业务服务监控详解
业务服务监控是运维体系中最重要的环节,是保证业务服务质量的关键手段。如何更有效地实现业务服务,是每个运维人员应该思考的问题,不同业务场景需要定制不同的监控策略。Python在监控方面提供了大量的第三方工具,可以帮助我们快速、有效地开发企业级服务监控平台,为我们的业务保驾护航。
一. 文件内容差异对比方法
difflib是一个Python标准库模块,主要功能是实现文件内容的差异对比,且支持生成可读性强的HTML文档,与Linux中的diff命令相似。可以用来比较代码、配置文件等的差异,在版本控制方面是非常有用。
#!/usr/bin/python3import difflibtxt1 = '''txt1:Someone like youauthor:AdeleI heard,that your settled down.That you, found a girl and your married now.I heard that your dreams came true.Guess she gave you things, I didn't give to you.'''txt2 = '''txt2:Someone like youauthor:AdeleThat you, found a girl and your married now.Guess she gave you things, I didn't give to you.I heard that your dreams came true.'''txt1s = txt1.splitlines() ##以行进行分割,以便进行对比txt2s = txt2.splitlines()D = difflib.Differ() ##创建Differ()对象diff = D.compare(txt1s,txt2s) ##采用compare方法对字符串进行比较print('\n'.join(list(diff)))
运行结果:
[root@localhost difflib-test]# ./simple1.py- txt1:? ^+ txt2:? ^- Someone like you+ Someone like you? +++++author:Adele- I heard,that your settled down.That you, found a girl and your married now.+ Guess she gave you things, I didn't give to you.I heard that your dreams came true.- Guess she gave you things, I didn't give to you.
符号含义说明:
| 符号 | 含义 |
|---|---|
| ‘-’ | 包含在第一个序列行中,但不包含在第二个序列行中 |
| ‘+’ | 包含在第二个序列行中,但不包含在第一个序列行中 |
| ’ ’ | 两个序列行一致 |
| ‘?’ | 标志两个序列行存在增量差异 |
| ‘^’ | 标志出两个序列行存在的差异字符 |
生成美观的对比HTML格式文档:
上例不便阅读,可以生成更易读的html文档,方法如下:
#!/usr/bin/python3import difflibtxt1 = '''txt1:Someone like youauthor:AdeleI heard,that your settled down.That you, found a girl and your married now.I heard that your dreams came true.Guess she gave you things, I didn't give to you.'''txt2 = '''txt2:Someone like youauthor:AdeleThat you, found a girl and your married now.Guess she gave you things, I didn't give to you.I heard that your dreams came true.'''txt1s = txt1.splitlines()txt2s = txt2.splitlines()D = difflib.HtmlDiff()diff = D.make_file(txt1s,txt2s) ##将比较结果输出为HTML格式HTML = 'ret.html'with open(HTML,'w') as f:f.write(diff)
运行结果后生成ret.html文件,使用浏览器打开可以看到结果:
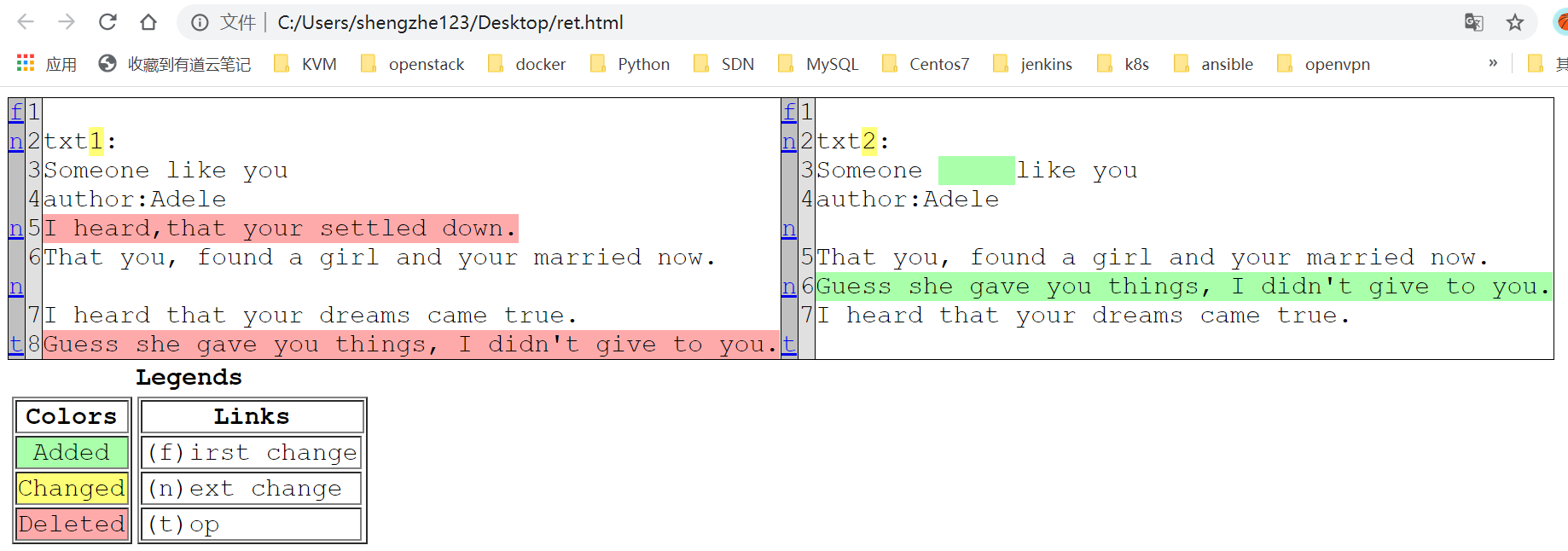
上例仅展示了比较文本变量之间的差异,如果要比较文件,可以将两个文件以readlines()的方法将两个文件读成列表,然后使用同样的方法进行对比。
示例:对比Nginx配置文件差异
当维护多个Nginx配置时,时常会对比不同版本配置文件的差异,使运维人员更加清晰了解不同版本迭代后的更新项,实现思路是读取两个需对比的配置文件,再以换行符作为分隔符,调用difflib.HtmlDiff()生成HTML格式的差异文件。
#!/usr/bin/python3import difflibimport systry:textfile1 = sys.argv[1] ##第一个配置文件路径参数textfile2 = sys.argv[2] ##第二个配置文件路径参数except Exception as e:print('Error:'+str(e))print("Usage: {} filename1 filename2".format(sys.argv[0]))sys.exit()def readfile(filename): ##定义文件读取分隔函数try:fileHandle = open(filename,'r')text = fileHandle.read().splitlines() ##读取后以行进行分隔fileHandle.close()return textexcept IOError as error:print('Read file Error: {}'.format(error))sys.exit()if textfile1 == "" or textfile2 == "":print("Usage: {} filename1 filename2".format(sys.argv[0]))sys.exit()text1_lines = readfile(textfile1) ##调用readfile()函数,获取分隔后的字符串text2_lines = readfile(textfile2)D = difflib.HtmlDiff() ##创建HtmlDiff()类对象diff = D.make_file(text1_lines,text2_lines) ##通过make_file方法输出HTML格式的比对结果HTML = 'ret.html'with open(HTML,'w') as f:f.write(diff)
运行以上代码即可:
# python3 simple3.py nginx.conf.v1 nginx.conf.v2
二. 文件与目录差异对比方法
出于对代码审计或校验备份等目的,有时需要检测原始目录与目标目录文件及目录的一致性。Python提供了标准模块filecmp,filecmp可以实现文件,目录,遍历子目录差异对比功能。得到目录之前的差异,以及对比文件内容来确认是否为同一文件。
filecmp提供了三个操作方法:
- cmp(单文件比较)
- cmpfiles(多文件对比)
- dircmp(对比目录)
2.1 单文件对比
filecmp.cmp(f1,f2 [,shallow])
比较文件f1 f2,相同返回True,不同返回False,shallow默认为True,意义为根据文件os.stat()得到的基本信息(最后访问时间,修改时间,状态改变时间等)进行确认是否为同一文件,而不是比较文件内容。当shallow为False时,则os.stat()与文件内容同时校验。
#!/usr/bin/python3import filecmptry:ret = filecmp.cmp('/root/1.txt','/root/1.html')except Exception as e:print('error: {}'.format(e))else:print('为同一文件' if ret else '不为同一文件')
2.2 多文件对比
filecmp.cmpfiles(dir1,dir2,common[,shallow])
比较dir1与dir2目录中的common定义的文件。并返回一个包含三个列表的元组。
- 第一个列表:两个目录中匹配的文件
- 第二个列表:两个目录中不匹配的文件
- 第三个列表:错误列表,包括不存在的文件,不具备读权限等无法比较的文件清单。
#!/usr/bin/python3import filecmp##定义需要对比的文件名files = ['f1.txt','f2.txt','f3.txt','f4.txt','f5.txt']##equal:文件相同的列表##notequal:文件不同的列表##error:文件错误列表equal,notequal,error = filecmp.cmpfiles('/root/cba','/root/nba',files)print(equal)print(notequal)print(error)
创建文件,执行结果如下:
[root@localhost filecmp-test]# ./filecap02.py['f1.txt', 'f2.txt']['f3.txt']['f4.txt', 'f5.txt']
2.3 目录对比
dircmp(a,b[,ignore[,hide]])
通过dircmp类创建一个目录比较对象。
- 其中a和b是参加比较的目录名;
- ignore代表文件名忽略的列表,并默认为[‘RCS’,‘CVS’,‘tags’];
- hide代表隐藏的列表,默认为[os.curdir, os.pardir]。
dircmp类可以获得目录比较的详细信息,如只有在a目录中包括的文件、a与b都存在的子目录、匹配的文件等,同时支持递归。
dircmp提供了三个输出报告的方法:
- report(),比较当前指定目录中的内容
- report_partial_closure(),比较当前指定目录及第一级子目录中的内容;
- report_full_closure(),递归比较所有指定目录的内容。
为输出更加详细的比较结果,dircmp类还提供了以下属性:
- left:左目录,如类定义中的a
- right:右目录,如类定义中的b
- left_list:左目录中的文件及目录列表
- right_list:右目录中的文件及目录列表
- common:两边目录共同存在的文件或目录
- left_only:只在左目录中的文件或目录
- right_only:只在右目录中的文件或目录
- common_dirs:两边目录都存在的子目录
- common_files:两边目录都存在的子文件
- common_funny:两边目录都存在的子目录(不同目录类型或os.stat()记录的错误)
- same_files:匹配相同的文件
- diff_files:不匹配的文件
- funny_files:两边目录中都存在,但无法比较的文件
- subdirs:将common_dirs目录名映射到新的dircmp对象,格式为字典类型。
示例:对比dir1和dir2的目录差异
通过调用dircmp()方法实现目录差异对比功能,同时输出目录对比对象所有属性信息。
#!/usr/bin/pythonimport filecmpa = '/root/test/filecmp/dir1' ##定义左目录b = '/root/test/filecmp/dir2' ##定义右目录dirobj = filecmp.dircmp(a,b,['test.py']) ##目录比较,忽略test.py文件##输出对比结果数据报表,详细说明参考filecmp类方法及属性信息dirobj.report()dirobj.report_partial_closure()dirobj.report_full_closure()print('left_list: {}'.format(str(dirobj.left_list)))print('right_list: {}'.format(str(dirobj.right_list)))print('common: {}'.format(str(dirobj.common)))print('left_only: {}'.format(str(dirobj.left_only)))print('right_only: {}'.format(str(dirobj.right_only)))print('common_dirs: {}'.format(str(dirobj.common_dirs)))print('common_files: {}'.format(str(dirobj.common_files)))print('common_funny: {}'.format(str(dirobj.common_funny)))print('same_files: {}'.format(str(dirobj.same_files)))print('diff_files: {}'.format(str(dirobj.diff_files)))print('funny_files: {}'.format(str(dirobj.funny_files)))
查看两个目录的树结构:
[root@localhost ~]# tree -C /root/test/filecmp/dir1/root/test/filecmp/dir1├── a│ ├── a1│ └── b│ ├── b1│ ├── b2│ └── b3├── f1├── f2├── f3├── f4└── test.py[root@localhost ~]# tree -C /root/test/filecmp/dir2/root/test/filecmp/dir2├── a│ ├── a1│ └── b│ ├── b1│ ├── b2│ └── b3├── aa│ └── aa1├── f1├── f2├── f3├── f5└── test.py
运行代码输出结果如下:
[root@localhost filecmp-test]# ./filecap03.py----------------report------------------diff /root/test/filecmp/dir1 /root/test/filecmp/dir2Only in /root/test/filecmp/dir1 : ['f4']Only in /root/test/filecmp/dir2 : ['aa', 'f5']Identical files : ['f1', 'f2', 'f3']Common subdirectories : ['a']diff /root/test/filecmp/dir1 /root/test/filecmp/dir2Only in /root/test/filecmp/dir1 : ['f4']Only in /root/test/filecmp/dir2 : ['aa', 'f5']Identical files : ['f1', 'f2', 'f3']Common subdirectories : ['a']---------------report_partial_closure--------------diff /root/test/filecmp/dir1/a /root/test/filecmp/dir2/aIdentical files : ['a1']Common subdirectories : ['b']diff /root/test/filecmp/dir1 /root/test/filecmp/dir2Only in /root/test/filecmp/dir1 : ['f4']Only in /root/test/filecmp/dir2 : ['aa', 'f5']Identical files : ['f1', 'f2', 'f3']Common subdirectories : ['a']diff /root/test/filecmp/dir1/a /root/test/filecmp/dir2/aIdentical files : ['a1']Common subdirectories : ['b']-------------report_full_closure-------------diff /root/test/filecmp/dir1/a/b /root/test/filecmp/dir2/a/bIdentical files : ['b1', 'b2', 'b3']left_list: ['a', 'f1', 'f2', 'f3', 'f4']right_list: ['a', 'aa', 'f1', 'f2', 'f3', 'f5']common: ['a', 'f1', 'f2', 'f3']left_only: ['f4']right_only: ['aa', 'f5']common_dirs: ['a']common_files: ['f1', 'f2', 'f3']common_funny: []same_files: ['f1', 'f2', 'f3']diff_files: []funny_files: []
三. 发送电子邮件模块 smtplib
电子邮件是最流行的互联网应用之一。在系统管理领域,常常使用邮件来发送告警信息、业务质量报表等,方便运维人员第一时间了解业务的服务状态。通过Python的smtplib模块可以实现邮件的发送功能,相当于模拟了一个smtp客户端,通过与smtp服务器交互实现了发送邮件功能。
3.1 smtplib模块的常用类与方法
SMTP类定义:
smtplib.SMTP([host[,port[,local_hostname[,timeout]]]])
作为SMTP的构造函数,功能是与smtp服务器建立连接,在连接建立成功后,就可以与服务器发送相关请求,比如登录、校验、发送、退出等。
- host参数为远程smtp主机地址
- port参数为连接端口,默认25
- local_hostname的作用是用本地主机的FQDN发送HELO/EHLO(标识用户身份)指令
- timeout为连接或尝试在多少秒超时
SMTP类具有如下方法:
SMTP.connect([host[,port]])方法,连接运城stmp主机方法,host为远程主机地址,port为远程主机smtp端口,默认25,也可以使用host:port形式来表示,例如:SMTP.connect('smtp.163.com','25')SMTP.login(user,password)方法,远程smtp主机的验证方法,参数为用户名与密码,如SMTP.login('python_2020@163.com','sdjkg358')SMTP.sendmail(from_addr,to_addrs,msg[,mail_options,rcpt_options])方法,实现邮件的发送功能,参数依次为发件人、收件人、邮件内容,例如:SMTP.sendmail('python_2020@163.com','demo@domail.com',body),其中body内容定义如下:
``` From: python_2020@163.com TO: demo@domail.com Subject: test mail
test mail body
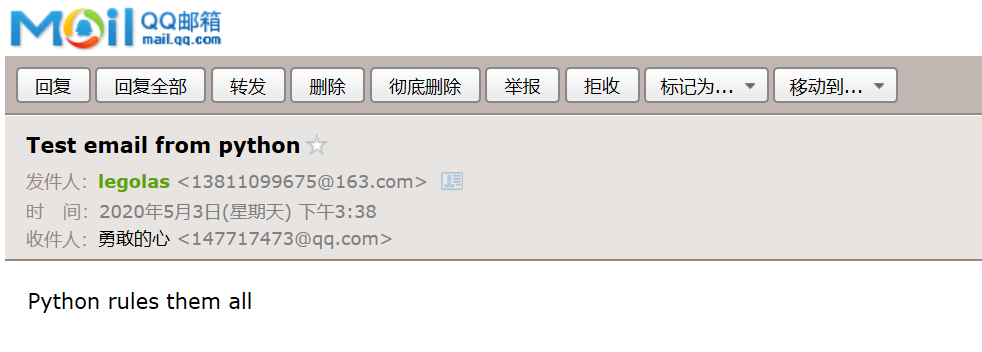
- `SMTP.starttls([keyfile[,certfile]])`方法,启用TLS(安全传输)模式,所有SMTP指令都将加密传输,例如使用gmail的smtp服务时需要启动此项才能正常发送邮件,如SMTP.starttls()。- `SMTP.quit()`方法,断开smtp服务器的连接。测试案例:```python#!/usr/bin/python3import smtplibHOST = "smtp.163.com" ##定义smtp主机SUBJECT = "Test email from python" ##定义邮件主题TO = "147717473@qq.com" ##定义邮件收件人FROM = "13811099675@163.com" ##定义邮件发件人text = "Python rules them all" ##邮件内容BODY = "\r\n".join(( ##组装sendmail方法的邮件主体内容,各段以“\r\n”进行分隔"From: %s" % FROM,"To: %s" % TO,"Subject: %s" % SUBJECT,"",text))server = smtplib.SMTP() ##创建一个SMTP()对象server.connect(HOST,'25') ##通过connect方法连接smtp主机server.starttls(), ##启动安全传输模式server.login('13811099675@163.com','客户端验证码') ##邮箱账号登录校验server.sendmail(FROM, [TO], BODY) ##邮件发送server.quit() ##断开smtp连接
执行程序后将收到邮件:
以上发送邮件只能以最简单的文本作为邮件主题,有时需要在邮件中发送图片或者附件,下面进行发送图片和附件讲解。
MIME (Multipurpose Internet Mail Extensions多用途互联网邮件扩展) 作为一种新的扩展邮件格式很好的完成了发送丰富媒体的功能。
email.mime.multipart.MIMEMultipart([_subtype[,boundary[,_subparts[,,_params]]]])
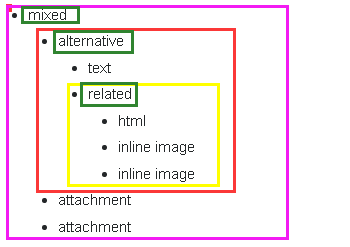
作用是生成包含多个部分的邮件体的MIME对象,参数_subtype指定要添加到“Content-type:multipart/subtype”报头的可选的三种子类型,分别为mixed、related、alternative,默认值为mixed。
- 定义mixed实现构建一个带附件的邮件体
- 定义related实现构建内嵌资源的邮件体
- 定义alternative则实现构建纯文本与超文本共存的邮件体
三者关系图如下所示:
email.mime.audio.MIMEAudio(_audiodata[,_subtype[,_encoder[,**_params]]])
创建包含音频数据的邮件体,_audiodata包含原始二进制音频数据的字节字符串。
email.mime.image.MIMEImage(_imagedata[,_subtype[,_encoder[,**_params]]])
创建包含图片数据的邮件体,_imagedata是包含原始图片数据的字节字符串。
email.mime.text.MIMEText(_text[,_subtype[,_charset]])
创建包含文本数据的邮件体,_text是包含消息负载的字符串,_subtype指定文本类型,支持plain(默认值)或html类型的字符串。
3.2 发送纯文本邮件
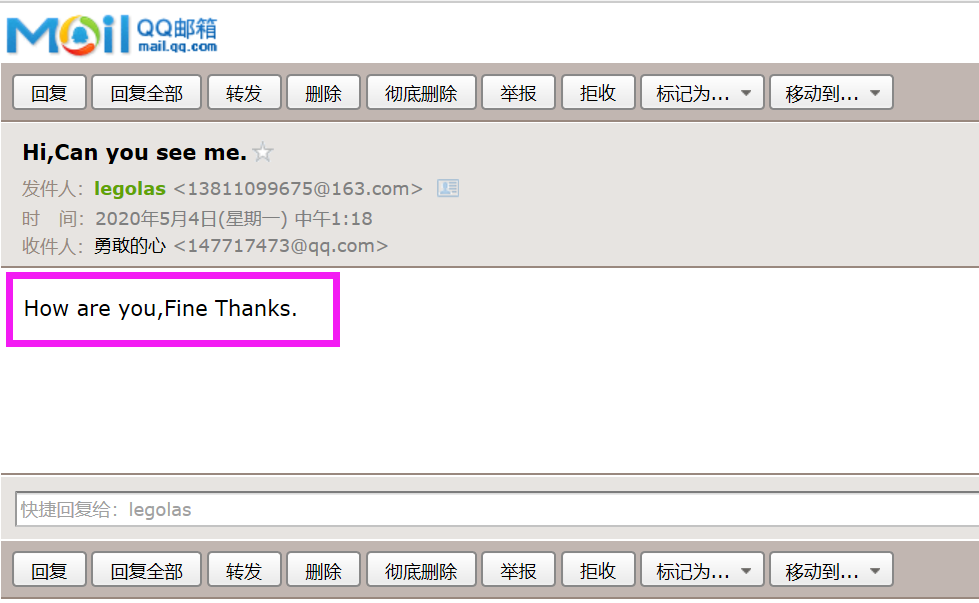
使用方法 : 脚本名 收信邮箱 主题 内容
# ./mail03.py 147717473@qq.com 'Hi,Can you see me.' 'How are you,Fine Thanks.'send to 147717473@qq.com success!
脚本内容如下:
#!/usr/bin/python3import smtplibimport sysfrom email.mime.text import MIMETextdef send_mail(rec_user,subject,content): ##定义发送邮件函数send_mailsmtp_host = 'smtp.163.com'smtp_user = '13811099675@163.com'smtp_pass = '这里填写邮件客户端验证码'msg = MIMEText(content,_subtype='plain')msg['Subject'] = subjectmsg['From'] = smtp_usermsg['To'] = rec_userserver = smtplib.SMTP()server.connect(smtp_host)server.starttls()server.login(smtp_user,smtp_pass)server.sendmail(smtp_user,rec_user,msg.as_string())server.quit()if __name__ == '__main__':rec_user = sys.argv[1].strip()subject = sys.argv[2].strip()content = sys.argv[3].strip()try:send_mail(rec_user,subject,content)except Exception as e:print('send error:{}'.format(e))else:print('send to {} success!'.format(rec_user))
结果如下:
3.3 发送图片和附件的邮件示例
#!/usr/bin/python3# -*- coding: UTF-8 -*-'''注意:直接运行此脚本方法:”脚本名 收信邮箱“.'''import smtplib,sys# MIMEMultipart可以将多个MIME对象进行封装from email.mime.multipart import MIMEMultipartfrom email.mime.image import MIMEImagefrom email.mime.text import MIMEText#添加图片函数def addimg(src,imgid):fp = open(src,'rb')msgImage = MIMEImage(fp.read())fp.close()msgImage.add_header('Content-ID',imgid)return msgImagedef send_mail(SMTP,SMTP_USER,SMTP_PASS,TO_USER,SUBJECT,IMG,ATTACHMENT):'''参数分别为:SMTP: smtp服务器地址如 smtp.163.comSMTP_USER :smtp用户如 hogwartslord@163.comSMTP_PASS :smtp用户的密码TO_USER :邮件发送给谁SUBJECT :邮件主题IMG :要发送的图片ATTACHMENT :要发送的附件'''msg = MIMEMultipart('mixed')msgtext = MIMEText("<font color=red> 这是一个测试:<br><img src=\"cid:testimg\"><br>详情见附件.</font>","html","utf-8")#MIMEMultipart(msg) 加入 MIMEText对象msgtextmsg.attach(msgtext)#MIMEMultipart(msg) 加入 MIMEImage对象(msgImage),注意文本中的 src="cid:testimg",一定要对应图片的 ‘Content-ID'msg.attach(addimg(IMG,"testimg"))#创建附件attachment = MIMEText(open(ATTACHMENT,'rb').read(),'base64','utf-8')attachment["Content-Type"] = "application/octet-stream"#指定邮件中附件的名字attachment["Content-Disposition"] = 'attachment; filename="{}"'.format(ATTACHMENT)msg.attach(attachment)msg['Subject'] = SUBJECTmsg['From'] = SMTP_USERmsg['To'] = TO_USERserver = smtplib.SMTP()server.connect(SMTP)server.login(SMTP_USER, SMTP_PASS)server.sendmail(SMTP_USER, TO_USER, msg.as_string())server.close()if __name__ == '__main__':TO_USER = sys.argv[1]SMTP = 'smtp.163.com'# 用户和密码,现在邮箱一般安全性比较好,无法直接使用登录密码,# 需在要邮箱后台设置第三方登录密码SMTP_USER = '13811099675@163.com'SMTP_PASS = '修改成客户端验证码'SUBJECT = r'邮件测试'IMG = r'one_punch_man.jpg'ATTACHMENT = r'mail_test.xlsx'try:send_mail(SMTP,SMTP_USER,SMTP_PASS,TO_USER,SUBJECT,IMG,ATTACHMENT)print('send mail success!')except Exception as e:print('send failure .Error: {}'.format(str(e)))
运行程序
# ./mail04.py 147717473@qq.com
结果如下:
四. 探测web服务质量方法
pycurl 是一个用C语言写的libcurl Python实现,功能非常强大,支持的协议有 FTP,HTTP,HTTPS,TELNET等,相当于linux中的curl命令。本节通过pycurl探测web服务质量(响应的HTTP状态码、请求延时、HTTP头信息、下载速度等)。
安装:
[root@localhost ~]# yum install libcurl-devel libcurl curl -y[root@localhost ~]# pip3 install pycurl
如果安装后import 提示如下错误:
n [1]: import pycurl---------------------------------------------------------------------------ImportError Traceback (most recent call last)<ipython-input-1-141165d68a5f> in <module>----> 1 import pycurlImportError: pycurl: libcurl link-time ssl backend (nss) is different from compile-time ssl backend (none/other)
解决方法:
[root@localhost ~]# pip3 uninstall pycurl[root@localhost ~]# export PYCURL_SSL_LIBRARY=nss[root@localhost ~]# pip3 install pycurl
4.1 pycurl模块常用方法
pycurl.Curl()类实现创建一个libcurl包的Curl句柄对象,无参数。Curl对象几个常用方法如下:
- close()方法,对应libcurl包中的curl_easy_cleanup方法,无参数,实现关闭、回收Curl对象。
- perform()方法,对应libcurl包中的curl_easy_perform方法,无参数,实现Curl对象请求的提交。
setopt(option,value)方法,对应libcurl包中的curl_easy_setopt方法,参数option是通过libcurl的常量来指定的,参数value的值会依赖option,可以是一个字符串、整型、长整型、文件对象、列表或函数等。下面列举常用的常量列表:
c = pycurl.Curl() #创建一个curl对象c.setopt(pycurl.CONNECTTIMEOUT, 5) #连接的等待时间,设置为0则不等待c.setopt(pycurl.TIMEOUT,5) #请求超时时间c.setopt(pycurl.NOPROGRESS, 0) #是否屏蔽下载进度条,非0则屏蔽c.setopt(pycurl.MAXREDIRS, 5) #指定HTTP重定向的最大数c.setopt(pycurl.FORBID_REUSE, 1) #完成交互后强制断开连接,不重用c.setopt(pycurl.FRESH_CONNECT, 1) #强制获取新的连接,即代替缓存中的连接c.setopt(pycurl.DNS_CACHE_TIMEOUT, 60) #设置保存DNS信息的时间,默认为120秒c.setopt(pycurl.URL, "http://www.baidu.com") #指定请求的URLc.setopt(pycurl.USERAGENT,"Mozilla/5.2 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50324)") #配置请求HTTP头的User-Agentc.setopt(pycurl.HEADERFUNCTION, getheader) #将返回的HTTP HEADER定向到回调函数getheaderc.setopt(pycurl.WRITEFUNCTION, getbody) #将返回的内容定向到回调函数getbodyc.setopt(pycurl.WRITEHEADER, fileobj) #将返回的HTTP HEADER 定向到fileobj文件对象c.setopt(pycurl.WRITEDATA, fileobj) #将返回的HTML内容定向到fileobj文件对象
getinfo(option)方法,对应libcurl包中的curl_easy_getinfo方法,参数option是通过libcurl的常量来指定的。下面列举常用的常量列表:
c = pycurl.Curl() #创建一个curl对象c.getinfo(pycurl.HTTP_CODE) #返回的HTTP状态码c.getinfo(pycurl.TOTAL_TIME) #传输结束所消耗的总时间c.getinfo(pycurl.NAMELOOKUP_TIME) #DNS解析所消耗的时间c.getinfo(pycurl.CONNECT_TIME) #建立连接所消耗的时间c.getinfo(pycurl.PRETRANSFER_TIME) #从建立连接到准备传输所消耗的时间c.getinfo(pycurl.STARTTRANSFER_TIME) #从建立连接到传输开始消耗的时间c.getinfo(pycurl.REDIRECT_TIME) #重定向所消耗的时间c.getinfo(pycurl.SIZE_UPLOAD) #上传数据包的大小c.getinfo(pycurl.SIZE_DOWNLOAD) #下载数据包的大小c.getinfo(pycurl.SPEED_UPLOAD) #平均上传速度c.getinfo(pycurl.SPEED_DOWNLOAD) #平均下载速度c.getinfo(pycurl.HEADER_SIZE) #HTTP头部大小
4.2 实现探测web服务质量
HTTP服务质量一般有两个标准:
- 一为服务可用性,比如是否处于正常提供服务状态,而不是出现404页面未找到或500页面错误等。
- 二为服务响应速度,如静态类文件下载时间都要控制在毫秒级,动态CGI资源控制在秒级。
使用python+pycurl来检测网站性能,时间单位默认为秒。
注意:各个阶段时间是从客户端发起URL请求时到某个阶段的时间差,而不是某个阶段开始时间到结束时间差。
total_time = curl_obj.getinfo(pycurl.TOTAL_TIME) #传输结束所消耗的总时间dns_time = curl_obj.getinfo(pycurl.NAMELOOKUP_TIME) #从发起请求到DNS解析完成所消耗的时间connect_time = curl_obj.getinfo(pycurl.CONNECT_TIME) #从发起请求到建立连接所消耗的时间redirect_time = curl_obj.getinfo(pycurl.REDIRECT_TIME) #从发起请求到重定向所消耗的时间ssl_time = curl_obj.getinfo(pycurl.APPCONNECT_TIME) #从发起请求到SSL建立握手时间pretrans_time = curl_obj.getinfo(pycurl.PRETRANSFER_TIME) #从发起请求到准备传输所消耗的时间starttrans_time = curl_obj.getinfo(pycurl.STARTTRANSFER_TIME) #从发起请求到接收第一个字节的时间
pycurl的各个阶段(根据pycurl.*_TIME统计)
依次为:DNS解析–>TCP连接–>重定向(如有)–>SSL握手(如有)–>客户端发送请求–>服务器响应–>数据传输
StringIO模块简介
读写磁盘上的文件速度是非常慢的,为了解决这一问题我们可以将文件直接写在内存中,还不需要向磁盘中写入。注意 sgringIO 只能写入字符串,如果要写入二进制文件,可以使用BytesIO。
在python2中可以直接使用StringIO模块,不过python3中将 io 相关模块全部放在了 io 包中。
In [1]: from io import StringIO# from io import BytesIO#创建一个stringio对象In [2]: f = StringIO()# f = StringIO('abc 123')#向stringio对象中写入字符串In [3]: f.write('abc')Out[3]: 3In [4]: f.write('xyz\n')Out[4]: 4In [5]: ret = f.getvalue()In [6]: print(ret)abcxyz#清空StringIO对象In [7]: f.seek(0,0)Out[7]: 0In [8]: f.truncate()Out[8]: 0In [9]: ret = f.getvalue()In [10]: print(ret)
pycurl 的一个小示例:
下载一张图片,并打印一些相关信息
#!/usr/bin/python3import pycurlfrom io import BytesIO##定义存放响应头和响应体的文件对象theader = BytesIO()body_f = open('/root/img.jpg','wb')R = pycurl.Curl()R.setopt(pycurl.URL,'https://up.enterdesk.com/edpic/46/62/6d/46626dbde6841f2545b2027027f20e42.jpg')R.setopt(pycurl.SSL_VERIFYPEER,0) #对于某些采用HTTPS的网站,有时会因为证书验证失败而无法正常访问,pycurl模块提供了取消验证过程的功能。R.setopt(pycurl.SSL_VERIFYHOST,0)R.setopt(pycurl.WRITEFUNCTION,body_f.write)R.setopt(pycurl.HEADERFUNCTION,theader.write)R.perform()##得到一些感兴趣的信息tmp = R.getinfo(pycurl.TOTAL_TIME)print(tmp)tmp = R.getinfo(pycurl.SIZE_DOWNLOAD)print(tmp)head = theader.getvalue()head = head.decode()print(head)R.close()
实现一个测试指定URL服务质量的脚本
#!/usr/bin/python3import sysimport pycurlfrom io import BytesIOclass url_detect():def __init__(self,url):self.url = url.strip()if not (self.url.startswith('https://') or self.url.startswith('http://')):raise ValueError('url {} must start with https or http.'.format(self.url))#创建一个StringIO对象用于存放响应的内容strio = BytesIO()# 创建一个curl对象self._curl = pycurl.Curl()self._curl.setopt(pycurl.USERAGENT,'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36')#禁用CA验证self._curl.setopt(pycurl.SSL_VERIFYPEER,0)self._curl.setopt(pycurl.SSL_VERIFYHOST,0)#连接的等待时间,设置为0则不等待self._curl.setopt(pycurl.CONNECTTIMEOUT,5)##请求超时时间self._curl.setopt(pycurl.TIMEOUT,5)##是否屏蔽下载进度条,非0则屏蔽self._curl.setopt(pycurl.NOPROGRESS,1)##指定HTTP重定向的最大数self._curl.setopt(pycurl.MAXREDIRS,5)##完成交互后强制断开连接,不重用self._curl.setopt(pycurl.FORBID_REUSE,1)##强制获取新的连接,即替代缓存中的连接self._curl.setopt(pycurl.FRESH_CONNECT,1)##设置保存DNS信息的时间,默认为120秒self._curl.setopt(pycurl.DNS_CACHE_TIMEOUT,1)##指定请求的URLself._curl.setopt(pycurl.URL, self.url)##指定响应内容后的回调函数self._curl.setopt(pycurl.WRITEFUNCTION, strio.write)##访问页面self._curl.perform()def get_relative_time(self):#从发起请求到DNS解析完成所消耗的时间dns_time = self._curl.getinfo(pycurl.NAMELOOKUP_TIME)#从发起请求到建立连接所消耗的时间connect_time = self._curl.getinfo(pycurl.CONNECT_TIME)#从发起请求到重定向所消耗的时间redirect_time = self._curl.getinfo(pycurl.REDIRECT_TIME)#从发起请求到SSL建立握手时间ssl_time = self._curl.getinfo(pycurl.APPCONNECT_TIME)#从发起请求到准备传输所消耗的时间pretrans_time = self._curl.getinfo(pycurl.PRETRANSFER_TIME)#从发起请求到接收到第一个字节的时间starttrans_time = self._curl.getinfo(pycurl.STARTTRANSFER_TIME)#传输结束所消耗的总时间total_time = self._curl.getinfo(pycurl.TOTAL_TIME)# 下面为每个阶段和发起请求之前的时间差,相对时间print('发起请求到DNS解析时间:%.3f ms' % (dns_time * 1000))print('发起请求到TCP连接完成时间:%.3f ms' % (connect_time * 1000))print('发起请求到跳转完成时间:%.3f ms' % (redirect_time * 1000))print('发起请求到SSL建立完成时间:%.3f ms' % (ssl_time * 1000))print('发起请求到客户端发送请求时间:%.3f ms' % (pretrans_time * 1000))print('发起请求到客户端接受首包时间:%.3f ms' % (starttrans_time * 1000))print('总时间为:%.3f ms' % (total_time * 1000))def get_absolute_time(self):'''获取绝对时间,即每个阶段所使用时间。需要一个pycurl对象。'''#从发起请求到DNS解析完成所消耗的时间dns_time = self._curl.getinfo(pycurl.NAMELOOKUP_TIME)#从发起请求到建立连接所消耗的时间connect_time = self._curl.getinfo(pycurl.CONNECT_TIME)#从发起请求到重定向所消耗的时间redirect_time = self._curl.getinfo(pycurl.REDIRECT_TIME)#从发起请求到SSL建立握手时间ssl_time = self._curl.getinfo(pycurl.APPCONNECT_TIME)#从发起请求到准备传输所消耗的时间pretrans_time = self._curl.getinfo(pycurl.PRETRANSFER_TIME)#从发起请求到接收第一个字节的时间starttrans_time = self._curl.getinfo(pycurl.STARTTRANSFER_TIME)#传输结束所消耗的总时间total_time = self._curl.getinfo(pycurl.TOTAL_TIME)#下面为每个阶段所用时间,绝对时间transfer_time = total_time - starttrans_time #传输时间serverreq_time = starttrans_time - pretrans_time #服务器响应时间,包括网络传输时间if ssl_time == 0:if redirect_time == 0:clientper_time = pretrans_time - connect_time #客户端准备发送数据时间redirect_time = 0else:clientper_time = pretrans_time - redirect_timeredirect_time = redirect_time - connect_timessl_time = 0else:clientper_time = pretrans_time - ssl_timeif redirect_time == 0:ssl_time = ssl_time - connect_timeredirect_time = 0else:ssl_time = ssl_time - redirect_timeredirect_time = redirect_time - connect_timeconnect_time = connect_time - dns_timeprint('发起请求到DNS解析时间: %.3f ms' % (dns_time * 1000))print('TCP连接消耗时间:%.3f ms' % (connect_time * 1000))print('跳转消耗时间:%.3f ms' % (redirect_time * 1000))print('SSL握手消耗时间:%.3f ms' % (ssl_time * 1000))print('客户端发送请求准备时间:%.3f ms' % (clientper_time * 1000))print('服务器处理时间: %.3f ms' % (serverreq_time * 1000))print('数据传输时间:%.3f ms' % (transfer_time * 1000))def get_other_info(self):'''获取其他请求信息,需要一个pycurl对象。'''ret = {}ret['http_code'] = self._curl.getinfo(pycurl.HTTP_CODE)ret['http_sizedown'] = self._curl.getinfo(pycurl.SIZE_DOWNLOAD)ret['http_sizeheader'] = self._curl.getinfo(pycurl.HEADER_SIZE)ret['http_speeddown'] = self._curl.getinfo(pycurl.SPEED_DOWNLOAD)ret['http_effurl'] = self._curl.getinfo(pycurl.EFFECTIVE_URL)print(ret)if __name__ == '__main__':#url = r'https://www.tmall.com/'#url = r'http://p0.so.qhimgs1.com/t0156dd096f20528974.jpg'#url = 'http://echarts.baidu.com/dist/echarts.js'url = 'http://www.sina.com.cn'py_obj = url_detect(url)print('='*10 + '相关请求信息' + '='*10)py_obj.get_other_info()print('='*10 + '相关请求阶段的耗时' + '='*10)py_obj.get_absolute_time()print('='*10 + '相关请求阶段和请求开始之间时差' + '='*10)py_obj.get_relative_time()

若有收获,就点个赞吧
0 人点赞
