模块和包
Python提供了强大的模块支持,主要体现为不仅在Python标准库中包含了大量的模块(称为标准模块),而且还有很多第三方模块,另外开发者自己也可以开发自定义模块。通过这些强大的模块支持,将极大的提高开发效率。
一、模块概述
模块的英文是Modules,可以认为是一盒(箱)主题积木,通过它可以拼出某一主题的东西。这与函数不同,一个函数相当于一块积木,而一个模块中可以包含很多函数,也就是很多积木,所以也可以说模块相当于一盒积木。
在Python中,一个扩展名为”.py”的文件就称之为一个模块。通常情况下,我们把能够实现某一特定功能的代码放置在一个文件中作为一个模块,从而方便其他程序和脚本导入并使用。另外,使用模块也可以避免函数名和变量名冲突。
Python代码可以写在一个文件中。但是随着程序不断变大,为了便于维护,需要将其分为多个文件,这样可以提高代码的可维护性。另外,使用模块还可以提高代码的可重用性。即编写好一个模块后,只要是实现该功能的程序,都可以导入这个模块来实现。
Python语言中,模块分为三类。
- 第一类:内置模块,也叫做标准库。此类模块就是python解释器给你提供的,比如我们之前见过的time模块,os模块。标准库的模块非常多(200多个,每个模块又有很多功能);
- 第二类:第三方模块,第三方库。一些python大神写的非常好用的模块,必须通过pip install 指令安装的模块,比如BeautfulSoup, Django,等等。大概有6000多个。
- 第三类:自定义模块。我们自己在项目中定义的一些模块。
二、自定义模块
在Python中,自定义模块有两个作用,一个是规范代码,让代码更易于阅读;另一个是方便其他程序使用已经编写好的代码,提供开发效率。要实现自定义模块主要分为两部分,一部分是创建模块;另一部分是导入模块。
2.1 创建模块
创建模块可以将模块中相关的代码(变量定义和函数定义等)编写在一个单独的文件中,并且将该文件命名为“模块名+.py”的形式。创建模块,实际就是创建一个.py文件。
- 创建模块时,设置的模块名尽量不要与Python自带的标准模块名称相同
- 模块文件的扩展名必须是“.py”
print('from the tbjx.py')name = '刘德华'def read1():print('tbjx模块:',name)def read2():print('tbjx模块')read1()def change():global namename = 'barry'
2.2 使用import语句导入模块
import导入语法:
import modulename [as alias]
- modulename为导入的模块名字
- as alias可以为模块起一个别名,通过该别名也可以使用模块
第一次导入模块执行三件事
- 创建一个以模块名命名的名称空间。
- 执行这个名称空间(即导入的模块)里面的代码。
- 通过此模块名. 的方式引用该模块里面的内容(变量,函数名,类名等)。 这个名字和变量名没什么区别,都是‘第一类的’,且使用tbjx名字的方式可以访问tbjx.py文件中定义的名字,tbjx.名字与test.py中的名字来自两个完全不同的地方。
被导入模块有独立的名称空间
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突。
import tbjx.pyname = '张学友'print(name)print(tbjx.name)'''from the tbjx.py张学友刘德华'''def read1():print(666)tbjx.read1()'''from the tbjx.pytbjx模块: 刘德华'''name = '黎明'tbjx.change()print(name)print(tbjx.name)'''from the tbjx.py黎明barry'''
导入多个模块
我们以后再开发过程中,免不了会在一个文件中,导入多个模块,推荐写法是一个一个导入。
import os,sys,json # 这样写可以但是不推荐#推荐写法import osimport sysimport json
2.3 使用from…import…语句导入模块
from … import … 使用
#from ... import ... 的使用示例。
from tbjx import name, read1
print(name)
read1()
'''
执行结果:
from the tbjx.py
刘德华
tbjx模块: 刘德华
'''
from…import… 与import对比
唯一的区别就是:使用from…import…则是将spam中的名字直接导入到当前的名称空间中,所以在当前名称空间中,直接使用名字就可以了、无需加前缀:tbjx.
from…import…的方式有好处也有坏处
- 好处:使用起来方便了
- 坏处:容易与当前执行文件中的名字冲突
注意:在使用from…import语句导入模块中的定义时,需要保证所导入的内容在当前的命名空间中是唯一的,否则将出现冲突,后导入的同名变量、函数或者类会覆盖先导入的。
2.4 模块搜索目录
当使用import语句导入模块时,默认情况下,会按照以下顺序进行查找:
- 在当前目录(即执行的Python脚本文件所在目录)下查找
- 到PYTHONPATH(环境变量)下的每个目录中查找
- 到Python的默认安装目录下查找
以上各个目录的具体位置保存在标准模块sys的sys.path变量中:
In [1]: import sys
In [2]: import pprint
In [3]: pprint.pprint(sys.path)
['/usr/local/bin',
'/usr/lib64/python36.zip',
'/usr/lib64/python3.6',
'/usr/lib64/python3.6/lib-dynload',
'',
'/usr/local/lib64/python3.6/site-packages',
'/usr/local/lib/python3.6/site-packages',
'/usr/lib64/python3.6/site-packages',
'/usr/lib/python3.6/site-packages',
'/usr/local/lib/python3.6/site-packages/IPython/extensions',
'/root/.ipython']
可以通过以下方法添加指定的目录到sys.path中。
#临时方法
> > > import sys
> > > sys.path.append('/a/b/c/d')
> > > sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索
# 增加.pth文件(推荐)
#在Python安装目录下的“/lib/site-packages”目录中,创建一个扩展名为.pth的文件,将目录写在文件中即可。
[root@host1 ~]# cd /usr/local/lib/python3.6/site-packages
[root@host1 site-packages]# cat easy-install.pth
/root/turtle-0.0.2
三、以主程序的形式执行
先创建一个模块,名称为christmastree,在该模块中,首先定义一个全局变量,然后创建一个名称为fun_christmastree()的函数,最后通过print()函数输出一些内容。代码如下:
pinetree = '我是一棵松树'
def fun_christmastree():
'''功能:一个梦
无返回值
'''
pinetree = '挂上彩灯、礼物。。。我变成一颗圣诞树'
print(pinetree)
print('下雪了...')
print('='*10 + ' 开始做梦 ' + '='*10)
fun_christmastree()
print('='*10 + ' 梦醒了 ' + '='*10)
pinetree = '我身上落满雪花,' + pinetree + ' -_- '
print(pinetree)
在与christmastree模块同级的目录下,创建一个名称为main.py的文件,在该文件中,导入christmastree模块,再通过print()语句输出模块中的全局变量pinetree的值。
import christmastree
print('全局变量的值为:',christmastree.pinetree)
执行main.py文件,输出如下结果:
下雪了...
========== 开始做梦 ==========
挂上彩灯、礼物。。。我变成一颗圣诞树
========== 梦醒了 ==========
我身上落满雪花,我是一棵松树 -_-
全局变量的值为: 我身上落满雪花,我是一棵松树 -_-
导入模块后,不仅输出了全局变量的值,而且模块中的原有的测试代码也被执行了,这个结果显然不是我们想要的。那么如何只输出全局变量的值呢?实际上,可以在模块中,将原本直接执行的测试代码放到一个if语句中。
pinetree = '我是一棵松树'
def fun_christmastree():
'''功能:一个梦
无返回值
'''
pinetree = '挂上彩灯、礼物。。。我变成一颗圣诞树'
print(pinetree)
# ******判断是否以主程序的形式运行******
if __name__ == '__main__':
print('下雪了...')
print('='*10 + ' 开始做梦 ' + '='*10)
fun_christmastree()
print('='*10 + ' 梦醒了 ' + '='*10)
pinetree = '我身上落满雪花,' + pinetree + ' -_- '
print(pinetree)
然后再执行导入模块main.py文件,结果如下:
全局变量的值为: 我是一棵松树
可以看到模块里面的测试代码并没有执行,如果单独执行christmastree.py文件,测试代码会执行:
下雪了...
========== 开始做梦 ==========
挂上彩灯、礼物。。。我变成一颗圣诞树
========== 梦醒了 ==========
我身上落满雪花,我是一棵松树 -_-
解释一下原因:
#模块是对象,并且所有的模块都有一个内置属性'__name__'。一个模块的 '__name__'的值取决于您如何应用模块。
#如果 import 一个模块,那么模块'__name__' 的值通常为模块文件名,不带路径或者文件扩展名。
#但是您也可以像一个标准的程序样直接运行模块,在这种情况下, '__name__' 的值将是一个特别缺省"__main__"。
直接运行.py文件,则'__name__'的值是'__main__';
在import 一个.py文件后,'__name__'的值就不是'__main__'了,而是文件名;
从而用if '__name__' == '__main__'来判断是否是在直接运行该.py文件
四、Python中的包
使用模块可以避免函数名和变量名重名引发的冲突。那么,如果模块名重复应该如何办呢?在Python中,提出了包(package)的概念。
包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下。这样,既可以起到规范代码的作用,又能避免模块名重名引起的冲突。
包简单理解就是“文件夹”,只不过在该文件夹下必须存在一个名称为“init.py”的文件。
4.1 Python程序的包结构
在实际项目开发时,通常情况下,会创建多个包用于存放不同类的文件。例如,开发一个网站时,可以创建如下所示的包结构:
[root@host1 python]# tree -C shop/
shop/ #项目名
├── admin #用于保存后台文件的包
│ ├── forms.py
│ ├── __init__py
│ └── views.py
├── home #用于保存前台文件的包
│ ├── forms.py
│ ├── __init__py
│ └── views.py
├── manage.py #入口程序
└── templates #用于保存模板文件的包
├── __init__py
└── models.py
在该项目下创建了admin,home和templates三个包和一个manage.py的文件,最后在每个包中,又创建了相应的模块。
4.2 创建和使用包
1. 创建包
创建包实际上就是创建一个文件夹,并且在该文件夹中创建一个名称为“init.py”的Python文件,在init.py文件中,可以不编写任何代码,也可以编写一些Python代码。在init.py中所编写的代码,在导入包时会自动执行。
init.py是一个模块文件,模块名为对应的包名。例如,在settings包中创建的init.py文件,对应的模块名为settings。
2. 使用包
创建包以后,就可以在包中创建相应的模块,然后再使用import语句从包中加载模块。从包中加载模块通常有以下3种方式:
- 通过“import+完整包名+模块名”形式加载指定模块
例如在包中有个size模块
#!/usr/bin/python3
width = 800 #宽度
height = 600 #高度
那么导入size模块,就可以这样写代码:
import settings.size
if __name__ == '__main__':
print('宽度:{}'.format(settings.size.width))
print('高度: {}'.format(settings.size.height))
#运行结果如下:
宽度:800
高度: 600
- 通过“from + 完整包名 + import + 模块名”形式加载指定模块
导入size模块,就可以这样写代码:
from settings import size
if __name__ == '__main__':
print('宽度:{}'.format(size.width))
print('高度: {}'.format(size.height))
#运行结果如下:
宽度:800
高度: 600
- 通过“from + 完整包名 + 模块名 + import + 定义名”形式加载指定模块
#导入settings包中size模块中的width和height变量
from settings.size import width,height
if __name__ == '__main__':
print('宽度:{}'.format(width))
print('高度: {}'.format(height))
#运行结果如下:
宽度:800
高度: 600
能否直接导入包名呢?
import settings #直接导入包
print(settings.size.width)
#程序执行结果:报错了
AttributeError: module 'settings' has no attribute 'size'
要查明模块包含哪些东西,可使用函数dir,它列出对象的所有属性(对于模块,它列出所有的函数、类、变量等)
In [1]: import settings
In [2]: dir(settings)
Out[2]:
['__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__']
修改settings下的init.py文件:
[root@host1 python]# cat settings/__init__.py
from settings import size
然后重新导入,可以使用size模块了
In [1]: import settings
In [2]: dir(settings)
Out[2]:
['__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__',
'size']
In [3]: print(settings.size.width)
800
4.3 使用help获取帮助
In [2]: import copy
In [3]: help(copy.copy)
4.4 使用模块文档
文档是有关模块信息的自然来源。
In [2]: import copy
In [3]: print(copy.__doc__)
In [4]: print(copy.copy.__doc__)
4.5 查看源码文件
要学习Python,阅读源代码是除动手编写代码外
的最佳方式。
In [2]: import copy
In [7]: print(copy.__file__)
/usr/lib64/python3.6/copy.py
In [5]: import settings
In [6]: print(settings.__file__)
/root/python/settings/__init__.py
In [7]: print(settings.size.__file__)
/root/python/settings/size.py
五、引用其他模块
在Python中,除了可以自定义模块外,还可以引用其他模块,主要包括使用标准模块和第三方模块。
5.1 导入和使用标准模块
在Python中,自带了很多实用的模块,称为标准模块(也可以称为标准库),对于标准模块,我们可以直接使用import语句导入到Python文件中使用。
例如,导入标准模块random(用于生成随机数)
import random #导入标准模块random
print(random.randint(0,10))
除了random外,Python还提供了大约200多个内置的标准模块,涵盖了Python运行时服务、文字模式匹配、操作系统接口、数学运算、对象永久保存、网络和Internet脚本和GUI建构等方面。
Python常用的内置标准模块及描述
| 模块名 | 描述 |
|---|---|
| sys | 与Python解释器及其环境操作相关的标准库 |
| time | 提供与时间相关的各种函数的标准库 |
| os | 提供了访问操作系统服务功能的标准库 |
| calendar | 提供与日期相关的各种函数的标准库 |
| urllib | 用于读取来自网上(服务器上)的数据的标准库 |
| json | 用于使用JSON序列化和反序列化对象 |
| re | 用于在字符串中执行正则表达式匹配和替换 |
| math | 提供标准算术运算函数的标准库 |
| decimal | 用于进行精确控制运算精度、有效数位和四舍五入操作的十进制运算 |
| shutil | 用于进行高级文件操作,如复制、移动和重命名等 |
| logging | 提供了灵活的记录事件、错误、警告和调试信息等日志信息的功能 |
| tkinter | 使用Python进行GUI编程的标准库 |
Python标准库:https://docs.python.org/3.6/library/index.html
5.2 第三方模块的下载与安装
在进行Python程序开发时,除了可以使用Python内置的标准模块外,还有很多第三方模块可以所使用,对于这些第三方模块,可以在Python官方推出的 https://pypi.org/ 中找到。
在使用第三方模块时,需要先下载并安装该模块,然后就可以像使用标准模块一样导入并使用了。可以使用pip命令进行安装
pip install numpy #用于科学计算
六、常用标准模块
6.1 os模块
os模块是与操作系统交互的一个接口,它提供的功能多与工作目录,路径,文件等相关。
接下来讲解下面的这些方法:按照星的等级划分,三颗星是需要记住的
当前执行这个python文件的工作目录相关的工作路径
os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 **
os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd **
os.curdir #返回当前目录: ('.') **
os.pardir #获取当前目录的父目录字符串名:('..') **
文件夹相关
os.makedirs('dirname1/dirname2') #可生成多层递归目录 ***
os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 ***
os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname ***
os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname ***
os.listdir('dirname') #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 **
文件相关
os.remove() # 删除一个文件 ***
os.rename("oldname","newname") # 重命名文件/目录 ***
os.stat('path/filename') # 获取文件/目录信息 **
路径相关
os.path.abspath(path) # 返回path规范化的绝对路径 ***
os.path.split(path) # 将path分割成目录和文件名二元组返回 ***
os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 **
os.path.basename(path) #返回path最后的文件名。如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。 **
os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False ***
os.path.isabs(path) #如果path是绝对路径,返回True **
os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False ***
os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False ***
os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 ***
os.path.getatime(path) #返回path所指向的文件或者目录的最后访问时间 **
os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间 **
os.path.getsize(path) #返回path的大小 ***
操作系统相关(了解)
os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" *
os.linesep #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep #输出用于分割文件路径的字符串 win下为;,Linux下为: *
os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix' *
# 和执行系统命令相关
os.system("bash command") #运行shell命令,直接显示 **
os.popen("bash command").read() #运行shell命令,获取执行结果 **
os.environ #获取系统环境变量 **
os.stat(‘path/filename’) 获取文件/目录信息 的结构说明(了解)
# stat 结构:
st_mode: inode #保护模式
st_ino: inode #节点号。
st_dev: inode #驻留的设备。
st_nlink: #inode 的链接数。
st_uid: #所有者的用户ID。
st_gid: #所有者的组ID。
st_size: #普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: #上次访问的时间。
st_mtime: #最后一次修改的时间。
st_ctime: #由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
os常用函数
| 方法 | 示例 | 说明 |
|---|---|---|
| os.name | os.name | 返回当前系统类型 |
| os.getcwd() | os.getcwd() | 返回当前工作路径 |
| os.listdir() | os.listdir() | 返回当前目录中所有文件及目录 |
| os.remove() | os.remove(‘1.txt’) | 删除 1.txt 文件 |
| os.rmdir() | os.rmdir(‘tmp’) | 删除tmp目录,tmp必须为空目录 |
| os.mkdir() | os.mkdir(‘tmp’) | 创建tmp目录 |
| os.chdir() | os.chdir(’/root’) | 切换目录 |
| os.makedirs() | os.makedirs(‘a/b/c’) | 创建多级目录 |
| os.path.isfile() | os.path.isfile(‘6.txt’) | 判断6.txt 是否为文件 |
| os.path.isdir() | os.path.isdir(‘tmp’) | 判断tmp是否为目录 |
| os.path.exists() | os.path.exists(‘b’) | 判断 文件或目录是否存在 |
| os.path.abspath() | os.path.abspath(‘6.txt’) | 返回 6.txt 文件的绝对目录 |
| os.path.basename() | os.path.basename(’/root/a.txt’) | 获取文件名 |
| os.path.dirname() | os.path.dirname(’/root/a.txt’) | 获取目录名 |
| os.system() | os.system(‘ls -l’) | 执行系统命令,执行ls -l命令 |
| os.popen() | ret = os.popen(‘ls -l’) | 执行系统命令,将结果放入到ret中,ret是一个文件对象。 |
shutil 常用函数
os模块在处理文件和目录时有不足之处,比如删除有文件的目录等,shutil是一个强有力的补充。
| 方 法 | 示 例 | 说 明 |
|---|---|---|
| shutil.copy() | shutil.copy(‘test.py’,‘test.bak’) | 拷贝文件 |
| shutil.copytree() | shutil.copytree(‘tmp’,‘tmp.d’) | 拷贝目录,目录可以非空 |
| shutil.rmtree() | shutil.rmtree(‘tmp’) | 递归删除文件夹 |
| shutil.move() | shutil.move(‘6.txt’,’…/6.bak’) | 移动文件 |
6.2 sys模块
sys模块是与python解释器交互的一个接口,这个模块功能不是很多,练习一遍就行。
sys.argv #命令行参数List,第一个元素是程序本身路径
sys.exit(n) #退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version #获取Python解释程序的版本信息
sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 ***
sys.platform #返回操作系统平台名称
6.3 random模块
- 引子
random模块是一个随机模块,生活中经常遇到随机的场景,彩票,抓阄,打牌,等等,以后你的代码中如果遇到需要随机的需求:随机验证码,发红包等等,那么首先要想到的是random模块。 - 代码示例
```import random
随机小数
random.random() # 大于0且小于1之间的小数 0.7664338663654585 random.uniform(1,3) #大于1小于3的小数 1.6270147180533838
随机整数
random.randint(1,5) # 大于等于1且小于等于5之间的整数 random.randrange(1,10,2) # 大于等于1且小于10之间的奇数
随机选择一个返回
random.choice([1,’23’,[4,5]]) # #1或者23或者[4,5]
随机选择多个返回,返回的个数为函数的第二个参数
random.sample([1,’23’,[4,5]],2) # #列表元素任意2个组合 [[4, 5], ‘23’]
打乱列表顺序
item=[1,3,5,7,9] random.shuffle(item) # 打乱次序 item [5, 1, 3, 7, 9] random.shuffle(item) item [5, 9, 7, 1, 3] ```
6.4 time模块
引子
time翻译过来就是时间,这个模块是与时间相关的模块,那么言外之意,如果我们在工作中遇到了对时间的需求(比如获取当前时间,获取时间戳等等)就要先想到time模块。
三种形式
time模块中对于时间可以分成三种形式:
- 时间戳
通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。这个是实时变化的。我们运行“type(time.time())”,返回的是float类型。
- 格式化字符串时间:
格式化的时间字符串(Format String): ‘1999-12-06’
# python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
- 结构化时间
元组(struct_time),struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
首先,我们先导入time模块,来认识一下python中表示时间的几种格式:
import time
# 时间戳
print(time.time()) # 1567568068.612113
# 字符串格式化时间
print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2019-09-04 11:36:54
# 结构化时间
print(time.localtime()) # time.struct_time(tm_year=2019, tm_mon=9, tm_mday=4, tm_hour=11, tm_min=37, tm_sec=45, tm_wday=2, tm_yday=247, tm_isdst=0)
小结:
时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的,时间模块我们就是学会如何获取当前的时间,以及三种时间之间的转化就行了。
时间格式转换
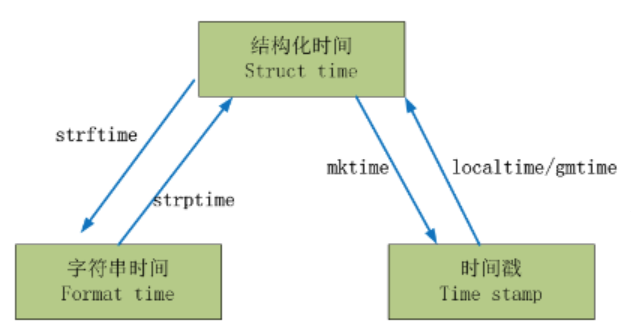
import time
# 格式化时间 ----> 结构化时间
ft = time.strftime('%Y/%m/%d %H:%M:%S')
st = time.strptime(ft,'%Y/%m/%d %H:%M:%S')
print(st)
# 结构化时间 ---> 时间戳
t = time.mktime(st)
print(t)
# 时间戳 ----> 结构化时间
t = time.time()
st = time.localtime(t)
print(st)
# 结构化时间 ---> 格式化时间
ft = time.strftime('%Y/%m/%d %H:%M:%S',st)
print(ft)
还有另一种转换方式,只是转化成的格式化时间是固定的格式,不能自定制,但是可以做到结构化时间与时间戳直接转化成格式化时间,省去了中间的一些步骤。
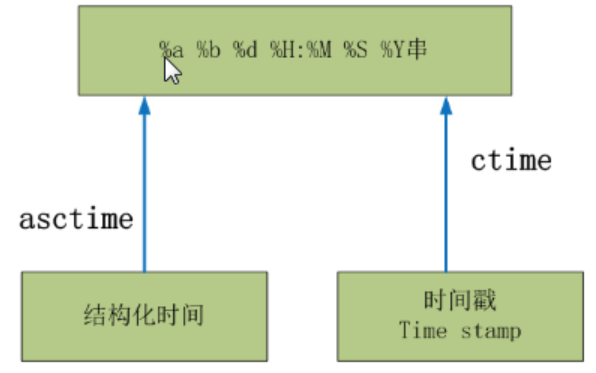
# 时间戳转化成格式化时间
t = time.time()
ft = time.ctime(t)
print(ft)
# 结构化时间转化成格式化时间
st = time.localtime()
ft = time.asctime(st)
print(ft)
6.5 datatime模块
此模块也是与时间相关的模块,他提供的功能更广泛一些,具体与time模块的区别,我下面会有具体的总结。
- 获取当前日期和时间
from datetime import datetime
print(datetime.now())
'''
结果:2018-12-04 21:07:48.734886
'''
- 获取指定日期和时间
要指定某个日期和时间,我们直接用参数构造一个datetime:
from datetime import datetime
dt = datetime(2018,5,20,13,14)
print(dt)
'''
结果:2018-05-20 13:14:00
'''
- datetime与时间戳的转换
from datetime import datetime
dt = datetime.now()
new_timestamp = dt.timestamp()
print(new_timestamp)
'''
结果:1543931750.415896
'''
import time
from datetime import datetime
new_timestamp = time.time()
print(datetime.fromtimestamp(new_timestamp))
- str与datetime的转换
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
from datetime import datetime
t = datetime.strptime('2018-4-1 00:00','%Y-%m-%d %H:%M')
print(t)
'''
结果: 2018-04-01 00:00:00
'''
#如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,
#转换方法是通过`strftime()`实现的,同样需要一个日期和时间的格式化字符串:
from datetime import datetime
now = datetime.now()
print(now.strftime('%a, %b %d %H:%M'))
Mon, May 05 16:28
- datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
#使用`timedelta`你可以很容易地算出前几天和后几天的时刻
from datetime import datetime, timedelta
now = datetime.now()
now + timedelta(hours=10) # 10小时后
now - timedelta(days=-1) # 一天前
now + timedelta(days=2, hours=12) # 2天12小时之后
- 指定datetime时间
current_time = datetime.datetime.now()
print(current_time.replace(year=1977)) # 直接调整到1977年
print(current_time.replace(month=1)) # 直接调整到1月份
print(current_time.replace(year=1989,month=4,day=25)) # 1989-04-25 18:49:05.898601
- 小结:
- time模块它提供的功能时更加接近于操作系统层面,部分函数都是与平台相关的,不同平台可能会有不同的效果,另外一点:由于time模块是基于Unix Timestamp,所以其所能表述的日期范围被限定在1970~2038年之间。
- datatime模块比time模块更加高级,可以理解为datetime模块基于time模块进行的封装。提供了更多实用的函数。
七、内置模块:re模块
7.1 正则
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
元字符 |
匹配内容 |
|---|---|
| \w | 匹配字母(包含中文)或数字或下划线 |
| \W | 匹配非字母(包含中文)或数字或下划线 |
| \s | 匹配任意的空白符 |
| \S | 匹配任意非空白符 |
| \d | 匹配数字 |
| \D | 匹配非数字 |
| \A | 从字符串开头匹配 |
| \Z | 匹配字符串的结束,如果是换行,只匹配到换行前的结果 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配行中以字符串的开始 |
| $ | 匹配行中以字符串的结尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 匹配字符组中的字符 |
| [^…] | 匹配除了字符组中的字符的所有字符 |
| * | 匹配0个或者多个左边的字符。 |
| + | 匹配一个或者多个左边的字符。 |
| ? | 匹配0个或者1个左边的字符,非贪婪方式。 |
| {n} | 精准匹配n个前面的表达式。 |
| {n,m} | 匹配n到m次由前面的正则表达式定义的片段,贪婪方式 |
| ab | 匹配a或者b |
| () | 匹配括号内的表达式,也表示一个组 |
7.2 匹配模式
我们现在配合着正则表达式来进行测试
字符串的常用操作:一对一匹配
s1 = 'tbjx太白金星'
print(s1.find('太白'))
正则匹配
\w 匹配中文,字母,数字,下划线
import re
name = "太白-tbjx_123 "
print(re.findall("\w",name))
#结果
['太', '白', 't', 'b', 'j', 'x', '_', '1', '2', '3']
\W 不匹配中文,字母,数字,下划线
import re
name = "太白-tbjx_123 "
print(re.findall("\W",name))
# 结果
['-',' ']
\s 匹配任意的空白符
import re
name = "太白-tbjx_123 "
print(re.findall("\s",name))
# 结果
[' ']
\S 匹配不是任意的空白符
import re
name = "太白-tbjx_123 "
print(re.findall("\s",name))
# 结果
['太', '白', '-', 't', 'b', 'j', 'x', '_', '1', '2', '3']
\d 匹配数字
import re
name = "太白-tbjx_123 "
print(re.findall("\d",name))
# 结果
['1', '2', '3']
\D 匹配非数字
import re
name = "太白-tbjx_123 "
print(re.findall("\D",name))
# 结果
['太', '白', '_', 't', 'b', 'j', 'x', '_', ' ']
\A 与 ^ 从字符串开头匹配
import re
name = "太白-tbjx_123 "
print(re.findall("\A太白",name))
# 结果
['太白']
import re
name = "太白-tbjx_123 "
print(re.findall("^太白",name))
# 结果
['太白']
\Z 与 与 $ 字符串结尾匹配
import re
name = "太白-tbjx_123 "
print(re.findall("123 \Z",name))
# 结果
['123 ']
import re
name = "太白-tbjx_123 "
print(re.findall("123 $",name))
# 结果
['123 ']
\n 与 \t 匹配换行符合制表符
import re
name = "太白-tbjx_123\t \n"
print(re.findall("\n",name))
# 结果
['\n']
import re
name = "太白-tbjx_123\t \n"
print(re.findall("\t",name))
# 结果
['\t']
7.3 重复匹配
. 匹配任意字符(换行符除外)
import re
print(re.findall('a.b', 'ab aab a*b a2b a牛b a\nb'))
? 匹配?前元素0个或1个
import re
print(re.findall('a?b', 'ab aab abb aaaab a牛b aba**b'))
匹配 前面元素0个或多个 [贪婪匹配]
import re
print(re.findall('a*b', 'ab aab aaab abbb')) # ['ab', 'aab', 'aaab', 'ab', 'b', 'b']
print(re.findall('ab*', 'ab aab aaab abbbbb'))
+ 匹配 +前面元素1个或多个 [贪婪匹配]
import re
print(re.findall('a+b', 'ab aab aaab abbb'))
{n,m} 匹配n到m个左边元素
import re
print(re.findall('a{2,4}b', 'ab aab aaab aaaaabb'))
.* 任意内容0个或多个
import re
print(re.findall('a.*b', 'ab aab a*()b'))
[] 获取括号中的内容
import re
# 括号中可以放任意一个字符,一个中括号代表一个字符
# - 在[]中表示范围,如果想要匹配上- 那么这个-符号不能放在中间.
# ^ 在[]中表示取反的意思.
print(re.findall('a.b', 'a1b a3b aeb a*b arb a_b'))
print(re.findall('a[abc]b', 'aab abb acb adb afb a_b'))
print(re.findall('a[0-9]b', 'a1b a3b aeb a*b arb a_b'))
print(re.findall('a[a-z]b', 'a1b a3b aeb a*b arb a_b'))
print(re.findall('a[a-zA-Z]b', 'aAb aWb aeb a*b arb a_b'))
print(re.findall('a[0-9][0-9]b', 'a11b a12b a34b a*b arb a_b'))
print(re.findall('a[*-+]b','a-b a*b a+b a/b a6b'))
# - 在[]中表示范围,如果想要匹配上- 那么这个-符号不能放在中间.
print(re.findall('a[-*+]b','a-b a*b a+b a/b a6b'))
print(re.findall('a[^a-z]b', 'acb adb a3b a*b'))
() 分组 定制一个匹配规则
import re
print(re.findall('(.*?)_sb', 'alex_sb wusir_sb 日天_sb'))
# 结果
['alex', ' wusir', ' 日天']
# 应用举例:
print(re.findall('href="(.*?)"','<a href="http://www.baidu.com">点击</a>')
# 结果
['http://www.baidu.com']
| 匹配 左边或者右边
import re
print(re.findall('alex|太白|wusir', 'alex太白wusiraleeeex宝太白odlb'))
# 结果
['alex', '太白', 'wusir', '太白']
import re
print(re.findall('compan(day|morrow)','Work harder today than yesterday, and the day after tomorrow will be better'))
# 结果
['day', 'morrow']
import re
print(re.findall('compan(?:day|morrow)','Work harder today than yesterday, and the day after tomorrow will be better'))
# 结果
['today', 'tomorrow']
# 分组() 中加入?: 表示将整体匹配出来而不只是()里面的内容。
7.4 常用方法
findall 全部找到返回一个列表
import re
print(re.findall("alex","alexdsb,alex_sb,alexnb,al_ex"))
# 结果
['alex', 'alex', 'alex']
search 从字符串中任意位置进行匹配查找到一个就停止了,返回的是一个对象. 获取匹配的内容必须使用.group()进行获取
import re
print(re.search("sb|nb","alexdsb,alex_sb,alexnb,al_ex").group())
# 结果
sb
match 从字符串开始位置进行匹配
import re
print(re.match('tbjx', 'tbjx alex wusir 日天').group())
# 结果
tbjx
import re
print(re.match('alex', 'tbjx alex wusir 日天'))
# 结果
None
split 分隔 可按照任意分隔符进行分隔
import re
print(re.split('[ ::,;;,]','alex wusir,日天,太白;女神;肖锋:吴超'))
# 结果
['alex', 'wusir', '日天', '太白', '女神', '肖锋', '吴超']
sub 替换
import re
print(re.sub('barry', 'tbjx', 'barry是最好的讲师,barry就是一个普通老师,请不要将barry当男神对待。'))
# 结果
tbjx是最好的讲师,tbjx就是一个普通老师,请不要将tbjx当男神对待。
compile 定义匹配规则
import re
obj = re.compile('\d{2}')
print(obj.findall("alex12345"))
# 结果
['12', '34']
import re
obj = re.compile('\d{2}')
print(obj.search("alex12345").group())
# 结果
12
finditer 返回一个迭代器
import re
g = re.finditer('al',"alex_alsb,al22,aladf")
print(next(g).group())
print([i.group() for i in g])
# 结果
al
['al','al','al']

若有收获,就点个赞吧
0 人点赞
