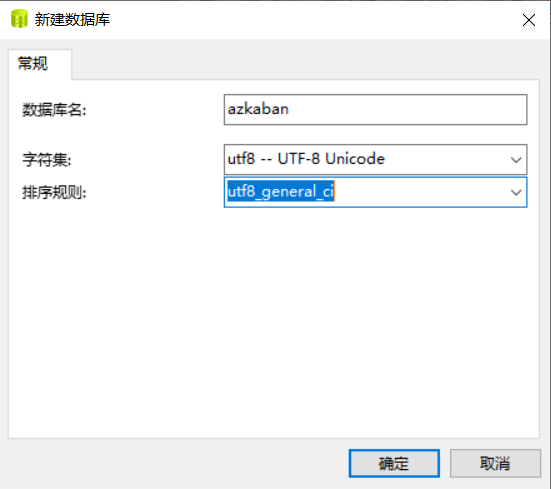
1、在mysql上,创建数据库 azkaban
执行SQL脚本文件: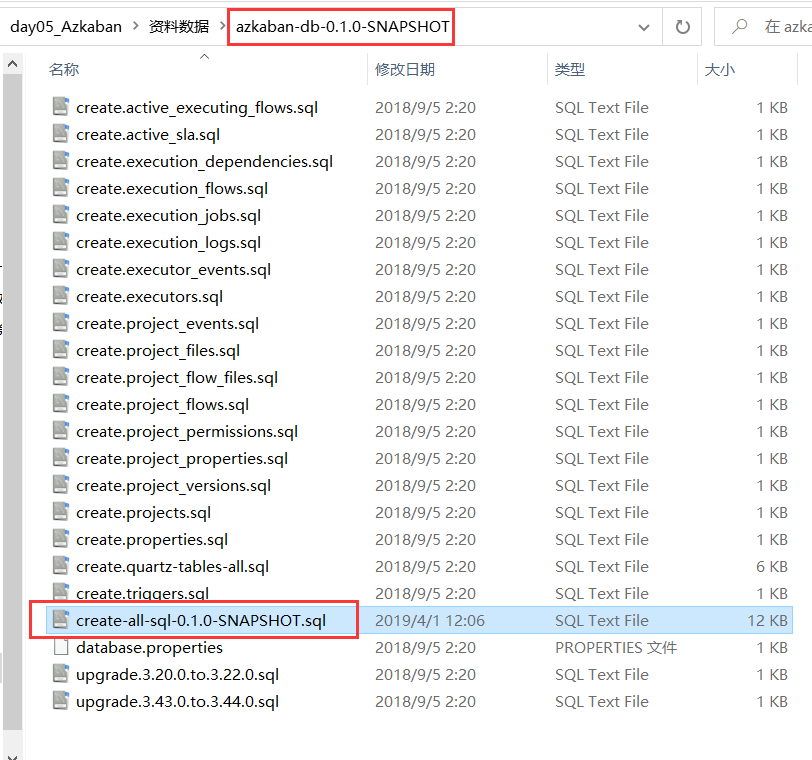
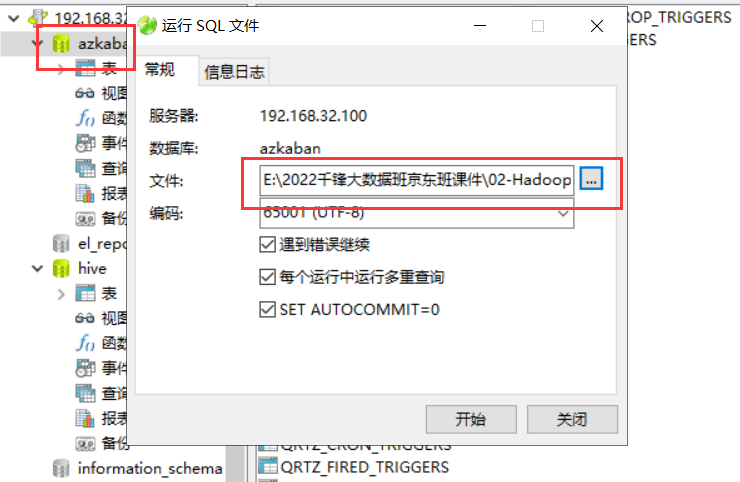
第三步:配置web-server
在 web-server 这个文件夹下,cd web-server
1、执行秘钥的生成:
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
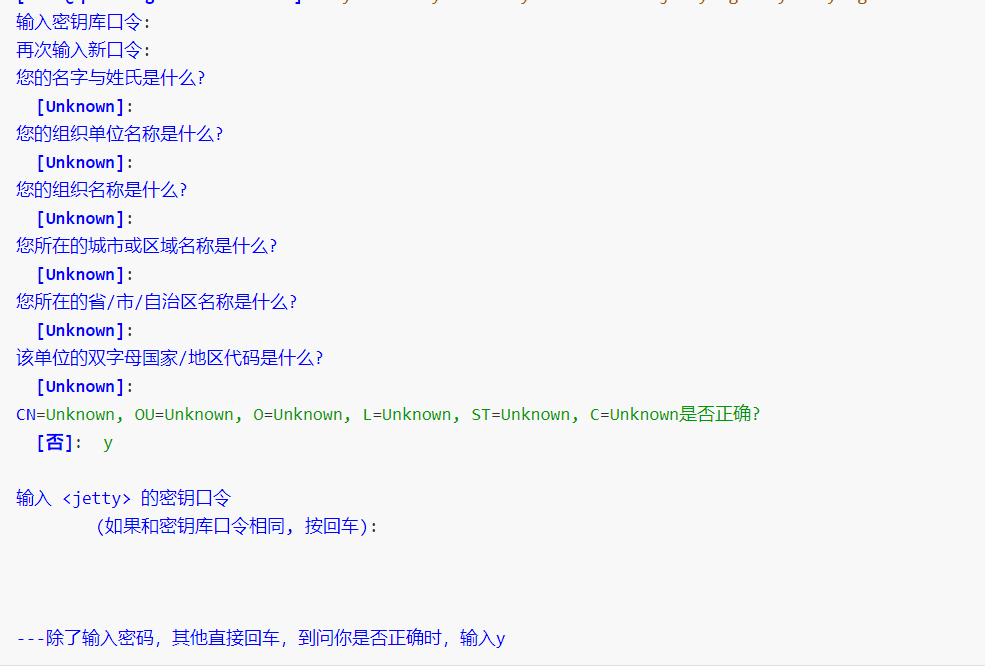
密码统一:123456
通过以上操作,会生成一个 keystore 这个文件。
2、编辑azkaban.properties
# Azkaban Personalization Settings
azkaban.name=Test
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
# 此处需要编写绝对路径,如果跟我的安装路劲一样,不需要改
web.resource.dir=/usr/local/azkaban-3.56.0/web-server/web
# 时区默认是美国时区,修改为上海时区
default.timezone.id=Asia/Shanghai
# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=/usr/local/azkaban-3.56.0/web-server/conf/azkaban-users.xml
# Loader for projects
executor.global.properties=/usr/local/azkaban-3.56.0/web-server/conf/global.properties
azkaban.project.dir=projects
# 配置mysql数据库连接的
database.type=mysql
mysql.port=3306
mysql.host=localhost
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100
# Velocity dev mode
velocity.dev.mode=false
# Azkaban Jetty server properties.
jetty.use.ssl=false
jetty.maxThreads=25
jetty.port=8081
# 此处是我们的生成的秘钥密码
jetty.keystore=keystore
jetty.password=123456
jetty.keypassword=123456
jetty.truststore=keystore
jetty.trustpassword=123456
# Azkaban Executor settings
executor.maxThreads=50
executor.port=12321
executor.flow.threads=30
# mail settings
#mail.sender=mx543042252@163.com
#mail.host=smtp.163.com
#mail.user=mx543042252@163.com
#mail.password=KFJYOIGXRIVFFIKP
# User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
# enduser -> myazkabanhost:443 -> proxy -> localhost:8081
# when this parameters set then these parameters are used to generate email links.
# if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
# azkaban.webserver.external_hostname=myazkabanhost.com
# azkaban.webserver.external_ssl_port=443
# azkaban.webserver.external_port=8081
job.failure.email=
job.success.email=
lockdown.create.projects=false
cache.directory=cache
# JMX stats
jetty.connector.stats=true
executor.connector.stats=true
azkaban.native.lib=false
# Azkaban plugin settings
azkaban.jobtype.plugin.dir=plugins/jobtypes
3、web-server/conf 目录下 azkaban-users.xml
添加用户:
<user password="admin" roles="admin,metrics" username="admin" />
将来登录我们的azkaban 用的。
完整的配置文件如下:
<azkaban-users>
<user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
<user password="metrics" roles="metrics" username="metrics"/>
<user groups="azkaban" password="test" roles="admin" username="test"/>
<user password="admin" roles="admin,metrics" username="admin" />
<role name="admin" permissions="ADMIN"/>
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
第四步:配置exec-server中的文件
1、配置conf 下的 azkaban.properties
# Azkaban Personalization Settings
azkaban.name=Azkaban
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=/usr/local/azkaban-3.56.0/web-server/web/
default.timezone.id=Asia/Shanghai
# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=/usr/local/azkaban-3.56.0/web-server/conf/azkaban-users.xml
# Loader for projects
executor.global.properties=/usr/local/azkaban-3.56.0/exec-server/conf/global.properties
azkaban.project.dir=projects/
azkaban.execution.dir=execution/
executor.flow.threads=30
flow.num.job.threads=10
job.log.chunk.size=100
job.log.backup.index=10
job.max.Xms=1
job.max.Xmx=2
azkaban.server.flow.max.running.minutes=-1
# Azkaban mysql settings by default. Users should configure their own username and password.
database.type=mysql
mysql.port=3306
mysql.host=bigdata01
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100
# Azkaban Executor settings
executor.maxThreads=50
executor.flow.threads=30
# Azkaban Executor settings
executor.maxThreads=50
executor.port=12321
executor.flow.threads=30
# JMX stats
jetty.connector.stats=true
executor.connector.stats=true
azkaban.native.lib=lib/
#azkaban.jobtype.plugin.dir=plugins/jobtypes
# uncomment to enable inmemory stats for azkaban
#executor.metric.reports=true
#executor.metric.milisecinterval.default=60000
2、修改插件文件
plugins/jobtypes/commonprivate.properties
set execute-as-user
execute.as.user=false
memCheck.enabled=false
第五步:替换 mysql 驱动包
在 web-server 以及 exec-server 中的lib目录下,删除 mysql-5.x 的驱动版本,替换为mysql-8.x的版本
rm -rf mysql-connector-java-5.1.28.jar
cp /usr/local/hive/lib/mysql-connector-java-8.0.26.jar /usr/local/azkaban-3.56.0/lib/
第六步:修改命令的执行权限
修改web-server 以及 exec-server 中的 bin目录下包括子文件夹下的所有的 .sh 结尾的文件,都修改为 777
第七步:启动,测试
进入web-server 这个目录下的bin目录下,启动web
./start-web.sh
进入exec-server 目录下的bin 下,启动exec
./start-exec.sh
启动成功后,jps查看进程: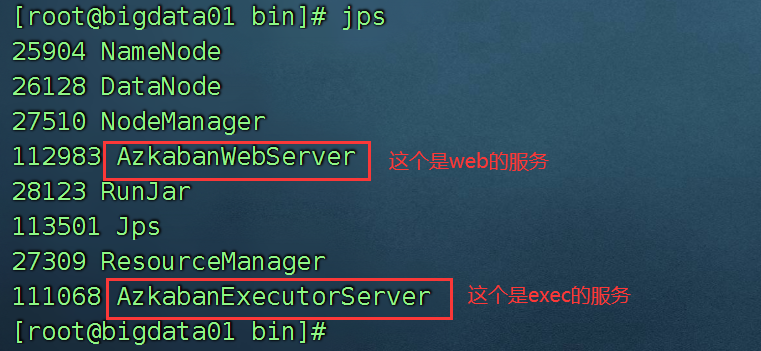
第八步:测试登录:
http://192.168.32.100:8081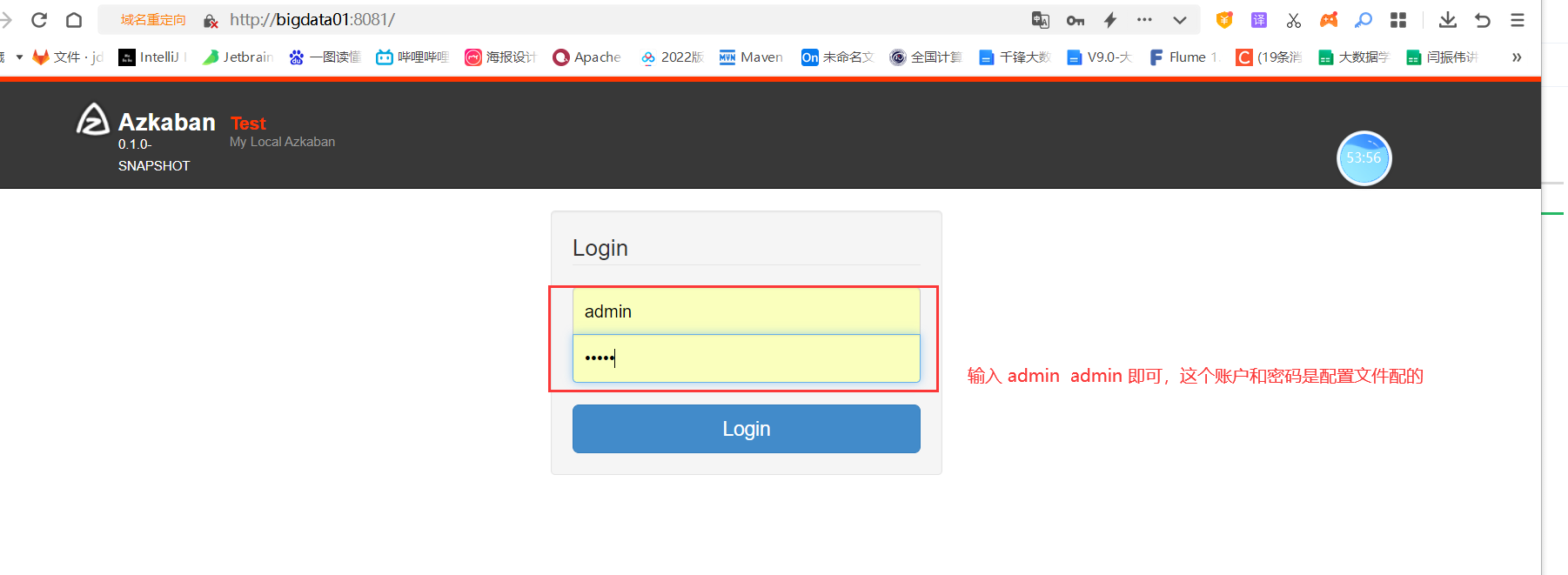

若有收获,就点个赞吧
0 人点赞
