第 1 节 概述
1.1 工作流调度系统
⼀个完整的数据分析系统通常都是由⼤量任务单元组成:
- shell脚本程序
- java程序
- mapreduce程序
- hive脚本等
各任务单元之间存在时间先后及前后依赖关系,为了很好地组织起这样的复杂执行计划,需要⼀个工作流调度系统来调度任务的执行。
假如,我有这样一个需求,某个业务系统每天产生20G原始数据,每天都要对其进行处理,处理步骤如下所示:
- 通过Hadoop先将原始数据同步到HDFS上;
- 借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储到多张Hive表中;
- 需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive大表;
- 将明细数据进行各种统计分析,得到结果报表信息;
需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
1.2 工作流调度实现方式
简单的任务调度
- 直接使用linux的crontab
复杂的任务调度
功能
两者均可以调度mapreduce,pig,java,脚本⼯作流任务
两者均可以定时执⾏工作流任务
- ⼯作流定义
Azkaban使⽤Properties文件定义工作流
Oozie使⽤XML文件定义工作流
- ⼯作流传参
Azkaban⽀持直接传参,例如${input}
Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
- 定时执⾏
Azkaban的定时执行任务是基于时间的
Oozie的定时执⾏任务基于时间和输入数据
- 资源管理
Azkaban有较严格的权限控制,如用户对⼯作流进行读/写/执行等操作
Oozie暂⽆严格的权限控制
- ⼯作流执⾏
Azkaban有两种运行模式,分别是solo server mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点)
Oozie作为⼯作流服务器运⾏,⽀持多用户和多工作流
第 2 节 Azkaban介绍
Azkaban是由linkedin(领英)公司推出的⼀个批量工作流任务调度器,⽤于在一个⼯作流内以一个特定的顺序运行⼀组工作和流程。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web⽤户界面维护和跟踪你的工作流。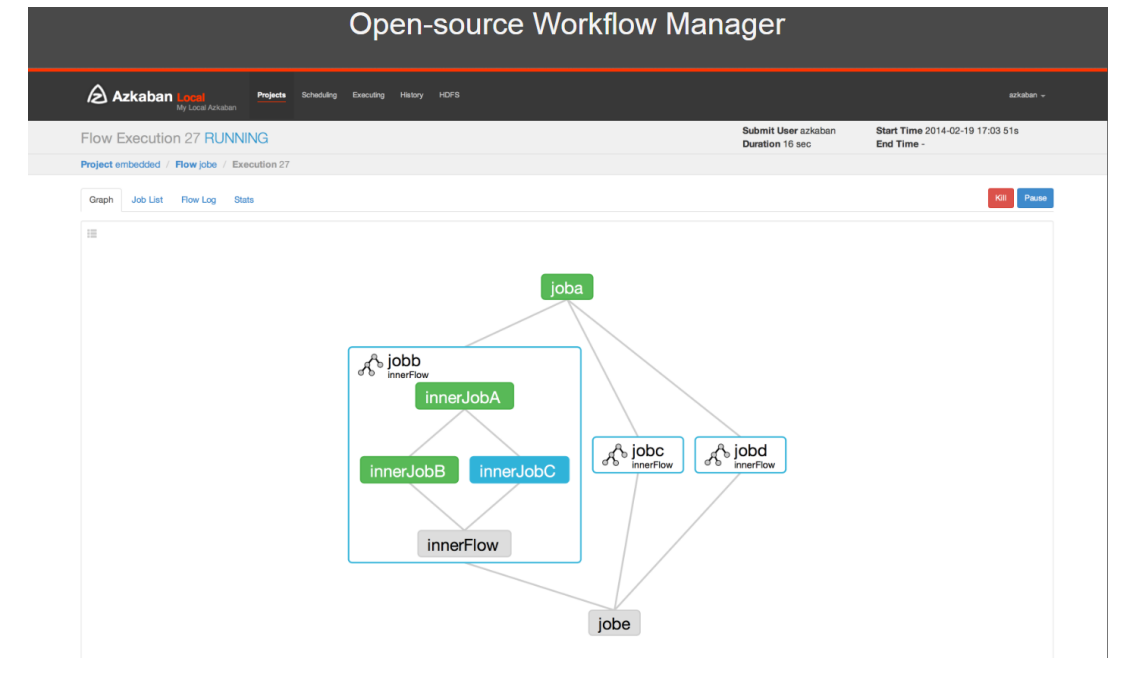
Azkaban定义了一种KV⽂件(properties)格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界⾯维护和跟踪你的工作流。
有如下功能特点
- Web⽤户界⾯
- ⽅便上传工作流
- 方便设置任务之间的关系
- 调度工作流
架构⻆色
- mysql服务器: 存储元数据,如项⽬名称、项目描述、项目权限、任务状态、SLA规则等
- AzkabanWebServer:对外提供web服务,使用户可以通过web⻚面管理。职责包括项⽬管理、权限授权、任务调度、监控executor。
- AzkabanExecutorServer:负责具体的工作流的提交、执行。
第 3 节 Azkaban安装部署
3.1 Azkaban的安装准备工作
1 编译
这⾥选⽤azkaban3.51.0这个版本⾃己进行重新编译,编译完成之后得到我们需要的安装包进行安装 ```shell cd /opt/lagou/software/
wget https://github.com/azkaban/azkaban/archive/3.51.0.tar.gz
tar -zxvf 3.51.0.tar.gz -C ../servers/
cd /opt/lagou/servers/azkaban-3.51.0/
yum -y install git yum -y install gcc-c++
./gradlew build installDist -x test
Gradlew是一个基于Apache Ant和Apache Maven的项⽬自动化构建工具。-x test 跳过测试。(注意联网!下载jar可能会失败、慢)<br />**2 上传编译后的安装文件**<br />****<a name="28523e10"></a>## 3.2 multiple-executor模式部署<a name="cfb84e94"></a>### 1 安装所需软件Azkaban Web服务安装包<br />azkaban-web-server-0.1.0-SNAPSHOT.tar.gz<br />Azkaban执行服务安装包<br />azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz<br />sql脚本<br /><br />**节点规划**<br />**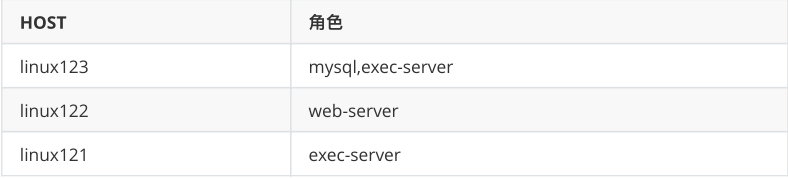**<a name="22f9078f"></a>### 2 数据库准备linux123```shell#解压数据库脚本tar -zxvf azkaban-db-0.1.0-SNAPSHOT.tar.gz -C /opt/lagou/servers/azkaban
进入mysql的客户端执行以下命令
mysql -uroot -p
# 设置密码位数和强度
SET GLOBAL validate_password_length=5;
SET GLOBAL validate_password_policy=0;
# 创建用户azkaban
CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban';
# 赋权
GRANT all privileges ON azkaban.* to 'azkaban'@'%' identified by 'azkaban' WITH GRANT OPTION;
CREATE DATABASE azkaban;
use azkaban;
#加载初始化sql创建表
source /opt/lagou/servers/azkaban/azkaban-db-0.1.0-SNAPSHOT/create-all-sql-0.1.0-SNAPSHOT.sql;
3 配置Azkaban-web-server
进入linux122节点
解压azkaban-web-server
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C ../../servers/azkaban/
进入解压后的目录
cd /opt/lagou/servers/azkaban/azkaban-web-server-0.1.0-SNAPSHOT
#生成ssl证书:
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
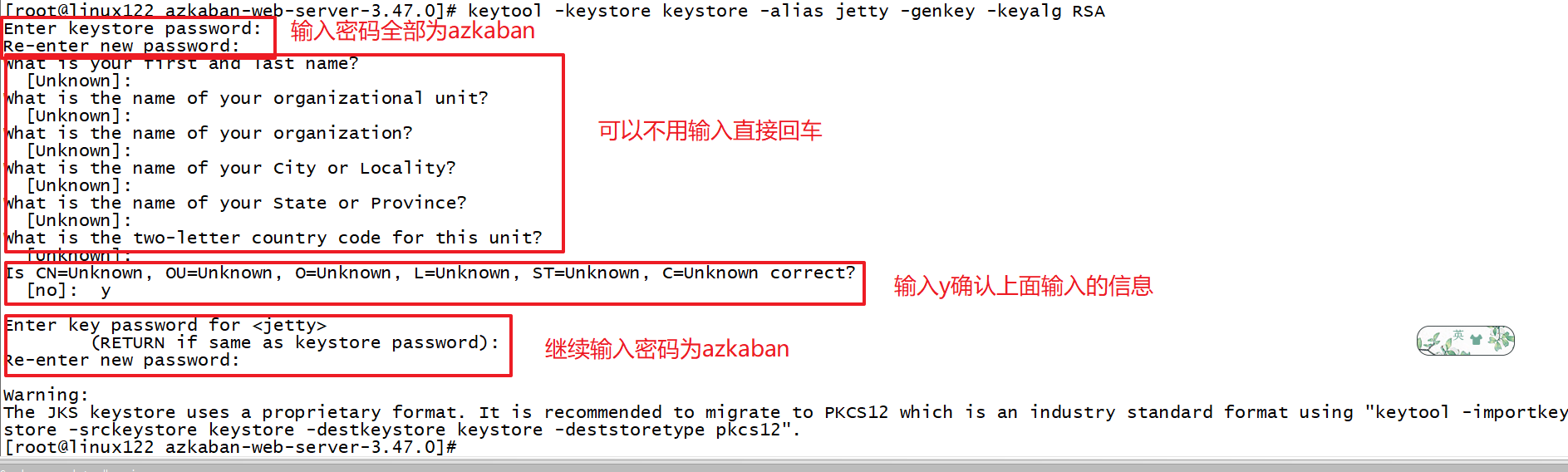
修改 azkaban-web-server的配置文件
cd /opt/lagou/servers/azkaban-web-server-3.51.0/conf
vim azkaban.properties
# Azkaban Personalization Settings
azkaban.name=Test
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=web/
default.timezone.id=Asia/Shanghai # 修改点1:时区注意后⾯不要有空格
# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=conf/azkaban-users.xml
# Azkaban Jetty server properties. 开启使用ssl 并且指定端⼝
jetty.use.ssl=true # 修改点2:改为true
jetty.port=8443 # 修改点3:端口改为8443
jetty.maxThreads=25
# 修改点4:增加KeyStore for SSL ssl相关配置
jetty.keystore=keystore
jetty.password=azkaban
jetty.keypassword=azkaban
jetty.truststore=keystore
jetty.trustpassword=azkaban
注意密码和证书路路径
# 修改点5:Azkaban mysql settings by default. Users should configure their own username and password.
database.type=mysql
mysql.port=3306
mysql.host=linux123
mysql.database=azkaban
mysql.user=root
mysql.password=12345678
mysql.numconnections=100
#Multiple Executor 设置为false
azkaban.use.multiple.executors=true
# 修改点6:注释掉校验
#azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,Cp uStatus
azkaban.executorselector.comparator.NumberOfAssignedFlowComparator=1
azkaban.executorselector.comparator.Memory=1
azkaban.executorselector.comparator.LastDispatched=1
azkaban.executorselector.comparator.CpuUsage=1
添加属性
mkdir -p plugins/jobtypes
cd plugins/jobtypes/
vim commonprivate.properties
azkaban.native.lib=false
execute.as.user=false
memCheck.enabled=false
4 配置Azkaban-exec-server
linux123节点,上传exec安装包到/opt/lagou/software/azkaban
tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz –C /opt/lagou/servers/azkaban/
修改azkaban-exec-server的配置文件
cd /opt/lagou/servers/azkaban-exec-server-0.1.0-SNAPSHOT/conf
vim azkaban.properties
# 修改点1:修改时区
default.timezone.id=Asia/Shanghai
# 修改点2:webserver url
azkaban.webserver.url=https://linux122:8443
# 修改点3:数据库配置
database.type=mysql
mysql.port=3306
mysql.host=linux123
mysql.database=azkaban
mysql.user=root
mysql.password=12345678
# 修改点4:增加 Azkaban Executor settings
executor.port=12321
分发exec-server到linux121节点
scp -r azkaban-exec-server-0.1.0-SNAPSHOT/ linux121:/opt/lagou/servers/azkaban/
5 启动服务
先启动exec-server(linux121,linux123)
再启动web-server(linux122)
#启动exec-server
bin/start-exec.sh
#启动web-server
bin/start-web.sh
激活exec-server
启动webServer之后进程失败消失,可通过安装包根⽬录下对应启动日志进行排查。
需要⼿动激活executor
cd /opt/lagou/servers/azkaban/azkaban-exec-server-0.1.0-SNAPSHOT
curl -G "linux123:$(<./executor.port)/executor?action=activate" && echo
启动时遇到的问题:
原因:权限不够
解决办法:
- 方式一:配置文件中mysql配置前面创建的azkaban用户
- 方式二:修改root用户权限,允许其他节点连接
# 赋予最大的权限 GRANT all ON *.* to 'root'@'%' identified by '12345678' WITH GRANT OPTION; flush privileges;
第 4 节 Azkaban使用
4.1 shell command调度
与单机模式操作案例一样
创建job描述文件:vim command.job
type=command command=echo 'hello'将描述文件打包成command.zip:zip command.job
- 通过azkaban的web界面创建project并上传压缩包
- 执行该job
4.2 job依赖调度
创建有依赖关系的多个job描述
第一个job:foo.job
第二个job:bar.job依赖foo.jobtype=command command=echo 'hello'
将上述两个文件打包成一个压缩包:foobar.ziptype=command dependencies=foo command=echo 'bar'
在azkaban的web管理界面创建工程并上传zip包
启动⼯作流flow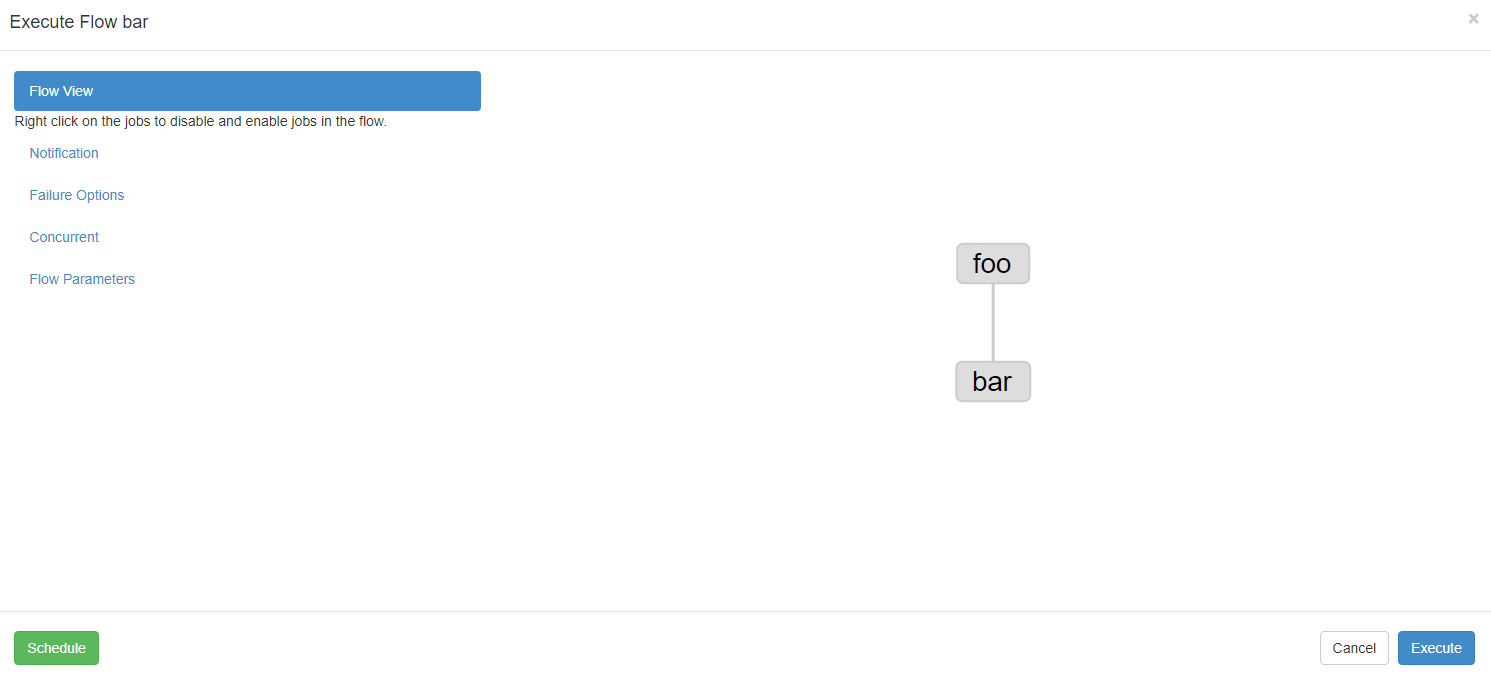
4.3 HDFS任务调度
创建job描述文件fs.job
打包、web界面创建project、上传、启动执行。type=command command=/opt/lagou/servers/hadoop-2.9.2/bin/hadoop fs -mkdir /azkaban
4.4 MapReduce任务调度
mr任务依然可以使用command的job类型来执行
创建job描述文件,及mr程序jar包(示例中直接使用hadoop⾃带的example jar)
mrwc.job
将所有job资源文件打到⼀个zip包中type=command command=/opt/lagou/servers/hadoop-2.9.2/bin/hadoop jar hadoop-mapreduce-examples-2.9.2.jar wordcount /wordcount/input /wordcount/azout
在azkaban的web管理界面创建工程并上传zip包
启动job
遇到虚拟机内存不足运行缓慢的情况:
1. 增大机器内存
2. 使用清除系统缓存命令,暂时释放一些内存[root@linux123 mapreduce]# echo 1 >/proc/sys/vm/drop_caches [root@linux123 mapreduce]# echo 2 >/proc/sys/vm/drop_caches [root@linux123 mapreduce]# echo 3 >/proc/sys/vm/drop_caches4.5 Hive脚本任务调度
创建job描述文件和hive脚本
Hive脚本: test.sql
Job描述⽂件:hivef.jobuse default; drop table aztest; create table aztest(id int,name string) row format delimited fields terminated by ',';
将所有job资源文件打到一个zip包中创建工程并上传zip包,启动jobtype=command command=/opt/lagou/servers/hive-2.3.7/bin/hive -f 'test.sql'4.6 定时任务调度
除了⼿动立即执行工作流任务外,azkaban也支持配置定时任务调度。
开启方式如下: ⾸页选择待处理的project 选择左边schedule表示配置定时调度信息,选择右边execute表示⽴即执行工作流任务。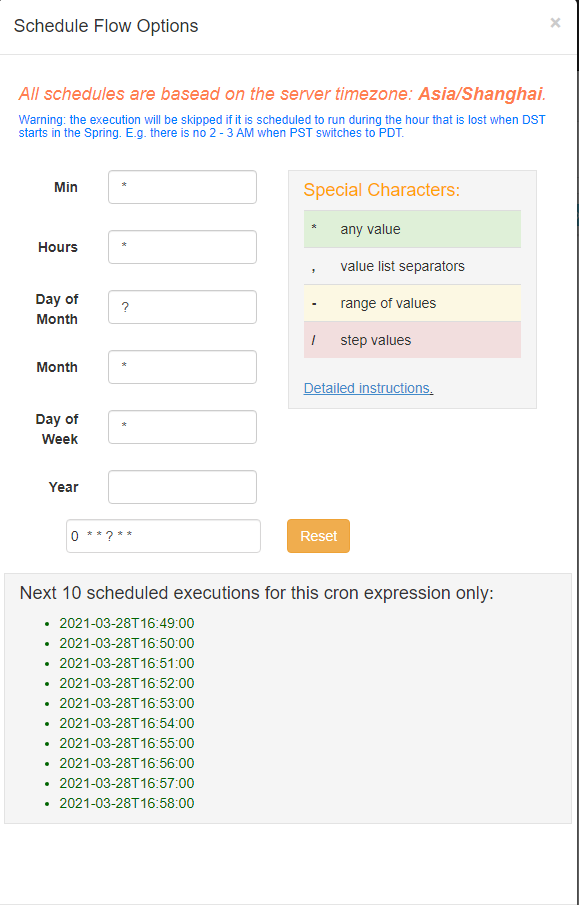

若有收获,就点个赞吧
0 人点赞
