一、全分布式环境的搭建
准备工作就绪:
1. 三台机器的防火墙必须是关闭的.2. 确保三台机器的网络配置畅通(NAT模式,静态IP,主机名的配置)3. 确保/etc/hosts文件配置了ip和hostname的映射关系4. 确保配置了三台机器的免密登陆认证(克隆会更加方便)5. 确保所有机器时间同步6. jdk和hadoop的环境变量配置
准备工作:
1、克隆一台新电脑
1)克隆操作 参见昨天的笔记
2)修改IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33重启网络服务:systemctl restart network查看ipip addr
修改主机名
vi /etc/hostname
修改hosts文件 vi /etc/hosts 然后分发到bigdata01 和 02 上<br />
scp /etc/hosts bigdata02:/etc/
2、确保网络畅通并且免密已经做好
ssh bigdata02
exit
ssh bigdata03
exit
3、确保jdk以及hadoop安装过了
java -verson
hadoop version
4、昨天的bigdata02没有安装hadoop
将bigdata01中的hadoop拷贝到bigdata02中
scp -r /usr/local/hadoop bigdata02:/usr/local/
并且将环境变量也拷贝过去:
scp -r /etc/profile bigdata02:/etc/
刷新一下bigdata02中的配置文件
source /etc/profile
全分布式搭建:
配置文件地址: /usr/local/hadoop/etc/hadoop/
修改core-site.xml
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>
修改hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
# Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
修改workers
bigdata01
bigdata02
bigdata03
接着分发到其余两台服务器上。
scp -r /usr/local/hadoop/etc/hadoop bigdata02:/usr/local/hadoop/etc/
scp -r /usr/local/hadoop/etc/hadoop bigdata03:/usr/local/hadoop/etc/
接着停止服务:
stop-dfs.sh
删除所有的临时文件 $HADOOP_HOME/tmp
将三台电脑上的 /usr/local/hadoop/tmp全部删除掉,因为里面有namenode和datanode数据,不便于我们格式化
rm -rf tmp
格式化namenode, 记得在bigdata01上进行格式化
hdfs namenode -format
启动hdfs
start-dfs.sh
启动完成后:
bigdata01上,jps查看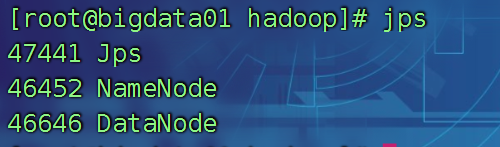
bigdata02上查看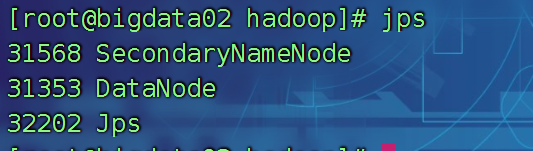
bigdata03上查看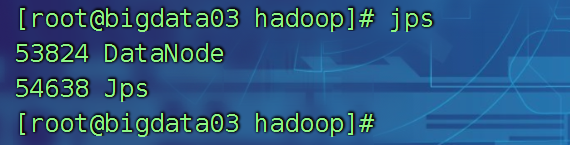
全分布式环境搭建的问题总结:
1、namenode 重新格式化的时候,需要删除之前的缓存文件 /usr/local/hadoop/tmp
2、没有将配置文件进行分发
3、资源不够用,导致namenode datanode
4、免密忘记做完了 bigdata01 --> 02,03
5、只能启动两台服务器,内存不够了,调整的小一些。
6、防火墙忘记关闭
systemctl stop firewalld
7、终极大招:全部检查一遍,重新进行namenode格式化
二、HDFS的shell操作
操作hdfs有三种操作方式:
1、使用图形化的界面进行操作
2、使用命令操作(shell操作)
3、使用java代码进行hdfs的操作
命令特别多,只需要学习我给大家讲的就够用了。
1、将文件或者文件夹上传至hdfs
hdfs dfs -put /home/a.txt /
hdfs dfs -put /home/input /
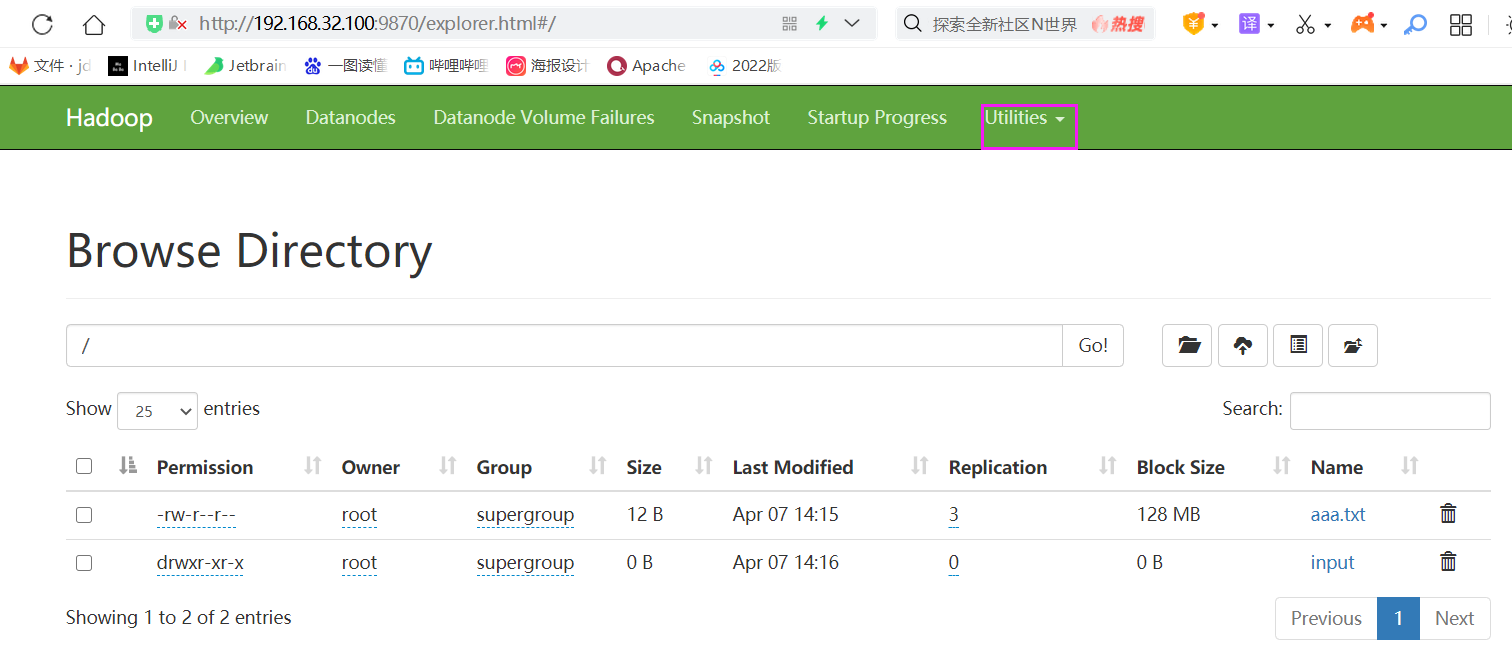
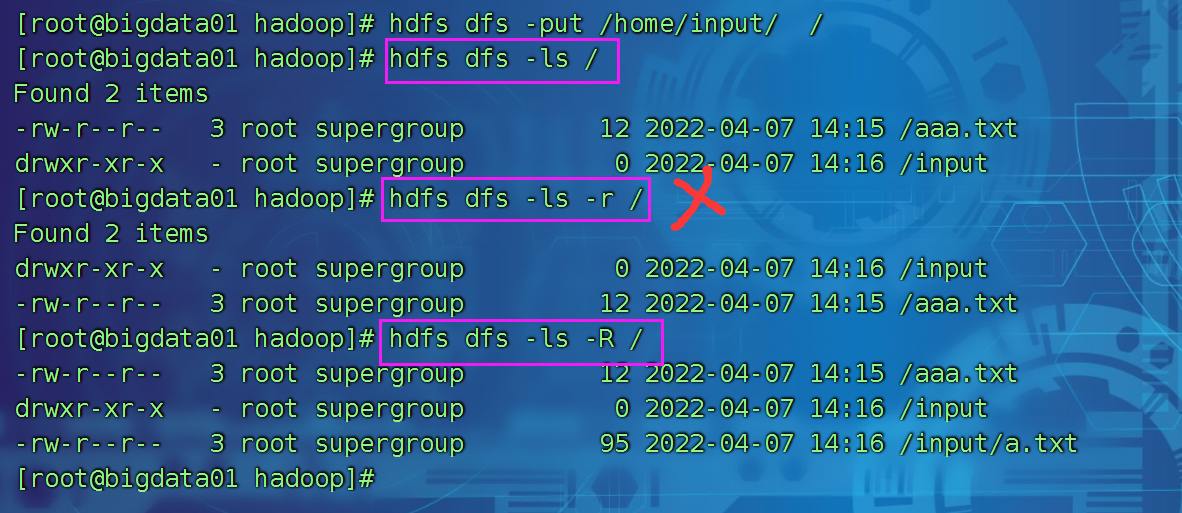
2、显示文件的列表
hdfs dfs -ls /
hdfs dfs -ls -R / 递归查看文件内容
hdfs dfs -lsr / == 第二个
创建文件夹
hdfs dfs -mkdir /abc
hdfs dfs -mkdir -p /bcd/def
查看文件的创建情况:
hdfs dfs -lsr /

移动某个文件到某处
hdfs dfs -moveFromLocal 本地文件 hdfs路径
hdfs dfs -moveFromLocal bbb.txt /abc

从hdfs上获取文件到本地
hdfs dfs -get hdfs上的文件 本地目录
hdfs dfs -get /abc/bbb.txt /home

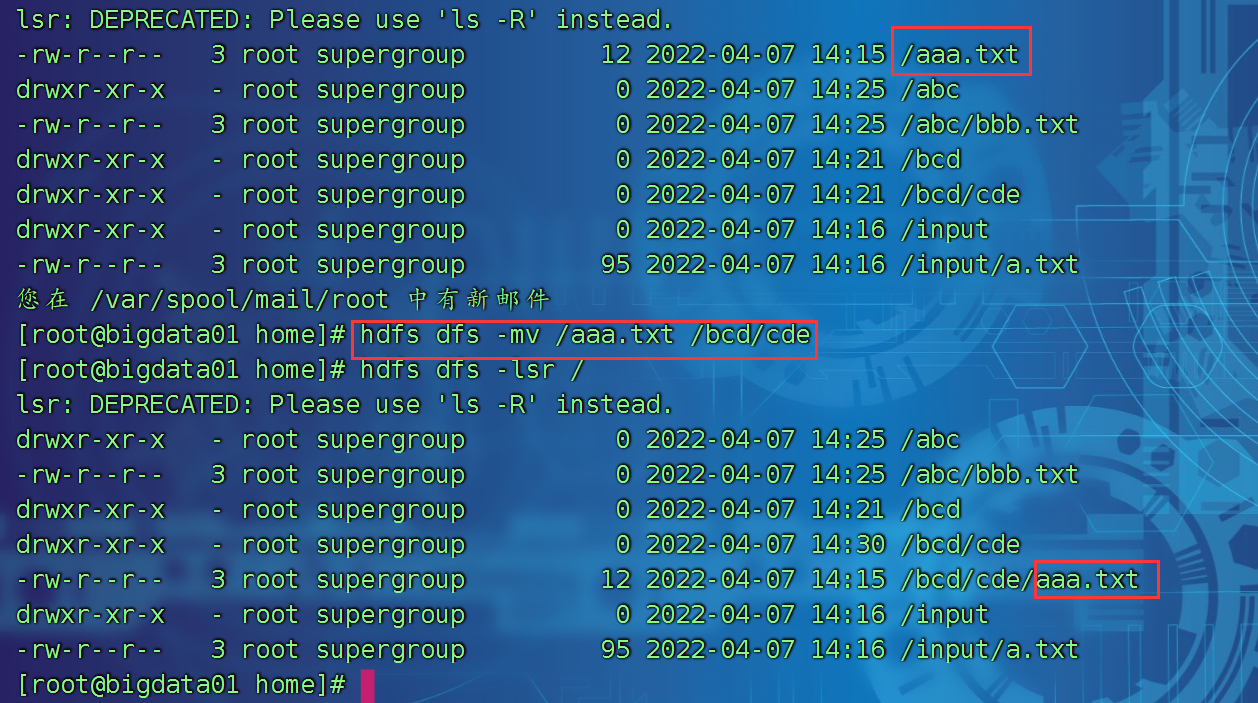
将hdfs上的文件进行相互移动
hdfs dfs -mv hdfs上的一个路径 hdfs上的另一个路径
hdfs dfs -mv /aaa.txt /bcd/cde
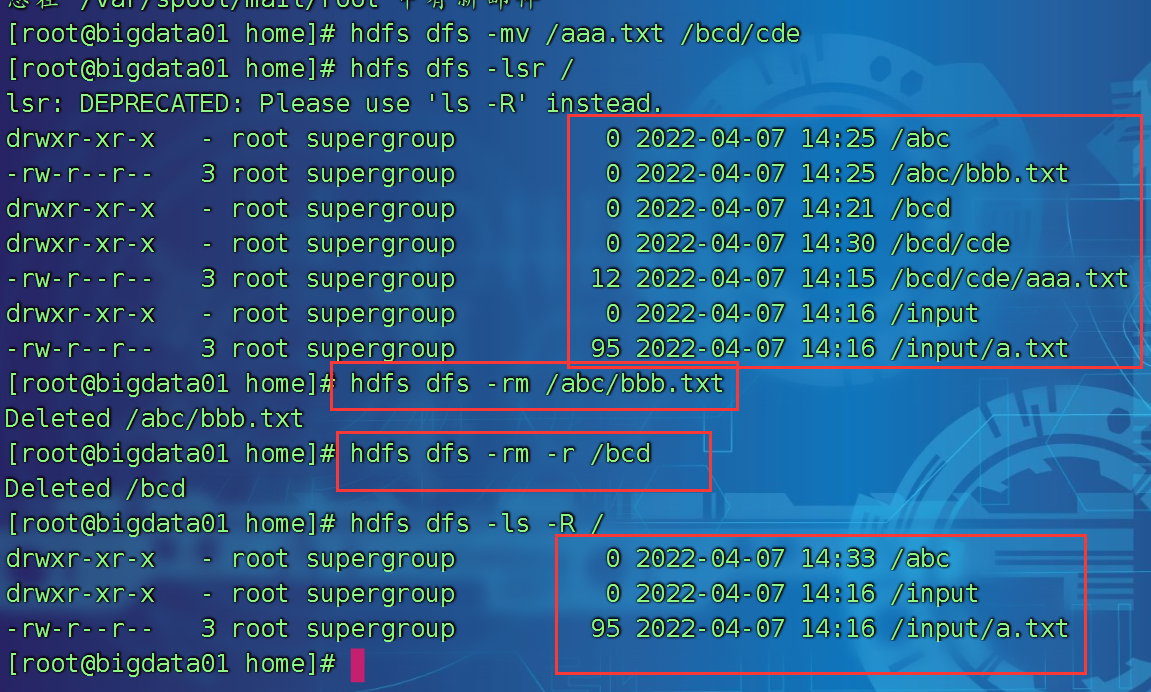
删除hdfs上文件或者文件夹
hdfs dfs -rm 文件及路径
hdfs dfs -rm /abc/bbb.txt
hdfs dfs -rm -r 后面跟上文件夹的名字
hdfs dfs -rm -r /bcd
删除的内容暂时进入了回收站
可以进行拷贝
hdfs dfs -cp hdfs上的文件 hdfs的一个文件夹下
hdfs dfs -cp /abc /input
查看hdfs上的文件
hdfs dfs -cat hdfs上的一个文件
hdfs dfs -cat /input/a.txt
进行文件权限的修改:
hdfs dfs -chmod 777 /input/a.txt
权限修改前
权限修改后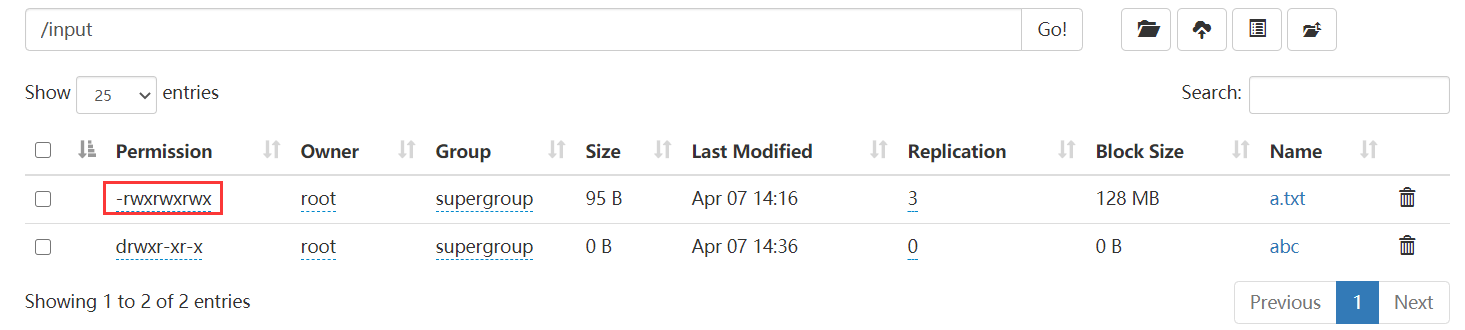
修改文件所属用户及用户组
hdfs dfs -chown hadoop:hadoop 文件名字
hdfs dfs -chown -R hadoop:hadoop 文件夹的名字
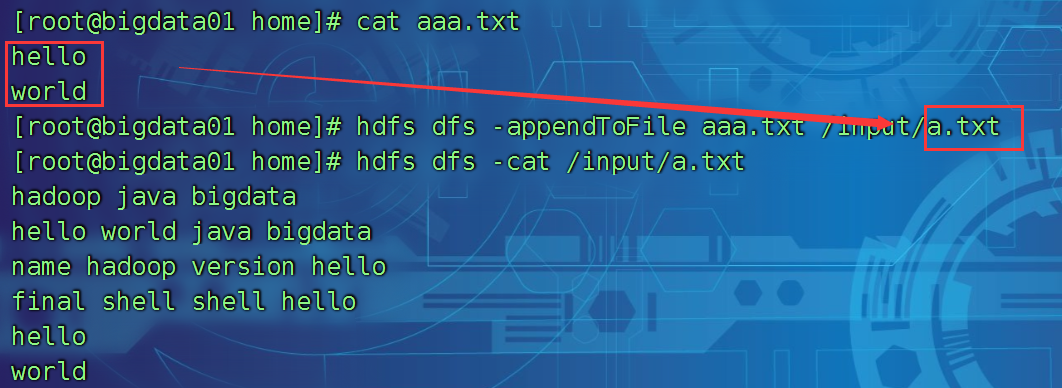
将一个或者多个文件追加到某个文件中
hdfs dfs -appendToFile 本地文件 hdfs上的文件
hdfs dfs -appendToFile aaa.txt /input/a.txt
三、HDFS的java操作
1、环境的配置
1) 解压一个压缩包
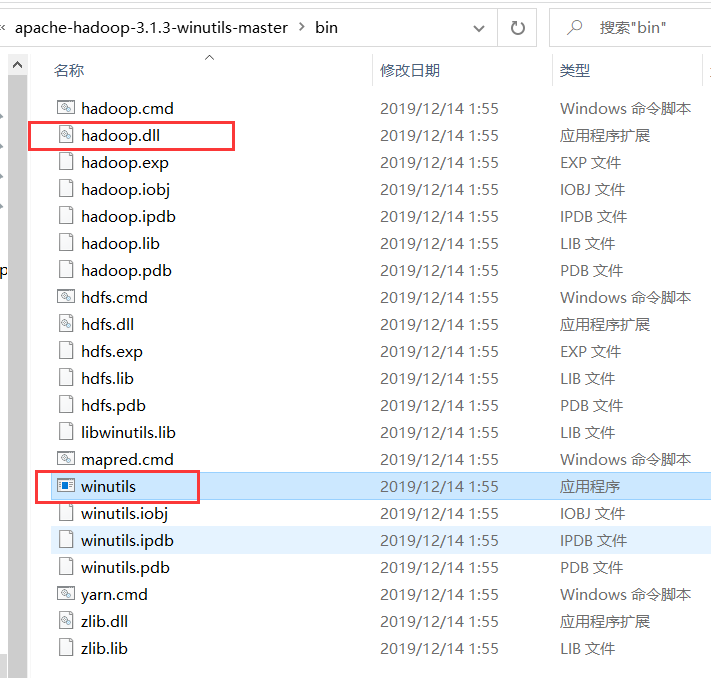
2) 解压我们的hadoop的安装包
将解压好的安装包,放置在非中文,非空格的路径下 D:\hadoop-3.3.1
3)配置hadoop的环境变量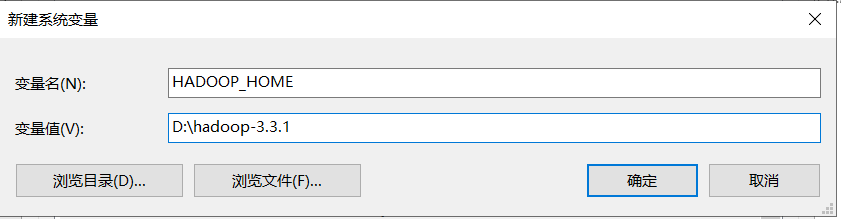
修改Path路径,增加如下内容:
%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
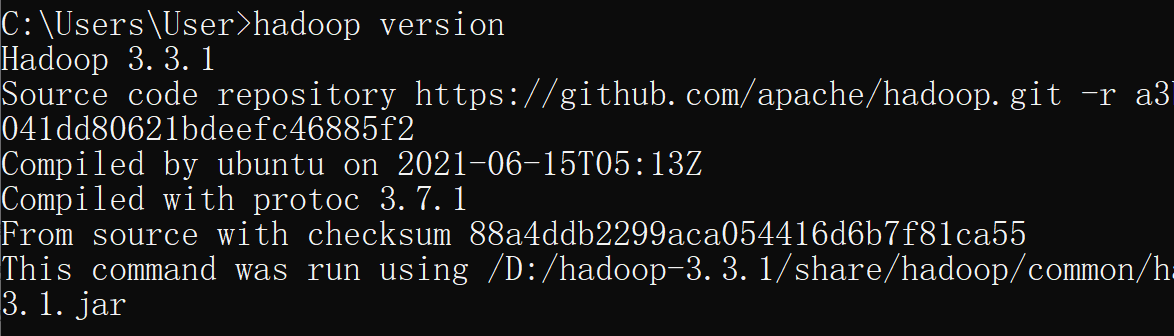
测试一下环境是否可以了:
hadoop version
4) 将我们之前解压的那两个文件拷贝到我的hadoop路径下的bin目录下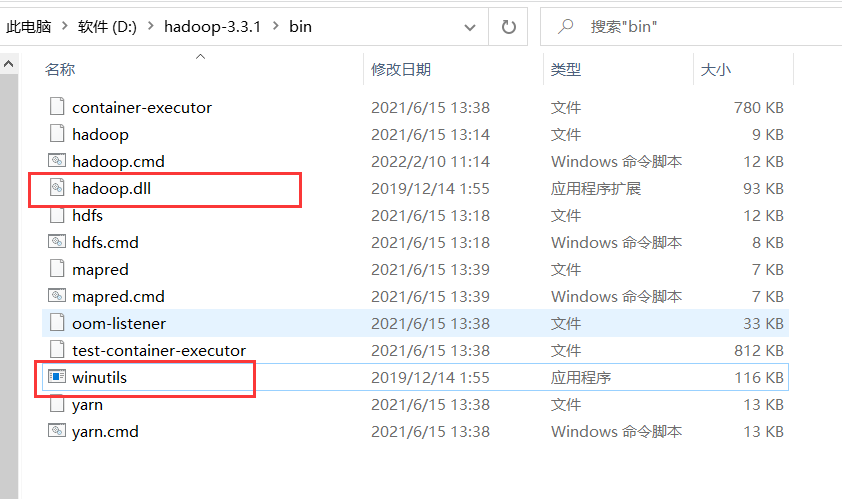
如果不这样做,将来写java代码会报错。
5) 修改hadoop-env.cmd 下的jdk路径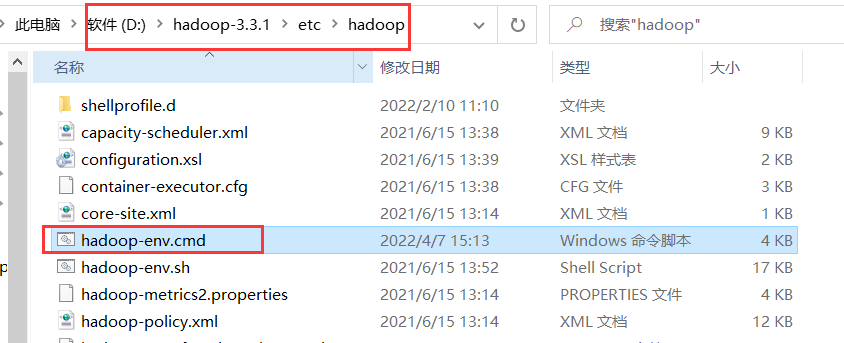
这个文件的大约25行左右
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_144
2、使用java代码操作hdfs
1) 创建maven项目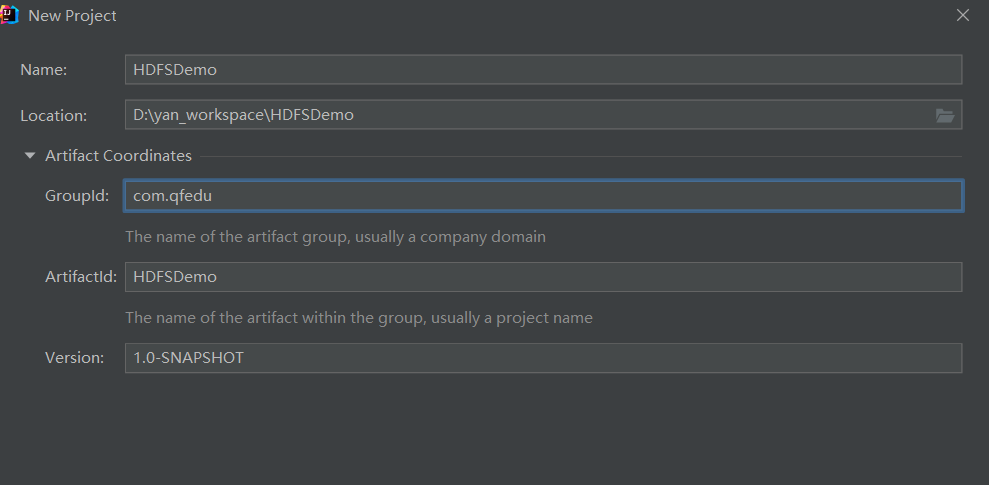
2)导入响应的jar包
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
如果遇到这种情况,点击一下这个链接
3) 使用单元测试Junit
需要导入Junit的jar包:
https://mvnrepository.com/
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
单元测试的方法类似于main方法,一个类只能有一个main方法,但是可以有多个单元测试方法
单元测试方法:
1、public void 开始
2、没有参数
3、方法上@Test进行标识
4)使用单元测试方法编写java代码
@Test
public void testCreate01() throws IOException {
//获取FileSystem对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.32.100:9820");
FileSystem fs = FileSystem.get(configuration);
System.out.println(fs);
}
5) 4种获取FileSystem对象的方式
package com.qfedu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/4/7 15:45
* @Version 1.0
*
* 单元测试 Junit 类似于我们的main方法
*/
public class DemoTestHDFS {
@Test
public void testCreate01() throws IOException {
// 获取FileSystem对象的第一种方式
//获取FileSystem对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.32.100:9820");
FileSystem fs = FileSystem.get(configuration);
System.out.println(fs);
}
@Test
public void testCreate02() throws IOException, URISyntaxException {
// 获取FileSystem对象的第二种方式
//获取FileSystem对象
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.32.100:9820"), new Configuration());
System.out.println(fs);
}
@Test
public void testCreate03() throws IOException, URISyntaxException {
// 获取FileSystem对象的第三种方式
//获取FileSystem对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.32.100:9820");
FileSystem fs = FileSystem.newInstance(configuration);
System.out.println(fs);
}
@Test
public void testCreate04() throws IOException, URISyntaxException {
// 获取FileSystem对象的第三种方式
//获取FileSystem对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.newInstance(new URI("hdfs://192.168.32.100:9820"),configuration);
System.out.println(fs);
}
}
6) 文件上传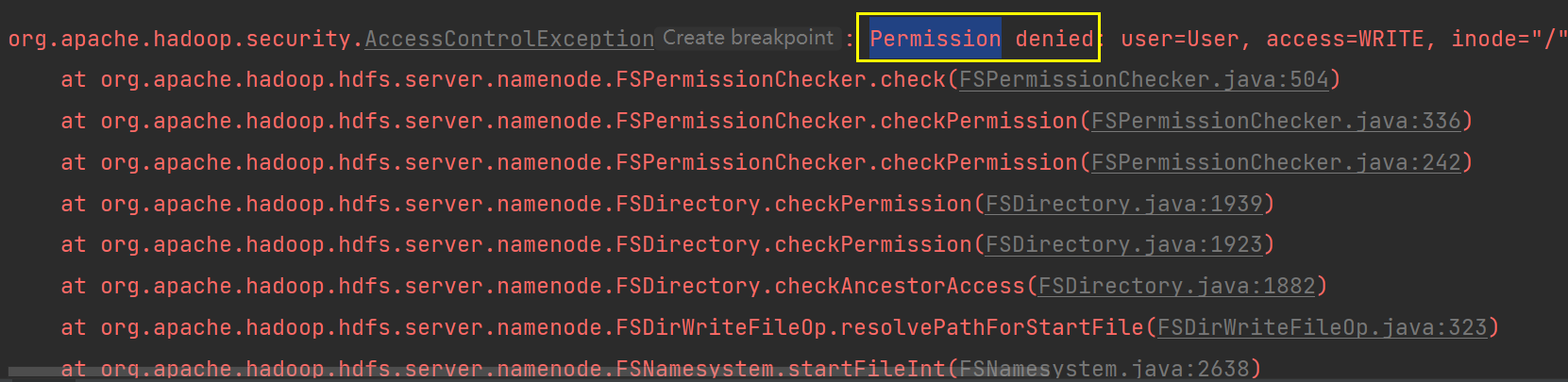
@Test
public void testUpload() throws IOException {
// 伪装一个root用户进行上传,就不会报权限问题了
System.setProperty("HADOOP_USER_NAME","root");
//获取文件系统对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.32.100:9820");
FileSystem fs = FileSystem.get(conf);
// 将本地的一个文件上传到hdfs上
Path localPath = new Path("C:\\Users\\User\\Desktop\\zhuo.txt");
// hdfs上的地址
Path hdfsPath = new Path("/");
fs.copyFromLocalFile(localPath,hdfsPath);
fs.close();
System.out.println("文件上传成功");
}

其他相关的hdfs操作:
package com.qfedu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/4/7 16:11
* @Version 1.0
*/
public class DemoTestHDFSAction {
FileSystem fs = null;
@Before //每一个单元测试方法执行前,必须先执行我 @Before
public void init() throws IOException {
// 伪装一个root用户进行上传,就不会报权限问题了
System.setProperty("HADOOP_USER_NAME","root");
//获取文件系统对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.32.100:9820");
fs = FileSystem.get(conf);
}
@After
public void destory() throws IOException {
fs.close();
}
@Test
public void testUpload() throws IOException {
// 将本地的一个文件上传到hdfs上
Path localPath = new Path("C:\\Users\\User\\Desktop\\zhuo.txt");
// hdfs上的地址
Path hdfsPath = new Path("/");
fs.copyFromLocalFile(localPath,hdfsPath);
System.out.println("文件上传成功");
}
// 文件下载
@Test
public void testDownload() throws IOException {
// hdfs上的地址
Path hdfsPath = new Path("/zhuo.txt");
// 将本地的一个文件上传到hdfs上
Path localPath = new Path("D:\\");
fs.copyToLocalFile(hdfsPath,localPath);
System.out.println("文件下载成功");
}
//创建文件夹
@Test
public void testMkdir() throws IOException {
fs.mkdirs(new Path("/2201大数据班"));
System.out.println("文件夹创建成功");
}
//删除文件夹
@Test
public void testDelete() throws IOException {
fs.delete(new Path("/2201大数据班"),true);
System.out.println("删除成功");
}
//对文件进行重命名
@Test
public void testRename() throws IOException {
fs.rename(new Path("/zhuo.txt"),new Path("/zhuomian.txt"));
System.out.println("重命名成功");
}
}
3、hdfs中的权限系统
默认情况下,我们看到的hdfs上的权限都是不起作用的,为了让其起作用,我们需要修改配置
hdfs-site.xml中
<!--启用hdfs上的权限系统,默认是false-->
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
然后分发到另外两台上面去:
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml bigdata02:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml bigdata03:/usr/local/hadoop/etc/hadoop
记得重启我们的hdfs
stop-dfs.sh
start-dfs.sh

若有收获,就点个赞吧
0 人点赞
