文件操作
在讲文件操作之前,先来了解编码方式
编码
咱们的电脑,存储和发送文件,发送的是什么?电脑里面是不是有成千上万个二极管,亮的代表是1,不亮的代表是0,这样实际上电脑的存储和发送是不是都是010101啊 我们发送的内容都是010101010这样写的内容比较多就不知道是什么了,所以我们想要明确的区分出来发送的内容就需要在某个地方进行分段.计算机中设定的就是8位一断句。
需要了解以下几个概念:
字节
字节(Byte)是计算机中数据存储的基本单元,一字节等于一个8位的比特,计算机中的所有数据,不论是保存在磁盘文件上的还是网络上传输的数据(文字、图片、视频、音频文件)都是由字节组成的。
字符
你正在阅读的这篇文章就是由很多个字符(Character)构成的,字符一个信息单位,它是各种文字和符号的统称,比如一个英文字母是一个字符,一个汉字是一个字符,一个标点符号也是一个字符。
字符集
字符集(Character Set)就是某个范围内字符的集合,不同的字符集规定了字符的个数,比如 ASCII字符集总共有128个字符,包括32个通用控制符,10个十进制数码,52个英文大小写字母和34个专用符号。而GB2312字符集定义了7445个字符,包含了绝大部分汉字字符。
字符码
字符码(Code Point)指的是字符集中每个字符的数字编号,例如 ASCII 字符集用 0-127 连续的128个数字分别表示128个字符,例如”A”的字符码编号就是65。
字符编码
字符编码(Character Encoding)是将字符集中的字符码映射为字节流的一种具体实现方案,常见的字符编码有 ASCII 编码、UTF-8编码、GBK编码等。某种意义上来说,字符集与字符编码有种对应关系,例如 ASCII 字符集对应 有 ASCII 编码。ASCII 字符编码规定使用单字节中低位的7个比特去编码所有的字符。例如”A” 的编号是65,用单字节表示就是0×41,因此写入存储设备的时候就是b’01000001’。
编码、解码
编码的过程是将字符转换成字节流,解码的过程是将字节流解析为字符。
常见的字符集
ASCII
#计算机:储存文件,或者是传输文件,实际上是010101010#计算机创建初期,美国,是7位一段,但是发明者说为了拓展,留出一位,这样#就是8位一段句。8位有多少种可能 ?256密码本:ascii0000000101000001 01000010 01000011 A B C
随着计算机的发展以及普及率的提高,流⾏到欧洲和亚洲,这时ASCII码就不合适了。比如: 中⽂汉字有几万个.而ASCII最多也就256个位置.所以ASCII不行了. 怎么办呢? 这时,不同的国家就提出了不同的编码用来适用于各自的语言环境. 比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等,这时各个国家都可以使用计算机了。
GBK
GBK, 国标码占用2个字节,对应ASCII码GBK直接兼容,因为计算机底层是用英文写的,你不支持英文肯定不行。而英文已经使用了ASCII码,所以GBK要兼容ASCII。这里GBK国标码,前⾯的ASCII码部分,由于使⽤两个字节,所以对于ASCII码⽽言,前9位都是0。
字母A:0100 0001 # ASCII字母A:0000 0000 0100 0001 # 国标码
Unicode
全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
#创建之初,16位,2个字节,表示一个字符.英文: a b c 六个字节 一个英文2个字节中文 中国 四个字节 一个中文用2个字节#但是这种也不行,这种最多有65535种可能,可是中国文字有9万多,#所以改成 32位,4个字节,表示一个字符.a 01000001 01000010 01000011 00000001b 01000001 01000010 01100011 00000001中 01001001 01000010 01100011 00000001#如果你写的文本基本上全部是英文的话,浪费资源。
UTF-8
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
#UTF-8A 01000001 ascii码中的字符:一个字符一个字节表示。To 01000001 01000010 (欧洲文字:葡萄牙,西班牙等)一个字符两个字节表示。中 01001001 01000010 01100011 亚洲文字;一个字符三个字节表示。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
其实这个不用深入理解,他就是规定,举个例子:用文件编辑器(word,wps,等)编辑文件的时候,从文件将你的数据(此时你的数据是非Unicode(可能是UTF-8,也可能是gbk,这个编码取决于你的编辑器设置))字符被转换为Unicode字符读到内存里,进行相应的编辑,编辑完成后,保存的时候再把Unicode转换为非Unicode(UTF-8,GBK 等)保存到文件。
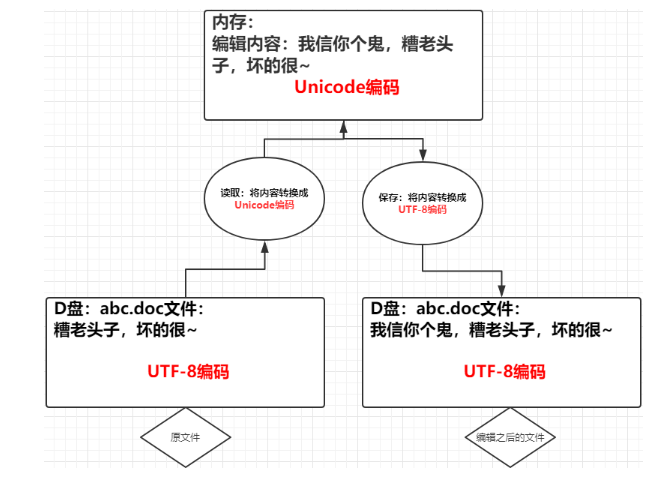
不同编码之间,不能直接互相识别
比如你的一个数据:‘老铁没毛病’是以utf-8的编码方式编码并发送给一个朋友,那么你发送的肯定是通过utf-8的编码转化成的二进制01010101,那么你的朋友接收到你发的这个数据,他如果想查看这个数据必须将01010101转化成汉字,才可以查看,那么此时那也必须通过utf-8编码反转回去,如果要是通过gbk编码反转,那么这个内容可能会出现乱码或者报错。
编码及解码
那么了解完以上知识点点之后,咱们开始进入编码进阶的最重要的内容。
前提条件:python3x版本(python2x版本与这个不同)。
主要用途:数据的存储或者传输。
刚才咱们也说过了,在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码比如:UTF-8编码。
咱们就以网络传输为例:
好那么接下来咱们继续讨论,首先先声明一个知识点就是这里所说的’数据’,这个数据,其实准确的说是以字符串(特殊的字符串)类型的数据。那么有同学就会问到,python中的数据类型很多,int bool list dict str等等,如果我想将一个列表数据通过网络传输给小明同学,不行么? 确切的说不行,你必须将这个列表转化成一个特殊的字符串类型,然后才可以传输出去,数据的存储也是如此。
那么你就清楚一些了,你想通过存储或者网络传输的数据是一个特殊的字符串类型,那么我就直接将这个字符串传出去不就行了么?比如我这有一个数据:‘今晚10点吃鸡,大吉大利’ 这不就是字符串类型么?我直接将这个数据通过网络发送给小明不就可以了么?不行。这里你还没有看清一个问题,就是特殊的字符串。为什么?

那么如何解决呢?
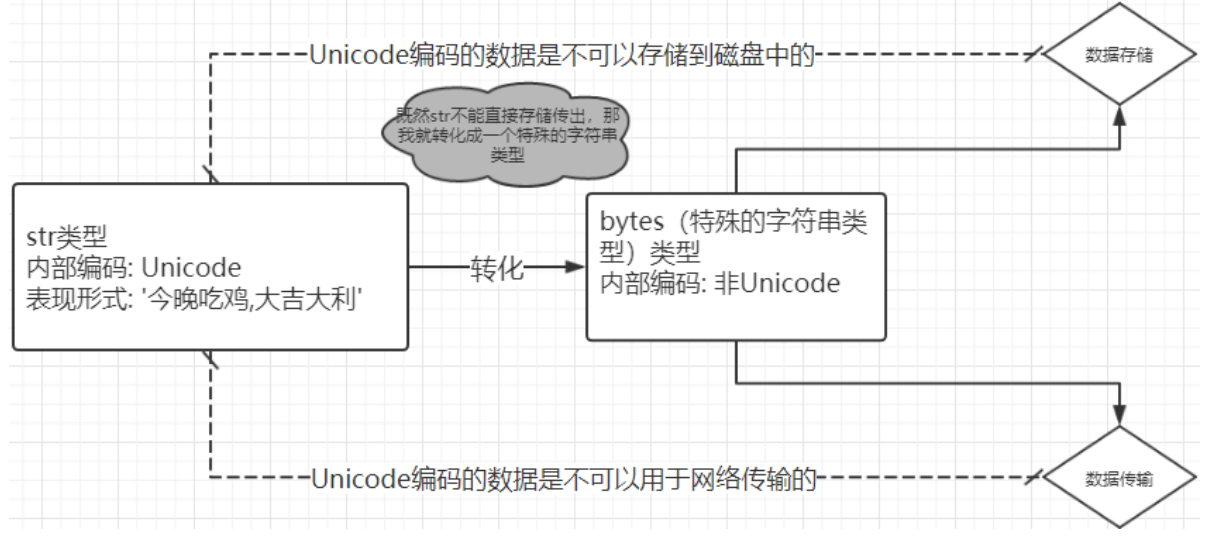
那么这个bytes类型是个什么类型呢?其实他也是Python基础数据类型之一:bytes类型。
这个bytes类型与字符串类型,几乎一模一样,可以看看bytes类型的源码,bytes类型可以用的操作方法与str相差无几.
那么上面写了这么多,咱们不用全部记住,对于某些知识点了解一下即可,但是对于有些知识点是需要大家理解的:
bytes类型也称作字节文本,他的主要用途就是网络的数据传输,与数据存储。那么有些同学肯定问,bytes类型既然与str差不多,而且操作方法也很相似,就是在字符串前面加个b不就行了,python为什么还要这两个数据类型呢?我只用bytes不行么?
如果你只用bytes开发,不方便。因为对于非ascii码里面的文字来说,bytes只是显示的是16进制。很不方便。
s1 = '中国'b1 = b'\xe4\xb8\xad\xe5\x9b\xbd' # utf-8 的编码
好,上面咱们对于bytes类型应该有了一个大致的了解,对str 与 bytes的对比也是有了对比的了解,那么咱们最终要解决的问题,现在可以解决了,那就是str与bytes类型的转换的问题。
如果你的str数据想要存储到文件或者传输出去,那么直接是不可以的,上面我们已经图示了,我们要将str数据转化成bytes数据就可以了。
编码:str ——> bytes
# encode称作编码:将 str 转化成 bytes类型s1 = '中国'b1 = s1.encode('utf-8') # 转化成utf-8的bytes类型print(s1) # 中国print(b1) # b'\xe4\xb8\xad\xe5\x9b\xbd's1 = '中国'b1 = s1.encode('gbk') # 转化成gbk的bytes类型print(s1) # 中国print(b1) # b'\xd6\xd0\xb9\xfa'
解码:bytes —> str
# decode称作解码, 将 bytes 转化成 str类型b1 = b'\xe4\xb8\xad\xe5\x9b\xbd's1 = b1.decode('utf-8')print(s1) # 中国
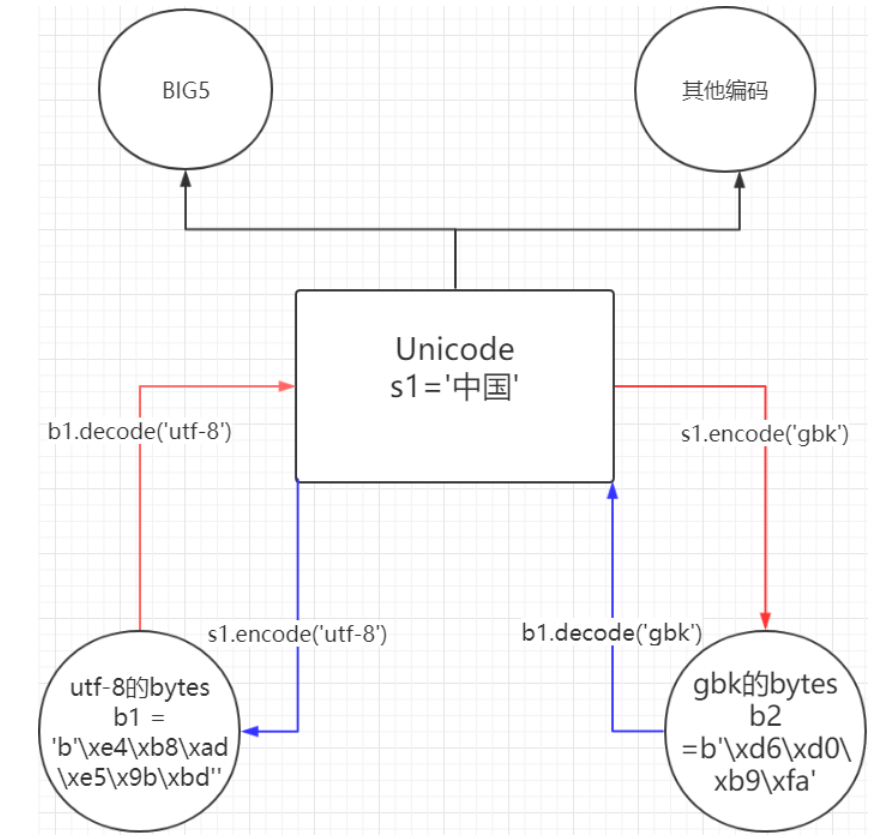
那么这里还有一个最重要的,也是你们以后工作中经常遇到的让人头疼的问题,就是gbk编码的数据,转化成utf-8编码的数据。有人说老师,我怎么有点蒙呢?这是什么? 来,捋一下,bytes类型他叫字节文本,他的编码方式是非Unicode的编码,非Unicode即可以是gbk,可以是UTF-8,可以是GB2312…
b1 = b'\xe4\xb8\xad\xe5\x9b\xbd' # 这是utf-8编码bytes类型的中国b2 = b'\xd6\xd0\xb9\xfa' # 这是gbk编码bytes类型的中国
那么gbk编码的bytes如何转化成utf-8编码的bytes呢?
不同编码之间,不能直接互相识别。
上面我说了,不同编码之间是不能直接互相是别的,这里说了不能直接,那就可以间接,如何间接呢? 现存世上的所有的编码都和谁有关系呢? 都和万国码Unicode有关系,所以需要借助Unicode进行转换。
看下面的图就行了!
Python文件操作
学习文件操作的目的:文件可以保存程序产生的数据
如果要操作文件,都需要哪些参数呢?
- 文件路径:D:\美女模特空姐护士联系方式.txt (你想操作这个文件,必须要知道这个文件的位置)
- 编码方式:utf-8,gbk,gb2312… (刚讲完编码,文件其实就是数据的存储,数据存储你需要编码知道这个数据是以什么编码存储的)
- 操作模式:只读,只写,追加,写读,读写…
>>> f = open('/root/test.conf',mode='r',encoding='utf-8')>>> content = f.read()>>> print(content)>>> f.close()
上面代码的解释:
f: 就是一个变量,一般都会将它写成f,f_obj,file,f_handler,fh,等,它被称作文件句柄。open:是Python调用的操作系统(windows,linux,等)的功能。'/root/test.conf': 这个是文件的路径。mode: 就是定义你的操作方式:r为读模式。encoding: 不是具体的编码或者解码,他就是声明:此次打开文件使用什么编码本。一般来说:你的文件用什么编码保存的,就用什么方法打开,一般都是用utf-8(有些使用的是gbk)。f.read():你想操作文件,比如读文件,给文件写内容,等等,都必须通过文件句柄进行操作。close(): 关闭文件句柄(可以把文件句柄理解成一个空间,这个空间存在内存中,必须要主动关闭)。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程,文件操作的步骤:
- 打开文件
- 读写文件
- 关闭文件
#1. 打开文件,得到文件句柄并赋值给一个变量f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r#2. 通过句柄对文件进行操作data=f.read()#3. 关闭文件f.close()
打开文件
使用open()函数
函数open将文件名作为唯一必不可少的参数,并返回一个文件对象。
调用函数open时,如果只指定文件名,将获得一个可读取的文件对象。如果希望可以写入文件,就会用到open()函数的第二个参数,显式指定模式。
操作音频、视频、图片、pdf文档等属于二进制文件,模式加‘b’
模式如下:
| 模 式 | 内容 |
|---|---|
| r | 默认打开方式,以只读形式打开文件,文件必须存在,否则出现错误 |
| w | 可以写操作文件,但是会把指针放到文件开头,意味着要把原先的文件覆盖。文件如果不存在,则创建新文件 |
| a | 追加形式打开文件,文件不存在,创建新文件并进行写入 |
| rb | 以二进制形式打开一个文件,只读,指针到文件开头,文件必须存在 |
| wb | 以二进制形式打开一个文件,可以写,指针到文件开头。如果文件存在则覆盖,文件不存在则创建 |
| ab | 以二进制形式打开文件,可以追加形式操作,文件不存在,创建新文件 |
| r+ | 打开一个文件用于读写,指针到文件开头,文件必须存在 |
| w+ | 打开一个文件用于读写,指针到文件开头,文件存在则覆盖,文件不存在则创建 |
| a+ | 以追加形式打开文件用于读写,指针到文件结尾,文件存在时追加内容,文件不存在则创建 |
| rb+ | 打开一个二进制文件用于读写,指针到文件开头,文件必须存在 |
| wb+ | 打开一个二进制文件用于读写,指针到文件开头,文件存在则覆盖,文件不存在则创建 |
| ab+ | 以追加形式打开二进制文件用于读写,指针到文件结尾,文件存在时追加内容,文件不存在则创建 |
读文件
1. 函数read()
读取文件的整个内容,当文件很大时就会非常的占用内存,容易导致内存奔溃.
f = open('abc.txt','r')f.read()'this\nis no\nhaiku'
可以每次读取一个字节
In [8]: f.read(1)Out[8]: 't'In [9]: f.read(1)Out[9]: 'h'
2. 函数readline()
readline()读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个\n。解决这个问题只需要在我们读取出来的文件后边加一个strip()就OK了。
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')msg1 = f.readline() #msg1 = f.readline().strip()msg2 = f.readline()msg3 = f.readline()msg4 = f.readline()f.close()print(msg1)print(msg2)print(msg3)print(msg4)结果:高圆圆刘亦菲张柏芝杨紫
3. 函数readlines()
readlines() 返回一个列表,列表里面每个元素是原文件的每一行,如果文件很大,占内存,容易崩盘。
>>> f = open('/root/test.conf')>>> f.readlines()['# Generated by NetworkManager\n', 'nameserver 192.168.154.2\n']
4. for循环读取
可以通过for循环去读取,文件句柄是一个迭代器,他的特点就是每次循环只在内存中占一行的数据,非常节省内存。
>>> f = open('/root/test.conf')>>> for line in f:... print(line.strip())...# Generated by NetworkManagernameserver 192.168.154.2>>> f.close()
5. rb模式
rb模式:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。记住下面讲的也是一样,带b的都是以二进制的格式操作文件,他们主要是操作非文字文件:图片,音频,视频等,并且如果你要是带有b的模式操作文件,那么不用声明编码方式。
可以网上下载一个图片给同学们举例:
当然rb模式也有read,read(n),readline(),readlines(),for循环这几种方法。
写文件
函数write()
把数据写入文件中
In [11]: f = open('aaa.txt','w')In [12]: f.write('this is a test\nHello World!\n')Out[12]: 28
w模式
如果文件不存在,利用w模式操作文件,那么它会先创建文件,然后写入内容。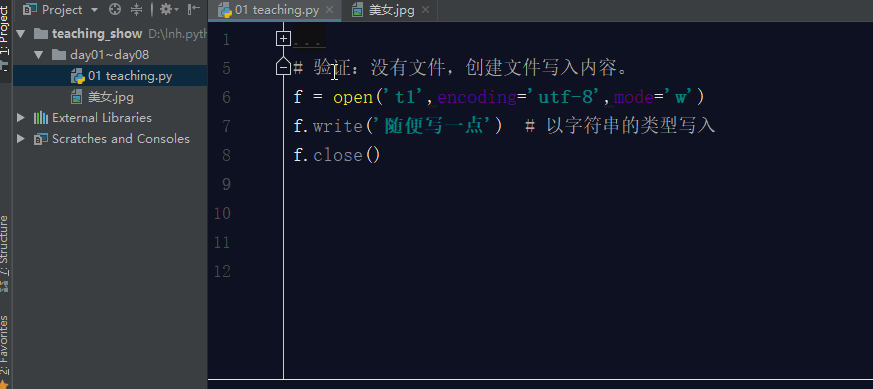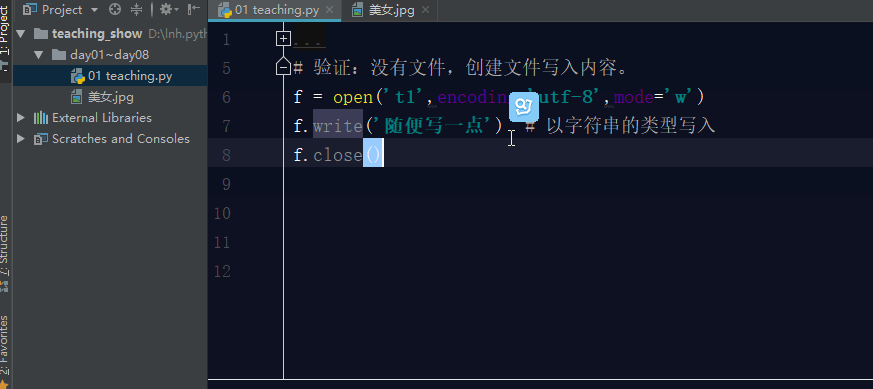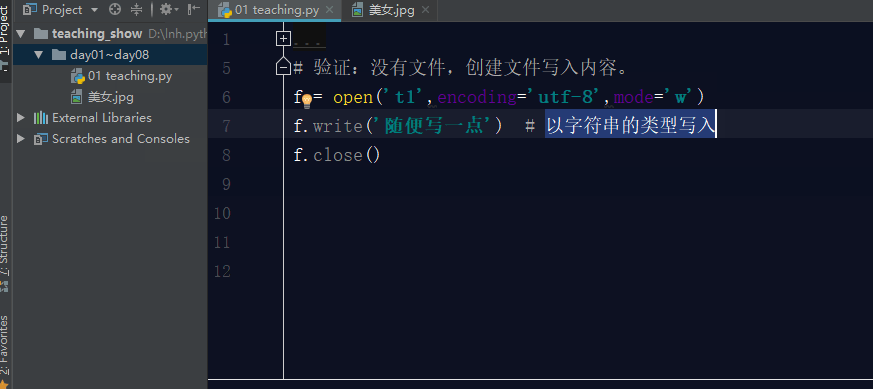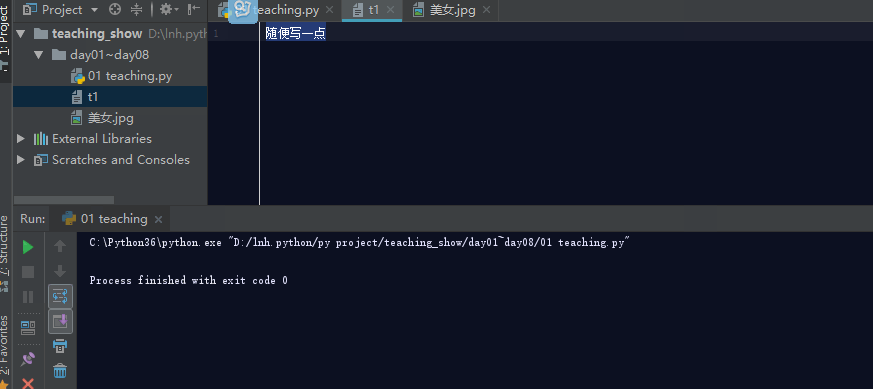
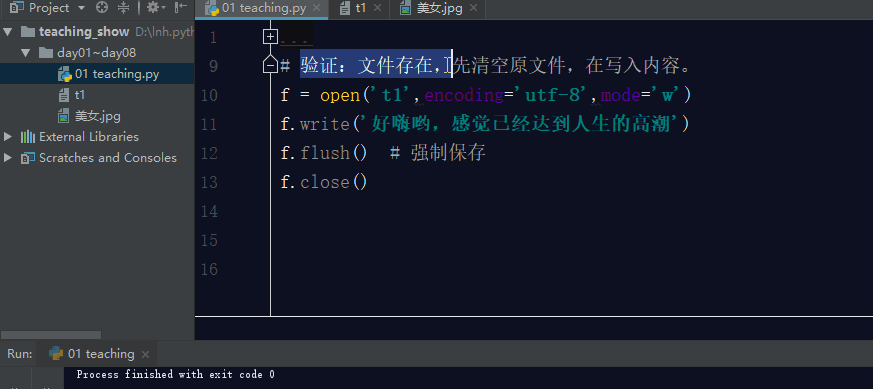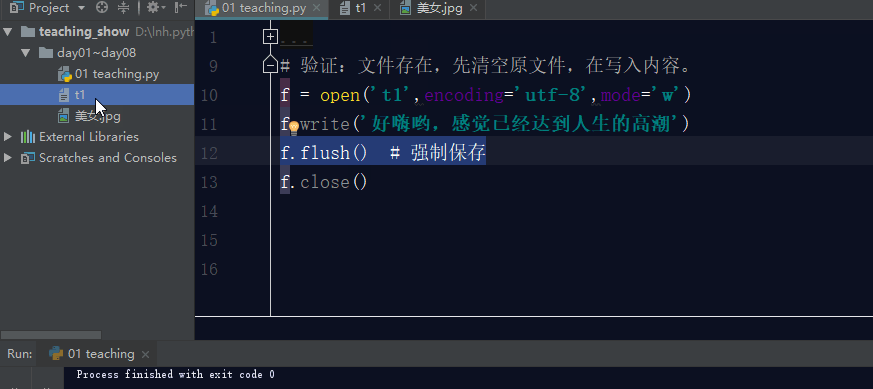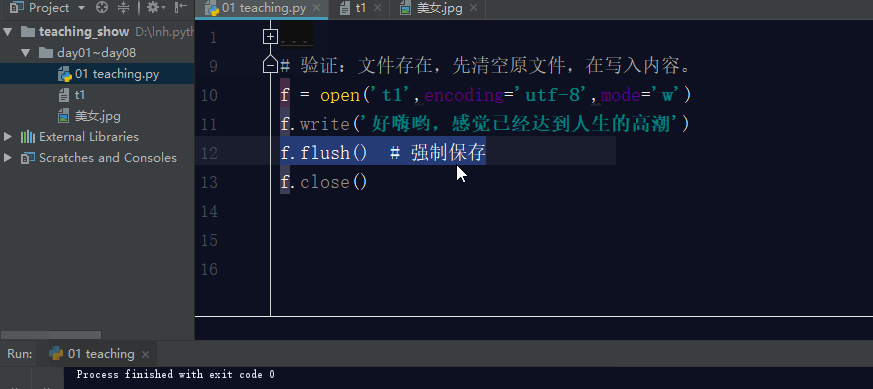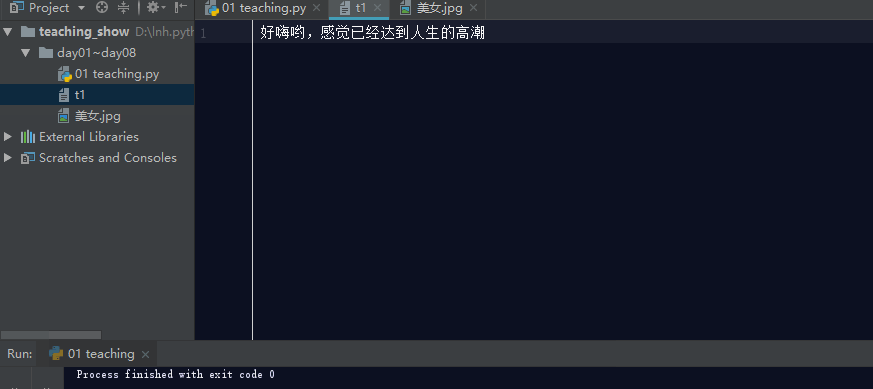
如果文件存在,利用w模式操作文件,先清空原文件内容,在写入新内容。
wb模式
wb模式:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如:图片,音频,视频等。
举例说明:
我先以rb的模式将一个图片的内容以bytes类型全部读取出来,然后在以wb将全部读取出来的数据写入一个新文件,这样我就完成了类似于一个图片复制的流程。具体代码如下:
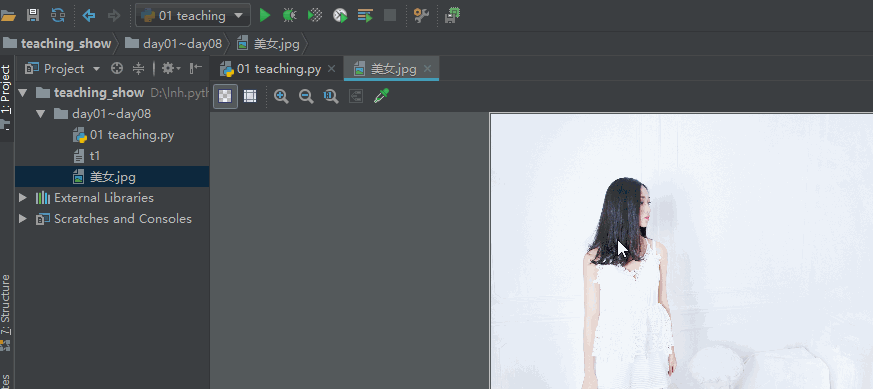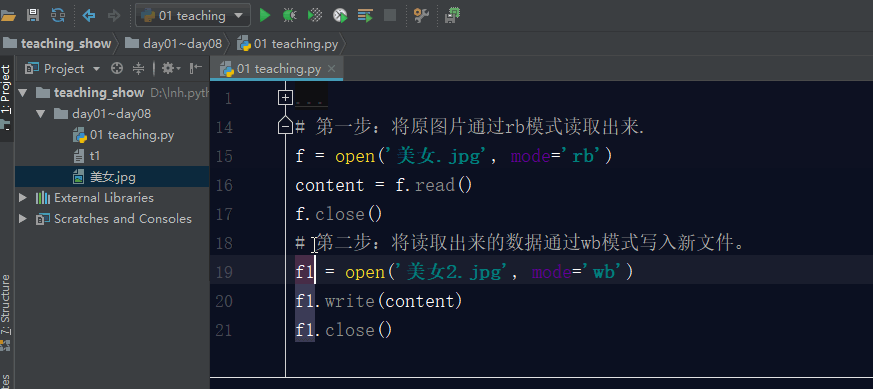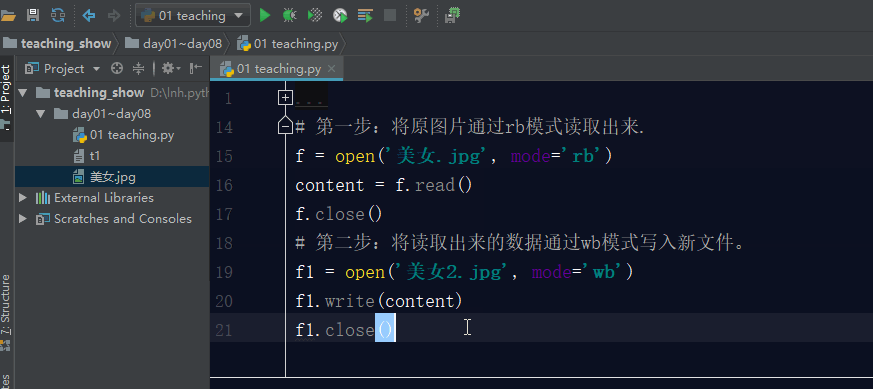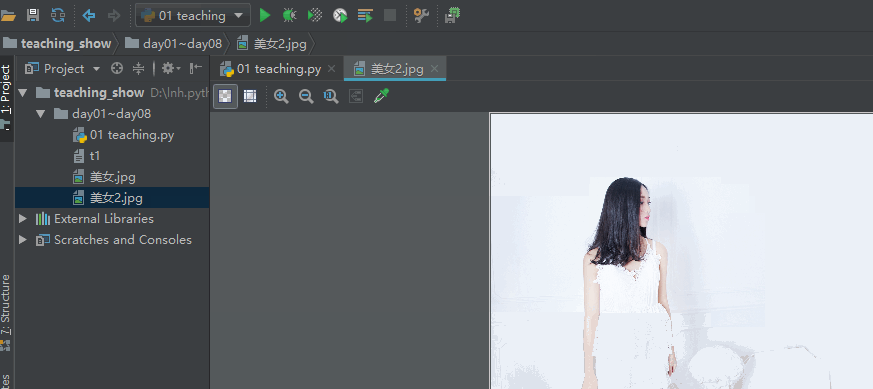
文件操作:追加
第三类就是追加,就是在文件中追加内容。这里也有四种文件分类主要四种模式:a,ab,a+,ab+,我们只讲a。
a模式
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
如果文件不存在,利用a模式操作文件,那么它会先创建文件,然后写入内容。
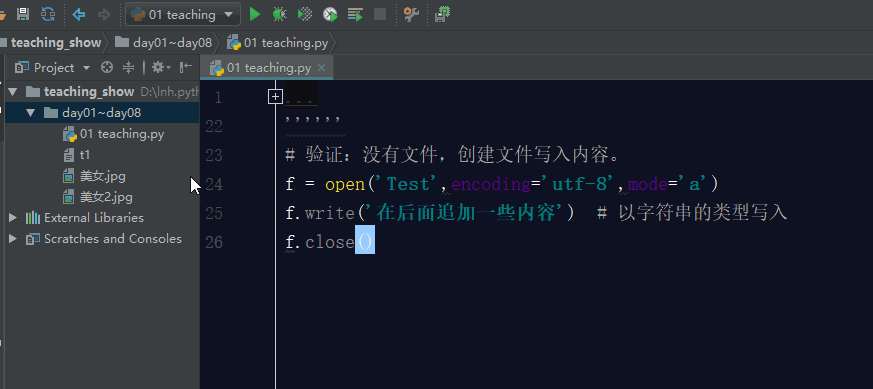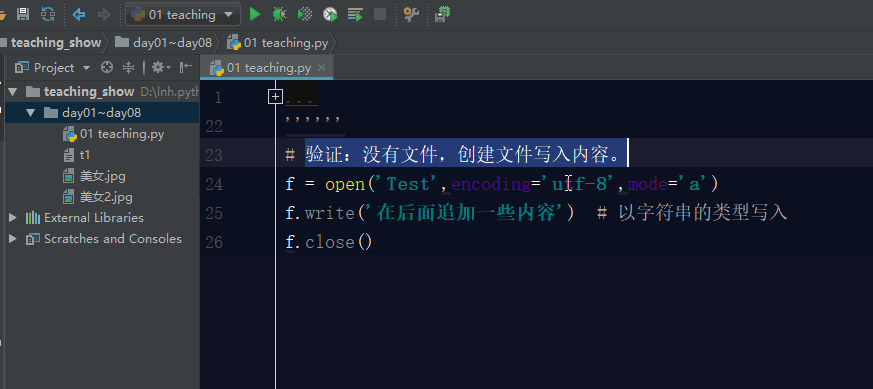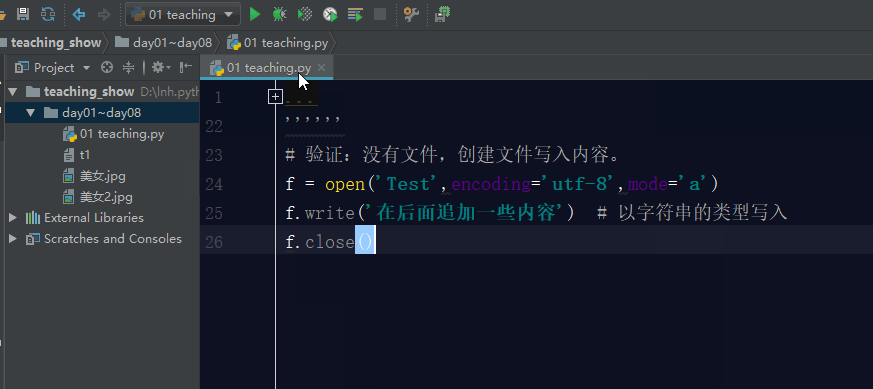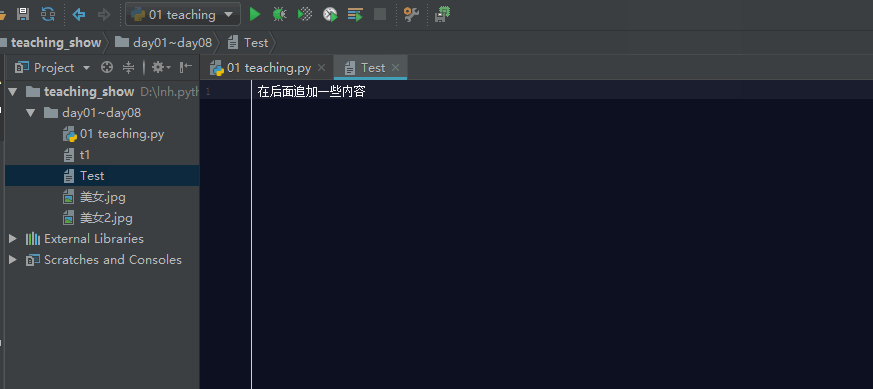
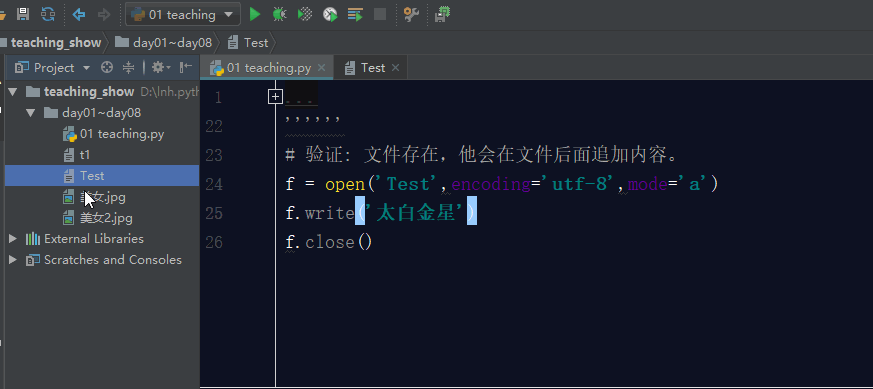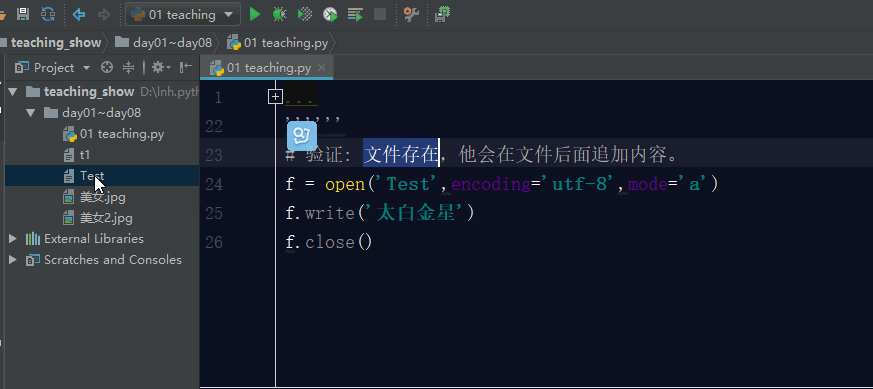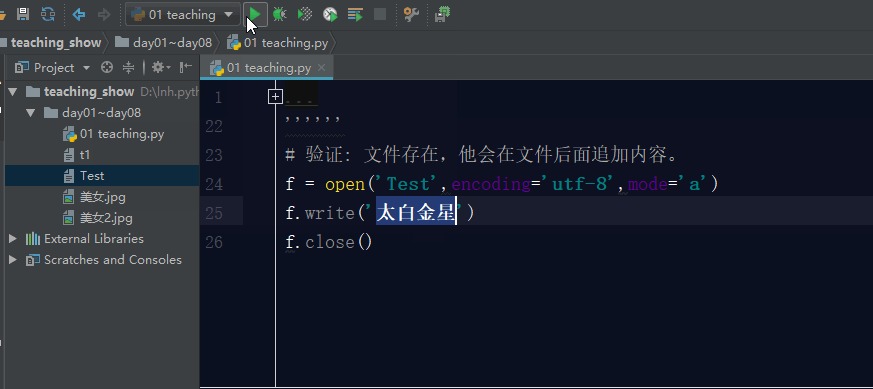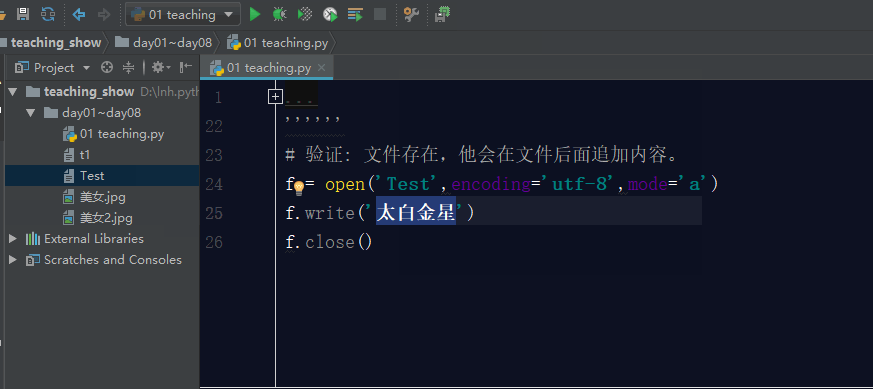
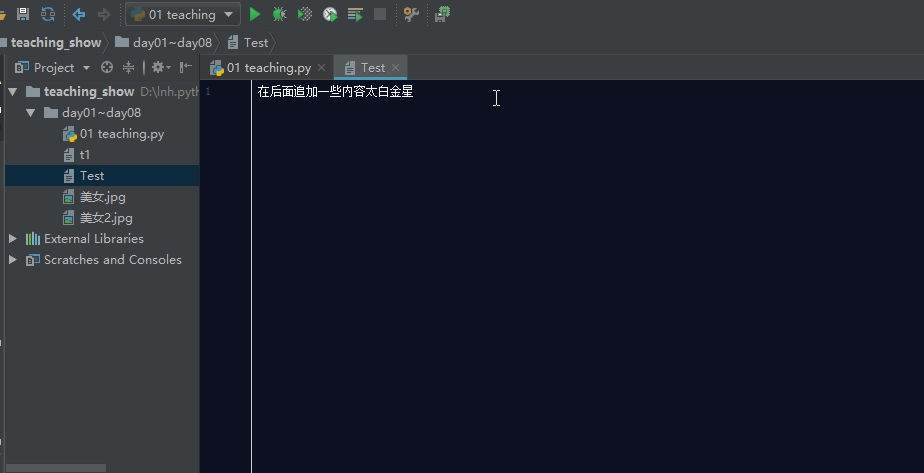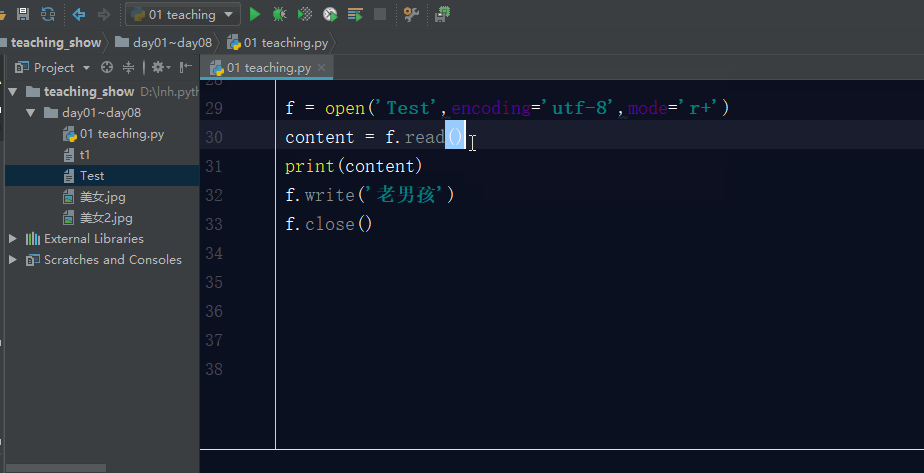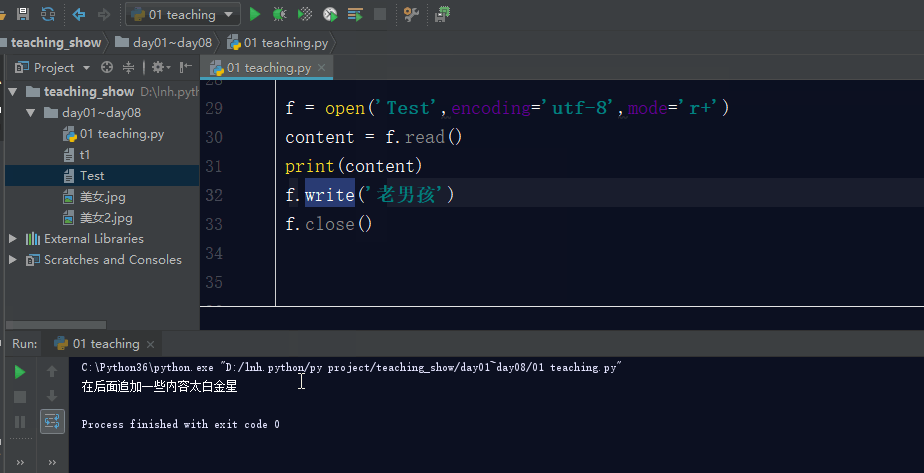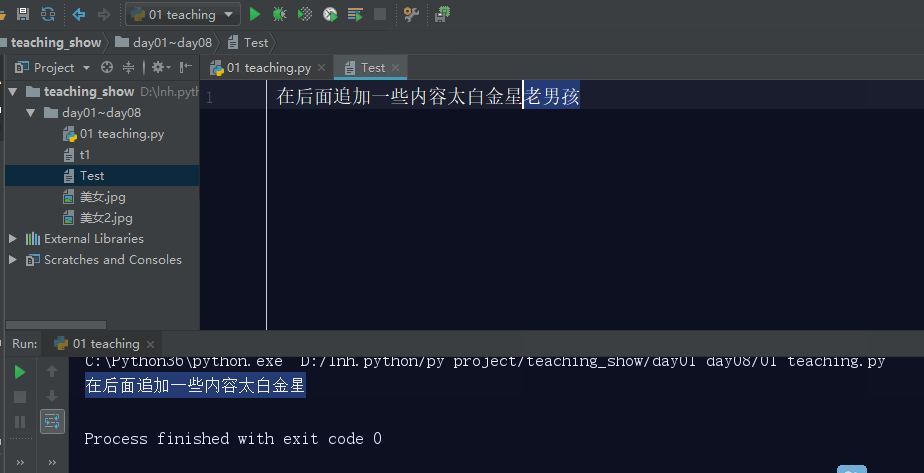
如果文件存在,利用a模式操作文件,那么它会在文件的最后面追加内容。
文件操作其他模式
大家发现了没有,咱们还有一种模式没有讲,就是那种带+号的模式。什么是带+的模式呢?+就是加一个功能。比如刚才讲的r模式是只读模式,在这种模式下,文件句柄只能进行类似于read的这读的操作,而不能进行write这种写的操作。所以我们想让这个文件句柄既可以进行读的操作,又可以进行写的操作,那么这个如何做呢?这就是接下来要说这样的模式:r+ 读写模式,w+写读模式,a+写读模式,rb+ 以bytes类型的读写模式…
在这里咱们只讲一种就是r+,其他的大同小异,自己可以练练就行了。
r+模式
r+: 打开一个文件用于读写。文件指针默认将会放在文件的开头。
注意:如果你在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会讲原内容覆盖掉,直到覆盖到你写完的内容,然后在后面开始读取。
文件操作其他功能
read(n)
- 文件打开方式为文本模式时,代表读取n个字符
- 文件打开方式为b模式时,代表读取n个字节
seek()
移动文件读取指针到指定位置
参数:
- offset – 开始的偏移量,也就是代表需要移动偏移的字节数
- whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
- seek(n)光标移动到n位置,注意: 移动单位是byte,所以如果是utf-8的中文部分则是3的倍数
- 通常我们使用seek都是移动到开头或者结尾
f = open("小娃娃", mode="r+", encoding="utf-8")f.seek(0) # 光标移动到开头content = f.read() # 读取内容, 此时光标移动到结尾print(content)f.seek(0) # 再次将光标移动到开头f.seek(0, 2) # 将光标移动到结尾content2 = f.read() # 读取内容. 什么都没有print(content2)f.seek(0) # 移动到开头f.write("张国荣") # 写入信息. 此时光标在9 中文3 * 3个 = 9f.flush()f.close()
tell()
使用tell()可以帮我们获取当前光标在什么位置
f = open("小娃娃", mode="r+", encoding="utf-8")f.seek(0) # 光标移动到开头content = f.read() # 读取内容, 此时光标移动到结尾print(content)f.seek(0) # 再次将光标移动到开头f.seek(0, 2) # 将光标移动到结尾content2 = f.read() # 读取内容. 什么都没有print(content2)f.seek(0) # 移动到开头f.write("张国荣") # 写入信息. 此时光标在9 中⽂文3 * 3个 = 9print(f.tell()) # 光标位置9f.flush()f.close()
readable(),writeable()
f = open('Test',encoding='utf-8',mode='r')print(f.readable()) # Trueprint(f.writable()) # Falsecontent = f.read()f.close()
flush()
刷新文件内部缓冲区,(就是主动保存到内存)。
打开文件的另一种方式
打开文件都是通过open去打开一个文件,其实Python也给咱们提供了另一种方式:with open() as … 的形式,那么这种形式有什么好处呢?
# 1,利用with上下文管理这种方式,它会自动关闭文件句柄。with open('t1',encoding='utf-8') as f1:f1.read()# 2,一个with 语句可以操作多个文件,产生多个文件句柄。with open('t1',encoding='utf-8') as f1,\open('Test', encoding='utf-8', mode = 'w') as f2:f1.read()f2.write('太白金星')
这里要注意一个问题,虽然使用with语句方式打开文件,不用你手动关闭文件句柄,比较省事儿,但是依靠其自动关闭文件句柄,是有一段时间的,这个时间不固定,所以这里就会产生问题,如果你在with语句中通过r模式打开t1文件,那么你在下面又以a模式打开t1文件,此时有可能你第二次打开t1文件时,第一次的文件句柄还没有关闭掉,可能就会出现错误,他的解决方式只能在你第二次打开此文件前,手动关闭上一个文件句柄。
文件修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:
将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os # 调用系统模块with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:data=read_f.read() #全部读入内存,如果文件很大,会很卡data=data.replace('alex','SB') #在内存中完成修改write_f.write(data) #一次性写入新文件os.remove('a.txt') #删除原文件os.rename('.a.txt.swap','a.txt') #将新建的文件重命名为原文件
方式二:
将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import oswith open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:for line in read_f:line=line.replace('alex','SB')write_f.write(line)os.remove('a.txt')os.rename('.a.txt.swap','a.txt')
复制文件
#把文件名为xxx.yyy的文件复制成xxx[复件].yyy文件old_file_name = input("请输入要复制的文件的名字:")old_file = open(old_file_name,'r')position = old_file_name.rfind('.')new_file_name = old_file_name[:position] + '[复件]' + old_file_name[position:]new_file = open(new_file_name,'w')file_content = old_file.read()new_file.write(file_content)old_file.close()new_file.close()print("{}已经被复制成{}".format(old_file_name,new_file_name))

若有收获,就点个赞吧
0 人点赞
