Python函数
函数是对程序逻辑进行结构化或过程化的一种编程方法。将通用代码写入一个函数,达到一处定义多处调用的效果,方便代码修改及管理。
使用函数的优势:
- 减少代码的重复性。
- 增强代码e的可读性。
函数是Python甚至所有的高级语言都支持的语言特征,Python不仅可以灵活的定义函数,而且自身还内置以许多实用的函数,给我们的开发带来了极大的便利。
举一个简单的例子,我们知道圆的面积计算公式为
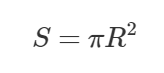
如果让你计算一个半径为10的圆的面积,你可能这样实现
r1 = 10s1 = 3.14*r1*r1
圆的半径变了,你就需要重复的去书写一些内容,并且,前提是你还记得公式是什么
r2 = 15r3 = 20s2 = 3.14*r2*r2s3 = 3.14*r3*r3
这还只是是在公式简单并且参数单一的情况下.
如果公式变得十分复杂,我们需要代入的数据非常多的时候,事情就会变得很麻烦.
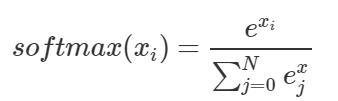
类比数学中的一些公式,在程序中反复执行的代码,我们可以封装到一个代码块当中,例如,计算圆的面积
s = area_of_circle(x)
今后我们再计算圆面积时,只需要传入一个半径,就可以得到结果了.
其实,area_of_circle这个封装起来的,解决圆的面积计算方法的代码块,我们可以称作函数。
抽象
抽象可节省人力,但实际上还有个更重要的优点:抽象是程序能够被人理解的关键所在(无论对编写程序还是阅读程序来说,这都至关重要)。计算机本身喜欢具体而明确的指令,但人通常不是这样的。例如,如果你向人打听怎么去电影院,就不希望对方回答:“向前走10步,向左转90度,接着走5步,再向右转45度,然后走123步。”听到这样的回答,你肯定一头雾水。
如果对方回答:“沿这条街往前走,看到过街天桥后走到马路对面,电影院就在你左边。”你肯定能明白。这里的关键是你知道如何沿街往前走,也知道如何过天桥,因此不需要有关这些方面的具体说明。
组织计算机程序时,你也采取类似的方式。程序应非常抽象,如下载网页、计算使用频率、打印每个单词的使用频率。这很容易理解。下面就将前述简单描述转换为一个Python程序。
page = download_page()freqs = compute_frequencies(page)for word, freq in freqs:print(word, freq)
看到这些代码,任何人都知道这个程序是做什么的。然而,至于具体该如何做,你未置一词。你只是让计算机去下载网页并计算使用频率,至于这些操作的具体细节,将在其他地方(独立的函数定义)中给出。
抽象是数学中常见的概念,也是计算机程序必不可少的一种思维方式.借助抽象,我们才能不关心底层的具体计算过程,而直接在更高的层次上思考问题.
在Python中,我们没有必要自己去思考几个数字类型相加如何去计算,因为Python给我们提供了sum()函数,sum其实就是一种对求和的方法的抽象,这可以帮助我们直接关心业务逻辑,忽略加法的具体过程.
同理,如果我们想要获得一个圆的面积,也可以采用类似数学公式的概念,将具体的,重复的问题抽象化
import mathdef area_of_circle(x):return math.pi*x*x
自己定义函数的过程,就是一个抽象的过程,这需要我们在接下来的课程中不断的学习。
自定义函数
在前面的学习过程中,我们用到了一些函数,例如len(),min(),max()这些函数都是由Python官方提供的,我们称之为内置函数(BIF)。
自定义函数的语法结构:
def 函数名(参数列表):函数体return 返回值
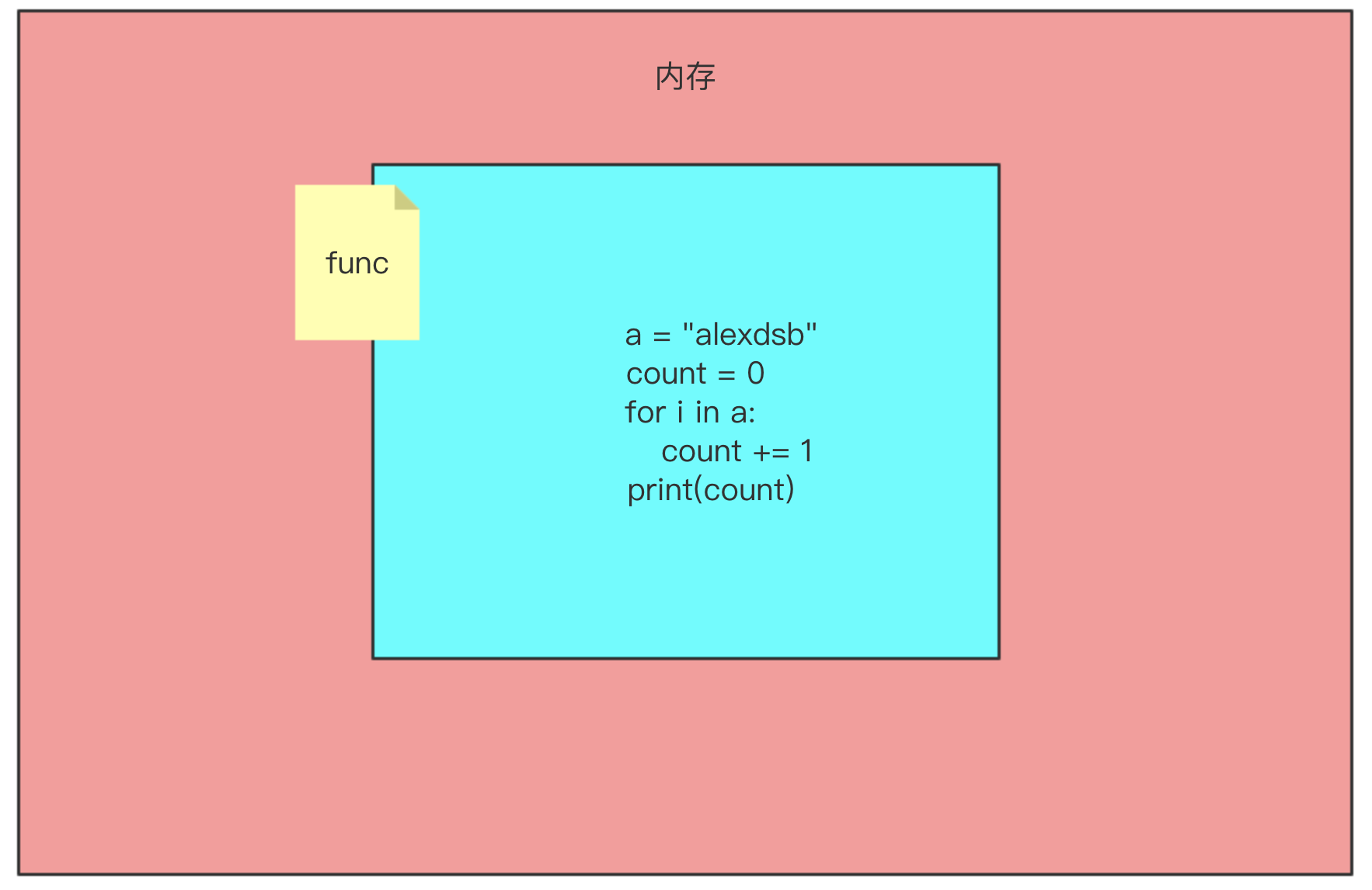
是的你没有看错,内存开辟了一个空间,但是里边存放是代码,这样我就将咱们写的代码封装起来了。
其中
- def 是定义函数的关键字
- 函数名需要符合标识符的命名规范
- 区分大小写
- 首字母可以是下划线_但不能是数字
- 除首字母之外的其他字符 可以是下划线,字母和数字
- 关键字不能作为标识符
- 函数名需要符合一般的命名标准
- 全部小写,如果由多个单词构成,可以用下划线隔开
- 在模块或函数内部,可以用单下划线开头
- 类内部使用变量名,双下划线开头,表示私有
- 多个参数列表之间可以用逗号分隔
- 函数体是我们”重复执行的代码块”
- 函数执行完毕之后如果有返回值,可以用return将数据返回,否则可以使用return None或者省略return语句.请注意,函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕。
案例
定义一个函数,用于计算长方形的面积
def rectangle_area(width,height):area = width * heightreturn arear_area = rectangle_area(100,200.0)print("100*200的长方形面积:{0:.2f}".format(r_area))
上述代码中:
- 通过def定义了计算长方形面积的函数,他有两个参数,分别是长方形的宽和高;
- 函数体是我们计算长方形面积的表达式,结果赋值给area,然后通过return返回我们所要的数据;
- 我们通过函数名rectangle加小括号的形式对函数进行调用执行;
- 执行过程中,我们在小括号内传入实际需要参与运算的数据(实参);
- 实参被赋给了参数列表,函数开始执行;
函数调用
- 函数必须被调用才会执行,使用函数名加小括号就可以调用了;
- 写法:函数名() 这个时候函数的函数体会被执行;
- 函数的调用通常情况下是在函数声明之后,否则可能出现报错。
r_area = rectangle_area(100,200.0)def rectangle_area(width,height):area = width * heightreturn areaprint("100*200的长方形面积:{0:.2f}".format(r_area))#执行后报以下错误:NameError: name 'rectangle_area' is not defined
函数返回值
凡是运算,皆有返回值。函数的本质是”一个运算”的抽象,因此函数本身必定有返回值。
无返回值函数
首先,我们需要明确一点,在Python中并不存在”无返回值参数”,因为凡是运算,皆有返回值,只是有些函数看起来没有返回值罢了。
>>> def say_hello():... print("Hello World")...>>> result = say_hello()Hello World>>> print(result)None
可以看到,当没有使用return语句时,返回的值为None。
也可以显式的返回None,或者只写一个return,他们的效果是一样的。
def say_hello():print("Hello World")return None#或者def say_hello():print("Hello World")return
say_hello函数返回None显然是多此一举.但是有时使用return或者return None是很有必要的:
def sum(*numbers,multiple=1):"""定义可变参数并验证"""if len(numbers) == 0:returntotal = 0.0for number in numbers:total += numberreturn total*multipleprint(sum(30.0,80.0))110.0print(sum(multiple=2))None#如果numbers中数据是空的,后面的求和计算也没有什么意义了,#return或者return None在此处的作用是终止函数继续执行.
多返回值函数
同”无返回值”函数一样,在Python中,也不存在”多返回值函数”,我们无论定义的返回值是什么,return只能返回单值,但值可以存在很多元素。
def yue():print("约你")print("约我")print("约他")return "美女一枚", "萝莉一枚", "成熟女性"girl = yue()print(type(girl)) # tuple
看起来更像是返回了3个值,但是其实Python在返回时,将值封装成了元组。
函数的参数
定义函数的时候,我们把参数的名字和位置定下来,对于函数的调用者来说,只需要知道如何传递正确的参数,以及函数将返回什么样的值就够了,调用者不需要关心函数的实现。
函数通过参数获得了一系列的值,然后让函数体代码利用这些值进行操作,产生我们想要的结果,再返回。举个例子:
def search(sex):print("拿出手机")print("打开陌陌")print('设置筛选条件:性别: %s' %sex)print("找个漂亮的妹子")print("问她,约不约啊!")print("ok 走起")search('女')
参数的分类
Python中,参数分为形参和实参两种
- 形参即为形式上的参数,是函数定义时规定的,函数调用时用以接收实际的值;
- 实参是实际的参数,是我们调用参数时传入的实际的值;
def rectangle_area(width,height): #形参area = width * heightreturn arear_area = rectangle_area(100,200.0) #实参print("100*200的长方形面积:{0:.2f}".format(r_area))
Python中,形参和实参有着不同的形式,我们可以将其进行分类,引用Python手册上的定义,分类如下:
parameter – 形参
function (或方法)定义中的命名实体,它指定函数可以接受的一个 argument (或在某些情况下,多个实参)。有五种形参:
- positional-or-keyword:位置或关键字,指定一个可以作为位置参数 传入也可以作为关键字参数传入的实参。这是默认的形参类型,例如下面的 foo 和 bar:
def func(foo, bar=None): ...
举例说明:
#假定我们在开发一个论坛,需要有一个能够输出用户姓名和年龄的函数>>> def user_info(name,age):... print("{},年龄{}".format(name,age))...>>> user_info("maryy",19)maryy,年龄19#如果没有按照顺序输入,就会产生错误的输出>>> user_info(19,"maryy")19,年龄maryy#可以安装关键字传入>>> user_info(name='lisi',age=30)lisi,年龄30
假如我们的user_info函数不仅仅想要输出用户的姓名和年龄,还想要输出用户的所在地,并且如果不输入所在地时,所在地有默认值。只需要稍加更改即可。
>>> def user_info(name,age,area="Beijing"):... print("{},年龄{},所在地是{}".format(name,age,area))...# 不传入area,则显示默认值>>> user_info("lily",18)lily,年龄18,所在地是Beijing#以位置参数形式传入实参>>> user_info("lucy",19,'shanghai')lucy,年龄19,所在地是shanghai#以关键字形式传入实参>>> user_info("jack",20,area="guangzhou")jack,年龄20,所在地是guangzhou#函数可以同时接收位置参数和关键字参数,一旦有实参是关键字参数,#那么其后面的所有的实参都必须采用关键字参数>>> user_info(area="chongqing","mike",23)File "<stdin>", line 1SyntaxError: positional argument follows keyword argument>>> user_info(area="chongqing",name="mike",age=23)mike,年龄23,所在地是chongqing
- positional-only:仅限位置,指定一个只能按位置传入的参数。Python 中没有定义仅限位置形参的语法。但是一些内置函数有仅限位置形参(比如 abs())。
- keyword-only:仅限关键字,指定一个只能通过关键字传入的参数。仅限关键字形参可通过在函数定义的形参列表中包含单个可变位置形参或者在多个可变位置形参之前放一个 * 来定义,例如下面的 kw_only1 和 kw_only2:
def func(arg, *, kw_only1, kw_only2): ...
例如:
>>> def f(a, *, b):... return a, b...#正确传入,b必须为关键字参数传入>>> f(1, b=2)(1, 2)#错误传入实参>>> f(1,2)Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: f() takes 1 positional argument but 2 were given
- var-positional:可变位置,指定可以提供由一个任意数量的位置参数构成的序列(附加在其他形参已接受的位置参数之后)。这种形参可通过在形参名称前加缀 * 来定义,例如下面的 args:
def func(*args, **kwargs): ...
有时候,允许用户提供任意数量的参数很有用,但是如何来收集这些参数呢?
>>> def print_params(*params):... print(params)...>>> print_params('Testing')('Testing',)>>> print_params(1,2,3) #将收集到的参数放到一个元组中(1, 2, 3)#再定义一个函数def print_params_2(title, *params):print(title)print(params)并尝试调用它:>>> print_params_2('Params:', 1, 2, 3)Params:(1, 2, 3)#因此星号意味着收集余下的位置参数。如果没有可供收集的参数,params将是一个空元组。>>> print_params_2('Nothing:')Nothing:()#带星号的参数也可放在其他位置(而不是最后),但不同的是,#在这种情况下你需要做些额外的工作:使用名称来指定后续参数。>>> def in_the_middle(x, *y, z):... print(x, y, z)...>>> in_the_middle(1, 2, 3, 4, 5, z=7)1 (2, 3, 4, 5) 7>>> in_the_middle(1, 2, 3, 4, 5, 7)Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: in_the_middle() missing 1 required keyword-only argument: 'z'#星号不会收集关键字参数。>>> print_params_2('Hmm...', something=42)Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: print_params_2() got an unexpected keyword argument 'something'
我们以数学为例,给定一组数字a,b,c…,请计算a+b+c+…
这需要定义函数来进行叠加运算,但是我们无法确定形参个数,因为实参,也就是我们进行加法运算的值的个数也是不确定的。
def _sum(*args):sum = 0for n in args:sum = sum + nreturn sumprint(_sum(1,2,5,10))
- var-keyword:可变关键字,指定可以提供任意数量的关键字参数(附加在其他形参已接受的关键字参数之后)。这种形参可通过在形参名称前加缀 ** 来定义,例如上面的 kwargs。
我们可以传入0个或者任意个有着key=>value关系的关键字参数,他们会在函数内部会组装一个字典
def user_info(name,age,**kw):print(name,"年龄",age,"other:",kw)user_info("lucy",19,gender='M',job='Engineer')lucy 年龄 19 other: {'gender': 'M', 'job': 'Engineer'}#此时的可变参数使用的是 **加变量名kw来打包不定个数的关键字参数
形参可以同时指定可选和必选参数,也可以为某些可选参数指定默认值。
def print_params_4(x, y, z=3, *pospar, **keypar):print(x, y, z)print(pospar)print(keypar)#其效果与预期的相同。>>> print_params_4(1, 2, 3, 5, 6, 7, foo=1, bar=2)1 2 3(5, 6, 7){'foo': 1, 'bar': 2}>>> print_params_4(1, 2)1 2 3(){}
argument——参数(实参)
在调用函数时传给 function(或 method)的值。参数分为两种:
- 关键字参数: 在函数调用中前面带有标识符(例如name=)或者作为包含在前面带有 ** 的字典里的值传入。举例来说,3 和 5 在以下对 complex() 的调用中均属于关键字参数:
complex(real=3, imag=5)complex(**{'real': 3, 'imag': 5})
- 位置参数: 不属于关键字参数的参数。位置参数可出现于参数列表的开头以及/或者作为前面带有 * 的 iterable 里的元素被传入。举例来说,3 和 5 在以下调用中均属于位置参数:
complex(3, 5)complex(*(3, 5))
重点:
- 参数会被赋值给函数体中对应的局部变量。
- 在函数调用中,关键字参数必须跟随在位置参数的后面。传递的所有关键字参数必须与函数接受的其中一个参数匹配,它们的顺序并不重要。这也包括非可选参数,不能对同一个参数多次赋值。
- 一般来说,这些可变参数将在形式参数列表的末尾,因为它们收集传递给函数的所有剩余输入参数。出现在 *args 参数之后的任何形式参数都是 ‘仅关键字参数’,也就是说它们只能作为关键字参数而不能是位置参数。
- 可变关键字参数:可接受任意数量的关键字参数(字典);只能作为最后一个参数出现。
函数的属性
python函数为我们提供了很多属性,有一些是经常用到的,有一些则使用比较少,我把这些属性都展示出来,经常用到的我会通过代码给大家演示,剩余的自己课下练习即可。
def eat(food, drink, sex='男'):"""这里描述这个函数是做什么的.例如这函数eat就是吃:param food: food这个参数是什么意思:param drink: drink这个参数是什么意思:return: 执行完这个函数想要返回给调用者什么东西"""print(food, drink,sex)return 666eat('麻辣烫','肯德基')# print(dir(eat)) dir() 获取函数所有的属性['__annotations__', '__call__', '__class__', '__closure__', '__code__','__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__','__eq__', '__format__', '__ge__', '__get__', '__getattribute__','__globals__', '__gt__', '__hash__', '__init__', '__init_subclass__','__kwdefaults__', '__le__', '__lt__', '__module__','__name__', '__ne__', '__new__', '__qualname__', '__reduce__','__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__','__subclasshook__']# 常用的属性print(eat.__doc__) # str类型 获取函数的注释信息print(eat.__name__) # str类型 获取函数名print(eat.__defaults__) # tuple类型 获取默认参数的默认值print(eat.__closure__) # 与闭包函数相关,后面会涉及
作用域
顾名思义,作用域,其实就是起作用的范围。
变量到底是什么呢?可将其视为指向值的名称。因此,执行赋值语句x = 1后,名称x指向值1。这几乎与使用字典时一样(字典中的键指向值),只是你使用的是“看不见”的字典。可以通过vars内置函数来查看:
>>> x = 1>>> scope = vars()>>> print(scope){'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'x': 1, 'scope': {...}}>>> scope['x']1>>> scope['x'] += 1>>> x2>>> print(scope){'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'x': 2, 'scope': {...}}
这种“看不见的字典”称为命名空间或作用域。那么有多少个命名空间呢?除全局作用域外,每个函数调用都将创建一个。既然作用域是其作用的范围,那么范围到底怎么划分呢?
块级作用域
先看一个简单的例子:
>>> if 1 == 1:... name = 'python'...#在条件判断语句代码块以外,name也是生效的>>> print(name)python#在代码块外打印vars()的返回结果#在代码块外部,我们可以看到作用域内存在name变量以及其值>>> print(vars()){'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'x': 2, 'scope': {...}, 'name': 'python'}
在Python中,代码块里的变量,代码块外可以访问到,Python中不存在块级作用域,在Java/C#中,执行上面的代码会提示name没有定义,这些语言是存在块级作用域的。
局部作用域
在代码块之后,我们探究一下函数的声明是否影响了变量起作用的范围,下列代码为例:
>>> def fun():... name = 'liudehua'...>>> print(name)Traceback (most recent call last):File "<stdin>", line 1, in <module>NameError: name 'name' is not defined#我们能够在函数外部打印出name的值吗?答案是否定的。
再看一个例子:
>>> def foo():... x = 42...>>> x = 1>>> foo()>>> x1>>>
在这里,函数foo修改(重新关联)了变量x,但当你最终查看时,它根本没变。这是因为调用foo时创建了一个新的命名空间,供foo中的代码块使用。赋值语句x = 42是在这个内部作用域(局部命名空间)中执行的,不影响外部(全局)作用域内的x。在函数内使用的变量称为局部变量(与之相对的是全局变量)。参数类似于局部变量,因此参数与全局变量同名不会有任何问题。
>>> def output(x): print(x)...>>> x = 1>>> y = 2>>> output(y)2
在函数内部给变量赋值时,该变量默认为局部变量,除非你明确地告诉Python它是全局变量。
全局作用域
在函数内部可以访问全局变量吗?
>>> def print_name():... print(name)...>>> name = 'zhoujielun'>>> print_name()zhoujielun
看来是可以的。如果只是想读取这种变量的值(不重新关联它),通常不会有任何问题。但还是存在出现问题的可能性,比如内部变量的名字和外部全局变量的名字相同,你就会访问不了全局变量。
像这样访问全局变量是众多bug的根源。务必慎用全局变量。
作用域的划分
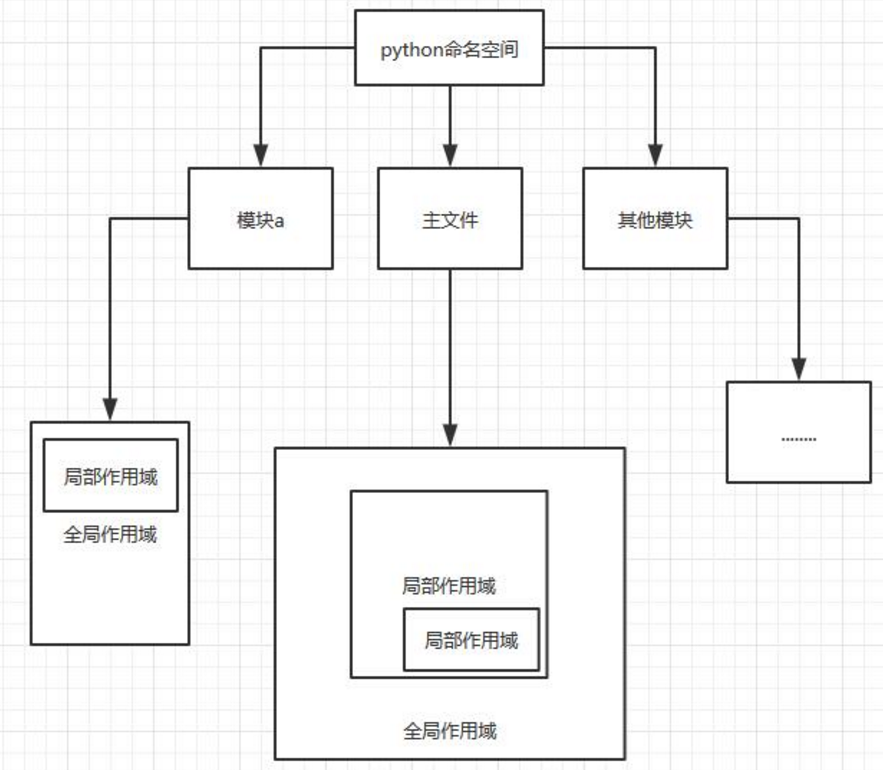
在上文中我们了解到全局作用域和局部作用域和他们的访问规则,也了解到了在全局作用域之外,系统也给我们准备了一系列的内置变量/函数,那么在Python当中,作用域到底有哪些呢?
L(Local)局部作用域
局部变量:包含在def关键字定义的语句块中,即在函数中定义的变量。每当函数被调用时都会创建一个新的局部作用域。在函数内部的变量声明,除非特别的声明为全局变量,否则均默认为局部变量。局部变量域就像一个 栈,仅仅是暂时的存在,依赖创建该局部作用域的函数是否处于活动的状态。所以,一般建议尽量少定义全局变量,因为全局变量在模块文件运行的过程中会一直存在,占用内存空间。
E(enclosing)嵌套作用域
E也包含在def关键字中,E和L是相对的,E相对于更上层的函数而言也是L。与L的区别在于,对一个函数而言,L是定义在此函数内部的局部作用域,而E是定义在此函数的上一层父级函数的局部作用域。
G(global)全局作用域
即在模块层次中定义的变量,每一个模块都是一个全局作用域。也就是说,在模块文件顶层声明的变量具有全局作用域,从外部开来,模块的全局变量就是一个模块对象的属性。
注意:全局作用域的作用范围仅限于单个模块文件内
B(built-in)内置作用域
系统内固定模块里定义的变量,即系统自带的的变量函数之类的。
我们用以下代码和图片表明LEGB的作用范围
#LEGB 作用范围依次增大。name = "lisi" #Gdef get_name():name = "wangwu" #Edef get_inner_name:name = "lucy" #Lprint(__name__) #B
Python 中寻找变量时,如果在局部作用域中有,就直接使用,如果没有,就去上级作用域去寻找,直到全局作用域,全局作用域还没有,再去内置作用域寻找,再没有,就会报错。
name = "lisi"def get_name():def get_outer_name():print(name)get_outer_name()get_name()# "lisi"print(vars)# <built-in function vars>
但是反过来,无论如何,上级作用域是无法访问到下级作用域的。
def get_name():def get_outer_name():name = "lisi"get_outer_name()print(name)get_name()# NameError: global name 'name' is not defined
函数的作用域取决于声明时,而不取决于调用时。
#这段代码看似很简单,但是也需要一定的思考name = "lisi"def f1():print(name)def f2():name = "wangwu"f1()f2()#答案是lisi
内置函数globals()和locals()
这两个内置函数放在这里讲是在合适不过的,他们就直接可以反映作用域的内容,有助于我们理解作用域的范围。
- globals(): 以字典的形式返回全局作用域所有的变量对应关系。
- locals(): 以字典的形式返回当前作用域的变量的对应关系。
这里一个是全局作用域,一个是当前作用域,一定要分清楚,接下来,我们用代码验证:
# 在全局作用域下打印,则他们获取的都是全局作用域的所有的内容。a = 2b = 3print(globals())print(locals())'''{'__name__': '__main__', '__doc__': None, '__package__': None,'__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001806E50C0B8>,'__spec__': None, '__annotations__': {},'__builtins__': <module 'builtins' (built-in)>,'__file__': 'D:/lnh.python/py project/teaching_show/day09~day15/function.py','__cached__': None, 'a': 2, 'b': 3}'''# 在局部作用域中打印。a = 2b = 3def foo():c = 3print(globals()) # 和上面一样,还是全局作用域的内容print(locals()) # {'c': 3}foo()
关键字global和nonlocal
局部作用域对全局作用域的变量(此变量只能是不可变的数据类型)只能进行引用,而不能进行改变,只要改变就会报错。
a = 1def func():print(a)func()a = 1def func():a += 1 # 报错func()
在函数内部给变量赋值时,该变量默认为局部变量,除非你明确地告诉Python它是全局变量。那么如何将这一点告知Python呢?有些时候,我们程序中会遇到局部作用域去改变全局作用域的一些变量的需求,这怎么做呢?这就得用到关键字global:
- global第一个功能:在局部作用域中可以更改全局作用域的变量。
>>> x = 1>>> def change_global():... global x... x = x + 1...>>> change_global()>>> x2
- global第二个功能:利用global在局部作用域也可以声明一个全局变量。
def func():global aa = 3func()print(a)
除了局部作用域和全局作用域出现上述场景,局部作用域和嵌套作用域同样会出现,因为都是由小范围的作用域,访问较大范围的作用域.
def change_outer():num = 10def change_inner():num = num + 10change_inner()change_outer()# UnboundLocalError: local variable 'num' referenced before assignment
出现了同样的错误,我们做一下类比,很容易就能想到,change_outer函数作用范围比较大,相当于”全局”,而change_inner函数嵌套在内部,可以看作”局部”,同理,上述代码运行也会报错,因为同样是内部作用域尝试改变外部作用域中变量的引用,这是绝对不允许的。
但是此时我们不能过用global关键字,因为global关键字无论在何处声明变量,关联的均为全局变量。现在我们想要在嵌套作用域中访问并修改上级作用域中的变量,可以使用nolocal关键字。
>>> def change_outer():... num = 10... def change_inner():... nonlocal num... num = num + 10... change_inner()... print(num)...>>> change_outer()20
这样,通过nonlocal修饰,在嵌套作用域可以访问并修改上层的局部作用域中的变量。我们也能理解,范围的大小是相对而言的。
同样,两层的变量num如果不做更改,实质上是同一个引用
def change_outer():num = 10print(id(num)) # 4562293168def change_inner():nonlocal numprint(id(num)) # 4562293168change_inner()change_outer()
同时需要注意,nonlocal既然是修饰嵌套作用域内的变量,那就不能够出现在全局,也不能出现在最外层函数内部。以下的写法都是错误的。
num = 10def change_outer():nonlocal numnum = 20change_outer()# SyntaxError: no binding for nonlocal 'num' foundnonlocal numdef change_outer():num = 20change_outer()# SyntaxError: nonlocal declaration not allowed at module level
注意:nonlocal是Python3新加的功能。
高阶函数
- 只要遇见了()就是函数的调用. 如果没有()就不是函数的调用
- 函数的执行顺序
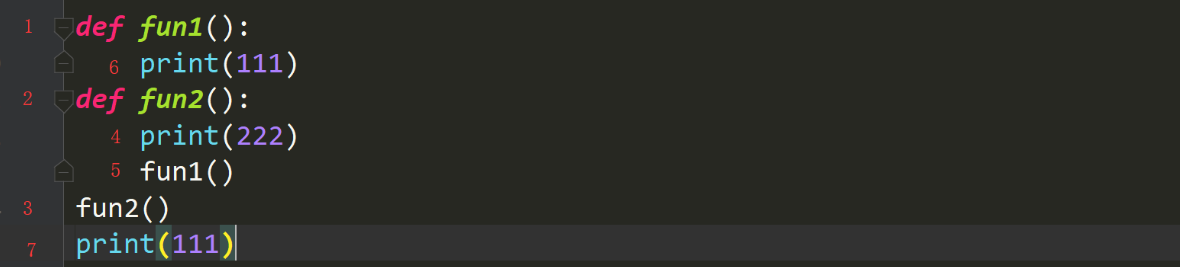
def fun1():print(111)def fun2():print(222)fun1()fun2()print(111)
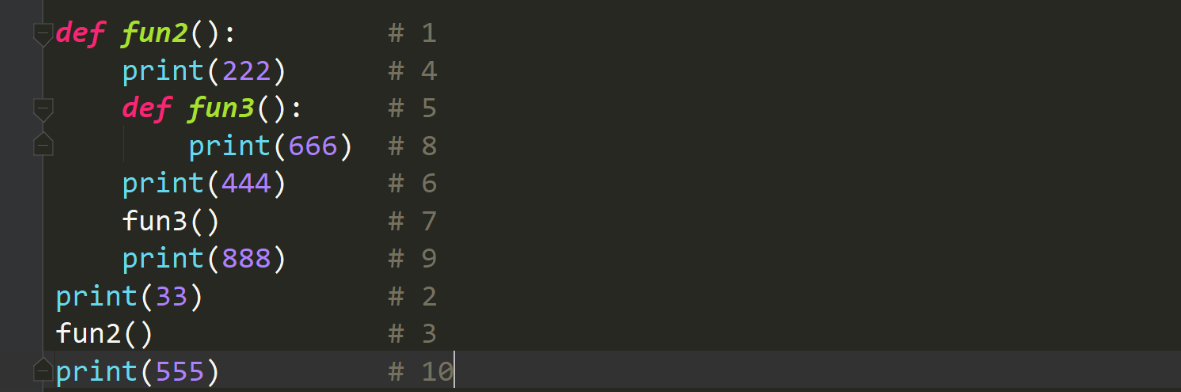
def fun2():print(222)def fun3():print(666)print(444)fun3()print(888)print(33)fun2()print(555)

若有收获,就点个赞吧
0 人点赞
