一、多表查询之内外连接
两个表以上进行关联查询,称之为多表查询。
复习:
产生笛卡尔集:
select from emp,dept ; // emp 14 dept 4 == 56条的记录。笛卡尔集毫无意义。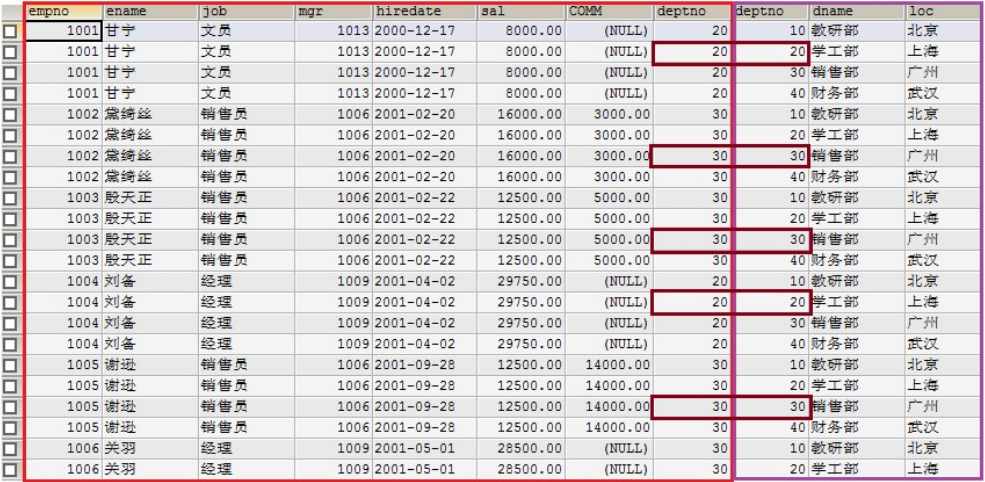
// 两个表关联查询,通过条件过滤掉无意义的数据,就是我们想要的数据了。
// SQL 查询员工以及该员工所在部门的信息
select from emp,dept where emp.deptno = dept.deptno;
以上这种写法是mysql 的方言,其他数据库听不懂(无法执行);
标准的写法:连接查询
1、内连接 a inner join b on a.字段= b.字段
select from emp e inner join dept d on e.deptno = d.deptno;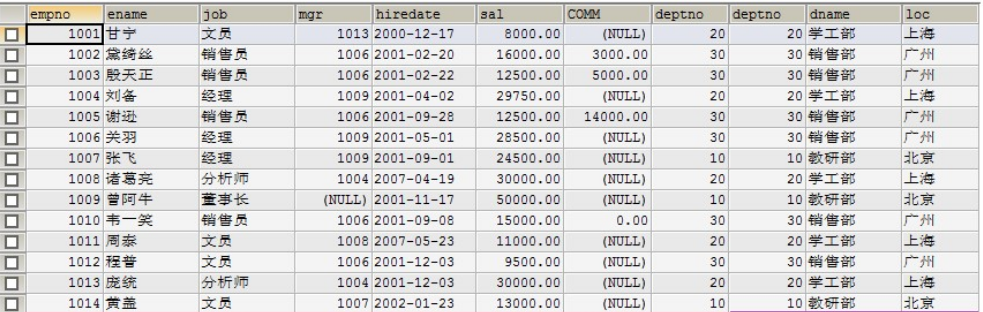
2、外连接
1) 左外连接
select from emp e left join dept d on e.deptno = d.deptno;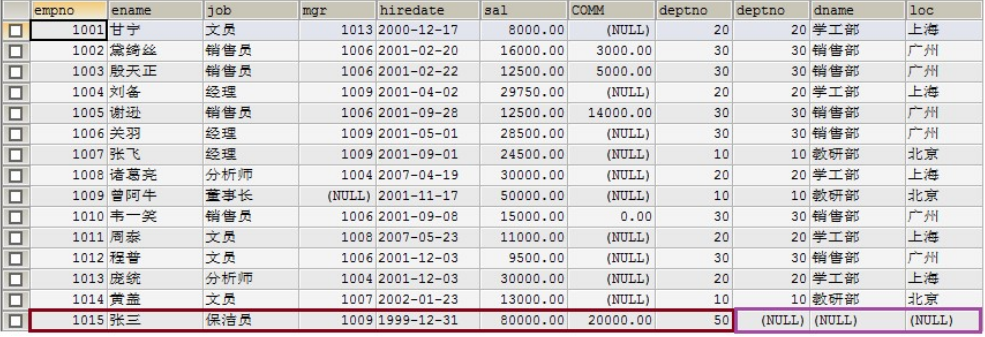
2)右外连接 所有的右外连接都可以写成左外连接
select * from dept d right join emp e on e.deptno = d.deptno;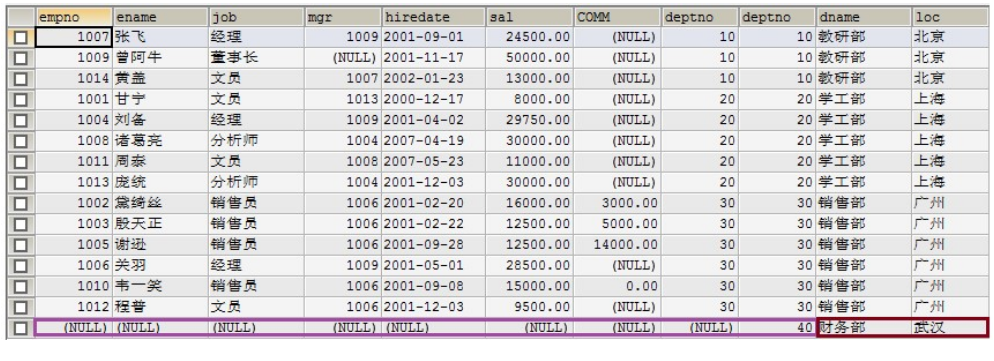
二、多表查询之子查询(重点)
有的时候,当一个查询语句A所需要的数据,不是直观在表中体现,而是由另外一个查询语句B查询出来的结果,那么查询语句A就是主查询语句,查询语句B就是子查询语句。这种查询我们称之为高级关联查询,也叫做子查询。<br />**上SQL:**
1. 工资高于JONES的员工分析:首先我们要知道JONES的员工工资是多少select sal from emp where ename = 'JONES';接着根据这个工资查询高于这个工资的员工信息select * from emp where sal > 2975;接着套在一起:select * from emp where sal > (select sal from emp where ename = 'JONES');2、查询与SCOTT同一个部门的员工思路:先查找SCOTT的部门select deptno from emp where ename='SCOTT';select * from emp where detpno = (SCOTT的部门编号)答案:select * from emp where deptno = (select deptno from emp where ename='SCOTT');3、工资高于30号部门所有人的员工信息select * from emp where sal > (select max(sal) from emp where deptno = 30);
插曲:如何将Navicat 的字体变大: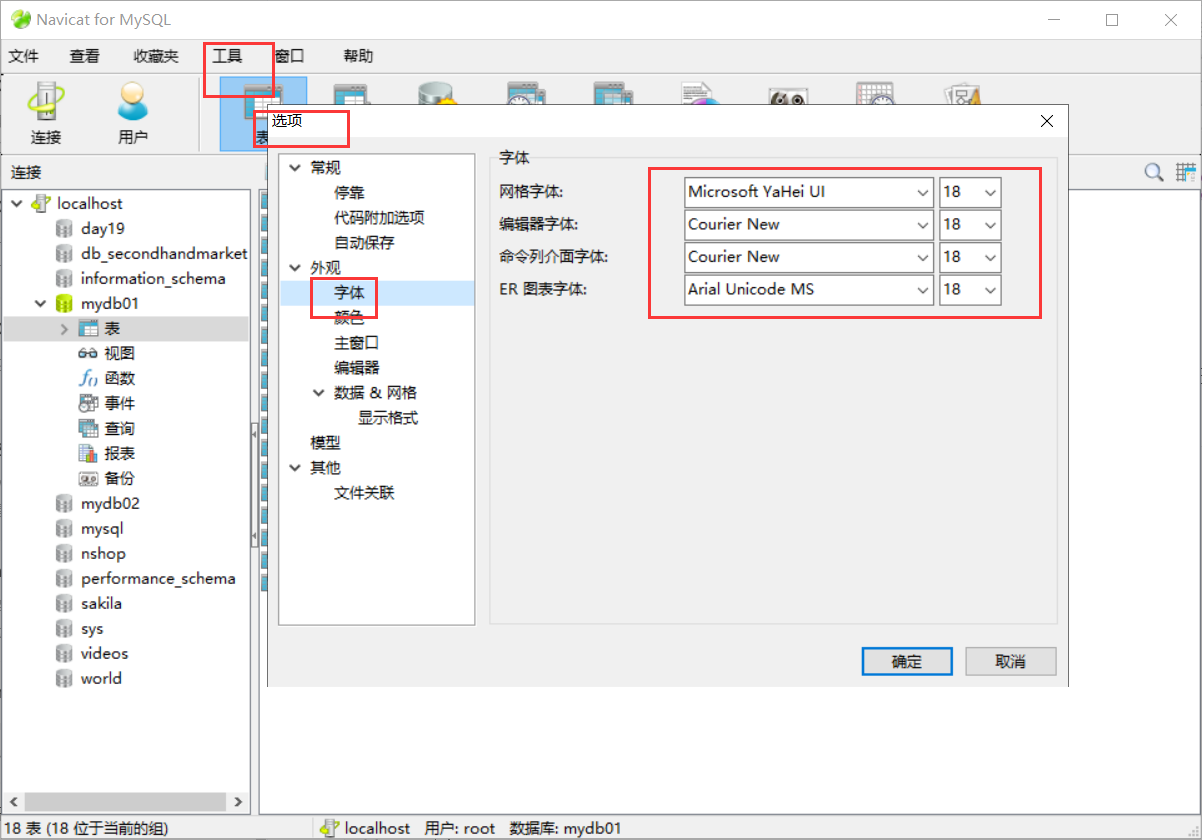
认真学习子查询:
子查询语句的返回数据形式:
- 返回单行单列 => 可以被视为一个数值来使用- 返回多行单列 => 可以被视为一个集合来使用- 返回单行多列 => 可以被视为一个虚拟表使用- 返回多行多列 => 可以被视为一个虚拟表使用
子查询语句的位置可以在以下几个子句中:
- 在where子句中: 子查询的结果可用作条件筛选时使用的值。- 在from子句中: 子查询的结果可充当一张表或视图,需要使用表别名。- 在having子句中: 子查询的结果可用作分组查询再次条件过滤时使用的值- 在select子句中: 子查询的结果可充当一个字段。仅限子查询返回单行单列的情况。
1、出现在where子句中,以上案例都是出现在where 子句中
1、查询工资大于10号部门的平均工资的非10号部门的员工信息10号部门平均工资select avg(sal) from emp where deptno = 10;select * from emp where sal > (select avg(sal) from emp where deptno = 10) and deptno != 10;2、查询与7369同部门的同事信息select * from emp where deptno = (select deptno from emp where empno = 7369) and empno != 7369;
2、出现在from子句中:
查询员工的姓名,工资,及其部门的平均工资select ename,sal from emp;员工所在部门的平均工资怎么算?select avg(sal) from emp group by deptno;答案一:查询出来了每一个部门的平均工资以及部门编号,当做一个新表,命名为 b 表,将员工表和 b 表进行关联查询。select ename,sal,emp.deptno,b.pjSal from emp ,(select avg(sal) pjSal,deptno from emp group by deptno) as b where emp.deptno= b.deptno;以上为什么药在deptno 前面加表名呢?原因是emp 表和 b 表里面都有 deptno 这样一个字段,如果不加表名,SQL语句不知道你想要哪个表的deptno,所以就报错了。
3、出现在having 后面:
查询平均工资大于30号部门的平均工资的部门号,和平均工资1、查询 30号部门的平均工资select avg(sal) from emp where deptno = 302、查询所有部门的平均工资以及部门号select avg(sal),deptno from emp group by deptno;3、组合select avg(sal),deptno from emp group by deptno having avg(sal) > (select avg(sal) from emp where deptno = 30);
4、出现在select 子句中:
查询每个员工的信息及其部门的平均工资,工资之和,部门人数select ename,deptno,sal,(select avg(sal) from emp e1 where e1.deptno=e2.deptno ) as 部门的平均工资,(select sum(sal) from emp e1 where e1.deptno=e2.deptno) as 部门的工资总和,(select count(1) from emp e1 where e1.deptno=e2.deptno) as 部门人数from emp e2;
三. regexp
正则表达式,也可以在SQL中使用。
| 模式 | 描述 |
|---|---|
| ^ 开始 $ 结尾 |
匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性, 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| . | 匹配除 “\n” 之外的任何单个字符。 |
| […] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^…] | 负值字符集合。匹配未包含的任意字符。例如, ‘abc’ 可以匹配 “plain” 中的’p’。 |
| \d | [0-9],匹配所有的数字。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,’z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| * | 匹配前面的子表达式零次或多次。例如,zo 能匹配 “z” 以及 “zoo”。 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| {n} | 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
创造数据:
CREATE TABLE `stu` (
`sid` char(6) DEFAULT NULL,
`sname` varchar(50) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`gender` varchar(50) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of stu
-- ----------------------------
INSERT INTO `stu` VALUES ('S_1001', 'liuYi', '35', 'male');
INSERT INTO `stu` VALUES ('S_1002', 'chenEr', '15', 'female');
INSERT INTO `stu` VALUES ('S_1003', 'zhangSan', '95', 'male');
INSERT INTO `stu` VALUES ('S_1004', 'liSi', '65', 'female');
INSERT INTO `stu` VALUES ('S_1005', 'wangWu', '55', 'male');
INSERT INTO `stu` VALUES ('S_1006', 'zhaoLiu', '75', 'female');
INSERT INTO `stu` VALUES ('S_1007', 'sunQi', '25', 'male');
INSERT INTO `stu` VALUES ('S_1008', 'zhouBa', '45', 'female');
INSERT INTO `stu` VALUES ('S_1009', 'wuJiu', '85', 'male');
INSERT INTO `stu` VALUES ('S_1010', 'zhengShi', '5', 'female');
INSERT INTO `stu` VALUES ('S_1011', 'xxx', null, null);
1、查询stu 表中以l开头或者以i结尾的数据
select * from stu where sname regexp '^l|i$';
2、SELECT 'hello' REGEXP '^he';
SELECT 'hello' REGEXP '^hh';
3、查找name字段中包含'mar'字符串的所有数据
select * from stu where sname like '%a%';
select * from stu where sname regexp 'a';
4、查找name字段中以元音字符开头或以'ok'字符串结尾的所有数据
select * from stu where sname regexp '^[aeiou]|ok$';
四、合并结果集(union / union all)
原始数据,建议同学们自己建表,自己插入数据,锻炼一下图形化界面的用法:
DROP TABLE IF EXISTS `a`;
CREATE TABLE `a` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of a
-- ----------------------------
INSERT INTO `a` VALUES ('1', 'aaa');
INSERT INTO `a` VALUES ('2', 'bbb');
INSERT INTO `a` VALUES ('3', 'ccc');
INSERT INTO `a` VALUES ('4', 'ddd');
-- ----------------------------
-- Table structure for `b`
-- ----------------------------
DROP TABLE IF EXISTS `b`;
CREATE TABLE `b` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sname` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of b
-- ----------------------------
INSERT INTO `b` VALUES ('4', 'ddd');
INSERT INTO `b` VALUES ('5', 'eee');
INSERT INTO `b` VALUES ('6', 'fff');


什么情况下可以使用union/union all?
将多个查询结果进行合并,并且多个查询结果中,列数要相同,每一列的数据类型要一致,字段名字可以不一样,这样的结果集可以合并。
五、MySQL函数
1、功能型函数
1)IFNULL 当前面一个值如果为null时,可以使用后面的默认值。
select ifnull(null,0); // 0
select ifnull(10,20); // 10
select ifnull(comm,0) from emp; // 奖金如果为null, 就给定默认值0
2、IF ,类似于 java三目运算
select if(10 > 20 , 10 ,20) ; 当前面的表达式成立,就返回10 ,不成立,返回 20
select if(10 < 20 , 10 ,20) ;
select if(chinese > math,chinese,math) from 表名;
3、case 类似于我们的java中的分支结构。通过模拟if的实现和switch 的实现。
生成一些数据:
CREATE TABLE `sc` (
`sname` varchar(20) DEFAULT NULL,
`subject` varchar(20) DEFAULT NULL,
`score` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of sc
-- ----------------------------
INSERT INTO `sc` VALUES ('张小三', '语文', '78');
INSERT INTO `sc` VALUES ('张小三', '数学', '77');
INSERT INTO `sc` VALUES ('张小三', '英语', '90');
INSERT INTO `sc` VALUES ('张小三', '历史', '89');
INSERT INTO `sc` VALUES ('张小三', '体育', '80');
INSERT INTO `sc` VALUES ('李小四', '数学', '90');
INSERT INTO `sc` VALUES ('李小四', '英语', '80');
INSERT INTO `sc` VALUES ('李小四', '体育', '88');
INSERT INTO `sc` VALUES ('李小四', '政治', '88');
INSERT INTO `sc` VALUES ('李小四', '历史', '78');
INSERT INTO `sc` VALUES ('王小五', '语文', '90');
INSERT INTO `sc` VALUES ('王小五', '英语', '80');
INSERT INTO `sc` VALUES ('王小五', '政治', '89');
INSERT INTO `sc` VALUES ('王小五', '体育', '90');
想查询学生的成绩,如果成绩大于等于60就显示及格,小于60不及格,如果大于60小于80显示良,大于等于80就实现优,否则就显示成绩无效。
比如使用类似于java中的if操作
select sname,subject,score,
case
when score < 0 or score >100 then '成绩无效'
when score <60 then '不及格'
when score < 80 then '良'
else '优'
end as 'level'
from sc;
使用类似于java中的switch 的语法:
查询学科成绩表,如果遇到汉字的学科,翻译为英语的学科。
select subject,
case subject
when '语文' then 'chinese'
when '英语' then 'english'
when '数学' then 'math'
when '历史' then 'history'
when '体育' then 'sports'
else subject
end as '翻译'
from sc;
4、行转列
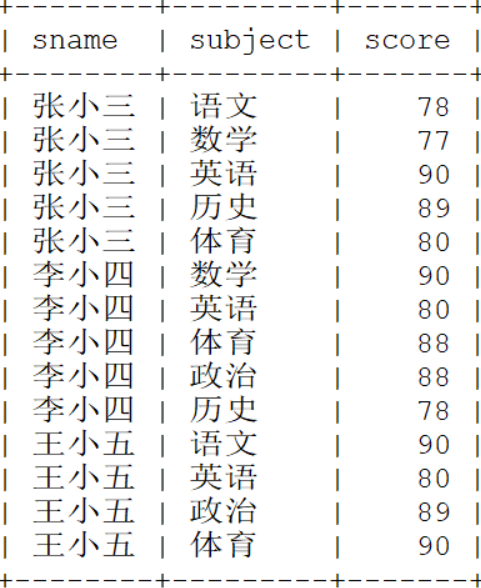
通过SQL语句,将数据转换为如下的方式: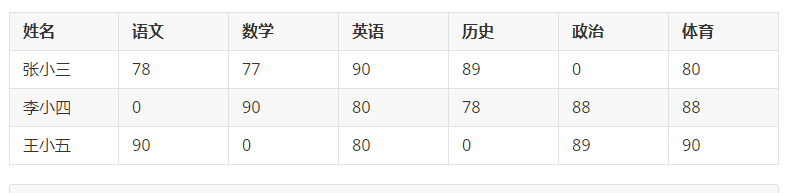
两种实现的版本:
第一个if版本:
select sname as 姓名,
if(subject='语文',score,0) as '语文',
if(subject='数学',score,0) as '数学',
if(subject='英语',score,0) as '英语',
if(subject='历史',score,0) as '历史',
if(subject='政治',score,0) as '政治',
if(subject='体育',score,0) as '体育'
from sc
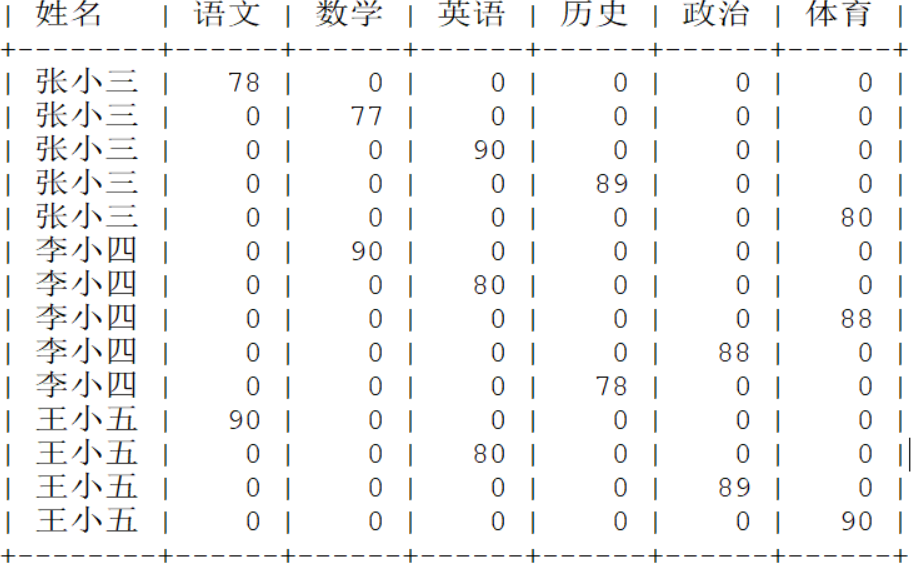
发现不对,需要分组查询:
select sname as 姓名,
if(subject='语文',score,0) as '语文',
if(subject='数学',score,0) as '数学',
if(subject='英语',score,0) as '英语',
if(subject='历史',score,0) as '历史',
if(subject='政治',score,0) as '政治',
if(subject='体育',score,0) as '体育'
from sc group by sname;
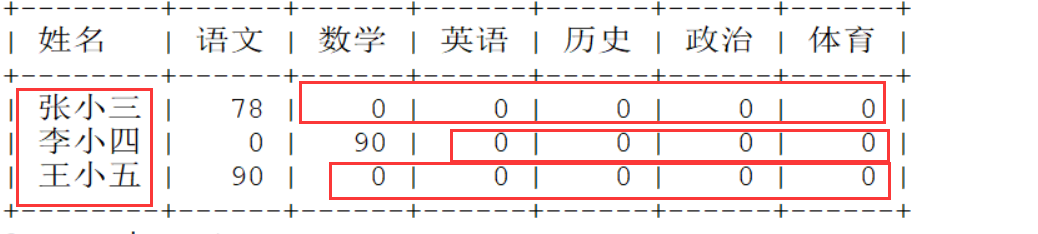
发现一个问题:已经分组了,但是成绩部分,只是以前没有分组的第一条数据?tel me why?
原因是:分组查询中 select from 之间,只能使用分组字段以及聚合函数,其他普通字段也可以使用,但是只展示第一条,毫无意义。
终极版:
select sname as 姓名,
sum(if(subject='语文',score,0)) as '语文',
sum(if(subject='数学',score,0)) as '数学',
sum(if(subject='英语',score,0)) as '英语',
sum(if(subject='历史',score,0)) as '历史',
sum(if(subject='政治',score,0)) as '政治',
sum(if(subject='体育',score,0)) as '体育'
from sc group by sname;
第二个版本:case版本
select sname as 姓名,
sum(case subject when '语文' then score else 0 end) as '语文',
sum(case subject when '数学' then score else 0 end) as '数学',
sum(case subject when '英语' then score else 0 end) as '英语',
sum(case subject when '历史' then score else 0 end) as '历史',
sum(case subject when '政治' then score else 0 end) as '政治',
sum(case subject when '体育' then score else 0 end) as '体育'
from sc group by sname;
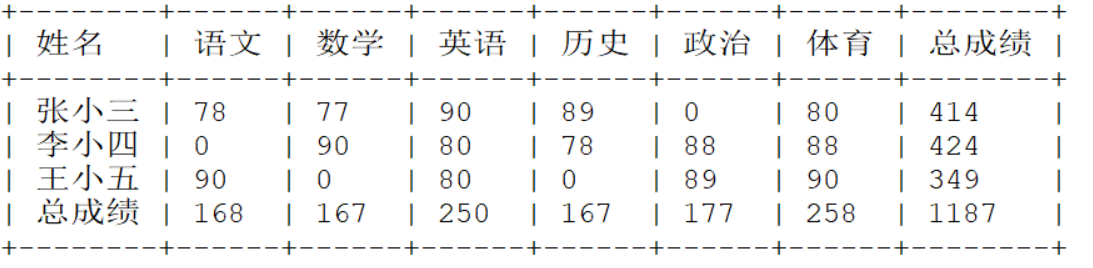
通过SQL语句,将我们的数据转换为: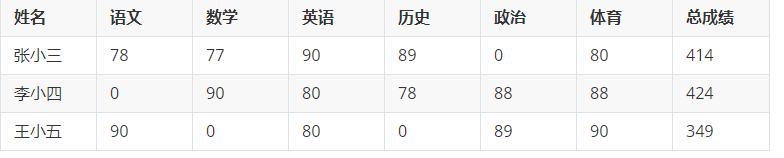
if版本的写法:
// 查询每一个同学的总成绩:
select sname,sum(score) from sc group by sname;
// 通过上面的SQL去理解下面的SQL
select sname as 姓名,
sum(if(subject='语文',score,0)) as '语文',
sum(if(subject='数学',score,0)) as '数学',
sum(if(subject='英语',score,0)) as '英语',
sum(if(subject='历史',score,0)) as '历史',
sum(if(subject='政治',score,0)) as '政治',
sum(if(subject='体育',score,0)) as '体育',
sum(score) as '总成绩'
from sc group by sname;
select sname as 姓名,
sum(case subject when '语文' then score else 0 end) as '语文',
sum(case subject when '数学' then score else 0 end) as '数学',
sum(case subject when '英语' then score else 0 end) as '英语',
sum(case subject when '历史' then score else 0 end) as '历史',
sum(case subject when '政治' then score else 0 end) as '政治',
sum(case subject when '体育' then score else 0 end) as '体育',
sum(score) as '总成绩'
from sc group by sname;
通过SQL语句,将数据转化为如下格式: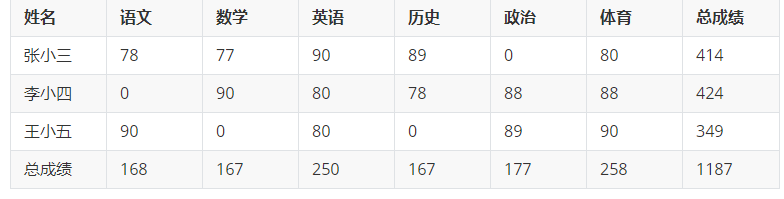
可以将上面的结果看做是两个查询的合并:
第一部分:按照名字进行的分组查询。
第二部分: 不按照任何分组进行的查询
只剩下一个问题:

select '总成绩' as '姓名',
sum(if(subject='语文',score,0)) as '语文',
sum(if(subject='数学',score,0)) as '数学',
sum(if(subject='英语',score,0)) as '英语',
sum(if(subject='历史',score,0)) as '历史',
sum(if(subject='政治',score,0)) as '政治',
sum(if(subject='体育',score,0)) as '体育',
sum(score) as '总成绩'
from sc ;

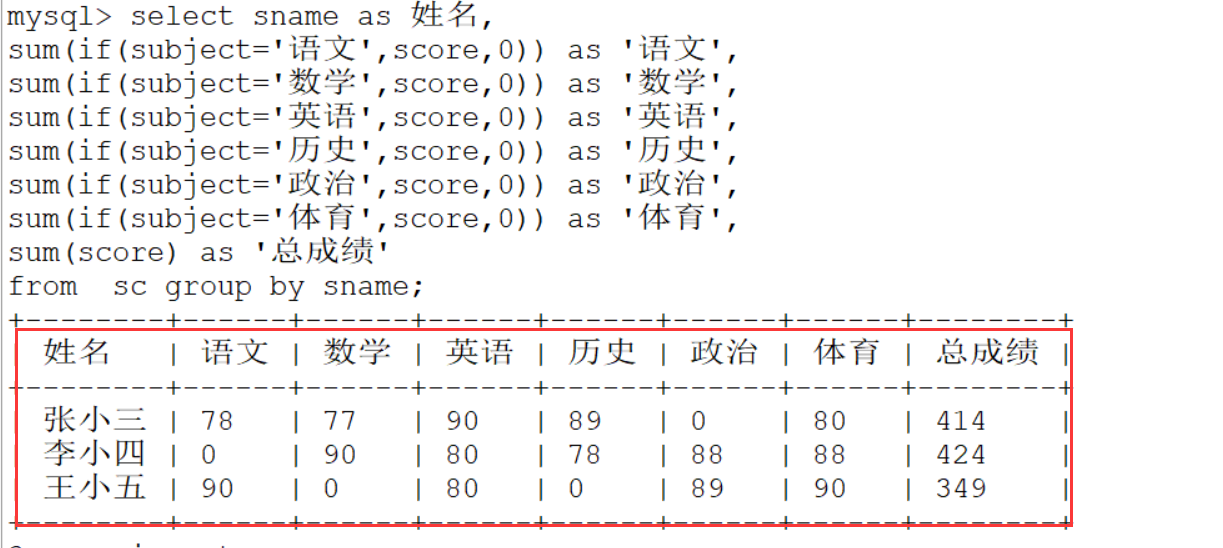
最终的答案:
select sname as 姓名,
sum(if(subject='语文',score,0)) as '语文',
sum(if(subject='数学',score,0)) as '数学',
sum(if(subject='英语',score,0)) as '英语',
sum(if(subject='历史',score,0)) as '历史',
sum(if(subject='政治',score,0)) as '政治',
sum(if(subject='体育',score,0)) as '体育',
sum(score) as '总成绩'
from sc group by sname
union
select '总成绩' as '姓名',
sum(if(subject='语文',score,0)) as '语文',
sum(if(subject='数学',score,0)) as '数学',
sum(if(subject='英语',score,0)) as '英语',
sum(if(subject='历史',score,0)) as '历史',
sum(if(subject='政治',score,0)) as '政治',
sum(if(subject='体育',score,0)) as '体育',
sum(score) as '总成绩'
from sc ;
写case 版本:
select sname as 姓名,
sum(case subject when '语文' then score else 0 end) as '语文',
sum(case subject when '数学' then score else 0 end) as '数学',
sum(case subject when '英语' then score else 0 end) as '英语',
sum(case subject when '历史' then score else 0 end) as '历史',
sum(case subject when '政治' then score else 0 end) as '政治',
sum(case subject when '体育' then score else 0 end) as '体育',
sum(score) as '总成绩'
from sc group by sname
union
select '总成绩' as 姓名,
sum(case subject when '语文' then score else 0 end) as '语文',
sum(case subject when '数学' then score else 0 end) as '数学',
sum(case subject when '英语' then score else 0 end) as '英语',
sum(case subject when '历史' then score else 0 end) as '历史',
sum(case subject when '政治' then score else 0 end) as '政治',
sum(case subject when '体育' then score else 0 end) as '体育',
sum(score) as '总成绩'
from sc;
5、exists 存在的意思。判断数据是否存在,效率要比连接查询以及子查询效率高!
1、查询有员工的部门
没有使用exists 之前:
select distinct d.* from dept d left join emp e on d.deptno = e.deptno where e.deptno is not null;
使用exists 以后:
select * from dept where exists (select 1 from emp where emp.deptno= dept.deptno);
2、查询没有员工的部门
select * from dept where not exists (select 1 from emp where emp.deptno= dept.deptno);
3、查询有部门的员工
select * from emp where exists (select 1 from dept where dept.deptno = emp.deptno);
4、查询没有部门的员工
select * from emp where not exists (select 1 from dept where dept.deptno = emp.deptno);
5、查询有下属的员工信息 (只要有一个员工他的部门领导的mgr 是我的员工编号,我就是领导,就应该被查询出来)
select * from emp e1 where exists (select * from emp e2 where e2.mgr = e1.empno );
6、查询有领导的员工信息(需要查询的数据,他的领导人编号刚好是别人的员工编号,这样的人就是有领导的人)
select * from emp e1 where exists (select * from emp e2 where e1.mgr = e2.empno);
6、常用函数
1)字符串函数
1、获取字符串的长度 char_length(s)
select char_length('Hello');
2、转换为大写:
select UPPER("runoob");
SELECT UCASE("runoob");
3、字符串空格的切割
SELECT TRIM(' RUNOOB ');// 左边和右边都切除
SELECT RTRIM("RUNOOB ");// 只切除右边的空格
SELECT LTRIM(" RUNOOB");// 只切除左边的空格
4、截取一段字符串
SELECT SUBSTR("RUNOOB", 2, 3); // 从第二个开始截取3个长度的字符串
5、比较两个字符串 相等返回0
SELECT STRCMP("runooc", "runoob");
6、将字符串的内容进行反转
SELECT REVERSE('abc');
7、替换
SELECT REPLACE('abc','a','x');// 将a 替换为 x
8、大写转小写
SELECT LOWER('RUNOOB');
SELECT LCASE('RUNOOB');
9、对数据进行格式化,截取的后一位四舍五入
select format(20.1987,2);
10、字符串通过某个分隔符进行拼接:
select concat_ws('~','Hello','World','Laoyan') ;
11、拼接字符串
select concat('Hello','World','Laoyan') ;
2)数学函数
除了我们之前学过的聚合函数以外,还有:
1、求某个数字,精确到小数点的位置,不四舍五入
SELECT TRUNCATE(1.23456,3);
2、获取0到1之间的随机数
select rand();
3、获取次方
select pow(2,3);
4、求pi 的值
select pi();
5、求余
select mod(5,2);
6、获取一个数据集的最大最小值:
SELECT GREATEST(3, 12, 34, 8, 25);
SELECT LEAST(3, 12, 34, 8, 25);
7、求地板砖
select floor(1.9);
8、求天花板
select ceil(10.1);
9、除以
select 10 div 5;
10、求绝对值
select abs(-100);
3)时间函数
获取当前时间:
带年月日时分秒:
select current_timestamp();
select now();
只获取当前的日期:
select current_date();
select curdate();
只获取时分秒:
select current_time();
select curtime();
获取date类型的数据:
SELECT DATE("2017-06-15");
两个日期之间的差值:
select datediff('2022-01-21','2022-05-31');
日期的格式化:
SELECT DATE_FORMAT('2011-11-11 11:11:11','%Y-%m-%d %r');
获取年,获取月,获取日:
select day('2022-03-28');
select year('2022-03-28');
select month('2022-03-28');
六、TCL
前面已经学习了 DDL\DML\DQL
TCL 是跟数据无关的SQL语句,一般用于创建用户,修改密码,以及赋予权限等内容。
1、创建用户
目前我们的用户是 root ,超级管理员。
语法:
create user '用户名'@'主机名' identified by '密码';
用户名: 只要不是root
主机名: 允许哪些电脑登录我的mysql服务。如果只允许本机登录 localhost(127.0.0.1),如果想让这个新创建的用户在任意电脑上都可以登录,主机名设置为 %
create user 'laoyan'@'localhost' identified by '123456';
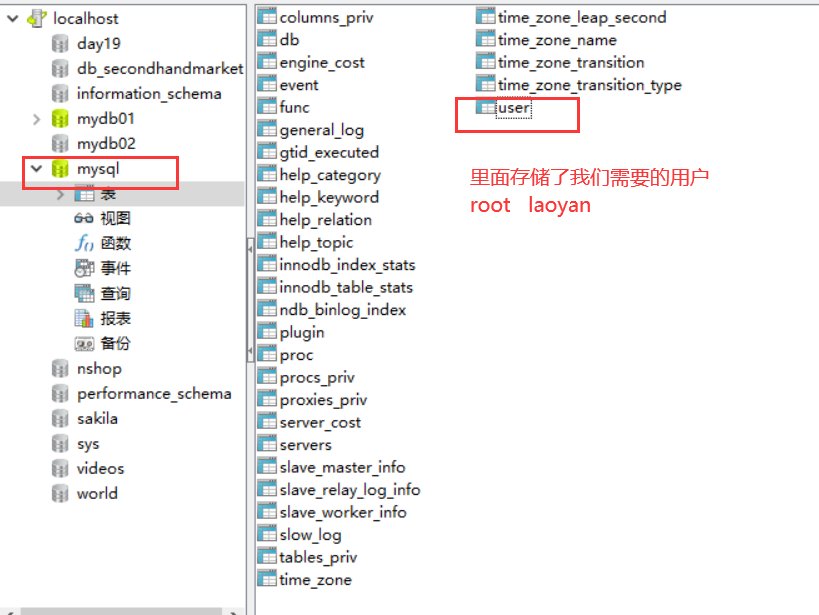
2、赋予权限
创建出来的用户没有任何权限,需要赋予权限
grant 权限1,权限2 ..... on 某个数据库中的一些表 to '用户民'@'主机名'
grant create,alter,insert,update,select on mydb01.* to 'laoyan'@'localhost';
撤销权限:
revoke 权限1,xxxx on 数据库.表名;
revoke create on mydb01.* from 'laoyan'@'localhost';// 撤销某个
revoke all on mydb01.* from 'laoyan'@'localhost';// 撤销所有
查看权限:
show grants for 'laoyan'@'localhost';
3、实战
我们自己的数据库,安装完成后,只允许我们自己本机访问,别人是访问不了的,因为权限的主机名是localhost<br />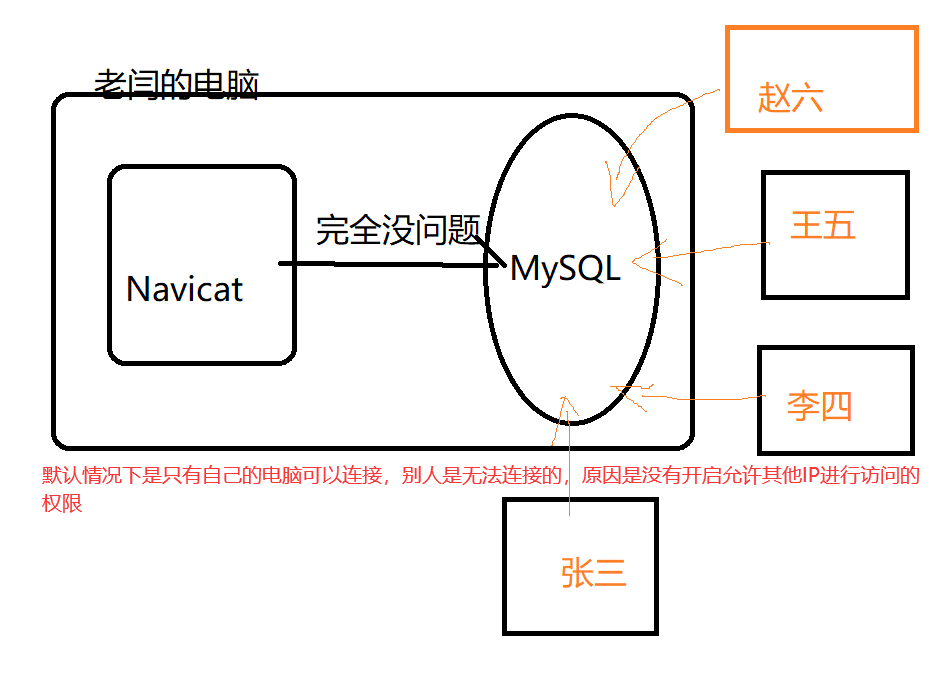<br />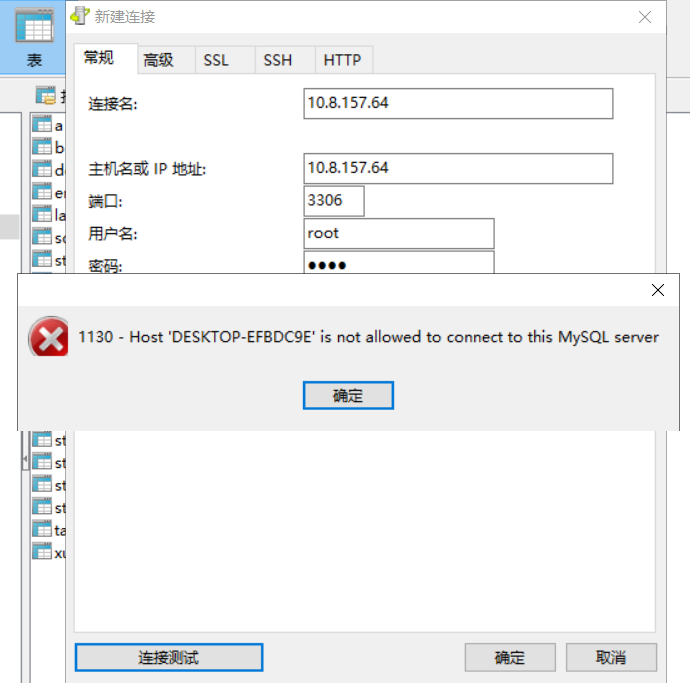
方案一:
改表法:
将mysql 数据库中的 对应的user 表中的 localhost 修改为 %

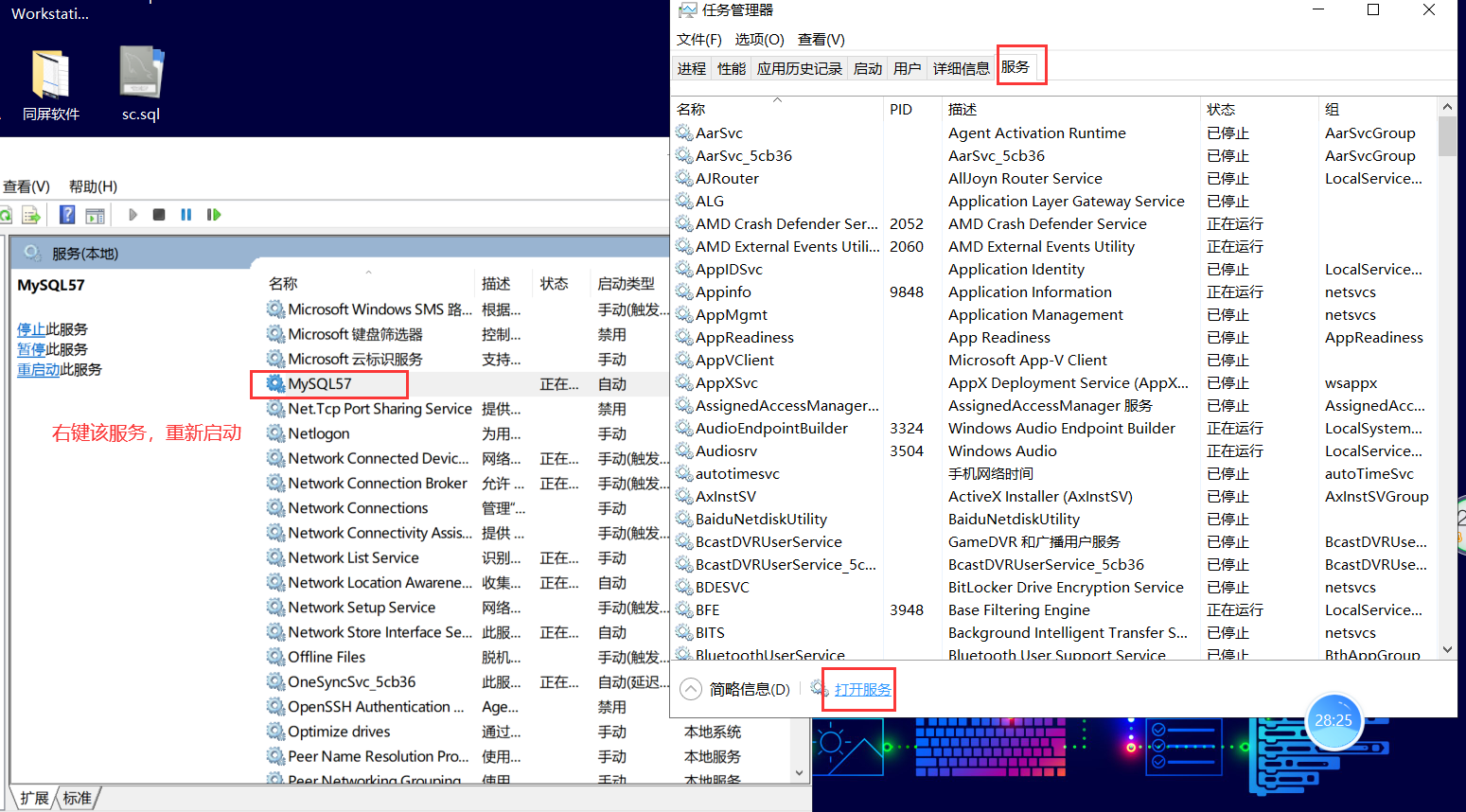
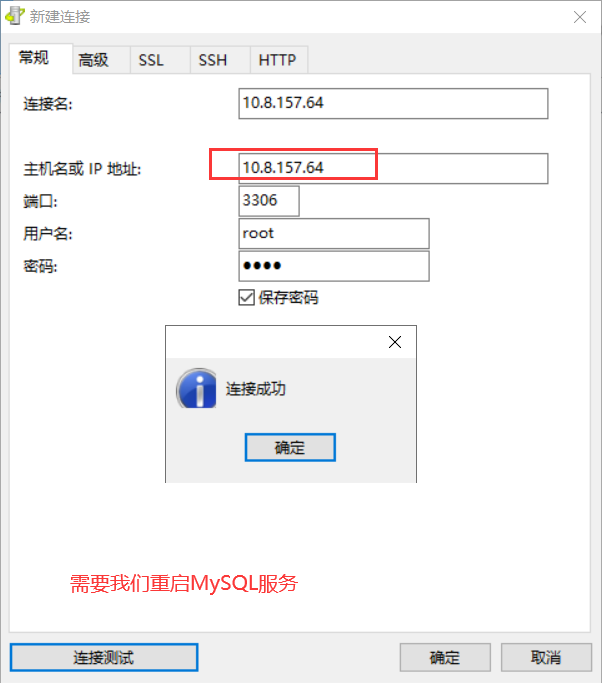
改表的方法修改成功!!!
授权法:
修改权限:
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;// 刷新权限
4、如何修改密码?
1)你可以登录成功,知道以前的密码,现在想重新设置一个新密码
use mysql;
update user set password = password('新密码');
这个方式只允许在mysql5.5之前可以使用。
mysql 5.7 以后,没有password 字段,只有 authentication_string
use mysql;
update user set authentication_string= password('123456') where user='root';
修改完之后需要重启mysql服务才可以。
2) 如果你把密码忘记了,压根登录不进去,也就没办法编写SQL语句
1. cmd -- > net stop mysql 停止mysql服务
* 需要管理员运行该cmd
2. 使用无验证方式启动mysql服务: mysqld --skip-grant-tables
3. 打开新的cmd窗口,直接输入mysql命令,敲回车。就可以登录成功
4. use mysql;
5. update user set password = password('你的新密码') where user = 'root';
6. 关闭两个窗口
7. 打开任务管理器,手动结束mysqld.exe 的进程
8. 启动mysql服务
9. 使用新密码登录。

若有收获,就点个赞吧
0 人点赞
