一、flume中的拦截器
不管是什么拦截器,本质都是一样的:
向每个Event的header中添加一个属性,时间戳拦截器就添加一个时间戳,host拦截器就添加一个host属性,如果是静态拦截器就添加一个自定义的KV键值对,如果想添加多个KV,多弄几个静态拦截器就可以了。
通过拦截器添加属性有什么用?
可以在sink中,直接通过k拿到vlaue值。
自定义拦截器:
1、创建一个项目,导入jar包
<dependencies><!-- https://mvnrepository.com/artifact/org.apache.flume/flume-ng-core --><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.48</version></dependency></dependencies>
2、编写一个类,实现Interceptor
package com.qfedu;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.util.List;/*** @Author laoyan* @Description TODO* @Date 2022/4/20 18:13* @Version 1.0*/public class MyInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {return null;}@Overridepublic List<Event> intercept(List<Event> list) {return null;}@Overridepublic void close() {}}
3、实现里面的核心方法
需求是:
处理数据样例:log='{"host":"www.baidu.com","user_id":"13755569427","items":[{"item_type":"eat","active_time":156234},{"item_type":"car","active_time":156233}]}'结果样例:[{"active_time":156234,"user_id":"13755569427","item_type":"eat","host":"www.baidu.com"},{"active_time":156233,"user_id":"13755569427","item_type":"car","host":"www.baidu.com"}]

编写代码:
发现我们event中的数据都是放在body中的,并且是一个byte数组。
package com.qfedu;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/4/20 18:13
* @Version 1.0
*/
public class MyInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] bytes = event.getBody();
String message = new String(bytes, Charset.forName("UTF-8"));
// message 此时是一个json 字符串
JSONObject jsonObject = JSON.parseObject(message);
String host = jsonObject.getString("host");
String user_id = jsonObject.getString("user_id");
JSONArray array = jsonObject.getJSONArray("items");
ArrayList<Map<String, String>> list = new ArrayList<Map<String, String>>();
for (Object obj:array) {
JSONObject itemObj = JSON.parseObject(obj.toString());
HashMap<String, String> map = new HashMap<>();
map.put("host",host);
map.put("user_id",user_id);
String item_type = itemObj.getString("item_type");
String active_time = itemObj.getString("active_time");
map.put("active_time",active_time);
map.put("item_type",item_type);
list.add(map);
}
// list集合集结完毕,如何将list变为json串
String json = JSON.toJSONString(list);
//[{"active_time":156234,"user_id":"13755569427","item_type":"eat","host":"www.baidu.com"}]
event.setBody(json.getBytes(StandardCharsets.UTF_8));
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
ArrayList<Event> events = new ArrayList<>();
for (Event event:list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
// 在类中编写了一个类,内部类
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new MyInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
通过maven,进行打包上传,因为需要依赖 fastjson.jar 所以,需要将打包的 MyInter.jar 和 json的jar包一起放在 flume 的lib下。
编写flume的脚本:mytest.conf
a1.sources = s1
a1.channels = c1
a1.sinks = r1
a1.sources.s1.type = TAILDIR
#以空格分隔的文件组列表。每个文件组表示要跟踪的一组文件
a1.sources.s1.filegroups = f1
#文件组的绝对路径
a1.sources.s1.filegroups.f1=/root/flumedata/input/a.log
#使用自定义拦截器
a1.sources.s1.interceptors = i1
a1.sources.s1.interceptors.i1.type = com.qfedu.MyInterceptor$MyBuilder
a1.channels.c1.type = file
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.r1.type = hdfs
a1.sinks.r1.hdfs.path = hdfs://bigdata01:9820/flume/0421
a1.sinks.r1.hdfs.fileSuffix= .log
a1.sinks.r1.hdfs.fileType=DataStream
a1.sinks.r1.hdfs.writeFormat=Text
a1.sources.s1.channels = c1
a1.sinks.r1.channel = c1
以上的脚本需要注意:
a1.sources.s1.interceptors = i1
a1.sources.s1.interceptors.i1.type = com.qfedu.MyInterceptor$MyBuilder
拦截器的名字的类型,必须是拦截器的类的全路径 + 内部类的名字
测试:启动agent
flume-ng agent -c ../conf/ -f ./mytest.conf -n a1 -Dflume.root.logger=INFO,console
接着,向 a.log中不断的添加json格式的数据。
为了方便测试,我们编写了一个脚本mytest.sh
#!/bin/bash
log='{
"host":"www.baidu.com",
"user_id":"13755569427",
"items":[
{
"item_type":"eat",
"active_time":156234
},
{
"item_type":"car",
"active_time":156233
}
]
}'
echo $log >> /root/flumedata/input/a.log
接着给脚本赋权限: chmod 777 mytest.sh
达到不断的向 a.logt 发送 json 数据的目的,最终hdfs上的文件的数据格式,是我们通过拦截器修改过的格式就说明对了。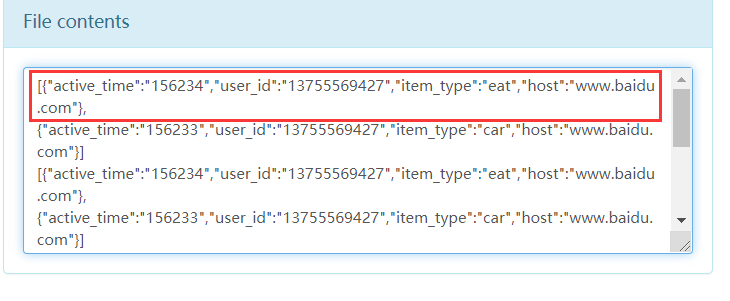
二、选择器
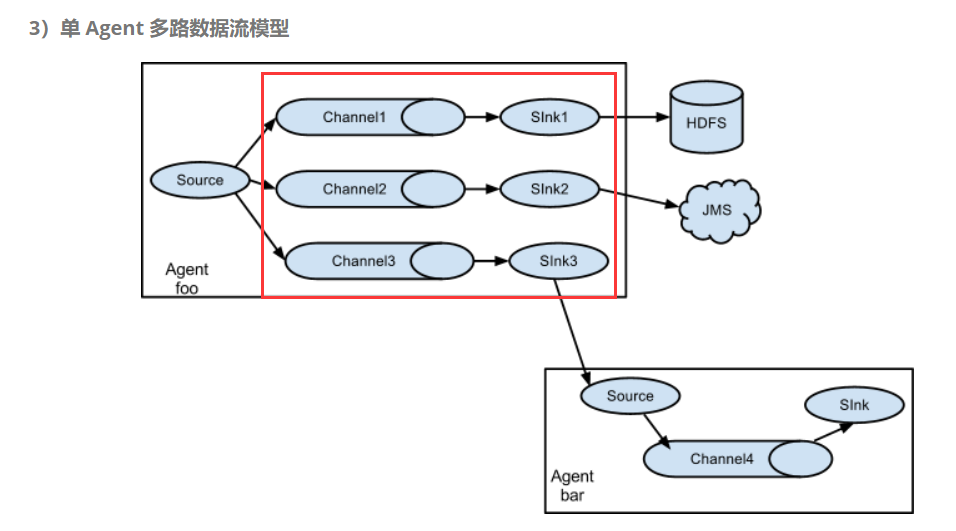
Flume中的Channel选择器作用于source阶段 ,是决定Source接受的特定Event写入到哪个Channel的组件,他们告诉Channel处理器,然后由其将Event写入到Channel。
lume分类两种选择器,如果Source配置中没有指定选择器,那么会自动使用复制Channel选择器.
- replicating:该选择器复制每个事件到通过Source的Channels参数指定的所有Channel中。
- multiplexing:是一种专门用于动态路由事件的Channel选择器,通过选择事件应该写入到哪个Channel,基于一个特定的事件头的值进行路由.
案例一:复制选择器

a1.sources = r1
a1.channels = c1 c2
a1.sinks = s1 s2
a1.sources.r1.type=syslogtcp
a1.sources.r1.host = bigdata01
a1.sources.r1.port = 6666
a1.sources.r1.selector.type=replicating
a1.channels.c1.type=memory
a1.channels.c2.type=memory
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.path=hdfs://bigdata01:9820/flume/%Y-%m-%d/rep
a1.sinks.s1.hdfs.filePrefix=s1sink
a1.sinks.s1.hdfs.fileSuffix=.log
a1.sinks.s1.hdfs.fileType=DataStream
a1.sinks.s1.hdfs.writeFormat=Text
a1.sinks.s1.hdfs.useLocalTimeStamp=true
a1.sinks.s2.type=hdfs
a1.sinks.s2.hdfs.path=hdfs://bigdata01:9820/flume/%Y-%m-%d/rep
a1.sinks.s2.hdfs.filePrefix=s2sink
a1.sinks.s2.hdfs.fileSuffix=.log
a1.sinks.s2.hdfs.fileType=DataStream
a1.sinks.s2.hdfs.writeFormat=Text
a1.sinks.s2.hdfs.useLocalTimeStamp=true
a1.sources.r1.channels=c1 c2
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
运行脚本:
flume-ng agent -c ../conf -f ./rep.conf -n a1 -Dflume.root.logger=INFO,console
安装nc:
yum install -y nc
发送消息给bigdata01 的6666端口:
echo "hello world" | nc bigdata01 6666
案例二、多路选择器
a1.sources = r1
a1.channels = c1 c2
a1.sinks = s1 s2
a1.sources.r1.type=http
a1.sources.r1.bind = bigdata01
a1.sources.r1.port = 7777
a1.sources.r1.selector.type=multiplexing
# header 跟 mapping 结合在一起,用于发送消息时,指定发送的方向
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.USER = c1
a1.sources.r1.selector.mapping.ORDER = c2
# 发送的消息找不到具体的channel,就走默认的c1
a1.sources.r1.selector.default = c1
a1.channels.c1.type=memory
a1.channels.c2.type=memory
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.path=hdfs://bigdata01:9820/flume/%Y-%m-%d/mul
a1.sinks.s1.hdfs.filePrefix=s1sink
a1.sinks.s1.hdfs.fileSuffix=.log
a1.sinks.s1.hdfs.fileType=DataStream
a1.sinks.s1.hdfs.writeFormat=Text
a1.sinks.s1.hdfs.useLocalTimeStamp=true
a1.sinks.s2.type=hdfs
a1.sinks.s2.hdfs.path=hdfs://bigdata01:9820/flume/%Y-%m-%d/mul
a1.sinks.s2.hdfs.filePrefix=s2sink
a1.sinks.s2.hdfs.fileSuffix=.log
a1.sinks.s2.hdfs.fileType=DataStream
a1.sinks.s2.hdfs.writeFormat=Text
a1.sinks.s2.hdfs.useLocalTimeStamp=true
a1.sources.r1.channels=c1 c2
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
启动agent:
flume-ng agent -c ../conf -f ./mul.conf -n a1 -Dflume.root.logger=INFO,console
发送消息给source源(http):
curl -X POST -d '[{"headers":{"state":"USER"},"body":"this my multiplex to c1"}]' http://bigdata01:7777
curl -X POST -d '[{"headers":{"state":"ORDER"},"body":"this my multiplex to c2"}]' http://bigdata01:7777
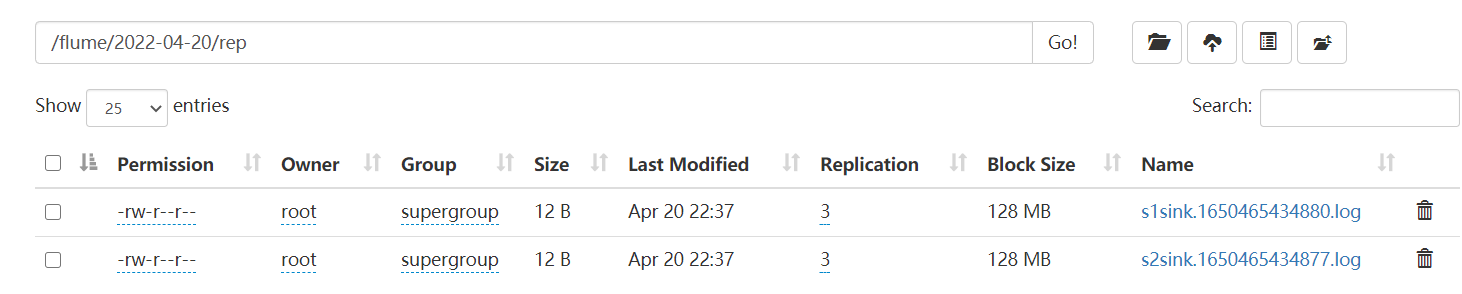
查看我们的hdfs,发现数据确实不一样,说明两个通道走的消息是不同的,达到了效果。
在linux上可以使用curl 访问一个页面,返回html,如果正常返回,说明服务启动没有问题。
三、自动容灾以及负载均衡
1、自动容灾
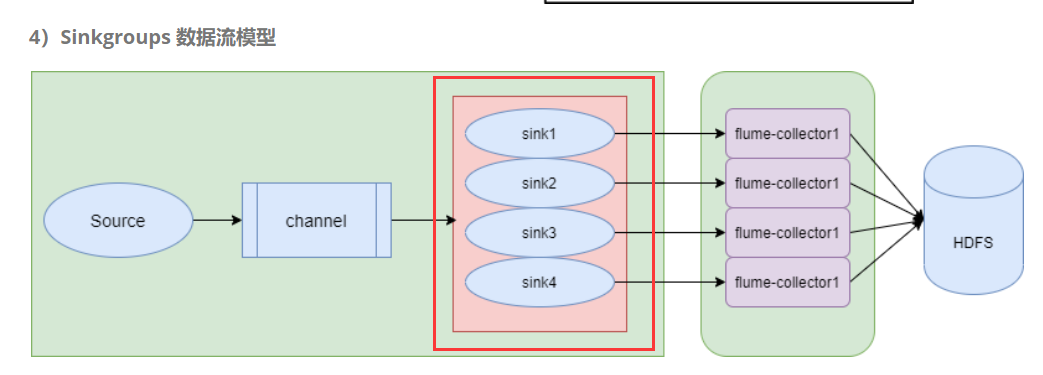
自动容灾:
案例: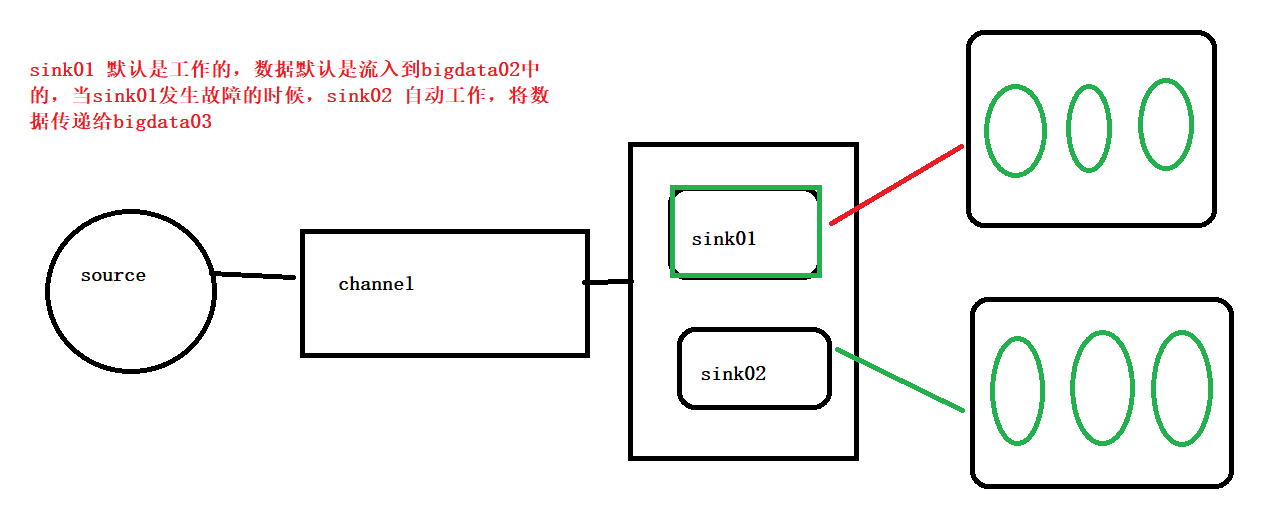
编写failover.conf
在bigdata01上,进行编写:
#list names
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
# source
a1.sources.r1.type = syslogtcp
a1.sources.r1.host = bigdata01
a1.sources.r1.port = 10086
# channel
a1.channels.c1.type = memory
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = bigdata02
a1.sinks.k1.port = 10087
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = bigdata03
a1.sinks.k2.port = 10088
#设置sink组
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
# 此处是设置的权重,权重越多,就工作
a1.sinkgroups.g1.processor.priority.k1 = 10
a1.sinkgroups.g1.processor.priority.k2 = 5
a1.sinkgroups.g1.processor.maxpenalty = 10000
接着开始启动bigdata02和 bigdata03上的flume,但是没有安装:
快速安装一下:
xsync.sh /usr/local/flume
xsync.sh /etc/profile
刷新一下环境变量:
xcall.sh source /etc/profile
开始在bigdata02上,配置 failover2.conf
#list names
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# source
a1.sources.r1.type = avro
a1.sources.r1.bind = bigdata02
a1.sources.r1.port = 10087
# channel
a1.channels.c1.type = memory
# sink
a1.sinks.k1.type = logger
启动:
flume-ng agent -c ../conf -f ./failover2.conf -n a1 -Dflume.root.logger=INFO,console
配置bigdata03上的failover3.conf
#list names
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# source
a1.sources.r1.type = avro
a1.sources.r1.bind = bigdata03
a1.sources.r1.port = 10088
# channel
a1.channels.c1.type = memory
# sink
a1.sinks.k1.type = logger
启动agent:
flume-ng agent -c ../conf -f ./failover3.conf -n a1 -Dflume.root.logger=INFO,console
接着启动bigdata01上的agent:
flume-ng agent -c ../conf -f ./failover.conf -n a1 -Dflume.root.logger=INFO,console
接着向bigdata01中的systemlog 发送消息
echo "hello" | nc bigdata01 10086
总结:
我们的bigdata01发送的消息一直给bigdata02 上面,因为它的权重比较大,当我们把bigdata02上的fluem停止后,再次发送的消息就给了bigdata03。 如果我们把bigdata02上的flume再次启动,此时发送的消息又会传给 bigdata02 了,实现了自动容灾功能。
2、负载均衡
负载均衡Sink 选择器提供了在多个sink上进行负载均衡流量的功能。 它维护一个活动sink列表的索引来实现负载的分配。 默认支持了轮询(round_robin)和随机(random)两种选择机制分配负载。 默认是轮询,可以通过配置来更改。
在flume中,多个sink共同工作,处理不同的数据,如果是轮训,第一次是sink01,下一次就是sink02。
演示:
有一个source,有一个channel,由两个sink,两个sink交替工作。
bigdata01 中,编写 balance.conf
#list names
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
# source
a1.sources.r1.type = syslogtcp
a1.sources.r1.host = bigdata01
a1.sources.r1.port = 10086
# channel
a1.channels.c1.type = memory
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = bigdata02
a1.sinks.k1.port = 10087
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = bigdata03
a1.sinks.k2.port = 10088
#设置sink组
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
processor.selector =random
bigdata02,bigdata03上的配置文件跟之前一样,启动即可。
四、数据仓库的概念
数据仓库,英文是Data Warehouse,可简写为 DW ,数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。<br />数据仓库是用于提供决策支持。<br /> **数据仓库**是==面向主题的==、==集成的==、==非易失的==和==时变的==数据集合,用以支持管理决策。<br />** ETL**(**抽取Extra, 转化Transfer, 装载Load**)的过程,一般用作数据清洗,脱敏。<br /> 数据仓库是用**用空间换时间(编写数据仓库项目的核心思想)。**<br />** 比如: user , order , addr 编写一个SQL语句将三个表关联起来查询。**<br />** 数据仓库,把三个表的数据,干到一个表里面去,再查询。**<br />**分析的指标:分析的问题(不同年龄段的点外卖的数量哪个更高,哪个更低)**<br />**数据仓库中最重要的内容:分层**<br />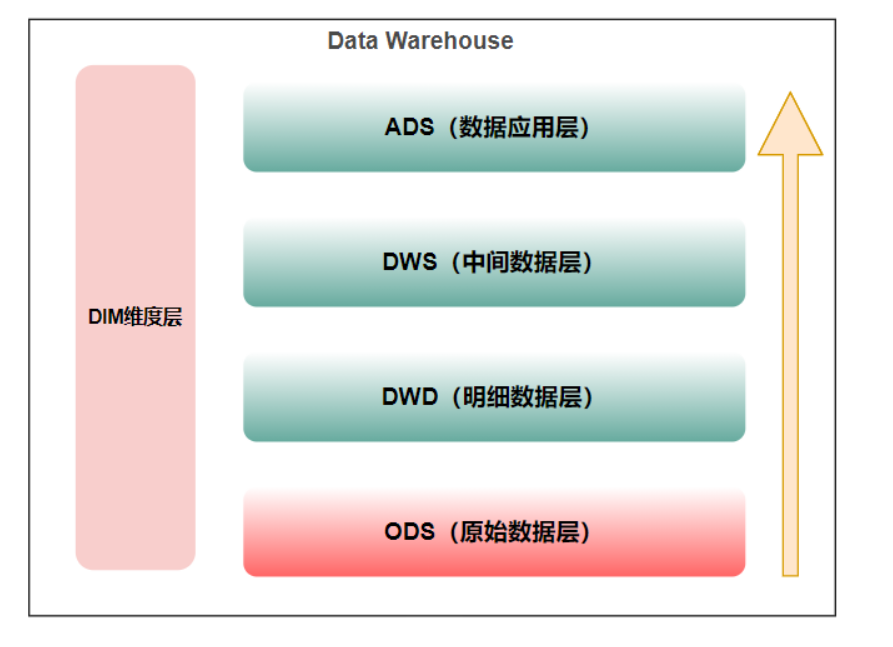<br />数据源层:ODS(Operational Data Store)
ODS 层,是最接近数据源中数据的一层,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的 DWD 层来做。
数据仓库层:DW(Data Warehouse)
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。
DW 层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和 DWS(Data WareHouse Servce) 层。
- 数据明细层:DWD(Data Warehouse Detail)
该层一般保持和 ODS 层一样的数据粒度,并且提供一定的数据质量保证。DWD 层要做的就是将数据清理、整合、规范化、脏数据、垃圾数据、规范不一致的、状态定义不一致的、命名不规范的数据都会被处理。
同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性 。 - 粒度:一个人姓名,身份证号,多个手机号,多个银行卡号。
- 张三 410xxxxxxxx [] [] 粒度
- 以手机号拆分
- 张三 410xxxxx 18133333333
- 张三 410xxxxx 18133333333
- 数据中间层:DWM(Data WareHouse Middle)
该层会在 DWD 层的数据基础上,数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。
直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
在实际计算中,如果直接从 DWD 或者 ODS 计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在 DWM 层先计算出多个小的中间表,然后再拼接成一张 DWS 的宽表。由于宽和窄的界限不易界定,也可以去掉 DWM 这一层,只留 DWS 层,将所有的数据再放在 DWS 亦可。
数据服务层:DWS(Data WareHouse Servce)
DWS 层为公共汇总层,会进行轻度汇总,粒度比明细数据稍粗,基于 DWD 层上的基础数据,整合汇总成分析某一个主题域的服务数据,一般是宽表。DWS 层应覆盖 80% 的应用场景。又称数据集市或宽表。
按照业务划分,如主题域流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP 分析,数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
数据应用层(ADS,Application Data Service)
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、 PostgreSql、Redis 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里。
维表层:DIM(Dimension)
如果维表过多,也可针对维表设计单独一层,维表层主要包含两部分数据:
- 高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
- 低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
数据库(OLTP)是为捕获数据而设计,数据仓库(OLAP)是为分析数据而设计。

若有收获,就点个赞吧
0 人点赞
