一、四大函数式接口以及Stream流,详见 【补充:Stream流】
二、Map集合
1、Map集合的常用方法
package com.qfedu.day12_02;import java.util.Collection;import java.util.HashMap;import java.util.Map;import java.util.Set;import java.util.function.BiFunction;/*** @Author laoyan* @Description TODO* @Date 2022/3/16 10:56* @Version 1.0*/public class DemoMap {/*** map集合的常用方法* @param args*/public static void main(String[] args) {/*** Map 是一个接口,父接口不是Collection* Map 接口他的有名的实现类 HashMap* 他跟之前的集合相比,最大的不同就是 是以键值对形式出现的。* Map 集合又称之为本地缓存(jvm内存中的)。*/Map<String, String> map = new HashMap<>();// put 存放数据, 而且有返回值,如果key已经存在,就覆盖掉原来的value,并且返回被覆盖掉的值,如果不是覆盖,返回nullmap.put("100","张三");map.put("200","李四");map.put("300","王五");// get 通过key 值获取 valueSystem.out.println(map.get("100"));// 如果出现相同的key 值,覆盖原来的数据String name = map.put("100", "老闫");String name2 = map.put("400", "老闫");System.out.println(name);System.out.println(name2);// null 可以当做 map集合中的key 和 valuemap.put(null,"慕遥");map.put("500",null);System.out.println(map);System.out.println(map.get(null));// put 是覆盖,putIfAbsent 是存在就插入不了了,不是覆盖,而且返回已经存在的值String name3 = map.putIfAbsent("400", "张宇");// 打印出来是老闫System.out.println(name3);HashMap<String, String> m = new HashMap<>();m.put("181","张局长");m.put("188","黄主任");m.put("400","闫政委");map.putAll(m);System.out.println(map);// map.remove("188"); // 通过Key 删除键值对map.remove("188","黄主任"); // 通过key 和 value 删除键值对System.out.println(map);//map.clear();boolean b = map.replace("181", "张局长", "张军长");System.out.println(map);map.replaceAll(new BiFunction<String, String, String>() {@Overridepublic String apply(String key, String value) {System.out.println("k="+key);System.out.println("v="+value);if(null != key && Integer.valueOf(key) > 300){return "hello" + value;}else{return "world";}}});System.out.println(map.get("1000")); // nullSystem.out.println(map.getOrDefault("1000","ABC")); // 如果获取不到,直接返回默认值ABC,如果获取到了,直接返回valueSystem.out.println(map);System.out.println(map.isEmpty()); // list , String , SetSystem.out.println(map.size()); // 返回map集合中键值对的个数System.out.println(map.containsKey("400")); // trueSystem.out.println(map.containsValue("闫政委")); // falseSet<String> keys = map.keySet(); // map 中所有的键,都存放在一个set中for (String key:keys) {System.out.println(key);}Collection<String> values = map.values();for (String value:values) {System.out.println(value);}}}
2、Map集合的三种遍历方式
package com.qfedu.day12_02;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/16 11:41
* @Version 1.0
*/
public class DempMap2 {
/**
* map集合的三种遍历方式
* @param args
*/
public static void main(String[] args) {
HashMap<String, String> m = new HashMap<>();
m.put("181","张局长");
m.put("188","黄主任");
m.put("400","闫政委");
/**
* 获取里面所有的键值对
* 通过key 获取value
*/
Set<String> keys = m.keySet();
for (String key:keys) {
System.out.println("Key="+key+",value ="+m.get(key));
}
/**
* 第二种方式 forEach
*/
m.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println("Key="+key+",value ="+m.get(key));
}
});
m.forEach((key,value) ->System.out.println("Key="+key+",value ="+m.get(key)));
/**
* 第三种:使用Entry 获取 key value
* class Entry{
* private String key;
* private String value
* }
* Set 集合
* {entry1,entry2......}
*/
Set<Map.Entry<String, String>> entrySet = m.entrySet();
for (Map.Entry<String,String> entry:entrySet) {
System.out.println("Key="+entry.getKey()+",value ="+entry.getValue());
}
}
}
3、Hashtable
1. HashMap是线程不安全的集合, Hashtable是线程安全的集合。
2. HashMap允许出现null键值, Hashtable是不允许的。
3. HashMap的父类是AbstractMap, Hashtable的父类是Dictionary。
4. HashMap的Map接口的新的实现类, 底层算法效率优于Hashtable。
4、TreeMap
TreeMap 是有序的,指的是Key有序。
5、LinkedHashMap
HashMap --> LinkedHashMap
HashMap 中存储了多个元素,打印输出的时候,不按照我存入的顺序打印。
LinkedHashMap 打印就是按照存储的顺序来的。
代码:
package com.qfedu.day12_02;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.TreeMap;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/16 14:59
* @Version 1.0
*/
public class DemoTreeMap {
public static void main(String[] args) {
TreeMap<Integer, String> treeMap = new TreeMap<>();
treeMap.put(1,"我们的奥运");
treeMap.put(5,"这个杀手不太冷静");
treeMap.put(3,"长津湖之水门桥");
treeMap.put(4,"守岛人");
System.out.println(treeMap);
TreeMap<Film, Integer> treeMap2 = new TreeMap<>();
treeMap2.put(new Film("长津湖","陈凯歌"),20);
treeMap2.put(new Film("功夫2","周星驰"),10);
treeMap2.put(new Film("阿发达","老闫"),200);
System.out.println(treeMap2);
// Map 集合中的key 值一般都是String或者int 类型的, 很少是自定义的类的类型
HashMap<Integer, String> treeMap3 = new HashMap<>();
treeMap3.put(1,"我们的奥运");
treeMap3.put(5,"这个杀手不太冷静");
treeMap3.put(3,"长津湖之水门桥");
treeMap3.put(4,"守岛人");
System.out.println(treeMap3);
LinkedHashMap<Integer, String> treeMap4 = new LinkedHashMap<>();
treeMap4.put(1,"我们的奥运");
treeMap4.put(5,"这个杀手不太冷静");
treeMap4.put(3,"长津湖之水门桥");
treeMap4.put(4,"守岛人");
System.out.println(treeMap4);
HashSet<String> set = new HashSet<>();
// 通过这个源码,我们看到HashSet 底层使用了HashMap
set.add("zahgnsan");
}
}
6、HashMap的存储原理
HashSet 底层数据结构是哈希表(JDK8里面:数组+链表+红黑树,JDK8之前:数组+链表)
JDK1.8之前结构:数组+链表 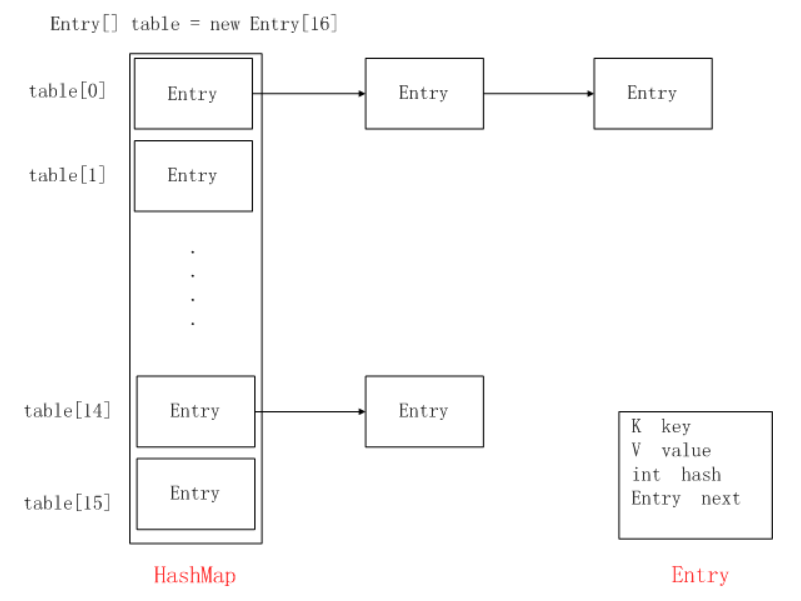
JDK1.8之后结构:节点数少于8个的时候采用数组+链表的结构,当节点数多于8个的时候,采用的是数组+红黑树的结构 。
HashMap存储的数据存放在内存中,提高HashMap数据寻址速度是重点要解决的问题,所以HashMap底层的存储结构非常关键,如果使用数组存储,时间复杂度为O(1),使用链表存储,时间复杂度为O(n),如果使用二叉树存储,时间复杂度为O(lg(n))。所以HashMap优先使用数组存储,如果出现hash碰撞,采用链表存储,如果链表长度大于8,寻址速度明显下降,进一步采用红黑树存储,将寻址效率提高。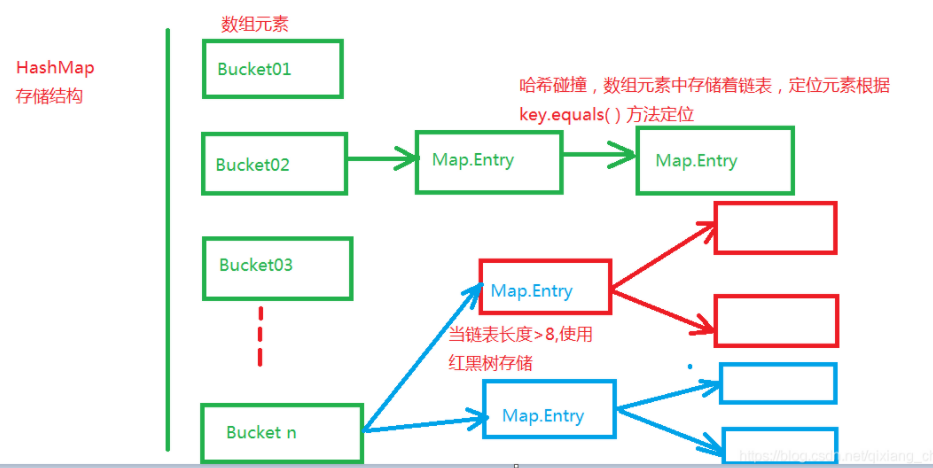
当存放两个元素获取Hash并且Mod 16得到Hash桶编号相同时,出现Hash碰撞,hash桶使用链表存储这两个对象,使用HashMap.get(key)获取这两个对象时,需要两步实现,首先得到它们对应的Hash桶号,在根据Key与链表中的Key1=Value1比较key.equale(key1),找出对应元素,这样需要递归遍历列表中的元素,执行效率降低。当链表长度大于8时,HashMap将链表存储转化为红黑树存储,红黑树遍历每次可以减少一个分支,效率比链表高,其时间复杂度为O(lg(n))。
7、HashMap 的扩容规则
HashMap使用数组存储,默认长度为16,加载因子为0.75,当HashMap的Hash桶数量的75%被分配使用时,HashMap扩容为原来的两倍。 跟HashSet一样。

若有收获,就点个赞吧
0 人点赞
