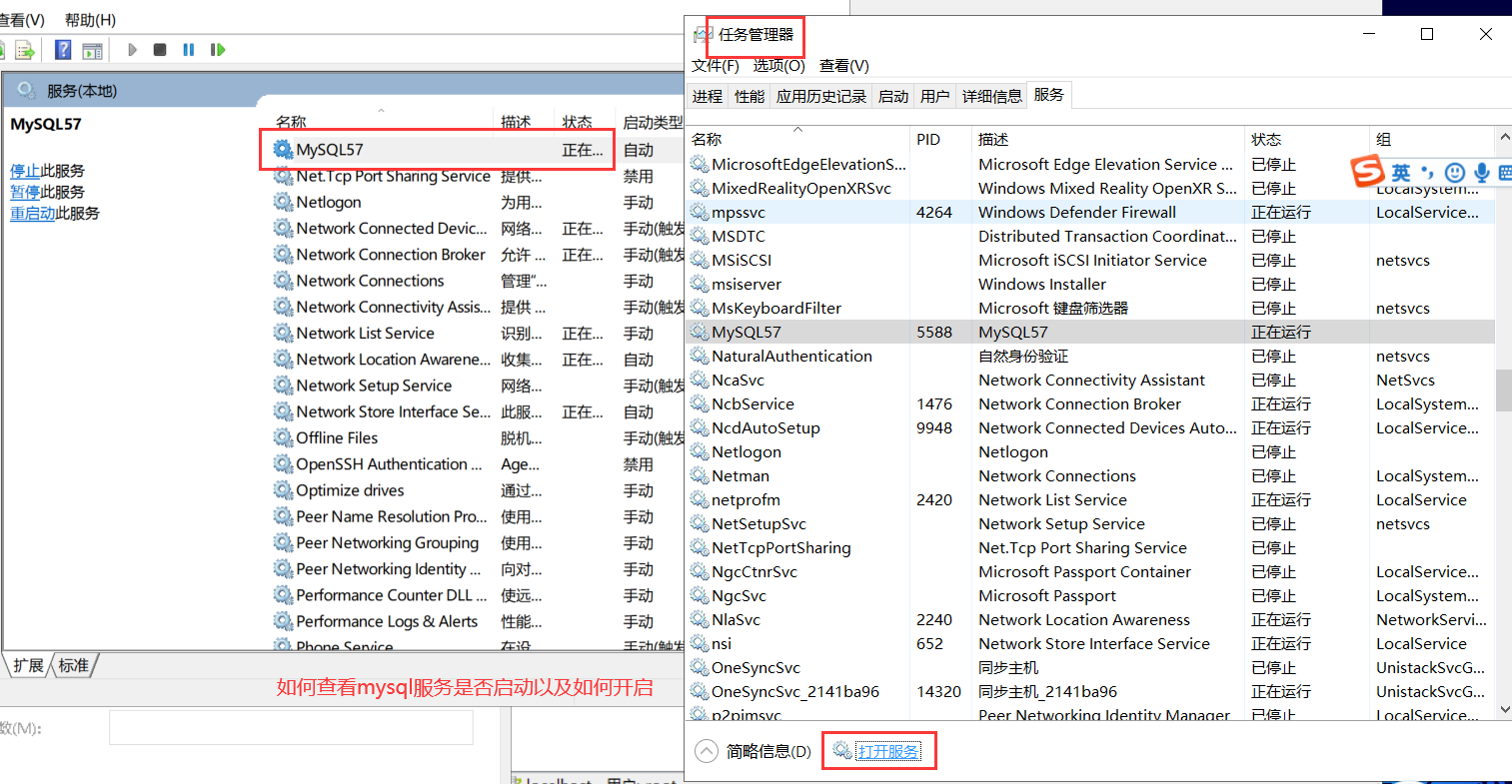
一、查看服务开启状态
二、关于列的操作
1、列之间可以计算
2、可以给列起别名
3、结果可以排序 order by 列值 (desc|asc);
4、聚合函数
以下这些函数可以作用在列上,都是函数(数据库自带的)
max() min() count() sum() avg()
// 求所有员工最高的工资是多少select max(sal) from emp;// 求最小值select min(sal) from emp;// 求员工的数量或者说emp表中有多少条数据select count(sal) from emp; // 14select count(comm) from emp; // 4条count(字段) 如果该字段为null,其实是不进行统计的。// 为了避免出现以上情况,我们一般做数据的条数统计,不适用具体的字段select count(*) from emp;或者select count(1) from emp;// 求所有员工的薪水总和不包含奖金select sum(sal) from emp;// 求所有员工的薪水总和包含奖金select sum(sal+comm) from emp; // 7800 不合理select sum(sal+IFNULL(comm,0)) from emp; // 统计结果正常,但是不好看select sum(sal+IFNULL(comm,0)) as 总薪水 from emp;// 求员工的平均工资select avg(sal) from emp;
5、分组查询
分组查询的查询字段只能是分组字段以及聚合函数,其他的不行。
查询一个部分的编号以及这个部门的最高工资(sal)
select deptno,max(sal) from emp group by deptno;
查询每一个工作的名字以及该工作的人数
select job,count(1) from emp group by job;
查询每一个部门,每一个工作 的人数
select deptno,job,count(1) from emp group by deptno,job;
// 写成这个样子可以吗?
// 每一个工作进行分组,再按照部门进行分组
select deptno,job,count(1) from emp group by job,deptno;


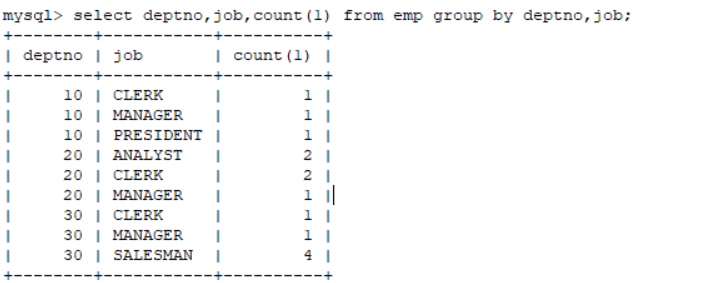
分组查询中也可以进行条件过滤。
having : 条件过滤 ,一般跟group by 一起使用,放在group by 后面,表示对分组过后的数据进行过滤。
where: 条件过滤,一般是对所有数据进行过滤的。跟分组没有关系。
having 后面可以使用聚合函数,但是where 条件后面不能使用聚合函数(说的是聚合不是所有函数)
// 查询平均工资高于3000的部分编号以及平均工资
// 先按照部分进行分组,再求每个部门的平均工资,平均工资大于3000,信息打印出来
select deptno,avg(sal) from emp group by deptno having avg(sal)>3000;
// 先分组
select deptno,avg(sal) from emp group by deptno;
再通过having 关键字进行过滤
select deptno,avg(sal) from emp group by deptno having avg(sal)>2500;
6、分页查询 limit
查询emp表中的前五条数据:
select * from emp limit 0,5; // 从第一条数据开始查,查询5条
// 从第10条数据开始查询,查询7条
select * from emp limit 10,7;
limit后面可以跟两个参数,中间用逗号隔开,第一个参数代表开始的位置,第二个参数表示查询的条数。
简写:
select * from emp limit 5;// 表示从开始位置开始查询,查询5条的意思。
7、SQL语句的查询顺序
书写顺序:
select ... from 表名 where .... group by ... having ... order by ... limit ...
执行的顺序:
from ... where .... group by ... having... select ... order by limit
三、数据完整性【基础】
1、概念
数据在创建的时候需要符合一定的逻辑,比如主键不能重复,关键字段不能为null.<br /> 分为:实体完整性,域完整性以及引用完整性
2、实体完整性
数据库中的一行数据,就成为实体,比如student 表一行数据就代表一个学生,那么学生就是实体。<br /> 保障我们每一行数据不能重复。<br />1) 唯一约束 unique ,可以修饰一个字段,该字段在表中,不能重复,比如手机号,身份证号。
// 为了保证id 数据不重复,可以添加unique
create table student(
id int(11) unique,
sname varchar(18)
);
insert into student(id,sname) values(1,'zhangsan');
insert into student(id,sname) values(1,'李四');
// 报错:
Duplicate entry '1' for key 'id'
或者这样写:
create table student2(
id int(11),
sname varchar(18),
unique(id)
);
以上是建表的时候指定的,万一我建表的时候忘记了,后来追加怎么办?
create table student3(
id int(11),
sname varchar(18)
);
alter table student3 add unique(id);
// 这个场景怎么处理? 唯一性不是指的一个字段,而是多个字段?
姓名相同并且年龄相同,我认为是是一个人。
可以使用联合唯一约束:
create table student4(
age int(11),
sname varchar(18),
unique(age,sname)
);
// 在数据库中只有年龄和姓名都一样,才插入不进去,否则不是重复数据
insert into student4(age,sname) values(18,'zhangsan');
insert into student4(age,sname) values(18,'李四');
insert into student4(age,sname) values(19,'zhangsan');
insert into student4(age,sname) values(19,'zhangsan');// 失败
2) 主键约束
关键字:primary key
为了保障数据的唯一性,我们会给每一个数据一个标识,这个标识就是主键。
跟unique 有啥区别: 主键使用这个关键字primary key,它就标识唯一。
普通字段使用unique ,标识该字段不能重复。
create table student5(
id int(11) primary key,
sname varchar(18)
);
insert into student5(id,sname) values(1,'zs');
insert into student5(id,sname) values(1,'lisi');// 报错,主键冲突
// Duplicate entry '1' for key 'PRIMARY'
啥是主键? 主键就是一个不可以重复的字段,该字段没有任何的其他意义,就是不能重复而已,一般字段名字为id,int类型。
每一表几乎都有主键,如果没有,每次打开表都会警告!!!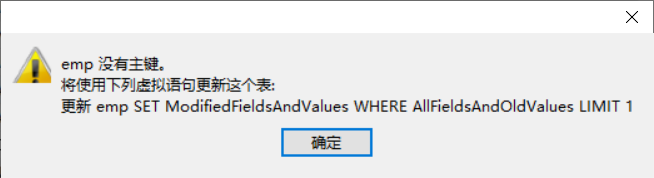
如果我创建表的时候没有加主键,如何追加呢?
alter table student5 add primary key (id);
创建表的时候也可以指定主键:
create table student5(
id int(11) ,
sname varchar(18),
primary key(id)
);
// 以上写法比较好,因为他可以设置联合主键
create table student5(
id int(11) ,
sname varchar(18),
primary key(id,sname)
);
// 插入数据的时候,只有id和sname 都重复,才会插入失败。
主键的插入:
insert into student6(id,sname) values(1,'zs');
因为id是主键,我们认为的进行设置插入值,总会碰到主键重复的异常,能不能让其自己自动增长,我们无需管理呢?
答案是肯定的:主键自增
create table student7(
id int(11) auto_increment,
sname varchar(18),
primary key(id)
);
insert into student7(sname) values('zs');
特别需要注意的是:只有主键是数值类型,才能够设置自增,比如不能让varchar 类型自增。
当我删除一个数据后,再次插入数据,顺序是不会倒回去的。我们的数据库中有一个计数器,用于计算当前的id到多少了,不管你的数据是删除了多少条,或者id是多少,每次都从它记录的那个数字开始继续往后推算。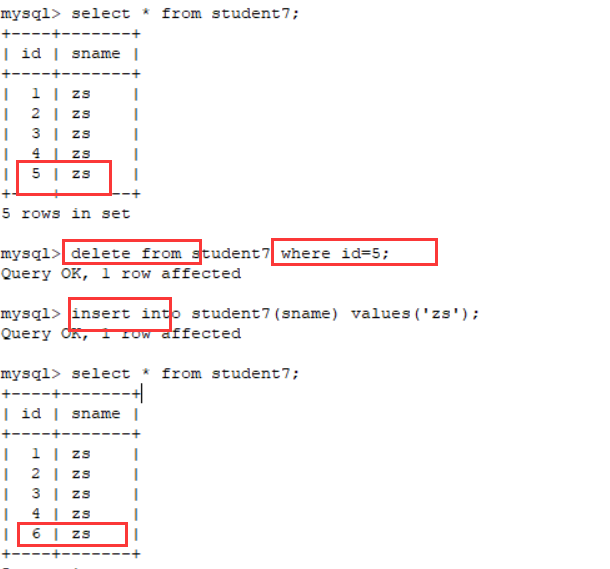
我们每一次创建主键的时候都是 primary key auto_increment
3、域完整性
一条记录是一个实体,实体之间不能重复,实体中有很多的字段,每个字段就称之为域。
1) 非空约束
默认的字段都是null,如果你不想让别人插入null值。
关键字 not null
create table student7(
id int(11) primary key auto_increment,
sname varchar(18),
phone varchar(11) not null
);
insert into student8(sname,phone) values('zs',null); // 失败的
//Column 'phone' cannot be null
insert into student8(sname,phone) values('zs','18137884467');// 成功的
以后主键就这样写:
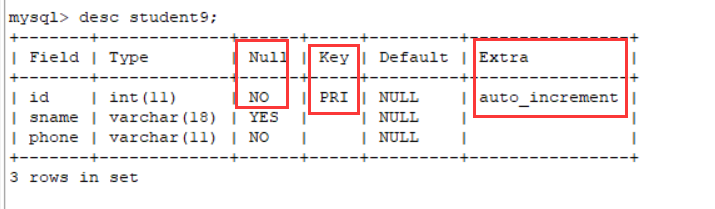
create table student9(
id int(11) primary key auto_increment not null,
sname varchar(18),
phone varchar(11) not null
);
2)默认值约束 default
create table student10(
id int(11) primary key auto_increment not null,
sname varchar(18) default '未起名' ,
phone varchar(11) not null default '100000000',
gender char(1) default '男'
);
insert into student10(phone) values('18137884406');
关于插入数据的问题:
1、插入SQL有两种写法:
insert into student10(id,sname,phone,gender) values(100,'张三','123212312','女');
如果一个表中插入数据的话,所有字段你都给了值,可以简写:
insert into student10 values(100,'张三','123212312','女');
如果写成这个样子:
insert into student10 values('张三','女'); 就是错误的。
因为你表名后面没有指定列,意味着所有的值都要给定才行,否则报:
Column count doesn't match value count at row 1
2、如果你就想给某些列插入值,其他列不管,可以写成如下方式:
insert into student10(phone) values('18137884406');
以上这个SQL语句只是插入一条数据:只给定了手机号的值,其他值都是默认值。
3) 检查约束(了解一下)
check 可以规定某个列的值只能是什么,其他的不管用。新版本的mysql才支持。
create table student11(
id int(11) primary key auto_increment not null,
sname varchar(18) default '未起名' ,
phone varchar(11) not null default '100000000',
gender char(1) check(gender in ('f','m'))
);
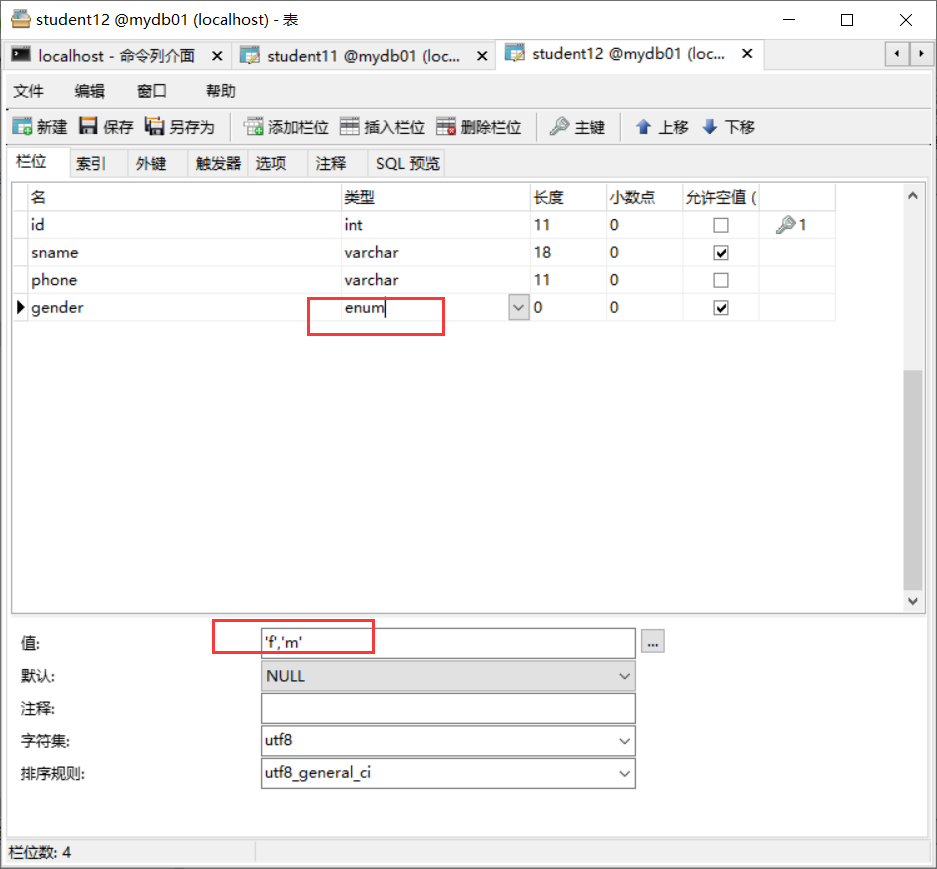
以上的写法,可以写成枚举:
create table student12(
id int(11) primary key auto_increment not null,
sname varchar(18) default '未起名' ,
phone varchar(11) not null default '100000000',
gender enum('f','m')
);
insert into student12 values(104,'张三','123212312','f');//可以插入
insert into student12 values(104,'张三','123212312','男'); // 不可以,因为gender 只能是 f 或 m
4、引用完整性
引用完整性就是外键。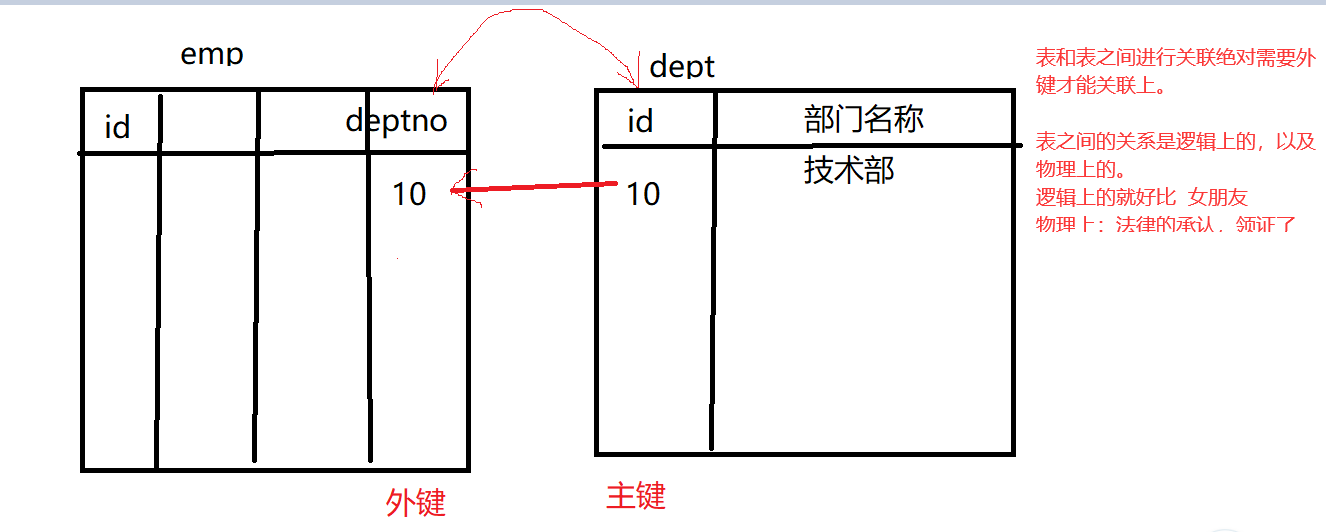
新建两个表xuesheng 表 ,laoshi表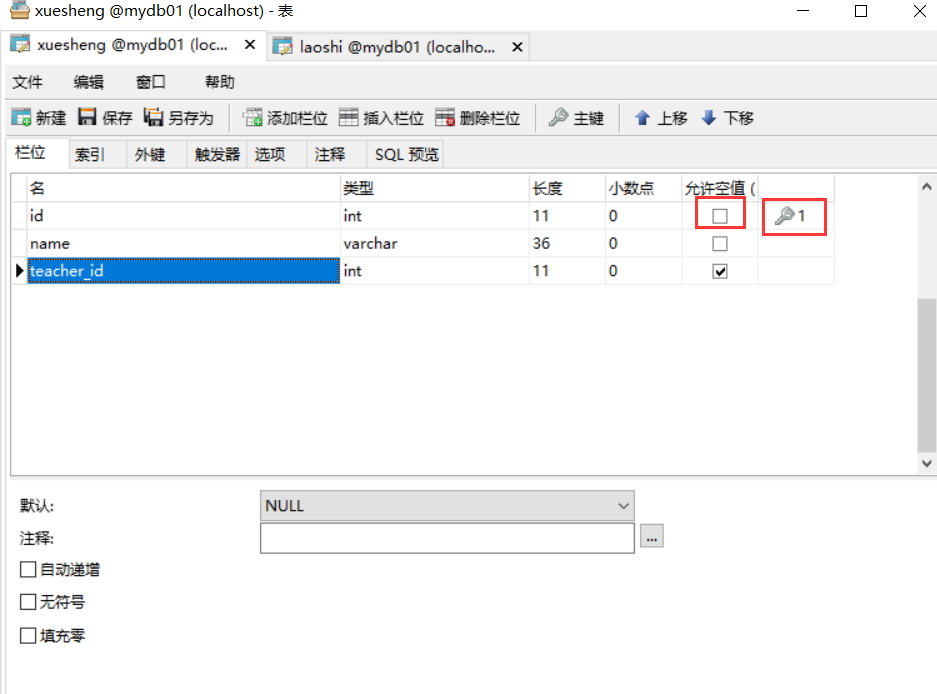
以上创建的方式,只是分析的两个表之间有关系,学生表中的teacher_id 是 老师表中的id. —逻辑上的关系,不是一种强制的措施。
如果你想加强这样的关系,就指定外键关联。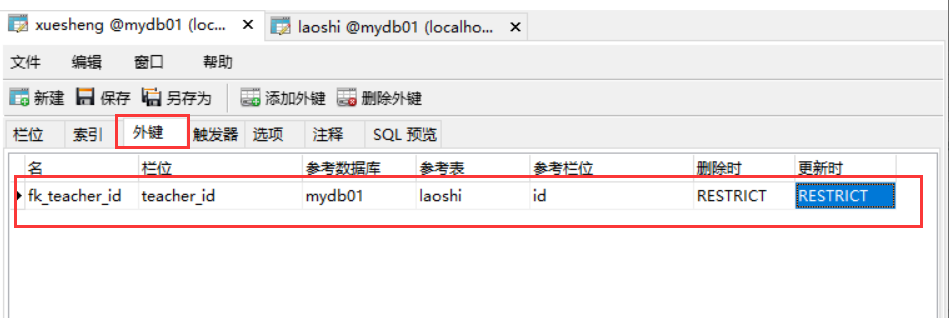
以上这种做法就是引用完整性。一般在企业中,不用。太死板,不利于数据的迁移。
比如我们去操作学生表,还要考虑老师表是否先进行操作,如果不考虑,就会这也错,那也错。
四、多表查询
1、笛卡尔集
select from emp,dept;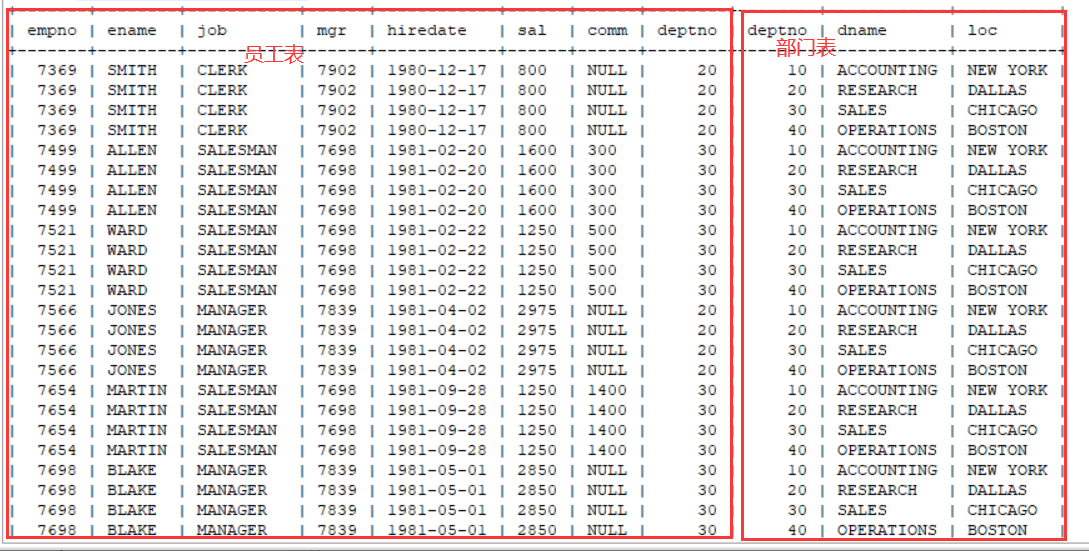
总共是56条数据,其中我们的员工表emp 14条数据,dept 是 4条数据 14 4 = 56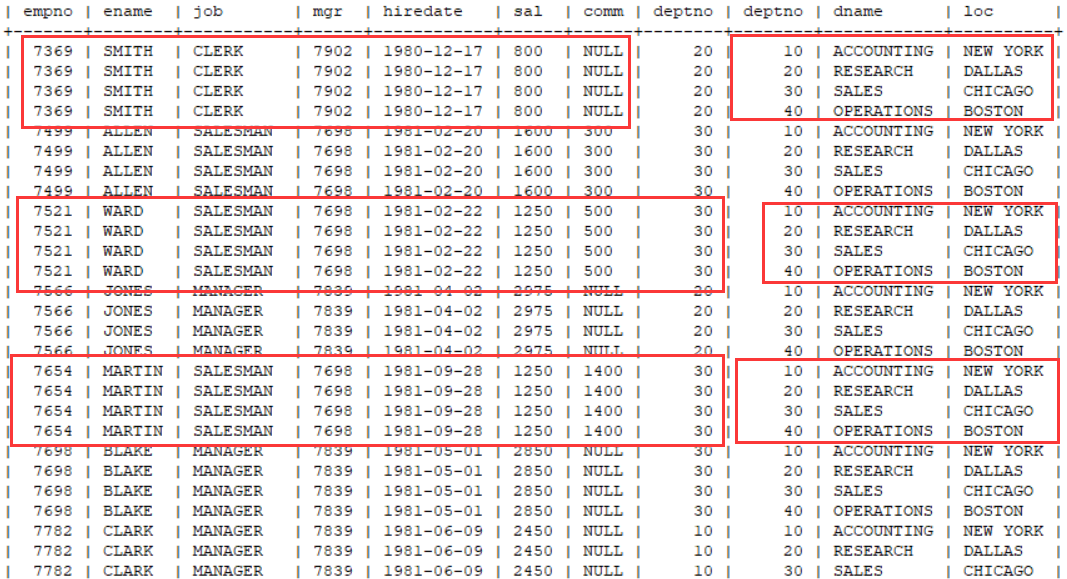
根据以上的图,发现一个员工和4个部门都产生了一条数据,14 个员工分别和 4 个部门都产生一遍数据 14 * 4 = 56.
这种现象就是笛卡尔集。笛卡尔集没有任何意义。
比如,有这样一个需求:查询每个员工的信息以及所在部门的部门名称。
select * from emp,dept where emp.deptno = dept.deptno;
进行表数据查询的时候,我们只需要在笛卡尔集中过滤掉不必须要的数据就是我们想要的数据。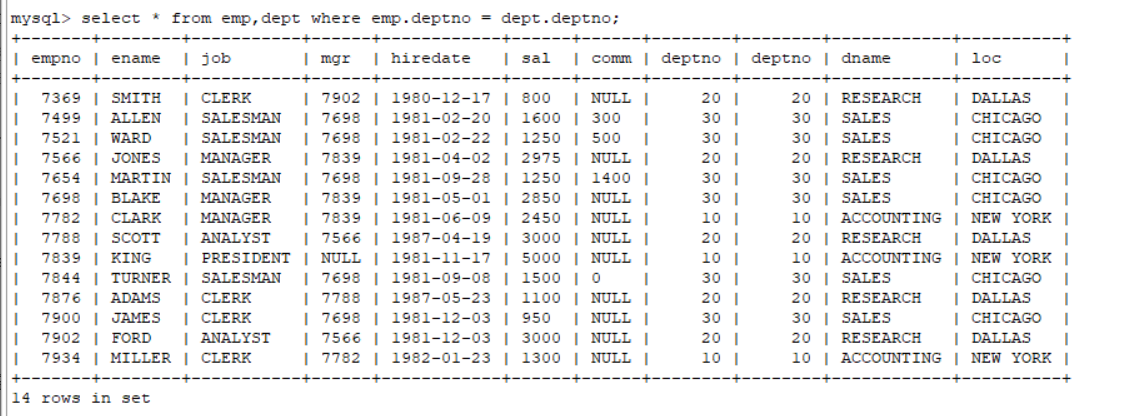
我们的SQL语句是有标准的,
以上这种:
select * from emp,dept where emp.deptno = dept.deptno;
属于mysql 的方言,不属于标准的写法。
以上写法是内关联查询的一种,标准的写法:
select * from emp inner join dept on emp.deptno = dept.deptno;
查询按照内外连接可以分为:
内连接、外连接(左外连接和右外连接),全连接(mysql不支持)
1)内连接
内连接是通过 inner join 进行连接的表示方式。inner可以省略
// 查询员工的编号,职位,入职日期以及部门编号和部门名称
select empno,job,hiredate,deptno,dname from emp inner join dept on emp.deptno = dept.deptno;
// 以上SQL有异常:
Column 'deptno' in field list is ambiguous 意思是deptno 员工表和部门表都有这个字段,你要展示哪一个
// 需要在deptno 前面加 表名
select empno,job,hiredate,emp.deptno,dname from emp inner join dept on emp.deptno = dept.deptno;
// 还可以这么写:通过起别名简化
select empno,job,hiredate,e.deptno,dname from emp e inner join dept d on e.deptno = d.deptno;
// 还可以这么搞:
// 展示员工的所有信息,以及部门信息中的名字
select e.*,d.dname from emp e inner join dept d on e.deptno = d.deptno;
2) 外连接(左外连接以及右外连接)
语法: left / right outer join outer 可以省略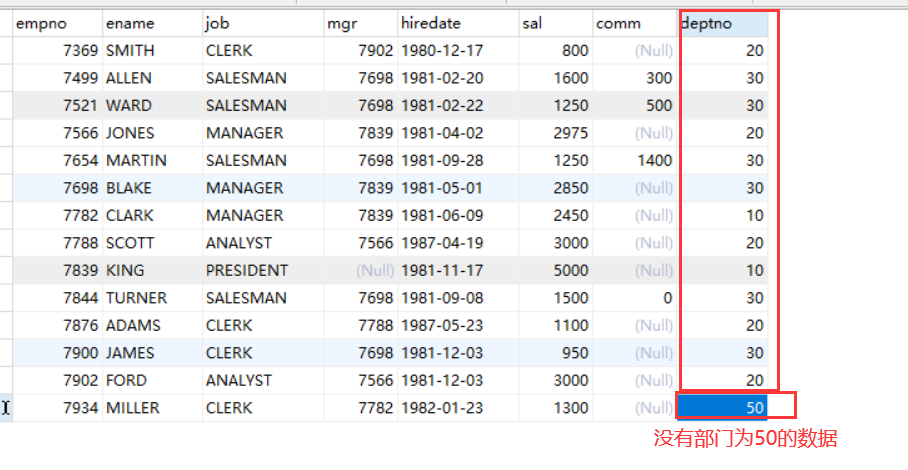
查询所有员工的数据,以及部门信息
select e.*,d.dname from emp e join dept d on e.deptno = d.deptno;
查询的结果发现: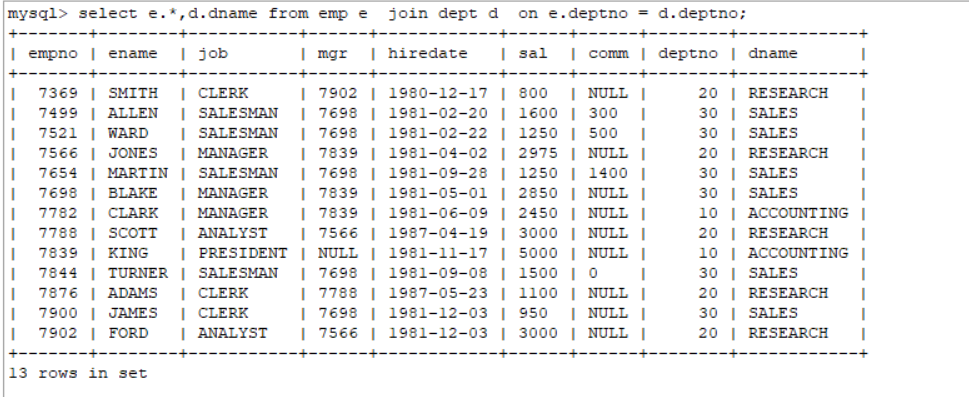
我有14个员工,但是查询出来玩了13数据,有一个员工因为没有对应的部门,就不展示他的基本信息,这种做法不满足题目要求。
应该是所有员工都必须展示,没有关联上的部门信息可以显示为null
就需要使用外连接了。
select * from emp e left outer join dept d on e.deptno=d.deptno;
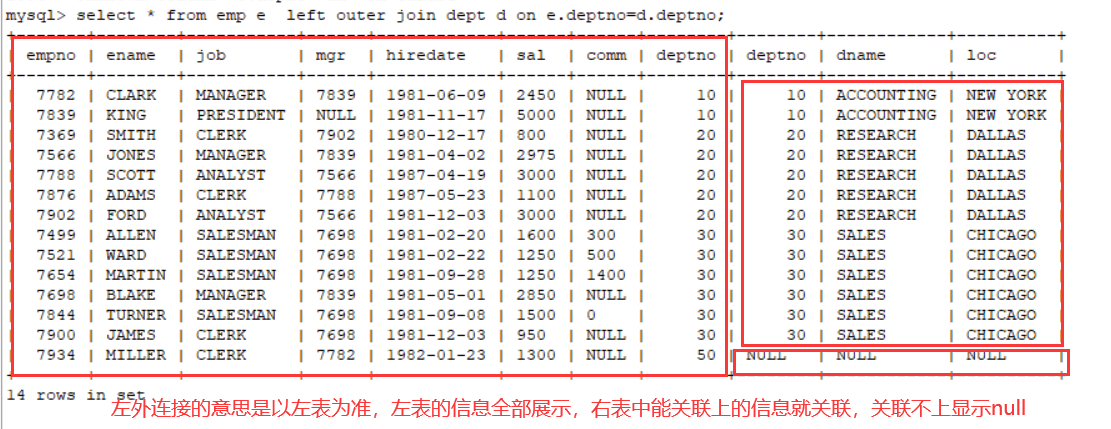
会左外连接就会右外连接,因为右外连接的意思是以右表为准,右表中的所有数据全部展示,关联不上的,左表显示null
select * from dept d right outer join emp e on e.deptno = d.deptno;
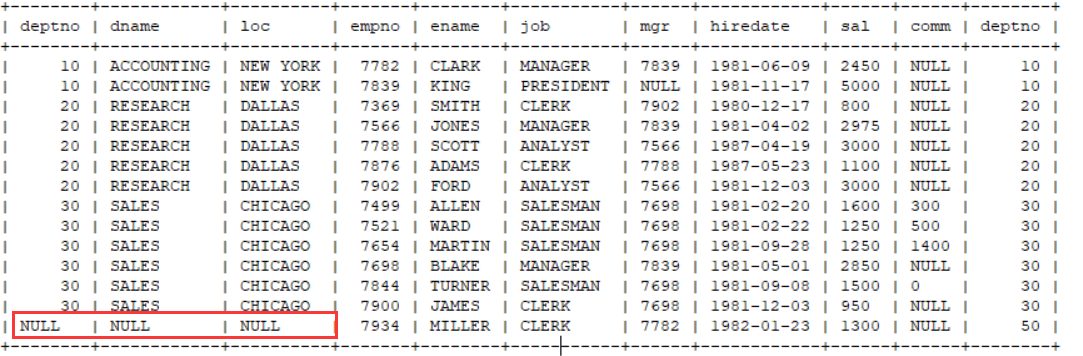
所有的右外连接都可以写成左外连接,所以我们经常使用左外比较多。
创建emp的SQL:
CREATE TABLE emp(
empno INT,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
);
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
创建dept的SQL:
CREATE TABLE dept(
deptno INT,
dname varchar(14),
loc varchar(13)
);
INSERT INTO dept values(10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept values(20, 'RESEARCH', 'DALLAS');
INSERT INTO dept values(30, 'SALES', 'CHICAGO');
INSERT INTO dept values(40, 'OPERATIONS', 'BOSTON');

若有收获,就点个赞吧
0 人点赞
