ZooKeeper数据模型Znode
在ZooKeeper中,数据信息被保存在⼀个个数据节点上,这些节点被称为znode。ZNode 是 Zookeeper 中最⼩数据单位,在 ZNode 下面又可以再挂 ZNode,这样⼀层层下去就形成了一个层次化命名空间ZNode树,我们称为ZNode Tree,它采⽤了类似⽂件系统的层级树状结构进行管理。见下图示例: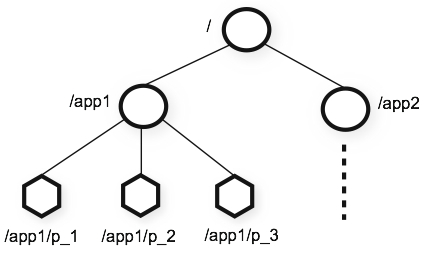
在Zookeeper中,每⼀个数据节点都是一个ZNode,上图根⽬录下有两个节点,分别是app1 和 app2,其中 app1 下⾯又有三个子节点,所有ZNode按层次化进行组织,形成这么⼀颗树,ZNode的节点路径标识⽅式和Unix文件系统路径非常相似,都是由⼀系列使用斜杠(/)进行分割的路径表示,开发人员可以向这个节点写⼊数据,也可以在这个节点下面创建子节点。
3.1 ZNode的类型
Zookeeper 节点类型可以分为三大类:
- 持久性节点(Persistent)
- 临时性节点(Ephemeral)
- 顺序性节点(Sequential)
在开发中在创建节点的时候通过组合可以生成以下四种节点类型:持久节点、持久顺序节点、临时节点、临时顺序节点。
不同类型的节点则会有不同的生命周期。
持久节点(createPersistent):是Zookeeper中最常见的⼀种节点类型,所谓持久节点,就是指节点被创建后会一直存在服务器,直到删除操作主动清除。
持久顺序节点(createPersistentSequential):就是有顺序的持久节点,节点特性和持久节点是一样的,只是额外特性表现在顺序上。 顺序特性实质是在创建节点的时候,会在节点名后面加上⼀个数字后缀,来表示其顺序。
临时节点(createEphemeral):就是会被⾃动清理掉的节点,它的生命周期和客户端会话绑在一起,客户端会话结束,节点会被删除掉。与持久性节点不同的是,临时节点不能创建⼦节点。
临时顺序节点(createEphemeralSequential):就是有顺序的临时节点,和持久顺序节点相同,在其创建的时候会在名字后面加上数字后缀。
事务ID
⾸先,先了解,事务是对物理和抽象的应用状态上的操作集合。往往在现在的概念中,狭义上的事务通常指的是数据库事务,⼀般包含了一系列对数据库有序的读写操作,这些数据库事务具有所谓的ACID特性,即原子性(Atomic)、⼀致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
而在ZooKeeper中,事务是指能够改变ZooKeeper服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新等操作。对于每一个事务请求,ZooKeeper都会为其分配一个全局唯一的事务ID,⽤ZXID来表示,通常是一个64位的数字。每一个ZXID 对应一次更新操作,从这些ZXID中可以间接地识别出ZooKeeper处理这些更新操作请求的全局顺序
zk中的事务指的是对zk服务器状态改变的操作(create,update data,更新字节点);zk对这些事务操作都会编号,这个编号是⾃增长的被称为ZXID。
3.2 ZNode的状态信息
#使用bin/zkCli.sh 连接到zk集群[zk: localhost:2181(CONNECTED) 2] get /zookeepercZxid = 0x0ctime = Wed Dec 31 19:00:00 EST 1969mZxid = 0x0mtime = Wed Dec 31 19:00:00 EST 1969pZxid = 0x0cversion = -1dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 0numChildren = 1
整个 ZNode 节点内容包括两部分:节点数据内容和节点状态信息。数据内容是空,其他的属于状态信息。
cZxid 就是 Create ZXID,表示节点被创建时的事务ID。ctime 就是 Create Time,表示节点创建时间。mZxid 就是 Modified ZXID,表示节点最后一次被修改时的事务ID。mtime 就是 Modified Time,表示节点最后⼀次被修改的时间。pZxid 表示该节点的子节点列表最后⼀次被修改时的事务 ID。只有子节点列表变更才会更新 pZxid,子节点内容变更不会更新。cversion 表示子节点的版本号。dataVersion 表示内容版本号。aclVersion 标识acl版本ephemeralOwner 表示创建该临时节点时的会话 sessionID,如果是持久性节点那么值为 0dataLength 表示数据⻓长度。numChildren 表示直系⼦节点数。
3.3 Watcher机制
Zookeeper使用Watcher机制实现分布式数据的发布/订阅功能
一个典型的发布/订阅模型系统定义了一种一对多的订阅关系,能够让多个订阅者同时监听某一个主题对象,当这个主题对象⾃身状态变化时,会通知所有订阅者,使它们能够做出相应的处理。
在 ZooKeeper 中,引⼊了 Watcher 机制来实现这种分布式的通知功能。ZooKeeper 允许客户端向服务端注册一个 Watcher 监听,当服务端的⼀些指定事件触发了这个Watcher,那么Zk就会向指定客户端发送⼀个事件通知来实现分布式的通知功能。
整个Watcher注册与通知过程如图所示。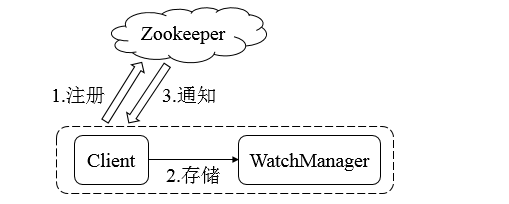
Zookeeper的Watcher机制主要包括客户端线程、客户端WatcherManager、Zookeeper服务器三部分。
具体⼯作流程为:
- 客户端在向Zookeeper服务器注册的同时,会将Watcher对象存储在客户端的WatcherManager当中
- 当Zookeeper服务器触发Watcher事件后,会向客户端发送通知
- 客户端线程从WatcherManager中取出对应的Watcher对象来执行回调逻辑

若有收获,就点个赞吧
0 人点赞
