一、何为大数据
1、大数据的定义
宏观定义:无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处
理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
关于 Hadoop 最朴素的原理,就是要使用大量的普通计算机处理大规模数据的存储和分析,而不是建造一台超级计算机。
2、大数据的特点

- 大量:采集、存储和计算的数据量非常大
- 高速:在大数据时代,数据的创建、存储、分析都要求被高速处理,比如电商网站的个性化推荐尽可能要求实时完成推荐,这也是大数据区别于传统数据挖掘的显著特征。
- 多样:数据的形式和来源多样化,包括结构化、半结构化和非结构化的数据
- 真实:确保数据的真实性,才能保证数据分析的正确性
- 低价值:数据价值密度相对较低。
这里有两个问题需要解决:
- 计算机的故障问题。想象我们使用一个有一万台计算机组成的集群,其中一台计算机出现问题的可能性是很高的,所以在大规模计算机集群上要处理好故障问题,就要做到一台计算机出现问题不会影响整个集群。
- 数据的依赖关系。集群由若干台计算机组成,数据也是分布在不同的计算机上面,当你需要计算一个任务的时候,你所需要的数据可能要从若干台计算机进行读取,而你的计算过程也要分配到不同的计算机上。当你的任务分成若干个步骤形成相互依赖的关系时,如何让系统保持高效和正确的运行是一个很大的问题。
3、职业发展路线
从职业发展来看,由大数据开发、挖掘、算法、到架构。从级别来看,从工程师、高级工程师,再
到架构师,甚至到科学家。而且,契合不同的行业领域,又有专属于这些行业的岗位衍生
如涉及金融领域的数据分析师等。大数据的相关工作岗位有很多,有数据分析师、数据挖掘工程师、大数据开发工程师、大数据产品经理、可视化工程师、爬虫工程师、大数据运营经理、大数据架构师、数据科学家等。
4、Hadoop优缺点
Hadoop 的优点**
- 强大的数据存储和处理能力。这个优点是显而易见的,也是最根本的。通过技术手段,Hadoop 实现了只需要增加一些普通的机器就可以获得强大的存储和运算能力。
- 隐藏了大量技术细节。使用 Hadoop 框架,不再需要关注那些复杂的并行计算、负载均衡等内容,只需要调用相关的 API 就可以实现大规模存储和计算。
- 良好的扩展能力。Hadoop 已经不是一个单一的解决方案,它提供了很多不同的组件,不限于我上面列出的这些。公司可以使用标准的方案,也可以根据自己的业务需求来进行细节上的调整甚至是自己的开发。比如说对于计算框架 MapReduce,在很多公司已经使用性能更好的 Spark 或者 Flink 进行了替换。
Hadoop 的缺点**
- 实时性较差。由于 HDFS 存储底层都是在磁盘中进行的,以及原生的 MapReduce 的中间结果也都要存储在磁盘上,所以 Hadoop 的实时性不太好。
- 学习难度较大。虽然说 Hadoop 已经对很多复杂的技术进行了封装,但是仍然挡不住它是一个庞大而复杂的系统。尤其是其中的很多问题都需要在实践中不断摸索,要想学习整个体系几乎是很难在短时间内实现的。
虽然处理大数据的框架并不只Hadoop一种。但Hadoop 是免费的开源的,且是当前应用最广泛的。它最强大的地方就在于能够利用最普通的机器解决了大规模数据存储和运算的问题。
二、Hadoop生态圈
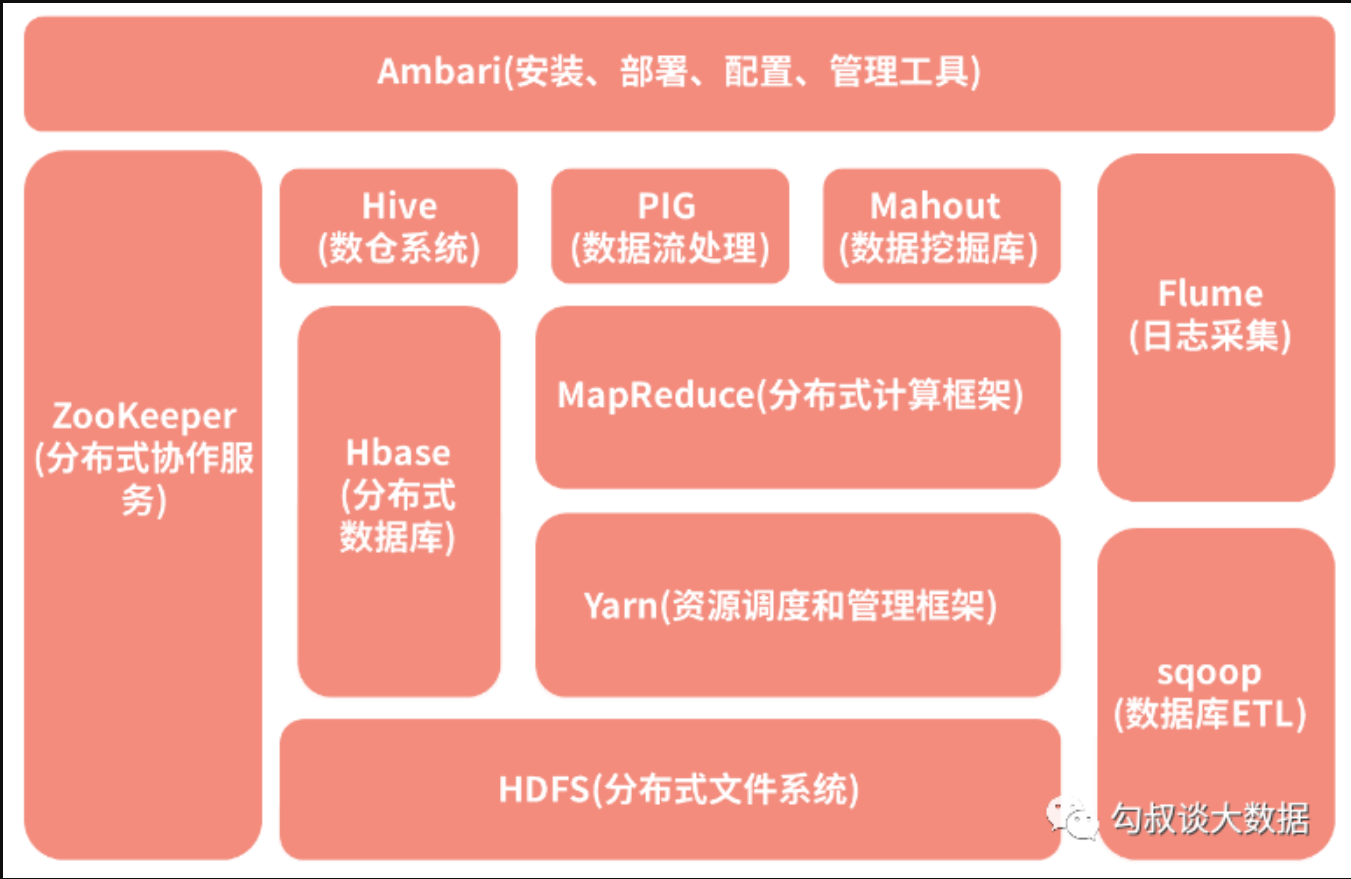
技术栈:
Hadoop(HDFS + MapReduce + Yarn)
- HDFS:是一个分布式文件系统,在Hadoop体系中解决底层存储的问题,支持海量数据的磁盘存储,进行机器的线性扩容,只需要在集群中增加节点,存储能力就会同步增长。
- MapReduce:解决了分布式计算的问题,包括其中的运算逻辑和数据依赖,在MapReduce的应用上,提供了一套编程模型,重点就是实现map函数和reduce函数
- map:用于组织和分割数据
- reduce:主要负责在分布式节点上的数据运算
- MapReduce:编程支持多种语言实现,如JAVA、Scala
- Yarn:资源调度和管理框架
Hive(数仓系统):在HDFS上,Hive是Hadoop体系中的数据仓库工具,可以将结构化的数据文件映射成一个数据表,Hive处理其中的结构化数据文件,本身不进行存储。Hive 提供了一套Hive SQL实现 MapReduce 计算,可以使用与 SQL 十分类似的 Hive SQL 对这些结构化的数据进行统计分析
**
- HBase(分布式数据库):是一个分布式高并发的K-V数据库系统,底层由HDFS支撑,而HBase通过对存储内容的重新组织,克服了HDFS对小文件处理困难的问题,实现了数据的实时操作。互联网公司中,对于量级较大变动较多的数据通常适合使用 HBase 进行存取。
- ZooKeeper(分布式协作服务):直译是动物园管理员。这是因为很多项目都以动物的名字命名,而 ZooKeeper 最常用的场景是作为一个服务的注册管理中心。生产者把所提供的服务提交到 ZooKeeper 中,消费者则去 ZooKeeper 中寻找自己需要的服务,从中获取生产者的信息,然后再去调用生产者的服务。
- Flume(日志采集):是一个分布式、高可靠、高可用的海量日志采集、聚合、传输的系统,(实时采集日志的数据采集引擎)
- Sqoop(数据迁移):主要用于Hadoop与传统数据库之间进行数据的传递
- Impala(交互式实时查询工具):实时数据分析,与Hive配合使用,对Hive的结果数据集进⾏实时分析

若有收获,就点个赞吧
0 人点赞
