一、Zookeeper作业要求
需求:基于Zookeeper实现简易版配置中心
要求实现以下功能:
创建一个Web项目,将数据库连接信息交给Zookeeper配置中心管理,即:当项目Web项目启动时,从Zookeeper进行MySQL配置参数的拉取
要求项目通过数据库连接池访问MySQL(连接池可以自由选择熟悉的)
当Zookeeper配置信息变化后Web项目自动感知,正确释放之前连接池,创建新的连接池
思路分析:
1.定义一个用于发布数据库连接信息到zookeeper的接口,用来修改数据库连接信息
2.项目启动时从zookeeper获取数据库连接信息,创建数据库连接池
3.项目要时刻监听zookeeper中数据库连接信息的变化
4.当发布数据库连接信息到zookeeper中时,如果连接信息有变化,项目会重新从zookeeper中获取数据库连接信息,释放之前的连接池,并创建新的数据库连接池
实现步骤:
1.创建一个spring web项目,添加需要的依赖到pom文件。
<properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.8.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-web</artifactId><version>5.2.8.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>5.2.8.RELEASE</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.4.14</version></dependency><dependency><groupId>com.101tec</groupId><artifactId>zkclient</artifactId><version>0.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.46</version></dependency></dependencies><!-- JVM 运行环境 --><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.5.1</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>UTF-8</encoding></configuration></plugin></plugins></build>
resources目录下新建日志配置文件:log4j.properties
log4j.rootLogger=INFO, Console#Consolelog4j.appender.Console=org.apache.log4j.ConsoleAppenderlog4j.appender.Console.layout=org.apache.log4j.PatternLayoutlog4j.appender.Console.layout.ConversionPattern=%-5p - %m%n
2.定义一个用于修改配置信息的接口:Publisher.java
package com.git.zk;
import org.I0Itec.zkclient.ZkClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Publisher {
Logger logger = LoggerFactory.getLogger(Publisher.class);
ZkClient zkClient = null;
public static final String serverstring = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
//
public static final String path = "/webapp/dblinkcfg";
/**
* 获取zk连接对象
*/
private void connectZk() {
zkClient = new ZkClient(serverstring);
if (!zkClient.exists(path)) {
// 创建保存数据库连接信息的节点
zkClient.createPersistent(path, true);
System.out.println("123");
System.out.println("321");
}
}
/**
* 发布数据库配置信息
*
* @param cfgInfo 连接信息
*/
public void publish(String cfgInfo) {
connectZk();
zkClient.writeData(path, cfgInfo);
logger.info("发布数据库连接信息成功:" + cfgInfo);
}
}
3.定义一个监听器,用于监听zk中保存配置信息的节点(webapp/dblinkcfg)
Listener.java
package com.git.zk;
import com.git.zk.ConnectionManager;
import com.git.zk.Utils;
import org.I0Itec.zkclient.IZkDataListener;
import org.I0Itec.zkclient.ZkClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Properties;
public class Listener {
private static Logger logger = LoggerFactory.getLogger(Listener.class);
// zk服务器地址信息
public static final String serverstring = "hadoop1:2181,hadoop2:2181,hadoop3:2181";
// 获取ZkClient对象
private static ZkClient zkClient = new ZkClient(serverstring);
// 保存数据库配置信息的节点路径
private static String path = "/webapp/dblinkcfg";
/**
* 监听
*
* @throws IOException
*/
public static void monitor() throws IOException {
zkClient.subscribeDataChanges(path, new IZkDataListener() {
public void handleDataChange(String dataPath, Object data) throws Exception {
logger.info("zk中的数据库配置信息发生修改!尝试重新获取数据库连接池...");
// 重新获取配置信息
String cfg = zkClient.readData(dataPath, true);
Properties pro = new Properties();
Utils.loadData(pro, cfg);
// 释放旧的连接池
ConnectionManager.clearPool();
// 创建新的连接池
Utils.createDbPool(pro);
}
public void handleDataDeleted(String dataPath) throws Exception {
logger.error("zk中的数据库配置信息已被删除!");
}
});
}
}
4.数据库连接管理器:ConnectionManager.java
package com.git.zk;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.LinkedList;
import java.util.List;
/**
* 数据库连接管理器
*/
public class ConnectionManager {
private static List<Connection> pool = new LinkedList<Connection>();
public static String Url = "";
public static String USERNAME = "";
public static String PASSWORD = "";
public static String DRIVER = "";
public static int initCount;
public static int maxCount;
public static int currentCount;
private static volatile ConnectionManager instance = null;
private ConnectionManager() {
init();
}
public static ConnectionManager getInstance() {
if (null == instance) {
synchronized (ConnectionManager.class) {
if (null == instance) {
return new ConnectionManager();
}
}
}
return instance;
}
public static void init() {
addConnection();
}
public static void addConnection() {
for (int i = 0; i < initCount; i++) {
try {
pool.add(createConnection());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
public static Connection createConnection() throws ClassNotFoundException {
Connection conn = null;
try {
Class.forName(DRIVER);
conn = DriverManager.getConnection(Url, USERNAME, PASSWORD);
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
/**
* 从连接池中获取连接
*
* @return
* @throws SQLException
* @throws ClassNotFoundException
*/
public static Connection getConnection() throws SQLException, ClassNotFoundException {
synchronized (pool) {
if (pool.size() > 0) {
System.out.println("Current Connection size is:" + pool.size());
return pool.get(0);
} else if (currentCount < maxCount) {
Class.forName(DRIVER);
Connection conn = createConnection();
pool.add(conn);
currentCount++;
return conn;
} else {
throw new SQLException("Current Connection is Zero");
}
}
}
/**
* 清空连接池,释放连接
*/
public static void clearPool() {
for (Connection connection : pool) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
pool = new LinkedList<Connection>();
}
public static void release(Connection conn) {
pool.remove(conn);
}
}
Utils.java
package com.git.zk;
import java.io.IOException;
import java.io.StringReader;
import java.util.Properties;
public class Utils {
public static void loadData(Properties pro, String cfg) throws IOException {
pro.load(new StringReader(cfg));
}
public static void createDbPool(Properties pro) {
// 解析配置信息,创建数据库连接池
ConnectionManager.DRIVER = pro.getProperty("driverClassName");
ConnectionManager.Url = pro.getProperty("url");
ConnectionManager.USERNAME = pro.getProperty("username");
ConnectionManager.PASSWORD = pro.getProperty("password");
ConnectionManager.initCount = Integer.parseInt(pro.getProperty("initCount"));
ConnectionManager.maxCount = Integer.parseInt(pro.getProperty("maxCount"));
ConnectionManager.currentCount = Integer.parseInt(pro.getProperty("currentCount"));
ConnectionManager.init();
}
}
5.启动时初始化数据库连接池并接听
package com.git.zk;
import com.git.zk.ConnectionManager;
import com.git.zk.Listener;
import com.git.zk.Utils;
import org.I0Itec.zkclient.ZkClient;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
@Component
public class Startup {
@PostConstruct
public void init() throws IOException, SQLException, ClassNotFoundException {
ZkClient zkClient = new ZkClient("hadoop1:2181,hadoop2:2181,hadoop3:2181");
String cfg = zkClient.readData("/webapp/dblinkcfg", true);
Properties pro = new Properties();
Utils.loadData(pro, cfg);
// 创建数据库连接池
Utils.createDbPool(pro);
// 监听节点数据的变化
Listener.monitor();
// 使用连接池测试
Connection conn = ConnectionManager.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement("select * from user");
ResultSet resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
System.out.println(resultSet.getString("id"));
System.out.println(resultSet.getString("username"));
}
}
}
6.需要在applicationContext.xml中配置自动扫描和注解驱动
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/mvc https://www.springframework.org/schema/mvc/spring-mvc.xsd">
<context:component-scan base-package="com.git.zk"></context:component-scan>
<context:annotation-config></context:annotation-config>
<mvc:default-servlet-handler></mvc:default-servlet-handler>
</beans>
7.定义测试类,往zk中/webapp/dblinkcfg节点的发布数据库配置信息
package com.git.zk;
import org.junit.Test;
public class PublisherTest {
Publisher publisher = new Publisher();
@Test
public void publish() {
String cfg = "driverClassName=com.mysql.jdbc.Driver\n" +
"url=jdbc:mysql://hadoop3:3306/test\n" +
"username=root\n" +
"password=root\n" +
"initCount=5\n" +
"maxCount=10\n" +
"currentCount=5";
publisher.publish(cfg);
System.out.println(publisher.zkClient.readData("/webapp/dblinkcfg", true).toString());
}
}
8.启动项目,修改节点中的数据
set /webapp/dblinkcfg{"url":"jdbc:mysql://hadoop1:3306/test?useUnicode=true&useSSL=false","username":"hive","password":"root","driver":"com.mysql.jdbc.Driver"}

9.删除节点/webapp/dblinkcfg
rmr /webapp

二、Azkaban作业要求
现有用户点击行为数据文件,每天产生会上传到hdfs目录,按天区分目录,现在我们需要每天凌晨两点定时导入Hive表指定分区中,并统计出今日活跃用户数插入指标表中。
日志文件:clicklog
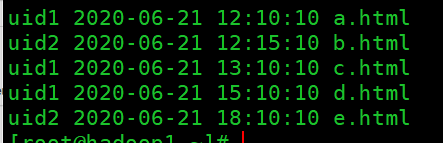
userId click_time index
uid1 2020-06-21 12:10:10 a.html
uid2 2020-06-21 12:15:10 b.html
uid1 2020-06-21 13:10:10 c.html
uid1 2020-06-21 15:10:10 d.html
uid2 2020-06-21 18:10:10 e.html
用户点击行为数据,三个字段是用户id, 点击时间,访问页面
hdfs目录会以日期划分文件,例如:
/user_clicks/20200621/clicklog.dat
/user_clicks/20200622/clicklog.dat
/user_clicks/20200623/clicklog.dat
Hive表
原始数据分区表
create table user_clicks(id string,click_time string, index string) partitioned by(dt string) row format delimited fields terminated by '\t' ;
需要开发一个import.job每日从hdfs对应日期目录下同步数据到该表指定分区。(日期格式同上或者自定义)
指标表
create table user_info(active_num string,dte string) row format delimited fields terminated by '\t' ;
需要开发一个analysis.job依赖import.job执行,统计出每日活跃用户(一个用户出现多次算作一次)数并插入user_inf表中。
作业
开发以上提到的两个job,job文件内容和sql内容需分开展示,并能使用azkaban调度执行。
实现步骤
1.首先,确保Linux服务器时区是自己想要的,如果不对,需修改时区。
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime

2.启动Hadoop集群,启动hive元数据服务,启动hive,创建hive表
[root@linux123 hive-2.3.7]# nohup hive --service metastore &
[root@linux123 hive-2.3.7]# hive
hive>use default;
create table user_clicks(id string,click_time string, index string) partitioned by(dt string) row format delimited fields terminated by '\t' ;
create table user_info(active_num string,dte string) row format delimited fields terminated by '\t' ;
2.编写hive从HDFS导入数据到表的shell脚本
vim /root/load_clicklog.sh
#!/bin/bash
## 环境变量生效
source /etc/profile
## HIVE_HOME
HIVE_HOME=/opt/lagou/servers/hive-2.3.7
## 每天的日志存储的目录名称,根据日期获取
yesterday=`date -d -1days '+%Y%m%d'`
## 源日志文件
LOG_FILE=/user_clicks/$yesterday/clicklog.dat
## hive执行.sql脚本
${HIVE_HOME}/bin/hive --hiveconf LOAD_FILE_PARAM=${LOG_FILE} --hiveconf yesterday=${yesterday} -f /root/load_data.sql
给脚本赋权
chmod 777 /root/load_clicklog.sh
3.编写将HDFS上的日志导入到hive表的sql脚本
vim /root/load_data.sql
LOAD DATA INPATH '${hiveconf:LOAD_FILE_PARAM}' OVERWRITE INTO TABLE default.user_clicks PARTITION(dt='${hiveconf:yesterday}');
4.创建job描述文件:loaddata2hive.job
type=command
command=sh /root/load_clicklog.sh
5.编写第二个分析数据的shell脚本
vim /root/analysis.sh
#!/bin/bash
## 环境变量生效
source /etc/profile
## HIVE_HOME
HIVE_HOME=/opt/lagou/servers/hive-2.3.7
## 每天的日志存储的目录名称,根据日期获取
yesterday=`date -d -1days '+%Y%m%d'`
## hive执行.sql脚本
${HIVE_HOME}/bin/hive --hiveconf yesterday=${yesterday} -f /root/analysis.sql
给脚本赋权
chmod 777 /root/analysis.sh
6.编写analysis.sql,统计每天活跃的用户并插入到表user_info.
insert into table default.user_info(active_num, dte) select id, click_time from user_clicks where dt='${hiveconf:yesterday}' group by click_time, id;
7.创建job描述文件:analysis.job
type=command
dependencies=loaddata2hive
command=sh /root/analysis.sh
8.将loaddata2hive.job和analysis.job打成压缩包:homework.zip
9.启动azkaban-web-server和azkaban-exec-server,在Azkaban web界面新建project,名称为homework
10.上传压缩包homework.zip
11.验证工作流程的正确性
先准备好前一天的数据放入到HDFS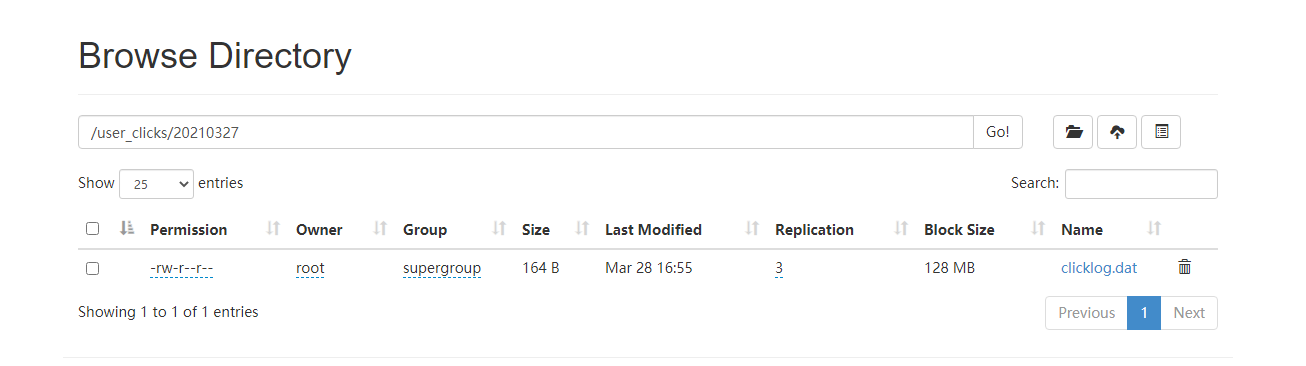
先清空hive表中的数据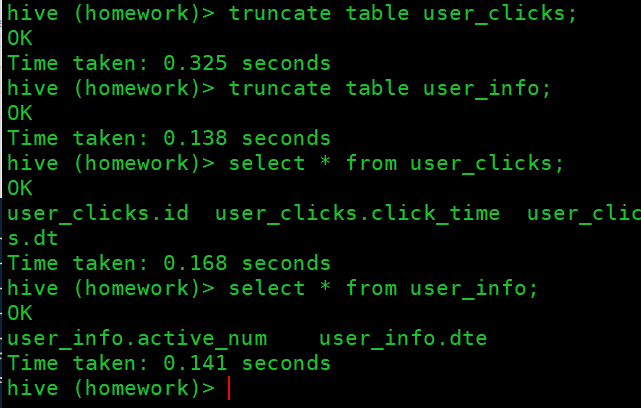
执行job,查看状态
查看hive表中的数据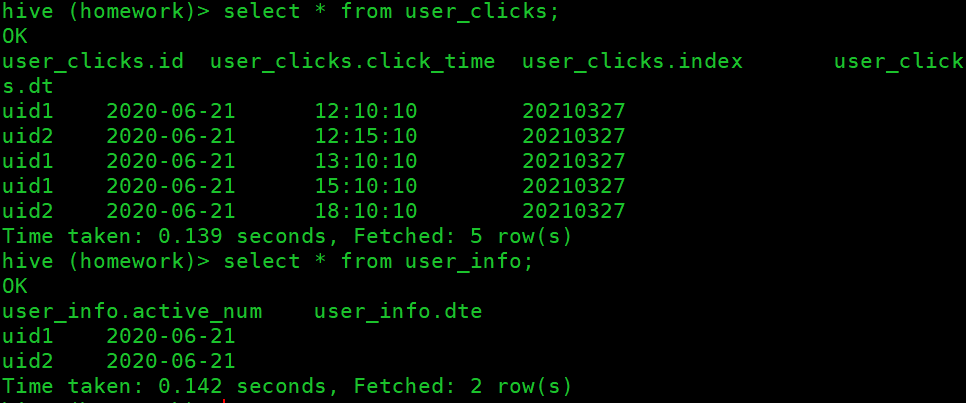
12.最后配置job调度时间

三、Hbase作业要求
在社交网站,社交APP上会存储有大量的用户数据以及用户之间的关系数据,比如A用户的好友列表会展示出他所有的好友,现有一张Hbase表,存储就是当前注册用户的好友关系数据,如下
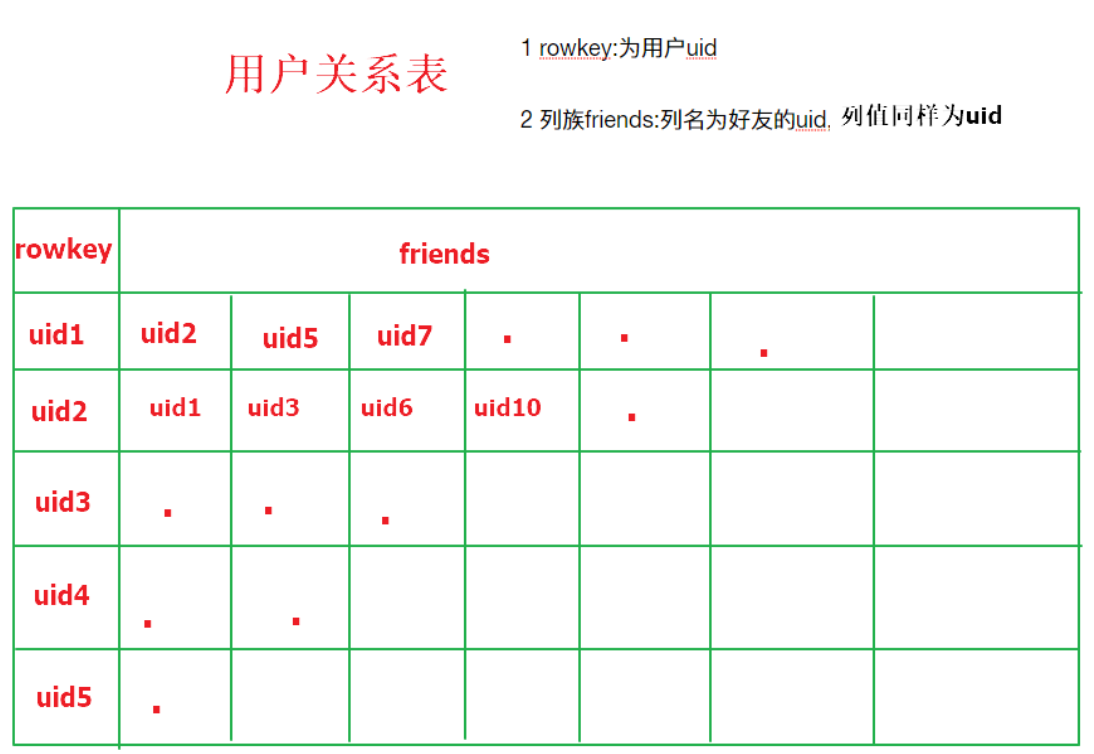
需求
- 使用Hbase相关API创建一张结构如上的表
- 删除好友操作实现(好友关系双向,一方删除好友,另一方也会被迫删除好友)
例如:uid1用户执行删除uid2这个好友,则uid2的好友列表中也必须删除uid1
实现步骤
创建maven工程,pom中引入相关jar包。
<dependencies> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>27.0.1-jre</version> </dependency> <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <version>6.14.3</version> <scope>test</scope> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.1</version> <scope>compile</scope> </dependency> </dependencies>编写Java代码,创建HBase表user_rel ```java package com.git.hbase.homework;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException; import java.util.ArrayList;
/**
- @author ytl
@date 2021/3/28 17:17 */ public class CreateTable {
static Connection conn = null; public static void main(String[] args){
Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "hadoop1,hadoop2,hadoop3"); conf.set("hbase.zookeeper.property.clientPort", "2181"); try { conn = ConnectionFactory.createConnection(conf); //获取HbaseAdmin对象用来创建表 HBaseAdmin admin =(HBaseAdmin) conn.getAdmin(); //创建Htabledesc描述器,表描述器 HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf( "hbase_user")); //指定列族 tableDescriptor.addFamily(new HColumnDescriptor("friends")); admin.createTable(tableDescriptor); System.out.println("表创建成功"); initData(); admin.close(); if (null != conf) { conn.close(); } } catch (IOException e) { System.out.println("表创建失败"); }
}
public static void initData() throws IOException {
Table table = conn.getTable(TableName.valueOf("hbase_user"));
//插入用户
Put u1 = new Put(Bytes.toBytes("001"));
u1.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("002"),Bytes.toBytes("002"));
u1.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("003"),Bytes.toBytes("003"));
u1.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("004"),Bytes.toBytes("004"));
Put u2 = new Put(Bytes.toBytes("002"));
u2.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("001"),Bytes.toBytes("001"));
u2.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("003"),Bytes.toBytes("003"));
u2.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("004"),Bytes.toBytes("004"));
Put u3 = new Put(Bytes.toBytes("003"));
u3.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("001"),Bytes.toBytes("001"));
u3.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("002"),Bytes.toBytes("002"));
u3.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("003"),Bytes.toBytes("003"));
ArrayList<Put> puts = new ArrayList<>();
puts.add(u1);
puts.add(u2);
puts.add(u3);
//写入
table.put(puts);
System.out.println("初始化数据成功");
}
}
```java
package com.git.hbase.homework;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
/**
* @author ytl
* @date 2021/3/28 17:17
*/
public class CreateTable {
static Configuration conf = null;
static Connection conn =null;
static {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","hadoop1,hadoop2");
conf.set("hbase.zookeeper.property.clientPort","2181");
try {
conn = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
//创建表
public void createTable() throws IOException {
Admin admin = conn.getAdmin();
HTableDescriptor table = new HTableDescriptor(TableName.valueOf("hbase_user"));
HColumnDescriptor friends = new HColumnDescriptor("friends");
table.addFamily(friends);
admin.createTable(table);
System.out.println("表创建成功");
admin.close();
}
//初始化数据
public void initData() throws IOException {
Table table = conn.getTable(TableName.valueOf("hbase_user"));
//插入用户
Put u1 = new Put(Bytes.toBytes("001"));
u1.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("002"),Bytes.toBytes("002"));
u1.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("003"),Bytes.toBytes("003"));
u1.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("004"),Bytes.toBytes("004"));
Put u2 = new Put(Bytes.toBytes("002"));
u2.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("001"),Bytes.toBytes("001"));
u2.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("003"),Bytes.toBytes("003"));
u2.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("004"),Bytes.toBytes("004"));
Put u3 = new Put(Bytes.toBytes("003"));
u3.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("001"),Bytes.toBytes("001"));
u3.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("002"),Bytes.toBytes("002"));
u3.addColumn(Bytes.toBytes("friends"),Bytes.toBytes("003"),Bytes.toBytes("003"));
ArrayList<Put> puts = new ArrayList<>();
puts.add(u1);
puts.add(u2);
puts.add(u3);
//写入
table.put(puts);
System.out.println("初始化数据成功");
}
//某个用户其中一个好友
public void deleteFriends(String uid,String friends) throws IOException {
Table table = conn.getTable(TableName.valueOf("hbase_user"));
Delete delete = new Delete(Bytes.toBytes(uid));
delete.addColumn(Bytes.toBytes("friends"), Bytes.toBytes(friends));
table.delete(delete);
}
}
运行main方法,hbase shell中验证表是否创建成功

- 创建Observer 协处理器,实现当uid1删除uid2时,触发uid2删除uid1的操作 ```java package com.git.hbase.homework;
import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Durability; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver; import org.apache.hadoop.hbase.coprocessor.ObserverContext; import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment; import org.apache.hadoop.hbase.regionserver.wal.WALEdit; import org.apache.hadoop.hbase.util.Bytes; import org.slf4j.Logger; import org.slf4j.LoggerFactory;
import java.io.IOException; import java.util.List;
/**
- @author ytl
@date 2021/3/28 17:30 */ public class DeleteFriend extends BaseRegionObserver { Logger logger = LoggerFactory.getLogger(DeleteFriend.class);
@Override public void postDelete(ObserverContext
e, Delete delete, WALEdit edit, Durability durability) throws IOException { //获取user_rel表table对象 HTable user_rel = (HTable)e.getEnvironment().getTable(TableName.valueOf("user")); //获取删除的行rowkey byte[] row = delete.getRow(); //获取friends下的所有cell List<Cell> friends = delete.getFamilyCellMap().get(Bytes.toBytes("friends")); for (Cell friend : friends) { byte[] bytes = CellUtil.cloneQualifier(friend); Delete delete1 = new Delete(bytes); delete.addColumn(Bytes.toBytes("friends"),row); user_rel.delete(delete1); } user_rel.flushCommits(); user_rel.close();} }
import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver; import org.apache.hadoop.hbase.coprocessor.ObserverContext; import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment; import org.apache.hadoop.hbase.regionserver.wal.WALEdit; import org.apache.hadoop.hbase.util.Bytes; import org.slf4j.Logger; import org.slf4j.LoggerFactory;
import java.io.IOException; import java.util.List; import java.util.Map; import java.util.NavigableMap; import java.util.Set;
/**
- @author ytl
@date 2021/3/28 17:30 */ public class DeleteProcessor extends BaseRegionObserver { @Override public void postDelete(ObserverContext
e, final Delete delete, WALEdit edit, Durability durability) throws IOException { //获取userRel表对象 HTableInterface table = e.getEnvironment().getTable(TableName.valueOf("hbase_user")); //获取删除的行rowkey byte[] row = delete.getRow(); //获取到firends下所有的cell NavigableMap<byte[], List<Cell>> familyCellMap = delete.getFamilyCellMap(); Set<Map.Entry<byte[], List<Cell>>> entries = familyCellMap.entrySet(); for (Map.Entry<byte[], List<Cell>> entry : entries) { //列族信息 System.out.println(Bytes.toString(entry.getKey())); List<Cell> value = entry.getValue(); for (Cell cell : value) { //rowkey信息 byte[] rowkey = CellUtil.cloneRow(cell); //列信息 byte[] column = CellUtil.cloneQualifier(cell); //验证删除的目标数据是否存在,存在则删除,否则不删除,必须判断,否则造成协处理器被循环调用耗尽资源 boolean flag = table.equals(new Get(column).addColumn(Bytes.toBytes("friends"), rowkey)); if (flag) { Delete delete1 = new Delete(column).addColumn(Bytes.toBytes("friends"), rowkey); table.delete(delete1); } } }} }
4. 挂载协处理器
```sql
alter 'user',METHOD=>'table_att','Coprocessor'=>'hdfs://hadoop1:9000/processor/homework1.jar|com.git.hbase.homework.DeleteFriend|1001|'

添加测试数据
put 'user','1000','friends:1001','1001' put 'user','1000','friends:1002','1002' put 'user','1001','friends:1000','1000' put 'user','1001','friends:1002','1002' put 'user','1002','friends:1000','1000' put 'user','1002','friends:1001','1001'
删除数据,并查看表数据
delete 'user','1002','friends:1000'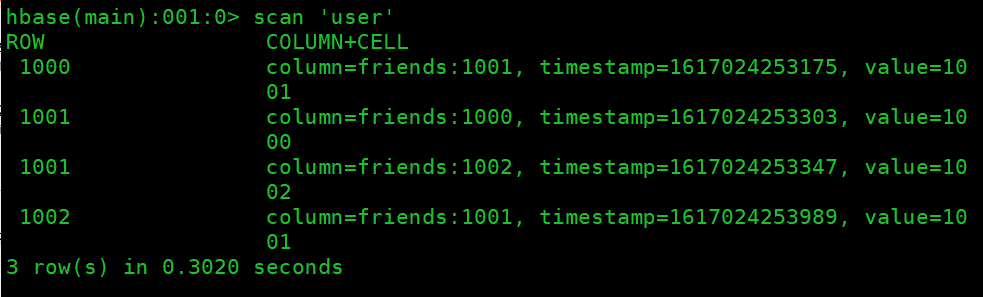

若有收获,就点个赞吧
0 人点赞
