Hive支持关系型数据库的绝大多数基本数据类型,同时也支持4种集合数据类型。
1、基本数据类型及转换
Hive类似和java语言中一样,会支持多种不同长度的整型和浮点类型数据,同时也支持布尔类型、字符串类型,时间戳数据类型以及二进制数组数据类型等。
详细信息见下表: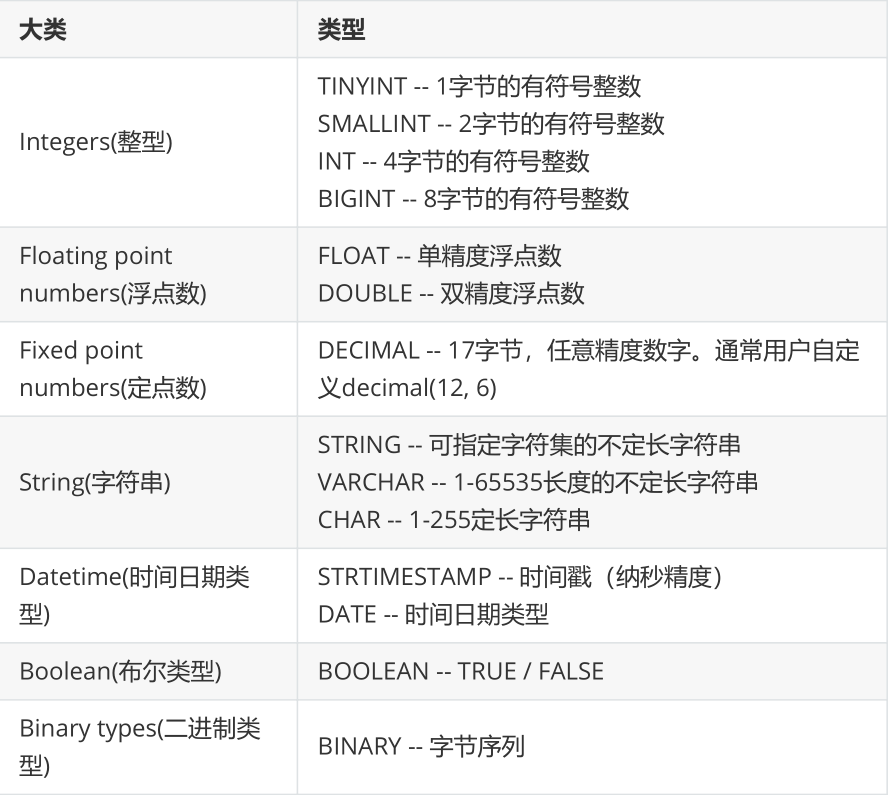
这些类型名称都是 Hive 中保留字。这些基本的数据类型都是 java 中的接口进行实现的,因此与 java 中数据类型是基本一致的。
数据类型的隐式转换
Hive的数据类型是可以进行隐式转换的,类似于Java的类型转换。如用户在查询中将一种浮点类型和另一种浮点类型的值做对比,Hive会将类型转换成两个浮点类型中值较大的那个类型,即:将FLOAT类型转换成DOUBLE类型;当然如果需要的话,任意整型会转化成DOUBLE类型。 Hive 中基本数据类型遵循以下层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。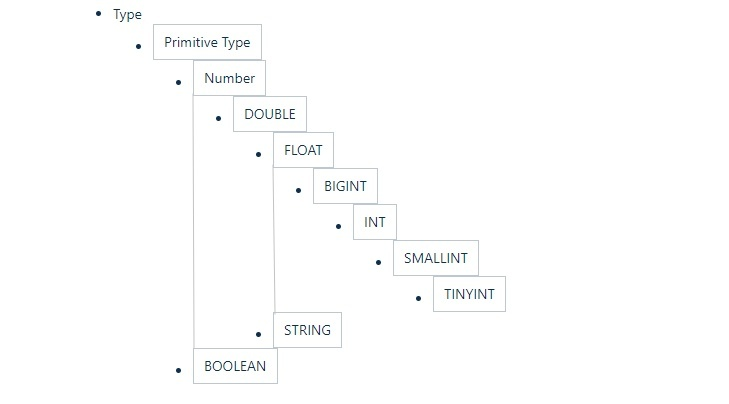
数据类型的显示转换
使用cast函数进行强制类型转换;如果强制类型转换失败,返回NULL
hive> select cast('1111s' as int);OKNULLhive> select cast('1111' as int);OK1111
2、集合数据类型
Hive支持集合数据类型,包括array、map、struct、union
**
和基本数据类型一样,这些类型的名称同样是保留字;
ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似;
STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套;
hive> select array(1,2,3);
OK
[1,2,3]
-- 使用 [] 访问数组元素
hive> select arr[0] from (select array(1,2,3) arr) tmp;
hive> select map('a', 1, 'b', 2, 'c', 3);
OK
{"a":1,"b":2,"c":3}
-- 使用 [] 访问map元素
hive> select mymap["a"] from (select map('a', 1, 'b', 2, 'c', 3) as mymap) tmp;
-- 使用 [] 访问map元素。 key 不存在返回 NULL
hive> select mymap["x"] from (select map('a', 1, 'b', 2, 'c', 3) as mymap) tmp;
NULL
hive> select struct('username1', 7, 1288.68);
OK
{"col1":"username1","col2":7,"col3":1288.68}
-- 给 struct 中的字段命名
hive> select named_struct("name", "username1", "id", 7, "salary", 12880.68);
OK
{"name":"username1","id":7,"salary":12880.68}
-- 使用 列名.字段名 访问具体信息
hive> select userinfo.id
> from (select named_struct("name", "username1", "id", 7, "salary", 12880.68) userinfo) tmp;
-- union 数据类型
hive> select create_union(0, "zhansan", 19, 8000.88) uinfo;
3、文本文件数据编码
Hive表中的数据在存储在文件系统上,Hive定义了默认的存储格式,也支持用户自定义文件存储格式。
Hive默认使用几个很少出现在字段值中的控制字符来表示替换默认分隔符的字符。
Hive默认分隔符

Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001”)、行分隔符(“\n”)以及读取文件数据的方法。
在加载数据的过程中,Hive 不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。
将 Hive 数据导出到本地时,系统默认的分隔符是^A、^B、^C 这些特殊字符,使用 cat 或者 vim 是看不到的;
在 vi 中输入特殊字符:
- (Ctrl + v) + (Ctrl + a) => ^A
- (Ctrl + v) + (Ctrl + b) => ^B
- (Ctrl + v) + (Ctrl + c) => ^C
^A / ^B / ^C 都是特殊的控制字符,使用 more 、 cat 命令是看不见的;可以使用cat -A file.dat查看。
4、读时模式
在传统数据库中,在加载时发现数据不符合表的定义,则拒绝加载数据。数据在写入数据库时对照表模式进行检查,这种模式称为”写时模式”(schema on write)。
写时模式 -> 写数据检查 -> RDBMS;
Hive中数据加载过程采用”读时模式” (schema on read),加载数据时不进行数据格式的校验,读取数据时如果不合法则显示NULL。这种模式的优点是加载数据迅速。
读时模式 -> 读时检查数据 -> Hive;
好处:加载数据快;
问题:数据显示NULL

若有收获,就点个赞吧
0 人点赞
