一、MySQL的安装
1、windows版本的安装分为两种
1)解压,并进行配置文件的配置
2)直接使用安装包安装
2、安装过程中,学习的时候
1) 端口3306 ,非必要不要改
2) 密码设置为123456 或者 root
3) 要明白,mysql的默认用户名是root
二、为什么要学习MySQL
1、MySQL中编写的SQL语句是一种编程语言,SQL语句是通用的,在MySQL 上学完,其他关系型数据库都可以使用。SQL一般语法不变化。十年前怎么写十年后还怎么写。
DBA(数据库管理员)
2、MySQL 这个数据库非常的小巧,免费的,市场占有率很高。虽然Oracle是数据库的老大,但是正在慢慢失去优势。
3、MySQL 中的SQL语法 是我们学习 Hive、SparkSQL 、Flink SQL 的必背技能。
4、大数据工程师,数据来源很多,其中关系型数据库中的数据是数据来源的重要部分。
三、数据库
数据库概念的理解:数据库里面存放的是一条条的数据。
DB:数据库,真正的数据库就是文件而已。
目前我想一些学生信息存放在磁盘上,我们可以通过IO流来完成存储。
但是有一点:操作起来不是特别方便,比如查询、删除、修改、新增都不是特别方便,有一些公司就开始提供这样的服务:
该公司可以编写一个软件,开发人员只需要编写他们规定的SQL语句,就可以操作底层文本文件。—这样的软件称之为—DBMS
(数据库管理系统)。
四、数据库的分类
1、关系型数据库
什么是关系型数据库呢? 通过行和列表达事物的这种数据库就是关系型的。<br /> 常见的关系型数据库有哪些?<br /> 1) Oracle : 是Oracle(甲骨文) 公司的核心产品(oracle公司有考试:颁发相应的数据库管理员证书)<br /> 2) MySQL : 早年是瑞士的一家MySQLAB 公司的,后来卖给了SUN, SUN又被Oracle公司收购了,所以目前是Oracle公司的。<br /> 3) MariDB: MySQL之父,出走Oracle 公司以后,在MySQL5.5基础之上修改的。<br /> 4) SQLServer: 微软的,一般java阵营的小伙伴不用。C#.net 这个路线的人在用。<br /> 6) DB2: IBM旗下产品。
2、非关系型数据库
1)Redis 是一个开源的,Key-Value价值对存储的一种基于内存的数据库,非常的小巧,性能很高,一般用作缓存。
2)HBase 是一个分布式的面向列存储的开源数据库(存储百万级的列,上亿的行),是大数据必须技能之一。
3)MongoDB 是一个基于文件存储的数据库(web前端的经常使用)
五、SQL的概念以及分类
SQL: Structure Query Language (结构化的查询语言),是开发语言之一。
目前SQL已经被标准化了(ANSI)。SQL语言是数据库的官方语言,每个SQL厂商还有自己的方言。
SQL语言经常使用的操作:CRUD (增Create 删 Delete 改 Update 查 Read )
SQL语法很多:
DDL: (Data Definition Language) 如何定义的语法(创建一个数据库,创建表,创建字段)
DML: (Data Manipulation Language) 数据库操作语法(数据库中新增删除修改数据)
DQL: (Data Query Language) 查询数据 (数据库中有数据,需要查询)
TCL: (Transaction Control Language) 比如修改密码、创建用户、赋予权限
六、图形化界面工具(数据库客户端工具)
1) 我们之前安装的软件是数据库的服务端

如果想操作数据库,可以使用cmd黑窗口
如果黑窗口你输入mysql 敲回车,说该命令无法识别,说明path路径没有配。
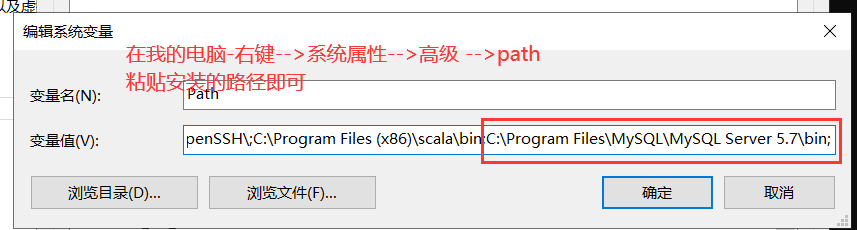
2)可以使用黑窗口来操作我们的数据库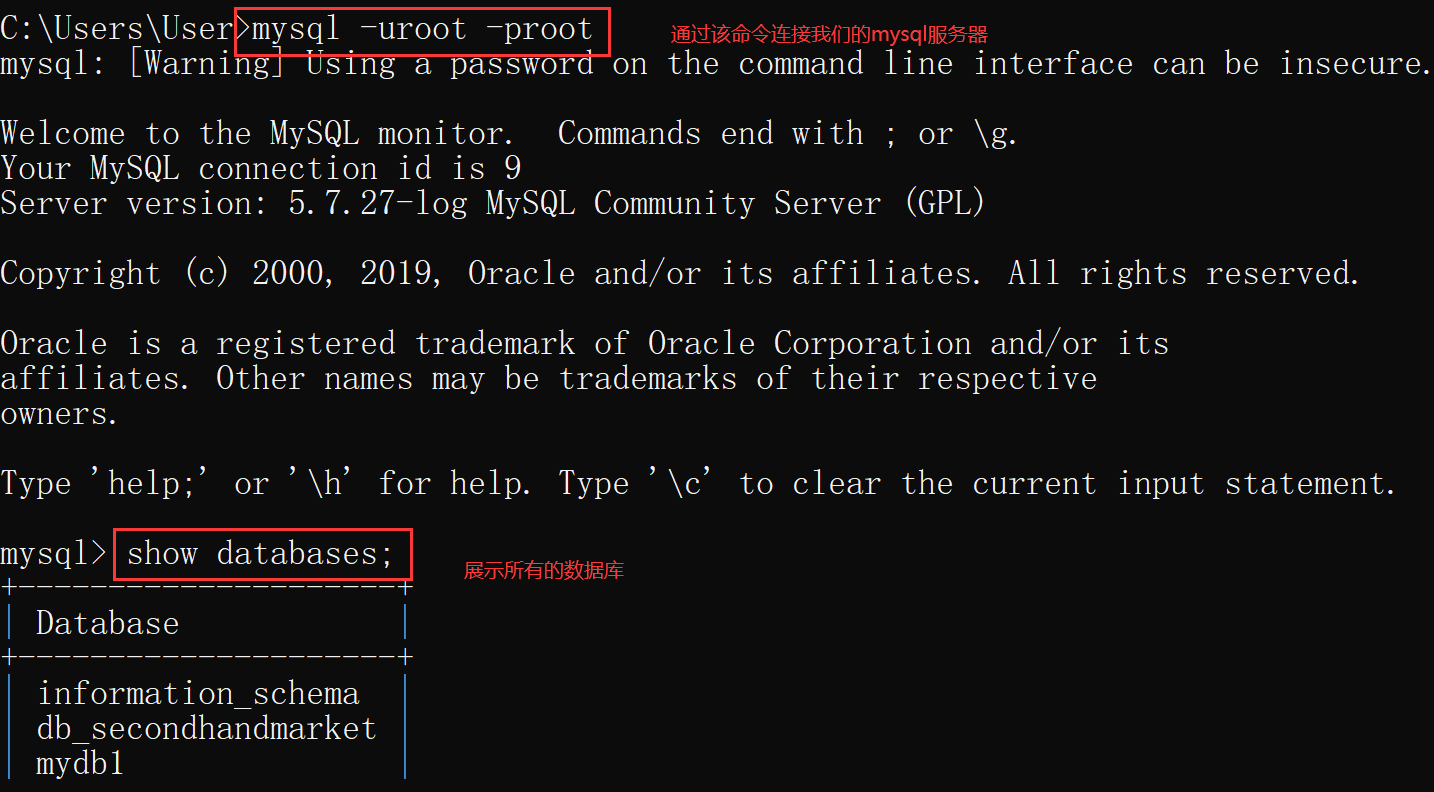
3) 可视化的客户端
这种软件有很多种:SQLyog Navicat 设置可以使用我们的idea 都可以连接我们的数据库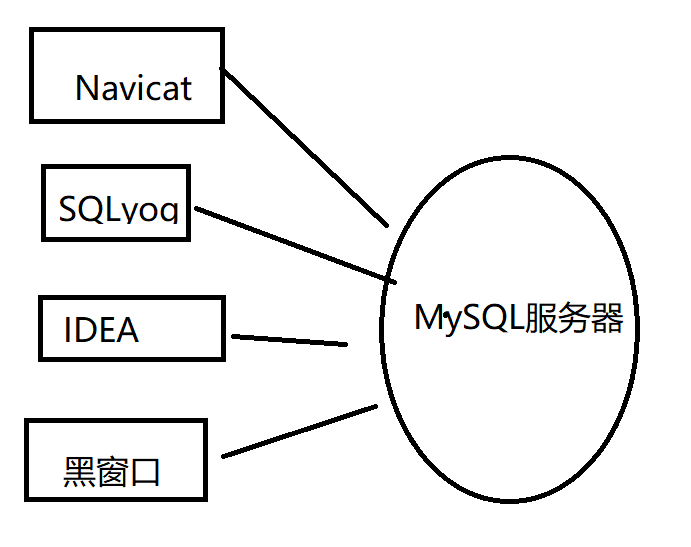

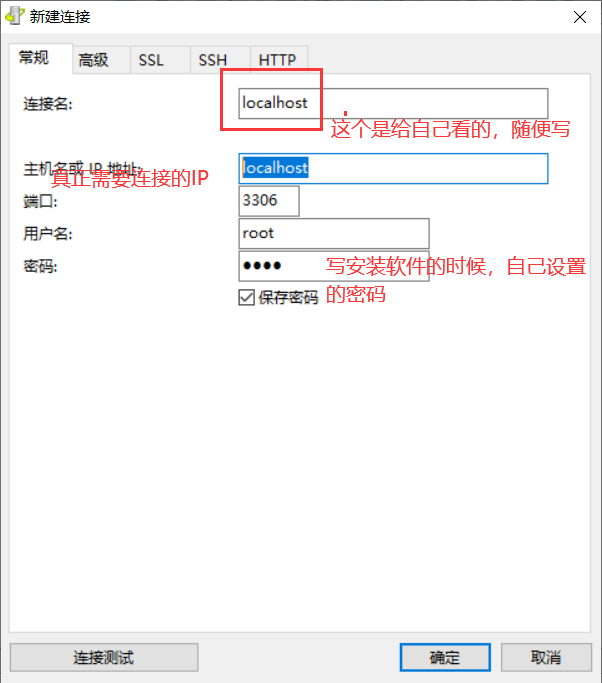
先点击连接测试,没有问题,再点确定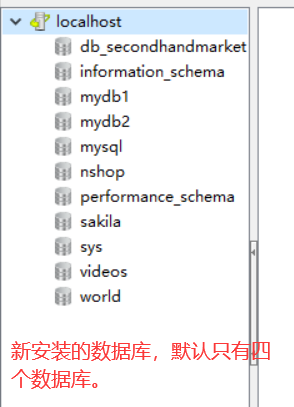
七、常规的SQL编写
1、DDL —创建数据库创建表的语句
创建数据库:
create database mydb01;
create database mydb02 character set utf8;
提问:第一个创建数据库的语法没有指定字符集,默认的字符集是什么?
如果你创建数据库没有指定字符集,那么默认就是你安装mysql软件的时候指定的字符集。
查看数据库:
show databases;
show create database mydb01;
修改数据库:
alter database mydb01 character set utf8;
删除数据库:慎用!!!删库跑路!!
drop database mydb01;
表:表存在于数据库中,一个数据库可以有很多的表。
一个数据库软件可以创建很多个数据库。
表都是二维的,由行和列组成。表和表之间存在某种关系!
表中的字段类型:
| 数据类型 | 类型描述 | 示例 |
|---|---|---|
| int | 整型,整数类型 | |
| double | 浮点型 | double(5,2): 表示最多有5位,其中必须有两位数小数,即最大值是999.99 |
| char | 固定长度的字符串 255 一个a 也会占 255的长度 |
char(5): 固定5位字符,即’aa’也占用5位字符 |
| varchar | 可变长度的字符串 255 abc —> 只占了三个字符的长度 |
varchar(5): 可以根据内容动态分配空间,’aa’只占用两位。括号里的5表示最大的位数。 |
| text | 字符串类型 | |
| blob | 字节类型 | |
| date | 日期类型 | yyyy-MM-dd |
| time | 时间类型 | hh:mm:ss |
| timestamp | 时间戳类型 | yyyy-MM-dd hh:mm:ss,会自动赋值 CURRENT_TIMESTAMP |
| datetime | 时间类型 | yyyy-MM-dd hh:mm:ss |
综上所述:我们经常使用的字段: int varchar 两种类型,可以满足大部分情况。
通过DDL语句操作表结构:
创建表:
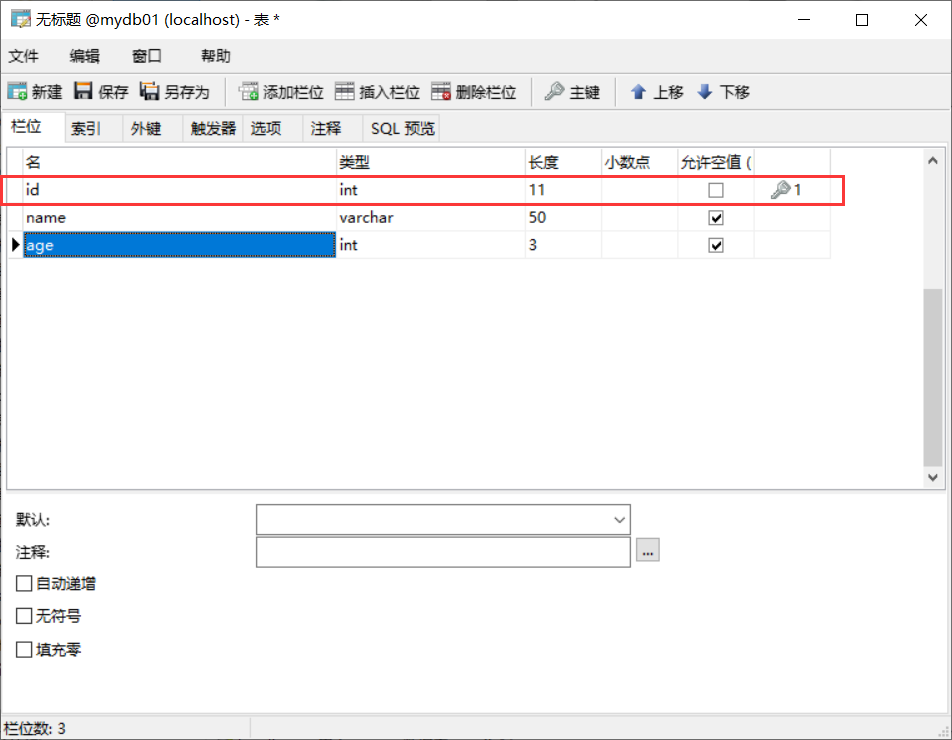
create table student(name varchar(25),age int,gender varchar(2));
查看某个数据库中所有的表:
show tables;
查看某个表中有哪些字段:
desc student;

通过以上这个图,我们可以看到int类型,我没有给定长度,默认长度是11位。
我们怎么知道我们目前操作的是哪个数据库呢?
一定要先选数据库,再操作表,在图形化界面中,直接点击哪个数据库,SQL语句操作的就是哪个数据库。
通过命令切换数据库。use 数据库的名字 可以进行数据库之间的切换!!!!
use videos;
表的删除:
drop table student;
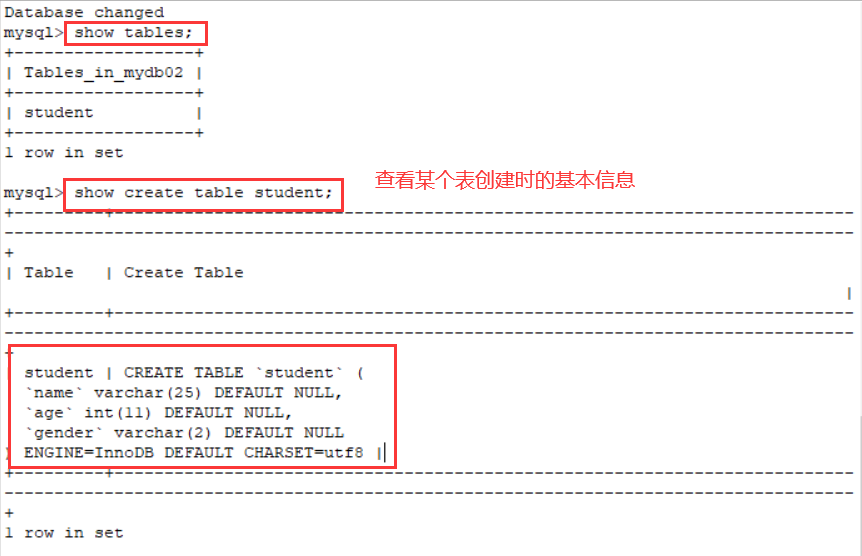
查看创建表的信息:
show create table student;
对表进行重命名:
alter table student rename to student_new;
给表添加一个字段:
alter table student_new add height double(5,2)
double(5,2) 5代表长度,2 代表小数点后有几位! 5这个长度包含后面的两位吗?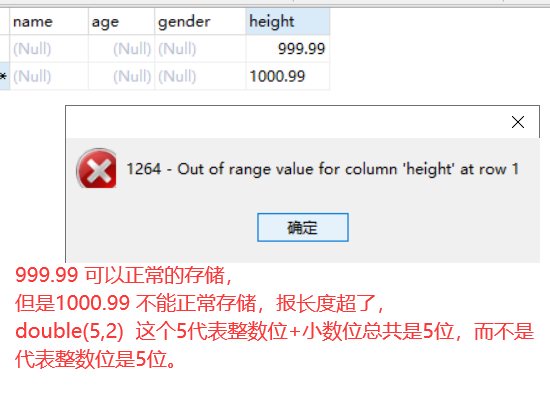
查看当前的数据库是哪个?
select database();
切换还得使用 use + 数据库名字;
修改表中的某个字段类型:
alter table student_new modify height int;
以前这个height 是double ,变为int以后,就会自动转换。
修改表中的一个字段:
alter table student_new change name uname varchar(50)
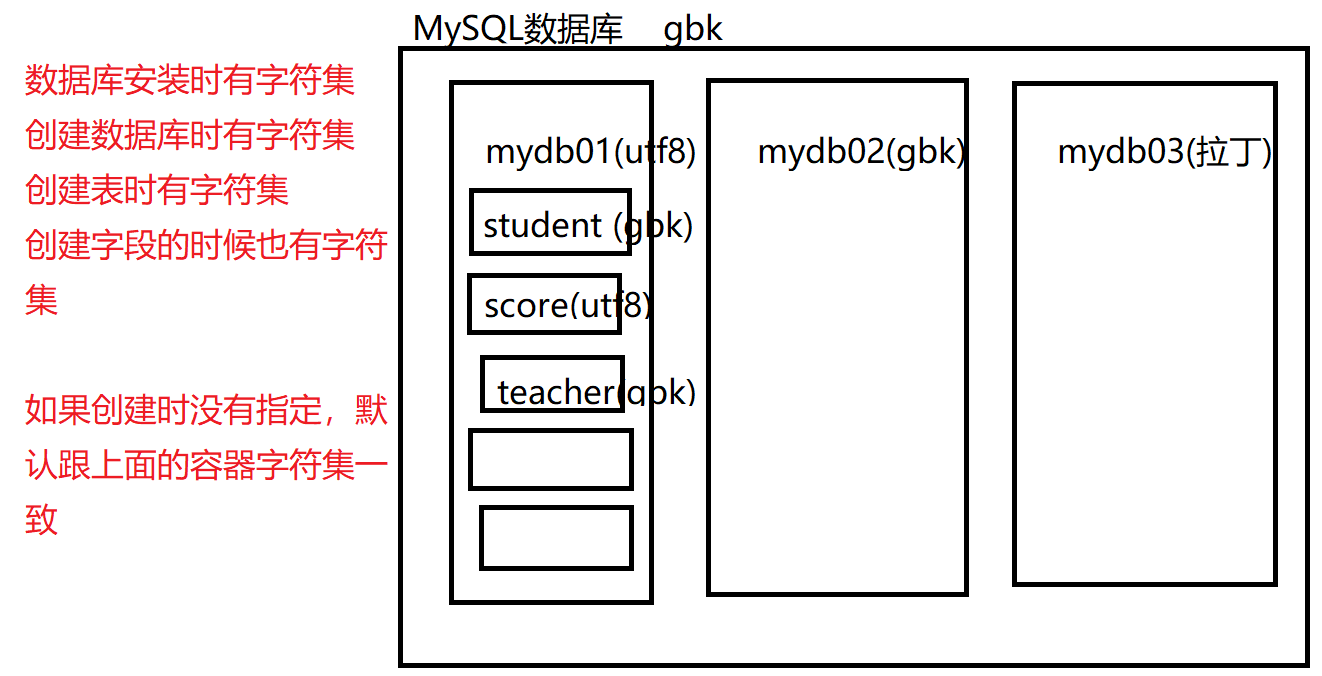
修改表的字符集:
我创建表的时候,没有给定字符集,那么默认的字符集是哪个?
默认就是数据库的字符集(mydb02)。
alter table student_new character set gbk;
删除表中的一个字段:
alter table student_new drop height;
备份表结构和表数据:
create table student2 as select * from student_new;
备份表结构,不要数据
create table student3 like student_new;
2、DML操作 —数据的新增修改删除操作
1)插入数据:
insert into 表名(列名1,列名2,列名3...) values (列值1,xxx,xxxx,xxx)
值的类型要和列名的类型保持一致。
create table emp(
id int,
name varchar(255),
gender varchar(3),
birthday date,
salary double(10,2),
entry_date date,
resume text
);
insert into emp(id,name,gender,birthday,salary,entry_date,resume) values(1,'zhangsan','男','1987-02-06',10000,'2015-05-21','生平爱打抱不平,义薄云天');
insert into emp(id,name,gender,birthday,salary,entry_date,resume) values(2,'lisi','男','1987-02-06',10000,'2015-05-21','生平爱打抱不平,义薄云天2');
// 查看emp表中的所有数据
select * from emp;
特殊的举例:
创建一个新表,里面的字段跟之前一样
create table emp2(
id int,
name varchar(255),
gender varchar(3),
birthday date,
salary double(10,2),
entry_date date,
resume text
);
insert into emp2 select * from emp;
删除数据:
方式一: delete from emp ; // 删除所有数据
方式二: truncate table emp;// 也是删除表中所有字段的意思
区别:
方式一的意思是:删除表中的数据,但是表结构还留着,删除的数据还可以恢复。
方式二的意思是:先把表给你Drop掉,再帮你创建一个新的表,这个表结构跟之前一模一样。数据是不可恢复的。
方式一删除的速度比较慢,方式二比较快。
修改数据:
语法:
update 表名 set 列名=列值,列名2=列值2 where 条件
update emp set name='zhaoliu';
如果你只想更新部分信息的字段值,可以添加一个where 条件
update emp set name='老闫' where id = 1;
详细讲解where:
where 条件过滤,只有满足条件的才会进行操作。
where条件常见于 修改、删除、查询。
where 条件和删除在一起使用:
delete from emp where id = 2;
where条件和查询在一起使用。
select * from emp where name = '老闫';
| 条件 | 描述 |
|---|---|
| = | 相等比较,类似于Java中的== |
| != <> | 不等比较 |
| > < >= <= | 大小比较 |
| BETWEEN…AND… | 判断在两个值之间 |
| IN(…) | 判断是否包含在指定的集合内 |
| IS NULL | 判断是否为空 |
| IS NOT NULL | 判断是否不为空 |
| AND OR NOT | 逻辑判断,与、或、非 |
| [NOT] LIKE | 模糊比较 |
操作一遍:
不等于有两种写法:
select * from emp where id != 2;
select * from emp where id <> 2;
select * from emp where id > 1;
select * from emp where id between 1 and 2; // id >= 1 && id <= 2
// 查询id 在某些值中间的,是满足条件的
select * from emp where id in(1,3,5);
// 判断某个字段是否为空
select * from emp where resume is null;
select * from emp where resume is not null;
// 查询id =1 或者 id=3
select * from emp where id=1 or id=3;
select * from emp where name='老闫' and id = 1;
// 查询名字中含有闫 这个字的员工信息
% 代表0 个或者多个文字。
select * from emp where name like '%闫%'
3、DQL—数据的查询(重点)
1)语法:
select ... from 表名 where ....
student表
| 字段名称 | 字段类型 | 说明 |
|---|---|---|
| sid | char(6) | 学生学号 |
| sname | varchar(50) | 学生姓名 |
| age | int | 学生年龄 |
| gender | varchar(50) | 学生性别 |
CREATE TABLE stu (
sid CHAR(6),
sname VARCHAR(50),
age INT,
gender VARCHAR(50)
);
INSERT INTO stu VALUES('S_1001', 'liuYi', 35, 'male');
INSERT INTO stu VALUES('S_1002', 'chenEr', 15, 'female');
INSERT INTO stu VALUES('S_1003', 'zhangSan', 95, 'male');
INSERT INTO stu VALUES('S_1004', 'liSi', 65, 'female');
INSERT INTO stu VALUES('S_1005', 'wangWu', 55, 'male');
INSERT INTO stu VALUES('S_1006', 'zhaoLiu', 75, 'female');
INSERT INTO stu VALUES('S_1007', 'sunQi', 25, 'male');
INSERT INTO stu VALUES('S_1008', 'zhouBa', 45, 'female');
INSERT INTO stu VALUES('S_1009', 'wuJiu', 85, 'male');
INSERT INTO stu VALUES('S_1010', 'zhengShi', 5, 'female');
INSERT INTO stu VALUES('S_1011', 'xxx', NULL, NULL);
emp表
| 字段名称 | 字段类型 | 说明 |
|---|---|---|
| empno | int | 员工编号 |
| ename | varchar(50) | 员工姓名 |
| job | varchar(50) | 员工工作 |
| mgr | int | 领导编号 |
| hiredate | date | 入职日期 |
| sal | decimal(7,2) | 月薪 |
| comm | decimal(7,2) | 奖金 |
| deptno | int | 部分编号 |
CREATE TABLE emp(
empno INT,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
);
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
查询开始:
1)基础查询
// * 代表所有列
select * from stu;
// sname,age 代表的是指定的列
select sname,age from stu;
2) 条件查询
CREATE TABLE stu (
sid CHAR(6),
sname VARCHAR(50),
age INT,
gender VARCHAR(50)
);
1、查询条件为女,并且年龄小于50岁的记录
select * from stu where gender='female' and age<50;
2、查询学号为S_1001,或者姓名是liSi的记录
select * from stu where sid='S_1001' or sname ='liSi';
3、查询学号为S_1001,S_1002,S_1003的记录
select * from stu where sid = 'S_1001' or sid = 'S_1002' or sid = 'S_1003'
select * from stu where sid in ('S_1001','S_1002','S_1003');
3) 模糊查询
使用where + like 进行模糊查询,like 后面可以跟两种通配符 %
代表任意一个字符
% 代表0个或者多个字符
1、查询所有姓名中以S开头的学生
select * from stu where sname like 's%';
2、查询所有姓名中以S开头的学生,并且名字长度是五位的学生
select * from stu where sname like 's____';
4) 数据去重
去除重复的记录 distinct
select sal from emp;// 查询到的薪水有重复的,可以去重
select distinct sal from emp;
5)列之间的计算
查看所有员工的总的薪水情况。
select ename,sal+comm from emp;

问题一:基本工资+null 理论讲应该是只有工资才对,不应该是null
select ename,sal+IFNULL(comm,0) from emp;
问题二: 可以给列起别名就好了。
as 可以去掉
select ename,sal+IFNULL(comm,0) as 总薪水 from emp;
select ename as 姓名,sal+IFNULL(comm,0) as 总薪水 from emp;
6) 结果排序
根据学生年龄,从小到大排序
关键字 order by 字段 ; desc 代表降续,asc 代表升续,默认是升续的。
select * from stu order by age asc ;
select * from stu order by age ;
select * from stu order by age desc;

若有收获,就点个赞吧
0 人点赞
