错误和异常
编写计算机程序时,通常能够区分正常和异常(不正常)情况。异常事件可能是错误(如试图除以零),也可能是通常不会发生的事情。为处理这些异常事件,可在每个可能发生这些事件的地方都使用条件语句。例如,对于每个除法运算,都检查除数是否为零。然而,这样做不仅效率低下、缺乏灵活性,还可能导致程序难以卒读。你可能很想忽略这些异常事件,希望它们不会发生,但Python提供功能强大的替代解决方案——异常处理机制。
一、错误分类
程序中难免出现错误,而错误类型分为两种
1.1 语法错误
这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正
#语法错误示范一if#语法错误示范二def test:pass#语法错误示范三print(haha#语法错误
1.2 逻辑错误
#用户输入不完整(比如输入为空)或者输入非法(输入不是数字)num=input(">>: ")int(num)#无法完成计算res1=1/0res2=1+'str'# 没有此键值对dic = {"key": 222}dic[1]# 超出索引范围l1 = [1, 2, 3]l1[100]
异常就是程序运行时发生错误的信号,在python中,错误触发的异常如下
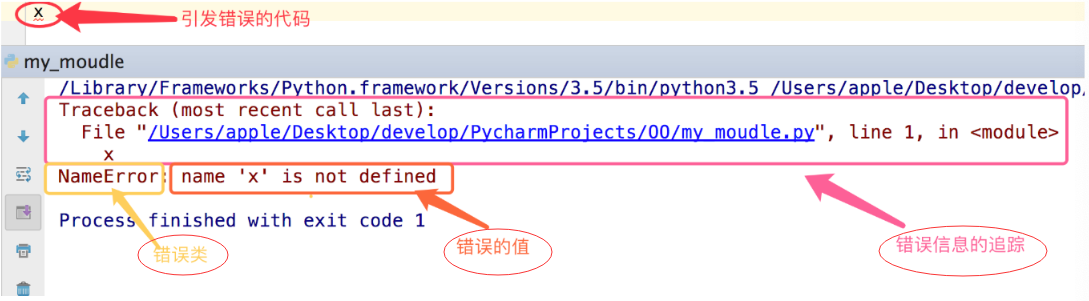
二、异常
Python使用异常对象来表示异常状态,并在遇到错误时引发异常。异常对象未被处理(或捕 获)时,程序将终止并显示一条错误消息(traceback)。
>>> 1 / 0Traceback (most recent call last):File "<stdin>", line 1, in ?ZeroDivisionError: integer division or modulo by zero
如果异常只能用来显示错误消息,就没多大意思了。但事实上,每个异常都是某个类(这里是ZeroDivisionError)的实例。你能以各种方式引发和捕获这些实例,从而逮住错误并采取措施,而不是放任整个程序失败。
2.1 常见异常
除了ZeroDivisionError异常外,Python中还有很多异常,下面是一些常见的错误:
AttributeError #试图访问一个类中不存在的成员(包括:成员变量、属性和成员方法)而引发的异常IOError #输入/输出异常;基本上是无法打开文件ImportError #无法导入模块或包;基本上是路径问题或名称错误IndentationError #语法错误(的子类);代码没有正确对齐IndexError #下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]KeyError #试图访问字典里不存在的keyKeyboardInterrupt #Ctrl+C被按下NameError #使用一个还未被赋予对象的变量SyntaxError Python #代码非法,代码不能编译(个人认为这是语法错误,写错了)TypeError #传入对象类型与要求的不符合UnboundLocalError # 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,#导致你以为正在访问它ValueError #传入一个调用者不期望的值,即使值的类型是正确的MemoryError #内存错误,内存不足
2.2 什么是异常处理
- python解释器检测到错误,触发异常(也允许程序员自己触发异常)
- 程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
- 如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理
2.3 为什么要有异常处理
python解析器去执行程序,检测到了一个错误时,触发异常,异常触发后且没被处理的情况下,程序就在当前异常处终止,后面的代码不会运行,谁会去用一个运行着突然就崩溃的软件。所以你必须提供一种异常处理机制来增强你程序的健壮性与容错性 。
2.4 常用的异常处理的方式
其实我们之前已经使用过一种异常处理的方式了,那就是条件判断语句if
num1=input('>>: ') #输入一个字符串试试int(num1)num1=input('>>: ') #输入一个字符串试试if num1.isdigit():int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴elif num1.isspace():print('输入的是空格,就执行我这里的逻辑')elif len(num1) == 0:print('输入的是空,就执行我这里的逻辑')else:print('其他情情况,执行我这里的逻辑')'''问题一:使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂问题二:这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。'''#使用if判断进行异常处理
总结:
- if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理。
- 在你的程序中频繁的写与程序本身无关,与异常处理有关的if,会使得你的代码可读性极其的差
- if是可以解决异常的,只是存在以上的问题,所以,千万不要妄下定论if不能用来异常处理。
你之前使用的异常处理机制:
def test():print('test running')choice_dic={'1':test}while True:choice=input('>>: ').strip()if not choice or choice not in choice_dic:continue #这便是一种异常处理机制啊choice_dic[choice]()#你之前用的异常处理机制
2.4.1 基本语法
try:被检测的代码块except 异常类型:try中一旦检测到异常,就执行这个位置的逻辑
2.4.2 异常类只能用来处理指定异常情况
# 未捕获到异常,程序直接报错s1 = 'hello'try:int(s1)except IndexError as e: #通过别名输出异常的具体内容print e
2.4.3 单分支
只能处理单个异常,只要检测出ValueError的错误,不让程序中断,立马跳转到except语句,实现程序分流的效果。
try:int(input('>>>'))except ValueError:print('必须输入数字。。。')print(111)
2.4.4 多分支
代码尝试运行try下面的代码,从上至下依次运行,只要出现了逻辑错误即异常,马上跳转到except语句,从上至下依次匹配错误类型,匹配成功,程序跳转,否则报错。
s1 = 'hello'try:int(s1)dic = {"name": 'taibai'}dic[1]l1 = [1, 2, 3]l1[100]except IndexError as e:print(e)except KeyError as e:print(e)except ValueError as e:print(e)
2.4.5 万能异常
可以捕获python给你提供的所有异常错误类型。
s1 = 'hello'try:int(s1)except Exception as e:print(e)
你可能会说既然有万能异常,那么我直接用上面的这种形式就好了,其他异常可以忽略
你说的没错,但是应该分两种情况去看
- 如果你想要的效果是,无论出现什么异常,我们统一丢弃,或者使用同一段代码逻辑去处理他们,那么骚年,大胆的去做吧,只有一个Exception就足够了。
s1 = 'hello'try:int(s1)except Exception,e:'丢弃或者执行其他逻辑'print(e)#如果你统一用Exception,没错,是可以捕捉所有异常,但意味着你在处理所有异常时都使用同一个逻辑去处理(这里说的逻辑即当前expect下面跟的代码块)
- 如果你想要的效果是,对于不同的异常我们需要定制不同的处理逻辑,那就需要用到多分支了。
s1 = 'hello'try:int(s1)except IndexError as e:print(e)except KeyError as e:print(e)except ValueError as e:print(e)#多分支
2.4.6 多分支+万能异常
还有一种是多分支+万能异常的处理情况,发生的异常中,有一些异常是需要不同的逻辑处理的,剩下的异常统一处理掉即可,无需进一步判断或者研究,这样的情况下,这种异常处理是最好的方式。
实战项目应用举例:
dic = {1: login,2: register,3: dariy,4: article,5: comment,}print('''欢迎访问博客园系统:1,登录2,注册3,访问日记页面4,访问文章页面5,访问评论页面''')try:choice = int(input('请输入:'))dic[choice]()# if choice.isdigit():# if## else:# print('请输入数字...')except ValueError:print('请输入数字....')except KeyError:print('您输入的选项超出范围...')except Exception as e:print(e)
2.4.7 异常处理其他功能
异常处理除了常用了try和except组合之外,还有一些其他的组合,我们先整体看一下:
s1 = 'hello'try:int(s1)except IndexError as e:print(e)except KeyError as e:print(e)except ValueError as e:print(e)#except Exception as e:# print(e)else:print('try内代码块没有异常则执行我')finally:print('无论异常与否,都会执行该模块,通常是进行清理工作')
- try…except…else组合
与循环中的else比较类似,try代码中,只要出现了异常,则不会执行else语句,如果不出现异常,则执行else语句。
比如我们完成一个转账功能的代码,需要一个转账给另一个人,然后另一个人确认收到才算是转账成功,我们用伪代码写一下,他就可以用在这个地方:
# 伪代码try:print('扣第一个人钱')...print('给第二个人加钱')except ValueError:print('必须输入数字。。。')else:print('转账成功')
- try…excet…finally组合
finally这个用法比较有意思,他是在捕获异常发生之前,先执行finally的代码,有点未卜先知的意思。
- 如果出现异常并且成功捕获了,finally会在try中最后执行。
``` try: dic = {‘name’: ‘太白金星’} print(dic[1])
except KeyError: print(‘出现了keyError错误….’)
finally: print(‘正常执行’)
- 如果出现异常但是没有成功捕获,finally会在异常发生之前执行。
try: dic = {‘name’: ‘太白金星’} print(dic[1])
except NameError: print(‘出现了NameError错误….’)
finally: print(‘异常发生之前,先执行我’)
- finally用在哪里呢?- 关闭文件的链接链接,数据等链接时,需要用到finally。
f = open(‘file’,encoding=’utf-8’) try: ‘’’各种操作’’’ print(f.read()) ‘’’但是发生错误了, 此时没关闭文件句柄,所以’’’
finally: f.close()
- 函数中,finally也会在return之前先执行。
def func(): try: return 1 finally: print(‘finally’) func()
- 循环中,finally也会在return之前执行。
while 1: try: break finally: print(‘finally’)
finally一般就是收尾工作,在一些重要环节出错之前必须一定要做的比如关闭链接的问题时,最好是用上finally作为最后一道防线,收尾。<a name="a397a8c0"></a>### 2.5 主动出发异常主动发出异常
raise TypeError(‘类型错误’)
<a name="40071d97"></a>### 2.6 断言表示一种强硬的态度,只要assert后面的代码不成立,直接报错,下面的代码就不让你执行。
assert 条件
assert 1 == 1
assert 1 == 2
应用:
assert 条件 代码 代码 …….
<a name="5a411432"></a>
### 2.7 自定义异常
python中给你提供的一些错误类型并不是所有的,只是常见的异常,如果以后你在工作中,出现了某种异常无法用已知的错误类型捕获(万能异常只能捕获python中存在的异常),那么你就可以尝试自定义异常,只要继承BaseException类即可。
class EvaException(BaseException): def init(self,msg): self.msg=msg def str(self): return self.msg
try: raise EvaException(‘类型错误’) except EvaException as e: print(e)
<a name="65e6becf"></a>
## 三、异常处理正确的使用方式
有的同学会这么想,学完了异常处理后,好强大,我要为我的每一段程序都加上try…except,干毛线去思考它会不会有逻辑错误啊,这样就很好啊,多省脑细胞===》2B青年欢乐多
try…except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的,这种东西加的多了,会导致你的代码可读性变差,只有在有些异常无法预知的情况下,才应该加上try…except,其他的逻辑错误应该尽量修正。
<a name="1d4dc985"></a>
## 四、调试
我们写的程序能一次成功执行的概念是很低的不足1%,程序中可能有各种错误和异常,有些错误和异常根据异常信息就可以容易的解决,有些则非常复杂,需要进行各种调试。常见的调试方法有以下几种:
<a name="2609bf61"></a>
### 4.1 print语句
在程序可能出错的地方打印各种变量等信息,进行判断。这种方法最原始,效率很低。
def foo(s): n = int(s) print(‘>>> n = %d’ % n) return 10 / n
def main(): foo(‘0’)
main()
<a name="445e4bc2"></a>
### 4.2 断言 assert
所有使用print进行调试输出的地方都可以使用断言,assert后面跟有判断条件,如果条件成立,则进行正常运算逻辑,否则抛出AssertionError异常。
def foo(s): n = int(s) assert n != 0, ‘n is zero!’ return 10 / n
def main(): foo(‘0’) main()
程序中如果到处充斥着assert,和print()相比也好不到哪去。不过,启动Python解释器时可以用-O参数来关闭assert:
python -O abc.py
<a name="4514708e"></a>
### 4.3 logging
把print()替换为logging是第3种方式,和assert比,logging不会抛出错误,而且可以输出到文件:
‘’’ 日志级别: debug < info < warning < error < critical logging.debug(‘debug级别,最低级别,一般开发人员用来打印一些调试信息’) logging.info(‘info级别,正常输出信息,一般用来打印一些正常的操作’) logging.warning(‘warning级别,一般用来打印警信息’) logging.error(‘error级别,一般用来打印一些错误信息’) logging.critical(‘critical 级别,一般用来打印一些致命的错误信息,等级最高’) ‘’’ import logging
logging.basicConfig( level = logging.INFO, #设置日志级别,默认warning format = ‘%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s’, datefmt = ‘%a,%d %b %Y %H:%M:%S’, filename = ‘test.log’, #可以不输出到文件,关闭就输出到终端 filemode = ‘w’ ##模式,有w和a,w就是写模式,每次都会重新写日志,覆盖之前的日志
#a是追加模式,默认如果不写的话,就是追加模式
)
def foo(s): n = int(s) logging.info(‘n = %d’ %n) return 10 / n
def main(): foo(‘0’)
main()
<a name="85eb5606"></a>
### 4.4 Python调试器 pdb
比如我们有个python文件test.py
def div(num1,num2): r = num1 / num2 print(‘result: {}’.format(r))
div(6,0)
我们可以 python -m pdb test.py 的方式来单步执行程序。
1. 执行 python -m pdb test.py 进入到 pdb环境 (Pdb)
1. l(小写字母L) :是显示脚本并且指示(->)出下一步执行的某行代码。
1. n : 执行下一条代码 也就是 -> 指向的代码,并且返回再次执行的代码内容。
1. p <变量名> : 打印当前变量内容
1. q : 退出 pdb 环境
1. help :帮助

上面的方法理论上是万能的,不过过于麻烦,实践性不强,因为有时代码是特别长的,比如1000行,如果执行到最后至少要按1000个 n 。其实我们没有必要所有的地方都单步执行,只需要在我们认为可以出错的地方暂停跟踪即可。
比如我们有个Python文件test.py
import pdb
num1 = 6 num2 = 0 pdb.set_trace() #设置断点 ret = num1 / num2 print(‘{} / {} = {}’.format(num1, num2, ret))
1. 执行python test.py程序
1. 小写字母l进行查看 代码刚好执行完pdb.set_trace()我们设置的跟踪点位置
1. 尝试查看感兴趣的变量
1. c :继续执行脚本,因为我们的脚本是有异常的,会正常抛出异常

<a name="bc00b857"></a>
### 4.5 ipython
当你在有问题的代码前加上这段代码,它就可以帮助你在异常时进入ipdb调试模式。前提是你要安装ipython。
import sys from IPython.core import ultratb sys.excepthook = ultratb.FormattedTB(mode=’Verbose’,color_scheme=’Linux’,call_pdb=1)
你也可以把上面的代码保存成crash_debug.py,然后在你出问题的文件test.py头上加上。
import crash_debug for i in range(10,-1,-1): y = 1/i print(y) ```
执行python3 test.py后输出: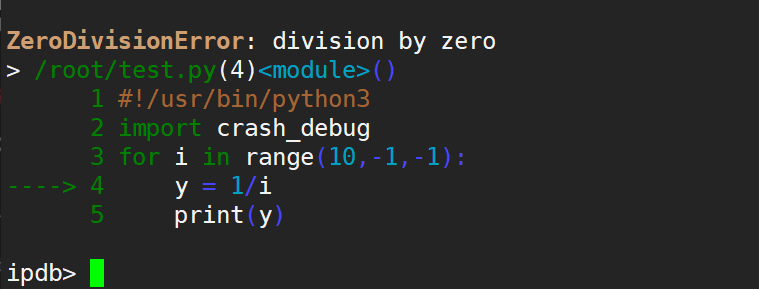

若有收获,就点个赞吧
0 人点赞
