对话数据包括故事、规则(训练数据也是由这两者组成),从而提供给 Rasa 机器人的对话管理模型。精心编写的对话数据将使机器人可靠地遵循所布置的对话路径,并未知的对话路径下也能去的不错的效果。
1. 设计故事
在设计故事时,需要考虑两组对话交互:常规的对话路径和意料之外的对话路径。常规的对话路径表示用户一直按照我们期望的对话流程进行交流,并总是提供了必要的信息。但是,用户经常会因为问题、闲聊或者其他问题而偏离了原先期望的流程,这种我们称之为意料之外的对话路径。
对于机器人而言,如何优雅地处理意料之外的对话路路径是非常重要的,但预测给定用户采取的对话路径也是不太可能的。通常,开发者在设计意料之外的对话路径时会尝试考虑所有可能的分歧路径。当我们对状态机中每个可能的状态(其中很多状态永远都不会达到)进行规划时,往往做需要大量的额外工作,并会显著地增加训练时间。
相反地,在设计意料之外的对话路径是,我们建议采用对话驱动开发(Conversation-Driven Development,CDD)的方法。对话驱动开发提倡尽早地与测试用户共享你的机器人,并以此来收集真实数据,这些数据可以准确地知道用户是如何偏离意料之中的对话路径的。从这个数据中,我们可以创建故事来完成用户的请求,并开始思考如何引导他们回到常规的对话路径中。
2. 何时编写故事或规则
规则作为一种训练数据,用于在对话管理器中处理平对话片段,这些对话片段应该总是采用相同的对话路径。
规则在实现以下情况时将非常有用:
- 一轮交互:有些消息不需要上下文来回答他们,规则是将意图映射到响应的非常简单的方法,它通过给消息指定固定的答案。
- 回退行为:结合
FallbackClassifier,我们可以编写规则来响应具有特定回退行为的低置信度的用户喜消息。 - 表单:激活和提交表单通常会遵循固定路径,我们也可以在表单期间编写规则来处理意料之外的用户输入。
因为规则并不能在未知对话上取得较好效果,我们应该在单轮对话片段中保留他们,然后使用故事来训练多轮对话。
以下是一个示例,机器人向意图为 greet 的用户消息返回固定的 utter_greet 响应:
rules:- rule: Greeting Rulesteps:- intent: greet- action: utter_greet
对于多轮交互,我们可以定义一个故事,例如:
stories:- story: Greeting and ask user how they're doingsteps:- intent: greet- action: utter_greet- action: utter_ask_how_doing- intent: doing_great- action: utter_happy
3. 管理对话流程
以下是管理故事中对话流程的一些小技巧:
- 何时使用插槽来影响对话
- 实现分支逻辑
- 使用“或”语句和检查点
- 在故事中创建逻辑中断
3.1 何时使用插槽来影响对话
插槽相当于机器人的内存,在定义插槽时,我们可以定义该插槽是否可以影响对话。对于带有influence_conversation属性的插槽,如果设置为false,则插槽只用于存储信息。如果设置为true的话,则可以基于所存储的信息来影响对话流程。
插槽可以在基于插槽映射的每个用户消息后进行设置,它们也可以通过自定义动作来响应用户消息。所有影响对话的插槽都需要定在故事或规则中。例如,你可以使用自定义动作的布尔类型插槽,基于该槽值来控制对话流程:
stories:- story: Welcome message, premium usersteps:- intent: greet- action: action_check_profile- slot_was_set:- premium_account: true- action: utter_welcome_premium- story: Welcome message, basic usersteps:- intent: greet- action: action_check_profile- slot_was_set:- premium_account: false- action: utter_welcome_basic- action: utter_ask_upgrade
如果不希望插槽影响对话流程,我们应该设置插槽的 influence_vonversation 为 false,此时也不需要在故事中为这些插槽设置 slot_was_set 事件。
3.2 实现分支逻辑
在编写故事时,有时下一个动作取决于自定义动作中返回的值。在这些情况下,重要的是要在返回插槽和直接使用自定义动作代码来影响机器人接下来的动作之间找到平衡。
在仅使用一个值来确定机器人相应的情况下,考虑将决策逻辑嵌入到自定义操作中,而不是在故事中直接使用插槽。这样的方式可以减少整体的复杂性,并让你的故事更易于管理。
例如,你可以转换这些故事:
stories:- story: It's raining nowsteps:- intent: check_for_rain- action: action_check_for_rain- slot_was_set:- raining: true- action: utter_is_raining- action: utter_bring_umbrella- story: It isn't raining nowsteps:- intent: check_for_rain- action: action_check_for_rain- slot_was_set:- raining: false- action: utter_not_raining- action: utter_no_umbrella_needed
变成一个故事的话:
stories:- story: check for rainsteps:- intent: check_for_rain- action: action_check_for_rain
对应的自定义动作代码:
def run(self, dispatcher, tracker, domain):is_raining = check_rain()if is_raining:dispatcher.utter_message(template="utter_is_raining")dispatcher.utter_message(template="utter_bring_umbrella")else:dispatcher.utter_message(template="utter_not_raining")dispatcher.utter_message(template="utter_no_umbrella_needed")return []
如果该值用于影响后续的动作流程,返回一个特征化槽来确定故事。例如,如果你想收集关于新用户的信息,但是不想返回新用户,那么故事可以这样编写:
stories:- story: greet new usersteps:- intent: greet- action: check_user_status- slot_was_set:- new_user: true- action: utter_greet- action: new_user_form- active_loop: new_user_form- active_loop: null- story: greet returning usersteps:- intent: greet- action: check_user_status- slot_was_set:- new_user: false- action: utter_greet- action: utter_how_can_help
3.3 使用“或”语句和检查点
“或”语句和检查点在减少必须编写故事的数量上非常有用。但是,在使用必须非常注意,过度使用“或”语句或者检查点将会降低训练速度,创建太多的检查点也会让故事变得更难理解。
1)“或”语句
在机器人以相同方式处理故事中的不同意图或槽事件,你可以使用“或”语句作为创建新故事的替代方法。
例如,你可以将以下两个故事进行合并:
stories:- story: newsletter signupsteps:- intent: signup_newsletter- action: utter_ask_confirm_signup- intent: affirm- action: action_signup_newsletter- story: newsletter signup, confirm via thankssteps:- intent: signup_newsletter- action: utter_ask_confirm_signup- intent: thanks- action: action_signup_newsletter
使用“或”语句变成一个单独的故事:
stories:- story: newsletter signup with ORsteps:- intent: signup_newsletter- action: utter_ask_confirm_signup- or:- intent: affirm- intent: thanks- action: action_signup_newsletter
在训练时,这个故事会被拆分为两个原始故事。
:::warning
💡 考虑重构数据
———————————————
如果你注意到频繁地在故事中使用“或”语句,考虑一下重构你的意图来减少其颗粒度,并更广泛地捕获用户消息。
:::
2)检查点
通常,检查点在将故事模块化为单独块很有用。例如,如果希望机器人在每轮对话流程结束时询问用户的反馈,你可以使用检查点来避免在每个故事结束时包含反馈交互:
stories:- story: beginning of conversationsteps:- intent: greet- action: utter_greet- intent: goodbye- action: utter_goodbye- checkpoint: ask_feedback- story: user provides feedbacksteps:- checkpoint: ask_feedback- action: utter_ask_feedback- intent: inform- action: utter_thank_you- action: utter_anything_else- story: user doesn't have feedbacksteps:- checkpoint: ask_feedback- action: utter_ask_feedback- intent: deny- action: utter_no_problem- action: utter_anything_else
:::warning
🩸 不要过度使用
————————————————
使用检查点的目的在于让许多不同故事中的一些重用对话变得更简单。我们强烈建议不要在现有检查点内使用检查点,因为这样会显著地增加训练时间,并使得故事难以理解。
:::
3.4 在故事中创建逻辑中断
在设计对话流程时,通常很想创建长篇故事样本,从头到尾捕捉完整地对话交互。在许多情况下,这将增加所需的训练故事数量,从而考虑使用分支路径。相反地,考虑将较长地故事分割成用于处理子任务地较小对话块。
一个常规路径的故事(用于处理丢失信用卡)示例如下:
stories:- story: Customer loses a credit card, reviews transactions, and gets a new cardsteps:- intent: card_lost- action: check_transactions- slot_was_set:- reviewed_transactions: ["starbucks"]- action: utter_ask_fraudulent_transactions- intent: inform- action: action_update_transactions- intent: affirm- action: utter_confirm_transaction_dispute- action: utter_replace_card- action: mailing_address_form- active_loop: mailing_address- active_loop: null- action: utter_sent_replacement- action: utter_anything_else- intent: affirm- action: utter_help
处理丢失信用卡涉及一系列子任务,即检查欺诈交易的消费历史、确认更换卡的邮寄地址,然后跟进用户的任何额外请求。在此对话中,机器人会在多个位置提示用户输入,从而创建需要考虑的分支路径。
例如,当提示 utter_ask_fraudulent_transactions,如果不适用的话,用户可能会以 deny 意图进行响应。当机器人问及是否可以帮助他们做一些其他事情时,用户还可以选择以 deny 意图进行响应。
我们可以将下面这个长故事分割成几个小故事:
stories:- story: Customer loses a credit cardsteps:- intent: card_lost- action: utter_card_locked- action: spending_history_form- active_loop: spending_history_form- active_loop: null- slot_was_set:- reviewed_transactions: ["starbucks"]- action: utter_ask_fraudulent_transactions- story: Customer reviews transactions and gets a new cardsteps:- action: utter_ask_fraudulent_transactions- intent: inform- action: action_update_transactions- slot_was_set:- reviewed_transactions: ["target", "starbucks"]- intent: affirm- action: utter_confirm_transaction_dispute- action: utter_replace_card- action: mailing_address_form- active_loop: mailing_address- active_loop: null- action: utter_sent_replacement- action: utter_anything_else- story: Customer has something else they need help withsteps:- action: utter_anything_else- intent: affirm- action: utter_help
4. 处理上下文切换
通常情况下,用户不会回答你向他们询问的信息,而是用不相关的问题偏离常规对话路径。使用 CDD 来了解用户正在采取哪些意料之外的对话路径,你可以创建用于上下文切换的故事。
4.1 使用规则来进行上下文切换
在一些情况下,我们可以使用规则而不需要通过故事来处理上下文切换。考虑以下的对话场景: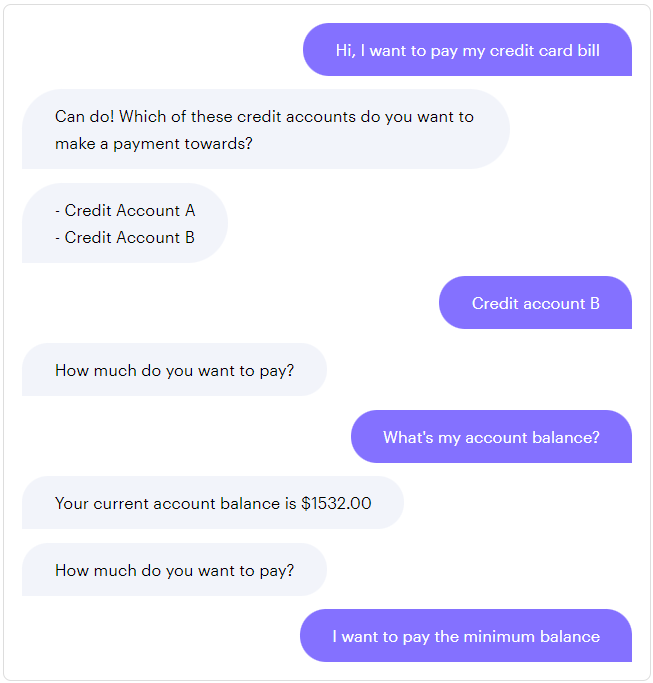
在上面例子中,用户在支付支付卡账单的期间,要求查询账户的余额,然后被引导会信用卡支付形式。因为无论上下文如何,用户询问账户余额都应该始终得到相同的响应,因此我们可以创建一个规则,该规则将在现有流程内自动触发:
rules:- rule: Check my account balancesteps:- intent: check_account_balance- action: action_get_account_balance
默认情况下,表单将继续保持活跃状态,并重新提示输入必要的信息,而无须创建额外的训练故事。
4.2 使用故事来进行上下文切换
当用户感叹需要多轮对话时,你需要编写额外的故事来处理上下文切换。如果有两个不同的对话流程,并希望用户能在这些流程中进行选择,那么你需要创建故事来指定如何进行切换,以及如何维护上下文。
例如,如果你想要根据用户的询问切换上下文,然后在该询问完成后返回原始流程: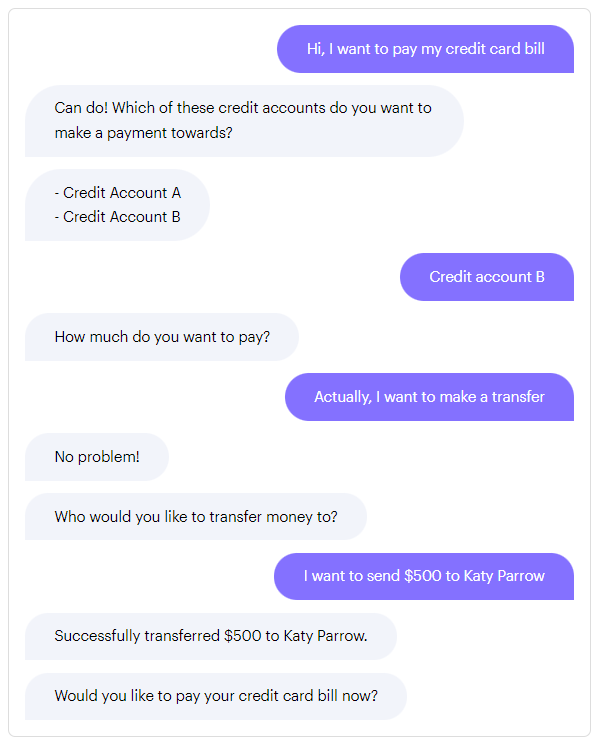
你将需要创建一个故事来描述这种上下文切换的交互:
stories:- story: Context switch from credit card payment to money transfersteps:- intent: pay_credit_card- action: credit_card_payment_form- active_loop: credit_card_payment_form- intent: transfer_money # - user requests a money transfer- active_loop: null # - deactivate the credit card form- action: transfer_money_form # - switch to the money transfer form- active_loop: transfer_money_form- active_loop: null- action: utter_continue_credit_card_payment # - once the money transfer is completed,# ask the user to return to the# credit card payment form
5. 管理对话数据文件
我们可以将训练数据作为单个文件或包含多个文件的目录提供给 Rasa,在编写故事和规则时,根据所表示的对话类型创建单独的文件通常是个好主意。例如,你可能创建一个 chichat.yaml 来处理闲聊,以及 faqs.yaml 来处理常规问题。
6. 使用交互式学习
交互式学习通过与机器人进行交谈,并提供相应的反馈,这将使得编写故事变得更加容易。这是探索机器人可以做什么的强大方法,也是修复它所犯错误的最简单方法。基于机器人学习的对话一个优点在于,当机器人还不知道如何做某些事情时,你可以教他。
在 Rasa 中,我们可以使用 rasa interactive 在命令中运行交互式学习。Rasa X 提供了 UI 界面来进行交互式学习,并且你可以使用任何用户对话作为起点。
6.1 命令行交互式学习
CLI 命令 rasa interactive 将在命令行中开启交互式学习,如果机器人有自定义动作,确保在单独的终端窗口中运行操作服务器。
在交互模式中,在机器人继续之前,你将被要求确认预测的每个意图和动作。以下是一个示例:
? Next user input: hello? Is the NLU classification for 'hello' with intent 'hello' correct? Yes------Chat History# Bot You────────────────────────────────────────────1 action_listen────────────────────────────────────────────2 hellointent: hello 1.00------? The bot wants to run 'utter_greet', correct? (Y/n)
我们可以在对话的每一步看到历史记录和槽值。如果输入 y 来批准预测,机器人将会继续下面的流程。如果你输入 n 的话,那么我们就有机会在继续之前更正预测:
? What is the next action of the bot? (Use arrow keys)» <create new action>1.00 utter_greet0.00 ...0.00 action_back0.00 action_deactivate_loop0.00 action_default_ask_affirmation0.00 action_default_ask_rephrase0.00 action_default_fallback0.00 action_listen0.00 action_restart0.00 action_session_start0.00 action_two_stage_fallback0.00 utter_cheer_up0.00 utter_did_that_help0.00 utter_goodbye0.00 utter_happy0.00 utter_iamabot

若有收获,就点个赞吧
0 人点赞
