字典和集合
需要将一系列值组合成数据结构并通过编号来访问各个值时,列表很有用。本章介绍一种可通过名称来访问其各个值的数据结构。这种数据结构称为映射(mapping)。字典是Python中唯一的内置映射类型,其中的值不按顺序排列,而是存储在键下。键可能是数、字符串或元组。
列表、字符串和字典是三种最重要的Python数据类型。
字典
列表是数值索引,不支持其它索引,而且列表相对较慢;字典的速度要快于列表,但是字典所耗费的资源比较大。
字典是一种无序可变容器,且可存储任意类型对象。字典的每个键值(key=>value)对用冒号(:)分割,每对之间用逗号分割,整个字典包括在花括号{}中。字典键必须唯一且不可变,值可以是任意类型,也可以重复。
# 合法dic = {123: 456, True: 999, "id": 1, "name": 'sylar', "age": 18, "stu": ['帅哥', '美⼥'], (1, 2, 3): '麻花藤'}print(dic[123])print(dic[True])print(dic['id'])print(dic['stu'])print(dic[(1, 2, 3)])# 不合法# dic = {[1, 2, 3]: '周杰伦'} # list是可变的. 不能作为key# dic = {{1: 2}: "哈哈哈"} # dict是可变的. 不能作为keydic = {{1, 2, 3}: '呵呵呵'} # set是可变的, 不能作为key
字典的用途
字典的名称指出了这种数据结构的用途。普通图书适合按从头到尾的顺序阅读,如果你愿意,可快速翻到任何一页,这有点像Python中的列表。字典(日常生活中的字典和Python字典)旨在让你能够轻松地找到特定的单词(键),以获悉其定义(值)。
在很多情况下,使用字典都比使用列表更合适。下面是Python字典的一些用途:
- 表示棋盘的状态,其中每个键都是由坐标组成的元组;
- 存储文件修改时间,其中的键为文件名;
- 数字电话/地址簿。
如果要存储人名和其对应的电话号码,可以采用2个列表的形式:
>>> names = ['Alice', 'Beth', 'Cecil', 'Dee-Dee', 'Earl']>>> numbers = ['2341', '9102', '3158', '0142', '5551']#可像下面这样查找Cecil的电话号码>>> numbers[names.index('Cecil')]'3158'
上面的方法可以,但是不太实用,这时候就可以采用字典:
>>> phonebook = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}#很方便的取值>>> phonebook['Cecil']'3258'
字典由键及其相应的值组成,这种键-值对称为项(item)。在前面的示例中,键为名字,而值为电话号码。每个键与其值之间都用冒号(:)分隔,项之间用逗号分隔,而整个字典放在花括号内。空字典(没有任何项)用两个花括号表示,类似于下面这样:{}。
字典使用举例:
- 例1、统计网站的用户主要分部在全国什么地方,我们可以通过http服务器的日志得到用户的ip地址,并将ip设置为键名,将流量和次数设置为值。这样就可以获得网站主要的用户来源,进而通过IP获得用户的地理位置。
- 例2、比如每次考试统计学生的成绩,键名可以为学生名,键值可以为学生语文、数学、英语等科目的成绩。
字典的创建
#初始化空字典>>> d = {}>>> d{}#设置键值对>>> d = {'a':'abc','tom':[1,2,'ab']}>>> d{'a': 'abc', 'tom': [1, 2, 'ab']}#可使用函数dict从其他映射(如其他字典)或键-值对序列创建字典>>> d1 = dict([('one', 1),('two', 2),('three', 3)])>>> d1{'one': 1, 'two': 2, 'three': 3}#使用关键字实参来调用dict函数>>> d2 = dict(one=1,two=2,three=3)>>> d2{'one': 1, 'two': 2, 'three': 3}#利用fromkey,格式为:dict.fromkeys(iterable,'M')>>> d3 = dict.fromkeys('abc')>>> d3{'a': None, 'b': None, 'c': None}>>> d4 = dict.fromkeys('abc','test')>>> d4{'a': 'test', 'b': 'test', 'c': 'test'}>>> d5 = dict.fromkeys(['harry','tom','lily'],'teacher')>>> d5{'harry': 'teacher', 'tom': 'teacher', 'lily': 'teacher'}
基本的字典操作
字典的基本行为在很多方面都类似于序列。
- len(d)返回字典d包含的项(键-值对)数。
- d[k]返回与键k相关联的值。
- d[k] = v将值v关联到键k。
- del d[k]删除键为k的项。
- k in d检查字典d是否包含键为k的项。
虽然字典和列表有多个相同之处,但也有一些重要的不同之处。
- 键的类型:字典中的键可以是整数,但并非必须是整数。字典中的键可以是任何不可变的类型,如浮点数(实数)、字符串或元组。
- 自动添加:即便是字典中原本没有的键,也可以给它赋值,这将在字典中创建一个新项。然而,如果不使用append或其他类似的方法,就不能给列表中没有的元素赋值。
- 成员资格:表达式k in d(其中d是一个字典)查找的是键而不是值,而表达式v in l(其
中l是一个列表)查找的是值而不是索引。这看似不太一致,但习惯后就会觉得相当自然。毕竟如果字典包含指定的键,检查相应的值就很容易。
字典案例:
# 一个简单的数据库# 一个将人名用作键的字典。每个人都用一个字典表示,# 字典包含键'phone'和'addr',它们分别与电话号码和地址相关联people = {'Alice': {'phone': '2341','addr': 'Foo drive 23'},'Beth': {'phone': '9102','addr': 'Bar street 42'},'Cecil': {'phone': '3158','addr': 'Baz avenue 90'}}# 电话号码和地址的描述性标签,供打印输出时使用labels = {'phone': 'phone number','addr': 'address'}name = input('Name: ')# 要查找电话号码还是地址?request = input('Phone number (p) or address (a)? ')# 使用正确的键:if request == 'p': key = 'phone'if request == 'a': key = 'addr'# 仅当名字是字典包含的键时才打印信息:if name in people:print("{}'s {} is {}.".format(name, labels[key], people[name][key]))
这个程序的运行情况类似于下面这样:
Name: BethPhone number (p) or address (a)? pBeth's phone number is 9102.
字典方法
字典的方法很有用,但其使用频率可能没有列表和字符串的方法那样高。
1. clear
方法clear删除所有的字典项,这种操作是就地执行的(就像list.sort一样),因此什么都不返回(或者说返回None)。
>>> d = {}>>> d['name'] = 'Gumby'>>> d['age'] = 42>>> d{'age': 42, 'name': 'Gumby'}>>> returned_value = d.clear()>>> d{}>>> print(returned_value)None
这为何很有用呢?我们来看两个场景。下面是第一个场景:
>>> x = {}>>> y = x>>> x['key'] = 'value'>>> y{'key': 'value'}>>> x = {}>>> y{'key': 'value'}
下面是第二个场景:
>>> x = {}>>> y = x>>> x['key'] = 'value'>>> y{'key': 'value'}>>> x.clear()>>> y{}
在这两个场景中,x和y最初都指向同一个字典。在第一个场景中,我通过将一个空字典赋给x来“清空”它。这对y没有任何影响,它依然指向原来的字典。这种行为可能正是你想要的,但要删除原来字典的所有元素,必须使用clear。如果这样做,y也将是空的,如第二个场景所示。
2. copy
方法copy返回一个新字典,其包含的键值对与原来的字典相同(这个方法执行的是浅复制,因为值本身是原件,而非副本)。
>>> x = {'username': 'admin', 'machines': ['foo', 'bar', 'baz']}>>> y = x.copy()>>> y['username'] = 'mlh'>>> y['machines'].remove('bar')>>> y{'username': 'mlh', 'machines': ['foo', 'baz']}>>> x{'username': 'admin', 'machines': ['foo', 'baz']}
当替换副本中的值时,原件不受影响。然而,如果修改副本中的值(就地修改而不是替换),原件也将发生变化,因为原件指向的也是被修改的值。
为避免这种问题,一种办法是执行深复制,即同时复制值及其包含的所有值,等等。为此,可使用模块copy中的函数deepcopy。
>>> from copy import deepcopy>>> d = {}>>> d['names'] = ['Alfred', 'Bertrand']>>> c = d.copy()>>> dc = deepcopy(d)>>> d['names'].append('Clive')>>> c{'names': ['Alfred', 'Bertrand', 'Clive']}>>> dc{'names': ['Alfred', 'Bertrand']}
3. fromkeys
方法fromkeys创建一个新字典,其中包含指定的键,且每个键对应的值都是None。
>>> dict.fromkeys(['name', 'age']){'age': None, 'name': None}#如果你不想使用默认值None,可提供特定的值。>>> dict.fromkeys(['name', 'age'], '(unknown)'){'age': '(unknown)', 'name': '(unknown)'}
4. get
方法get为访问字典项提供了宽松的环境。通常,如果你试图访问字典中没有的项,将引发错误。
>>> d = {}>>> print(d['name'])Traceback (most recent call last):File "<stdin>", line 1, in ?KeyError: 'name'
而使用get不会这样:
>>> print(d.get('name'))None
使用get来访问不存在的键时,没有引发异常,而是返回None。你可指定“默认”值,这样将返回你指定的值而不是None。
>>> d.get('name', 'N/A')'N/A'
如果字典包含指定的键,get的作用将与普通字典查找相同。
>>> d['name'] = 'Eric'>>> d.get('name')'Eric'
字典方法案例:
# 一个使用get()的简单数据库# 一个将人名用作键的字典。每个人都用一个字典表示,# 字典包含键'phone'和'addr',它们分别与电话号码和地址相关联people = {'Alice': {'phone': '2341','addr': 'Foo drive 23'},'Beth': {'phone': '9102','addr': 'Bar street 42'},'Cecil': {'phone': '3158','addr': 'Baz avenue 90'}}# 电话号码和地址的描述性标签,供打印输出时使用labels = {'phone': 'phone number','addr': 'address'}name = input('Name: ')# 要查找电话号码还是地址?request = input('Phone number (p) or address (a)? ')# 使用正确的键:key = request # 如果request既不是'p'也不是'a'if request == 'p': key = 'phone'if request == 'a': key = 'addr'# 使用get提供默认值person = people.get(name, {})label = labels.get(key, key)result = person.get(key, 'not available')print("{}'s {} is {}.".format(name, label, result))
通过修改程序,get提高了灵活性,让程序在用户输入的值出乎意料时也能妥善处理。
Name: GumbyPhone number (p) or address (a)? batting averageGumby's batting average is not available.
5. items
方法items返回一个包含所有字典项的列表,其中每个元素都为(key, value)的形式。字典项在列表中的排列顺序不确定。
>>> d = {'title': 'Python Web Site', 'url': 'http://www.python.org', 'spam': 0}>>> a = d.items()>>> adict_items([('title', 'Python Web Site'), ('url', 'http://www.python.org'), ('spam', 0)])>>> type(a)<class 'dict_items'>
返回值属于一种名为字典视图的特殊类型。字典视图可用于迭代。另外,你还可确定其长度以及对其执行成员资格检查。
>>> len(a)3>>> ('spam',0) in aTrue
视图的一个优点是不复制,它们始终是底层字典的反映,即便你修改了底层字典亦如此。
>>> d['spam'] = 1>>> ('spam',0) in aFalse>>> d['spam'] = 0>>> ('spam',0) in aTrue
可以将字典项复制到列表中
>>> b = list(d.items())>>> b[('title', 'Python Web Site'), ('url', 'http://www.python.org'), ('spam', 0)]>>> d['spam'] = 1>>> b[('title', 'Python Web Site'), ('url', 'http://www.python.org'), ('spam', 0)]>>> d{'title': 'Python Web Site', 'url': 'http://www.python.org', 'spam': 1}>>> adict_items([('title', 'Python Web Site'), ('url', 'http://www.python.org'), ('spam', 1)])
6. keys
方法keys返回一个字典视图,其中包含指定字典中的键。
>>> d = {'title': 'Python Web Site', 'url': 'http://www.python.org', 'spam': 0}>>> d.keys()dict_keys(['title', 'url', 'spam'])
7. pop
方法pop可用于获取与指定键相关联的值,并将该键值对从字典中删除。
>>> d = {'title': 'Python Web Site', 'url': 'http://www.python.org', 'spam': 0}>>> d.pop('spam')0>>> d{'title': 'Python Web Site', 'url': 'http://www.python.org'}
8. popitem
方法popitem类似于list.pop,但list.pop弹出列表中的最后一个元素,而popitem随机地弹出一个字典项(python3.6是删除最后一个)。
>>> d1 = dict.fromkeys([1,2,3,4,5,6],'test')>>> d1{1: 'test', 2: 'test', 3: 'test', 4: 'test', 5: 'test', 6: 'test'}>>> d1.popitem()(6, 'test')>>> d1{1: 'test', 2: 'test', 3: 'test', 4: 'test', 5: 'test'}>>> d1.popitem()(5, 'test')>>> d1.popitem()(4, 'test')>>> d1.popitem()(3, 'test')>>> d1.popitem()(2, 'test')>>> d1.popitem()(1, 'test')>>> d1{}>>> d1.popitem()Traceback (most recent call last):File "<stdin>", line 1, in <module>KeyError: 'popitem(): dictionary is empty'
9. setdefault
方法setdefault有点像get,因为它也获取与指定键相关联的值,但除此之外,setdefault还在字典不包含指定的键时,在字典中添加指定的键值对。
>>> d2 = {}>>> d2.setdefault('刘德华','天王')'天王'>>> d2{'刘德华': '天王'}>>> d2.setdefault('张学友')>>> d2{'刘德华': '天王', '张学友': None}>>> d2['张学友'] = '歌神'>>> d2{'刘德华': '天王', '张学友': '歌神'}>>> d2.setdefault('张学友','天王')'歌神'>>> d2{'刘德华': '天王', '张学友': '歌神'}
指定的键不存在时,setdefault返回指定的值并相应地更新字典。如果指定的键存在,就返回其值,并保持字典不变。与get一样,值是可选的;如果没有指定,默认为None。
10. update
方法update使用一个字典中的项来更新另一个字典。
>>> d2{'刘德华': '天王', '张学友': '歌神'}>>> d3 = {'黎明':'帅哥'}>>> d2.update(d3)>>> d2{'刘德华': '天王', '张学友': '歌神', '黎明': '帅哥'}>>> d2.update({'刘德华':'大帅哥'})>>> d2{'刘德华': '大帅哥', '张学友': '歌神', '黎明': '帅哥'}
对于通过参数提供的字典,将其项添加到当前字典中。如果当前字典包含键相同的项,就替换它。
11. values
方法values返回一个由字典中的值组成的字典视图。不同于方法keys,方法values返回的视图可能包含重复的值。
>>> d2{'刘德华': '大帅哥', '张学友': '歌神', '黎明': '帅哥'}>>> d2.values()dict_values(['大帅哥', '歌神', '帅哥'])>>> d2.update({'郭富城':'帅哥'})>>> d2.values()dict_values(['大帅哥', '歌神', '帅哥', '帅哥'])>>> test = d2.values()>>> d2['刘德华'] = '帅哥'>>> testdict_values(['帅哥', '歌神', '帅哥', '帅哥'])
集合
set和dict类似,是一组key的集合没有value,而且keys不可以重复并且必须为不可变对象。相当于一个只有key没有value的字典。
集合在Pyhton中的关键字是set,也是以{}的形式展示,形式: {1,2,3,‘abc’,‘xyz’} ;
使用:可以用来去重或者数学集合运算(比如去重列表)。
>>> lst = [1,3,4,112,23,1,3,1,41,12,3,1]#这样就没有重复的元素出现了,我们再将集合转换成列表>>> print(set(lst)){1, 3, 4, 41, 12, 112, 23}#这样就把没有重复的集合转成列表了>>> list(set(lst))[1, 3, 4, 41, 12, 112, 23]
集合的增删改查
集合是无序,可变的数据类型,说到可变我们就知道集合是能够增加和删除等操作的,我们来看看怎么操作。
增加
>>> s = {"刘嘉玲", '关之琳', "王祖贤"}>>> s.add("郑裕玲")>>> print(s){'王祖贤', '刘嘉玲', '郑裕玲', '关之琳'}>>> s.add("郑裕玲") # 重复的内容不会被添加到set集合中>>> print(s){'王祖贤', '刘嘉玲', '郑裕玲', '关之琳'}>>> s = {"刘嘉玲", '关之琳', "王祖贤"}>>> s.update("麻花藤") # 迭代更新>>> print(s){'藤', '麻', '刘嘉玲', '王祖贤', '关之琳', '花'}>>> s.update(["张曼⽟", "李若彤","李若彤"])>>> print(s){'藤', '麻', '张曼⽟', '李若彤', '刘嘉玲', '王祖贤', '关之琳', '花'}
删除
>>> s = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}>>> item = s.pop() # 随机弹出⼀个.>>> print(s){'李若彤', '刘嘉玲', '王祖贤', '关之琳'}>>> print(item)张曼⽟>>> s.remove("关之琳") # 直接删除元素>>> print(s){'李若彤', '刘嘉玲', '王祖贤'}>>> s.remove("⻢⻁疼") # 不存在这个元素. 删除会报错Traceback (most recent call last):File "<stdin>", line 1, in <module>KeyError: '⻢⻁疼'>>> print(s){'李若彤', '刘嘉玲', '王祖贤'}>>> s.clear() # 清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和dict区分的.>>> print(s)set()
修改
# set集合中的数据没有索引. 也没有办法去定位⼀个元素. 所以没有办法进⾏直接修改.# 我们可以采⽤先删除后添加的⽅式来完成修改操作s = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}# 把刘嘉玲改成赵本⼭s.remove("刘嘉玲")s.add("赵本⼭")print(s)
查询
#set是⼀个可迭代对象. 所以可以进⾏for循环>>> s = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}>>> for e1 in s:... print(e1)...张曼⽟李若彤刘嘉玲王祖贤关之琳
集合常用操作
Python中的集合跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集等运算。
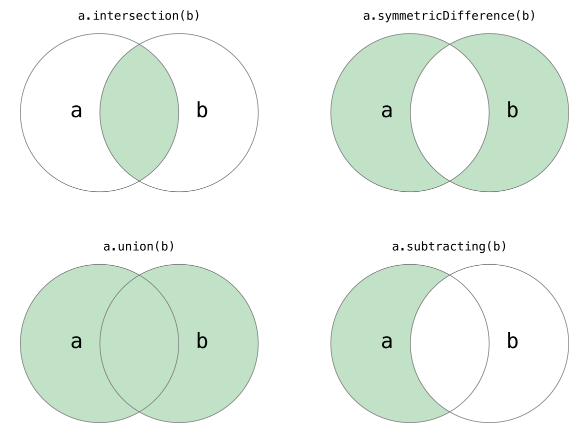
>>> s1 = {"刘能", "赵四", "⽪⻓⼭"}>>> s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"}# 交集:两个集合中的共有元素>>> print(s1 & s2){'⽪⻓⼭'}>>> print(s1.intersection(s2)){'⽪⻓⼭'}# 并集>>> print(s1 | s2){'⽪⻓⼭', '冯乡⻓', '刘科⻓', '赵四', '刘能'}>>> print(s1.union(s2)){'⽪⻓⼭', '冯乡⻓', '刘科⻓', '赵四', '刘能'}# 差集:得到第⼀个中单独存在的>>> print(s1 - s2){'赵四', '刘能'}>>> print(s1.difference(s2)){'赵四', '刘能'}#反交集:两个集合中单独存在的数据>>> print(s1 ^ s2){'冯乡⻓', '刘能', '刘科⻓', '赵四'}>>> print(s1.symmetric_difference(s2)){'冯乡⻓', '刘能', '刘科⻓', '赵四'}>>> s1 = {"刘能", "赵四"}>>> s2 = {"刘能", "赵四", "⽪⻓⼭"}#子集判断>>> print(s1 < s2)True>>> print(s1.issubset(s2))True#超集判断>>> print(s1 > s2)False>>> print(s1.issuperset(s2))False

若有收获,就点个赞吧
0 人点赞
