一、List的其他相关内容
1、LinkedList 作用仅次于 ArrayList
1) 比较
- 相同点:- 都是List集合的常用的实现类。- 对集合中的元素操作的方法基本一致。- 都是线程不安全的- 不同点:- ArrayList底层实现是数组, 使用数组这种数据结构进行数据的存储。- LinkedList底层实现是双链表, 使用双链表这种数据结构进行数据的存储。- 数组实现功能时查找快,添加删除慢 -- ArrayList- 链表查找慢,添加删除快 -- LinkedList- 如果对集合中的元素, 增删操作不怎么频繁, 查询操作比较频繁。 使用ArrayList。- 如果对集合中的元素, 增删操作比较频繁, 查询操作不怎么频繁。 使用LinkedList。
2)LinkedList 常见方法
package com.qfedu.day11;
import java.util.LinkedList;
import java.util.List;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/15 10:57
* @Version 1.0
*/
public class LinkedListDemo {
public static void main(String[] args) {
// list 只能调用List 接口中有的方法
List<String> list = new LinkedList<>();
// list2 可以调用LinkedList 中的独有方法
LinkedList<String> list2 = new LinkedList<>();
list2.add("sqoop"); // Collection
list2.add(0,"sparkCore"); // List
// 在第一个和最后一个插入某个元素
list2.addFirst("flume"); // LinkedList
list2.addLast("echarts");
// 获取第一个元素
System.out.println(list2.getFirst());
System.out.println(list2.getLast());
System.out.println(list2);
// 删除集合中的第一个元素,并返回该元素
/**
* jdk1.6以前的删除获取方法,拿不到元素报异常
* jdk1.6以后的删除获取方法,拿不到元素返回null
*/
System.out.println(list2.removeFirst());
System.out.println(list2.removeLast());
System.out.println(list2);
/**
* addFirst 没有返回值
* offerFirst 有返回值,可以返回插入是否成功
*
* offerFirst(E e)方法和addFirst(E e)方法实现的功能都是在列表的开头插入指定的元素。但是,有个小小的不同。
* 请注意二者的返回值类型。addFirst(E e)的返回值是void,为空。而offerFirst(E e)的返回值是boolean,也就是说插入成功返回true,否则返回false。
* 内存是有限的,如果内存不足,插入就失败。
*/
list2.offerFirst("springBoot");
list2.offerLast("flink");
// 获取第一个元素,如果是getFirst() 获取不到,会报异常,peekFirst 不会报异常,只会返回null
String s = list2.peekFirst();
// poolFirst 删除第一个元素,并返回该元素,跟removeFirst一个效果
System.out.println(list2.pollFirst());
System.out.println(list2);
}
}
3) 为什么ArrayList 查找快,增删慢,LinkedList 查找慢,增删快
ArrayList 底层是数组,如果想插入一个元素的话,需要挪动大部分的数组的元素,为插入的元素挪地方
LinkedList 底层是链表,链表之间的元素靠指针,双向指针,如果插入元素的话,只需要修改链表的指针位置即可。
二、如果比较两个引用数据类型是否相等
package com.qfedu.day11;
import java.util.ArrayList;
import java.util.List;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/15 9:58
* @Version 1.0
*/
public class Demo01 {
/*
例题:将各学科名字(java,python,python,iOS,bigdata)存入集合,注意名字里面有重复,要求使用List存储数据,但是数据不能重复
分析:List默认是有序可重复的---利用Contains
*/
public static void main(String[] args) {
// java,python,python,iOS,bigdata
String[] arr = "java,python,python,iOS,bigdata".split(",");
List<String> list = new ArrayList<>();
for (String str:arr) {
if(!list.contains(str)){
list.add(str);
}
}
System.out.println(list);
}
}
package com.qfedu.day11;
import java.util.ArrayList;
import java.util.List;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/15 9:58
* @Version 1.0
*/
public class Demo02 {
/*
Student 集合,集合中的元素不重复
我们需要重写Student 中 equals 和 hashCode 两个方法
equals 等于true 只能说明 内容相同
hashCode 相等只能说明 地址相同
所以比较两个对象是否相同 一般需要重写这两个方法。
*/
public static void main(String[] args) {
// java,python,python,iOS,bigdata
Student[] arr = {
new Student("张三",19),
new Student("张三",19),
new Student("李四",20),
new Student("李四",19),
};
List<Student> list = new ArrayList<>();
for (Student stu:arr) {
if(!list.contains(stu)){
list.add(stu);
}
}
System.out.println(list);
}
}
package com.qfedu.day11;
import java.util.Objects;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/15 10:03
* @Version 1.0
* 龙目 lombok
*/
public class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
// 比较两个对象的地址,地址都一样了,说明就是一个对象
if (this == o) return true;
// 如果比较的对象都是null,那肯定是false,
// 如果比较的数据类对象都不一样,那肯定是false Student Pig
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && name.equals(student.name);
}
@Override
public int hashCode() {
// hash 是一个算法,给定一个值,然后进行hash算法,得出一个值
// zhangsan+19 100028
// zhangsan+19 100028
// 有可能 lisi+20 100028
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
三、Collections 工具类
package com.qfedu.day11;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/15 11:36
* @Version 1.0
*/
public class CollectionDemo {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("我是first");
// 在一个集合中添加多个元素
Collections.addAll(list,"第二","第三");
System.out.println(list);
ArrayList<Integer> list1 = new ArrayList<>();
// Math.max()
Collections.addAll(list1,20,37,49,89,16);
System.out.println(Collections.max(list1));
System.out.println(Collections.max(list));
ArrayList<Student> list2 = new ArrayList<>();
Collections.addAll(list2,new Student("张三",19),
new Student("张三",19),
new Student("李四",20),
new Student("李四",19));
/**
* max(一个参数) 要求里面的实体类需要实现Comparable 接口才行
* max(两个参数的方法)
*
* 如果实体类继承了Comparable 接口,你也编写了Compartor比较器,以比较器的规则为准
*
*/
//System.out.println(Collections.max(list2));
System.out.println(Collections.min(list2, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge() ;
}
}));
System.out.println(Collections.min(list2, ( o1, o2) -> o1.getAge() - o2.getAge() ));
System.out.println(list1);
// 洗牌,将集合中的元素搞乱
//Collections.shuffle(list1);
System.out.println(list1);
// 对调两个位置上的元素,shuffle 方法调用了该方法
Collections.swap(list1,0,4);
// 反转整个集合中的元素
Collections.reverse(list1);
Collections.sort(list1);
System.out.println(list1);
System.out.println(list1);
System.out.println(list2);
// 洗牌,将集合中的元素搞乱
Collections.shuffle(list2);
System.out.println(list2);
// 需要排序的类,必须实现Comparable 接口
// Collections.sort(list2);
Collections.sort(list2,(o1,o2) -> o1.getAge()-o2.getAge());
System.out.println(list2);
// 二分查找 Arrays中出现过 针对的是有序的集合,查找某个元素,返回的是元素的下标
int search = Collections.binarySearch(list1, 89);
System.out.println(search);
ArrayList<Integer> list3 = new ArrayList<>();
System.out.println(list3.size());
Collections.addAll(list3,0,0,0,0,0,0);
/*
这个方法有要求: list3 中元素的个数必须大于等于 src 中元素的个数,否则报错
*/
Collections.copy(list3,list1);
System.out.println(list3);
Collections.fill(list3,100);
System.out.println(list3);
/*ArrayList<Integer> list4 = new ArrayList<>(5);
Collections.fill(list4,100);
System.out.println(list4);*/
ArrayList<Integer> list4 = new ArrayList<>(5);
System.out.println(list4.size());
// 在我们的java的世界中,ArrayList,HashSet,HashMap 都是现成不安全的,如果想转换安全的,这个算一个方式
List<Integer> synchronizedList = Collections.synchronizedList(list3);
}
}
四、常见的数据结构
1、数组
一段连续的空间,里面的元素基本上都是同一个类型,插入元素比较的慢
2、栈
类似于弹夹,先进后出,后进先出。
3、队列
类似于排队,先来的先处理,后来的后处理。 先进先出,后进后出。
4、链表
通过指针连接前面的元素和后面的元素,删除或者添加,只需要修改指针的方向即可,新增删除比较快。 元素之间的空间不是连续的。<br />
5、树(Tree)
树是典型的非线性结构,它是包括,2个结点的有穷集合K。在树结构中,有且仅有一个根结点,该结点没有前驱结点。在树结构中的其他结点都有且仅有一个前驱结点,而且可以有两个后继结点,m≥0。 <br />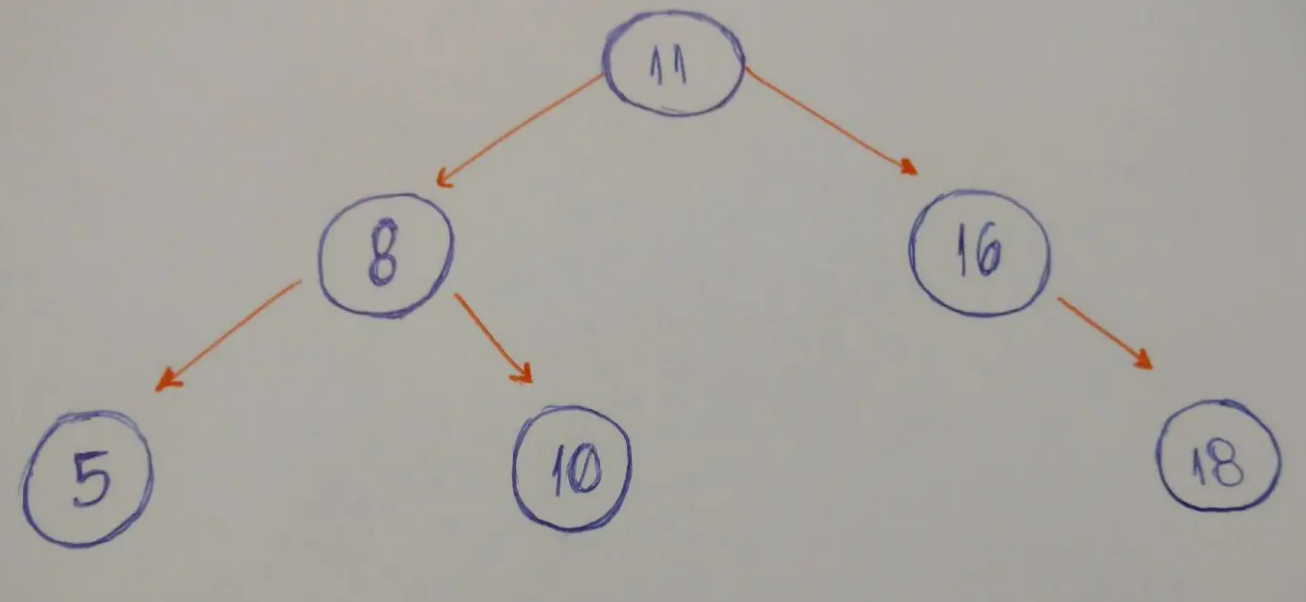<br />树的高度(深度)指的是从根节点到后面的叶子节点的层级。<br />MySQL 中的索引的实现,跟树有关系。
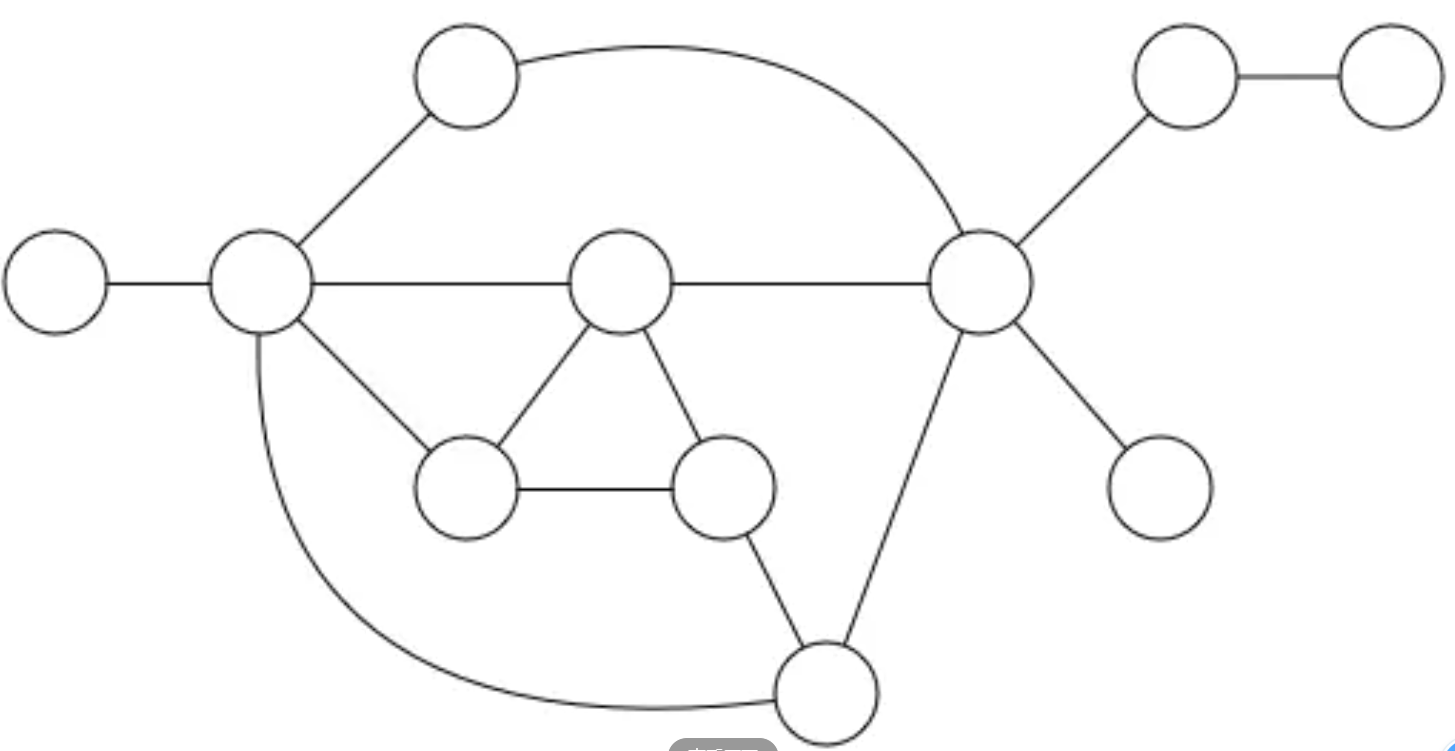
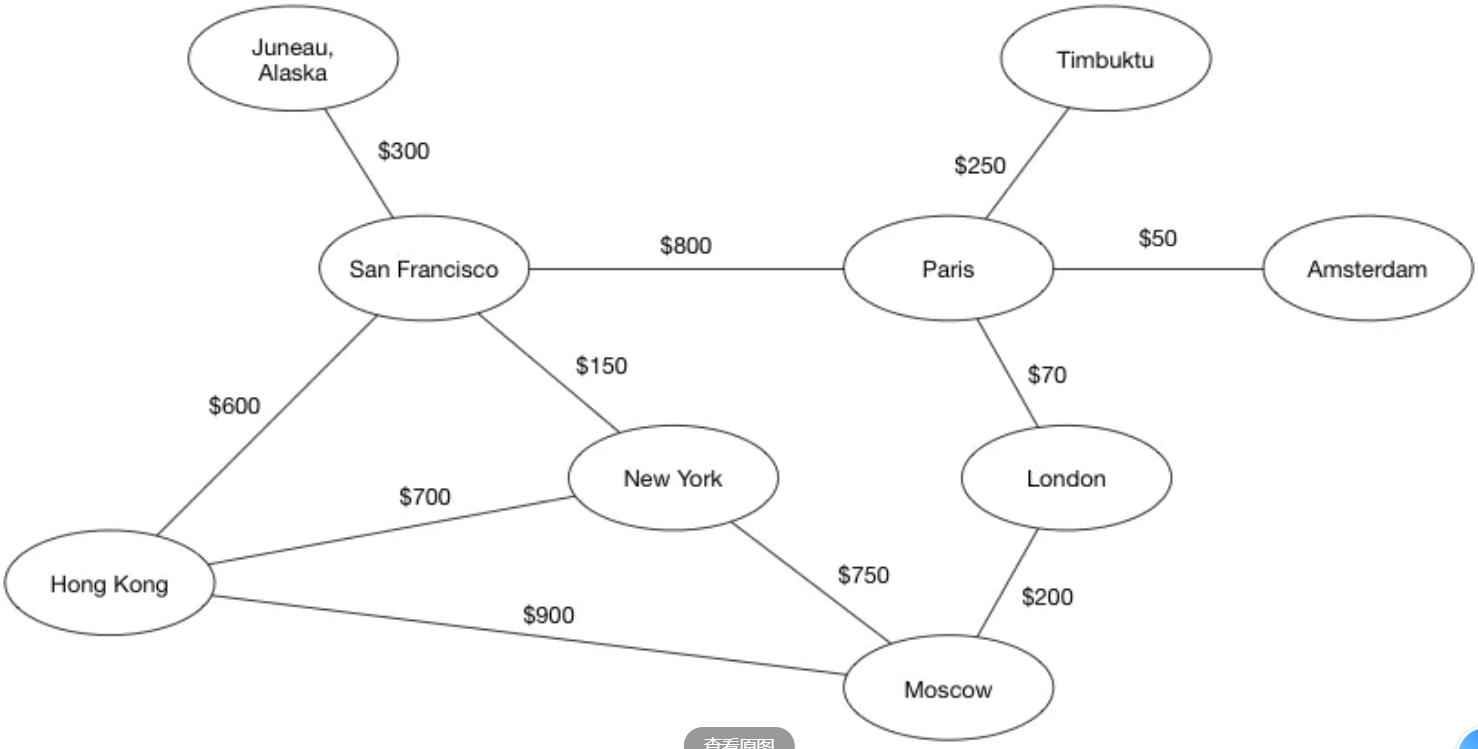
6、图(Graph)
7、堆(Heap)
堆就是使用数组表示的二叉树,空间使用上要比二叉树小,因为里面不放指针的数据。
堆属性分为—最大堆,最小堆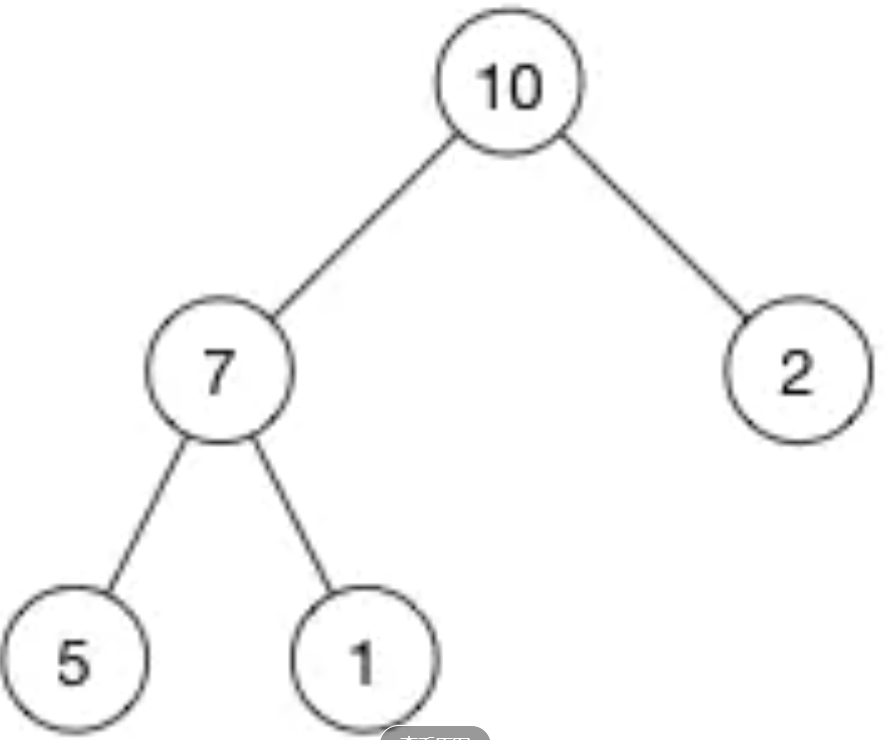
以上表示的就是最大堆,每个子节点都比父节点小。
8) 散列表(Hash)
散列表源自于散列函数(Hash function),其思想是如果在结构中存在关键字和T相等的记录,那么必定在F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。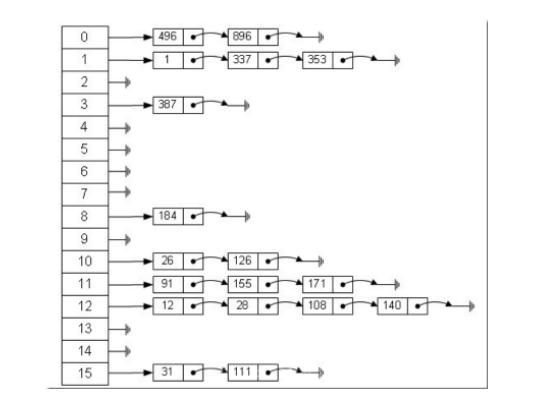
比如: 12 数字对16取余 = 12
28 对16取余 == 12
108、140 都是对16取余 == 12
所谓的 0 ~ 15 可以看做是16个桶,每个桶里面可以有多个数据,他们都是经过hash算法的出来的相同结果的数据。
五、Set
1) 无序,不可重复
2) HashSet 是最常见的Set集合的实现类,HashSet:底层是哈希表,线程不安全的
3) 初识:HashSet
package com.qfedu.day11_02;
import com.qfedu.day11.Student;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/3/15 16:11
* @Version 1.0
*/
public class Demo01 {
/**
* Set 集合: 无序,不可重复
* List 集合: 有序,可重复
* @param args
*/
public static void main(String[] args) {
// HashSet 是 Set集合中使用频率最高的实现类
Set<String> set = new HashSet<>();
set.add("java");
set.add("java");
set.add("python");
System.out.println(set);
for (String str:set) {
System.out.println(str);
}
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
Set<Student> set2 = new HashSet<>();
/**
* HashSet 中的元素是如何虑重的?
* 1、Hashset 中底层是 hash表
* 2、需要添加某个元素的时候,需要判断该元素在hash表中是否存在,如果存在,添加失败
* 3、我们会拿到这个元素的hashCode 值,然后在hash表中查找
*/
set2.add(new Student("zhangsan",19));
set2.add(new Student("zhangsan",20));
set2.add(new Student("lisi",19));
set2.add(new Student("zhangsan",20));
System.out.println(set2);
}
}
4) 虑重规则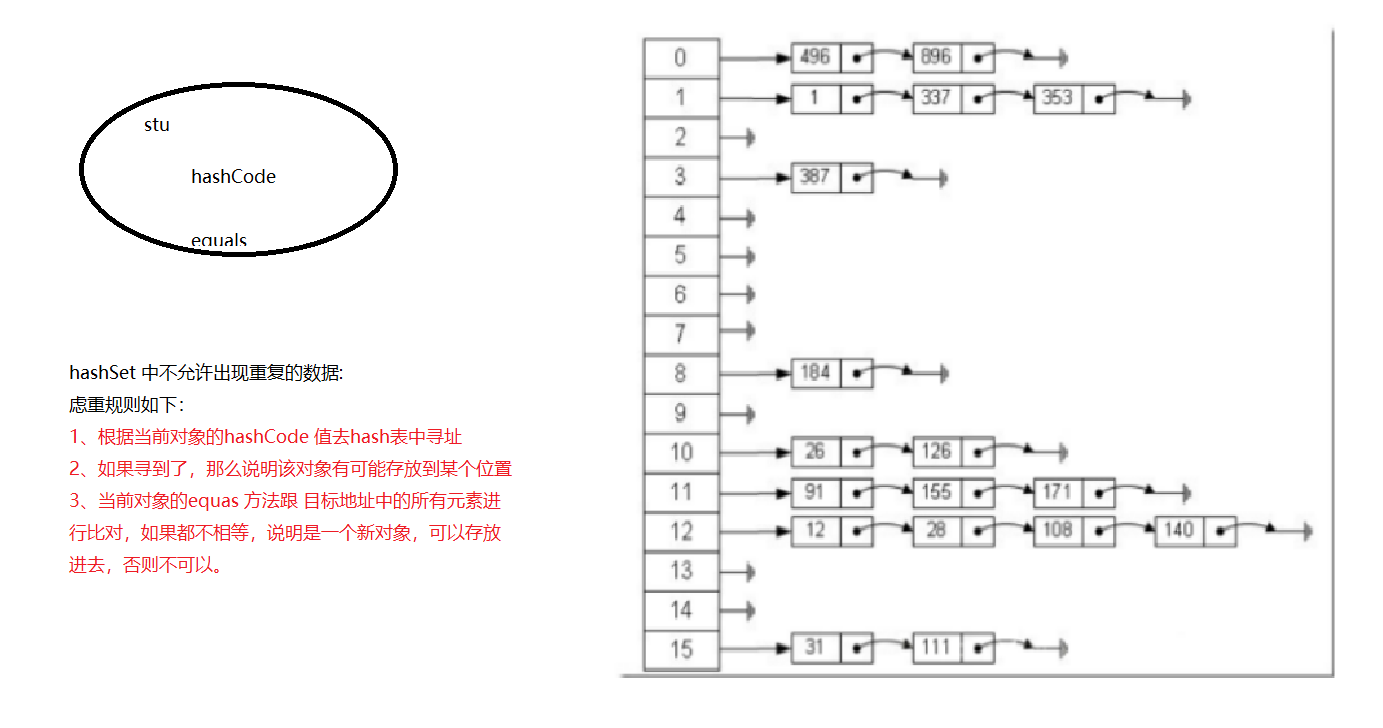
5) 扩容规则:
可是当哈希表接近装满时,因为数组的扩容问题,性能较低(转移到更大的哈希表中).
Java默认的散列单元大小全部都是2的幂,初始值为16(2的4次幂)。假如16条链表中的75%链接有数据的时候,则认为加载因子达到默认的0.75。HahSet开始重新散列,也就是将原来的散列结构全部抛弃,重新开辟一个散列单元大小为32(2的5次幂)的散列结果,并重新计算各个数据的存储位置。以此类推下去.....
负载(加载)因子:0.75.-->hash表提供的空间是16 也就是说当到达12的时候就扩容
哈希表的插入和查找是很优秀的。
6) TreeSet — 底层是二叉树,是有序的不可重复的集合。作用仅次于HashSet.
7) 排序 Comparable【系统排序】 和 Compartor 【人工排序】
当一个类实现网络Comparable 接口,同时,在调用某个方法的时候,又编写了Compartor 接口的实现类,以Compartor 为准。
8) 面试题: TreeSet、HashSet、LinkedHashSet 的区别。

若有收获,就点个赞吧
0 人点赞
