数据集包含两个csv格式文件,data为我们接下来要使用的数据,test为kaggle提供的测试集。
1. 泰坦尼克号生存者预测
1. 导入所需要的库
import pandas as pdfrom sklearn.tree import DecisionTreeClassifier #决策树from sklearn.model_selection import train_test_split #分测试集训练集from sklearn.model_selection import GridSearchCV #网格搜索from sklearn.model_selection import cross_val_score #交叉验证import matplotlib.pyplot as plt
2. 导入数据集
# 导入数据集data = pd.read_csv(r'C:\Users\18700\Desktop\.ipynb_checkpoints\data.csv') #前面写一个r,就不用在对文件的\进行修改。data#探索数据data.info()data.head(5)
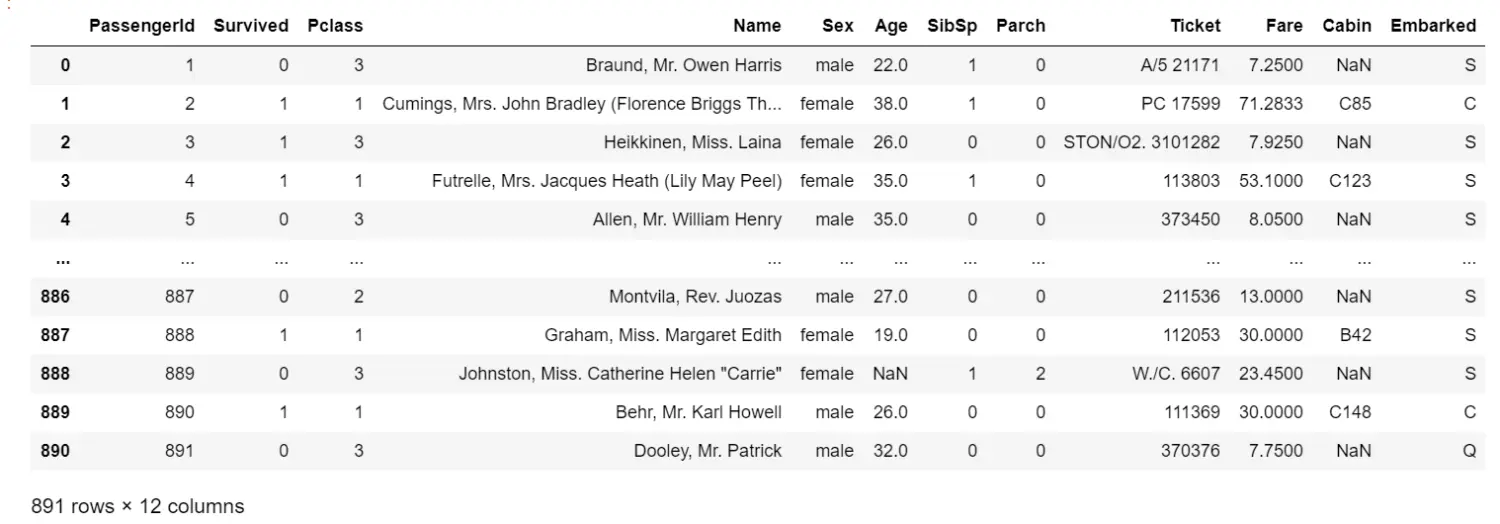
3. 对数据集进行预处理
##筛选特征 删除不需要的特征data.drop(['Cabin','Name','Ticket'],inplace=True,axis=1) #drop删除操作,inpalce=True是生成的表格覆盖原表,axis=1是对列进行操作,=0是删除行。##处理缺失值data['Age'] = data['Age'].fillna(data['Age'].mean()) #用mean值填补na值data.info()## 删除有缺失值的行 Embarkeddata= data.dropna(axis=0) #dropna是删除nadata.info()##将三分类转换为数值变量data['Embarked'].unique() #看有哪些信息labels= data['Embarked'].unique().tolist()# 将其转换维列表data['Embarked']= data['Embarked'].apply(lambda x: labels.index(x)) #将Embarked中每行的数据查找其在labels.index中的索引(S', 'C', 'Q'分别对应0,1,2)## 将二分类转换为数值变量data['Sex'] = (data['Sex']=='male').astype('int') #astype将布尔值转换为0-1,(data['Sex']=='male')是返回是不是male的布尔值data.head()
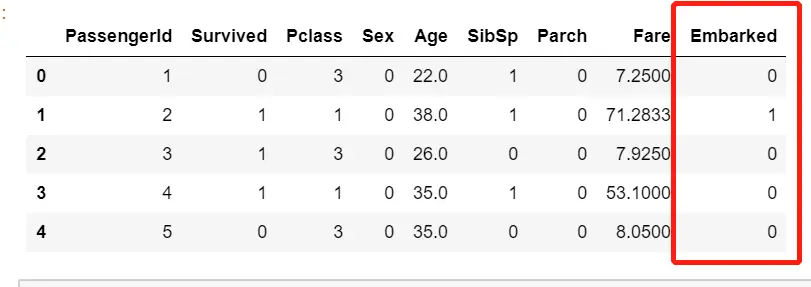
4. 提取标签和特征矩阵,分测试集和训练集
x = data.iloc[:,data.columns != 'Survived'] #iloc用来提取表格的行列,行全部提取,提取列不等于survived的。y = data.iloc[:,data.columns == 'Survived']x.head()y.head()Xtrain,Xtest,Ytrain,Ytest = train_test_split(x,y,test_size=0.3) #分训练集和测试集#修正测试集和训练集的索引#Xtrian.index = range(Xtrian.shape[0])#Xtrain.shape是Xtrain的结构(622,8),[0]就是取662,[1]就是取8,Xtrian.index=range(622)就是将Xtrain的索引按照0-621进行排序for i in [Xtrain, Xtest, Ytrain, Ytest]:i.index = range(i.shape[0])Xtrain.head()
5. 导入模型,粗略跑一下查看结果
#导入模型,粗略跑一下查看结果clf = DecisionTreeClassifier(random_state=25) #实例化clf = clf.fit(Xtrain,Ytrain)#训练score = clf.score(Xtest,Ytest) #模型精确度score
使用交叉验证
#使用交叉验证clf = DecisionTreeClassifier(random_state = 25)score = cross_val_score(clf,x,y,cv=10).mean() #交叉验证不自己分训练集和测试集score
6. 在不同max_depth下观察模型的拟合状况
tr=[] #制作一个空表te=[]for i in range(10): #range(10)是取值0-9的10个数clf = DecisionTreeClassifier(random_state = 25,max_depth=i+1) #max_depth=i+1就是树的最大深度是1-10clf = clf.fit(Xtrain,Ytrain)score_tr = clf.score(Xtrain,Ytrain) #训练集模型精确度score_te = cross_val_score(clf,x,y,cv=10).mean() #测试集交叉验证得分tr.append(score_tr) #将得到的score_tr不停的加入tr的表格中te.append(score_te)print(max(te))plt.plot(range(1,11),tr,color = 'red',label='train') #rang(1,11)就是数字1-10plt.plot(range(1,11),te,color = 'blue',label='test')plt.xticks(range(1,11)) #规定x取1-10的整数plt.legend()plt.show()
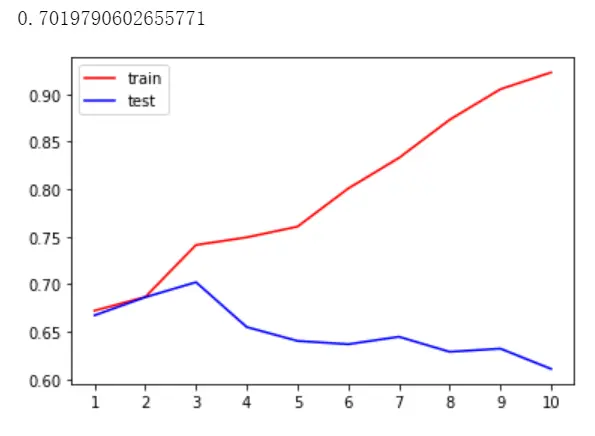
可以看到在max_depth=3的时候,test的得分最高,往后train发生了过拟合,所以我们应该让最大深度=3.
将标准换维entropy
##将标准换为entropy,虽然entropy是在欠拟合下下使用的,但是我们的数据其实在max_depth=3的时候,其实还没有拟合。criterion默认是gini.tr=[] #制作一个空表te=[]for i in range(10): #range(10)是取值0-9的10个数clf = DecisionTreeClassifier(random_state = 25,max_depth=i+1,criterion = 'entropy')clf = clf.fit(Xtrain,Ytrain)score_tr = clf.score(Xtrain,Ytrain) #训练集模型精确度score_te = cross_val_score(clf,x,y,cv=10).mean() #测试集交叉验证得分tr.append(score_tr) #将得到的score_tr不停的加入tr的表格中te.append(score_te)print(max(te))plt.plot(range(1,11),tr,color = 'red',label='train') #rang(1,11)就是数字1-10plt.plot(range(1,11),te,color = 'blue',label='test')plt.xticks(range(1,11)) #规定x取1-10的整数plt.legend()plt.show()
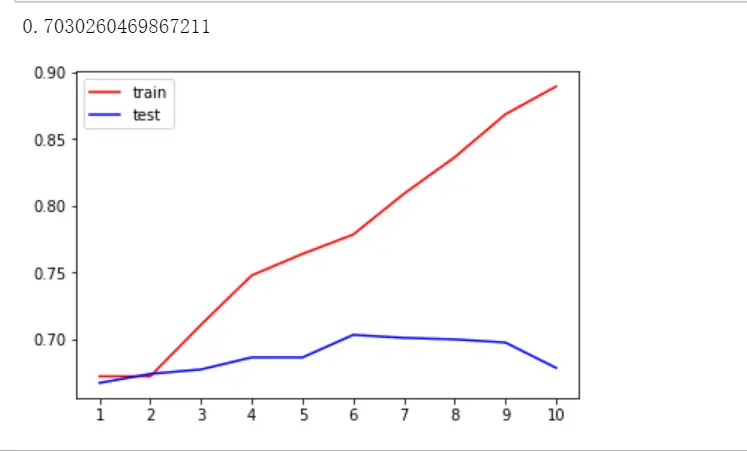
可以看到,socre并没有提高
7. 用网格搜索调整参数: 可以同时调整多个参数,枚举技术
import numpy as npgini_thresholds = np.linspace(0,0.5,20) #linspace在0-0.5之间随机取20个数#parameters一串参数和这些参数对应的,我们希望网格搜索来搜索的参数的取值范围,是一个字典parameters= {'criterion':('gini','entropy'),'splitter':('best','random'),'max_depth':[*range(1,10)] #[*range(1,10)]就是[1,2,3,4,5,6,7,8,9],'min_samples_leaf':[*range(1,50,5)],'min_impurity_decrease':[*np.linspace(0,0.5,20)]}clf = DecisionTreeClassifier(random_state=25) #实例化GS = GridSearchCV(clf, parameters, cv=10) #实例化GS.fit(Xtrain,Ytrain) #训练

#网格搜索的两个重要属性和接口GS.best_params_ #返回输入参数中的最佳组合GS.best_score_ #网格搜索后的模型的评判标准

网格搜索的缺点:不能舍弃参数,比如本来是gini+max_depth=3时候已经得到了最佳的socre,但是因为又提供了solitter,min_samples_leaf等,它就也会把这些的数据也纳进来继续运算。
2. 决策树的优缺点
决策树优点
- 易于理解和解释,因为树木可以画出来被看见
- 需要很少的数据准备。其他很多算法通常都需要数据规范化,需要创建虚拟变量并删除空值等。但请注意,sklearn中的决策树模块不支持对缺失值的处理。
- 使用树的成本(比如说,在预测数据的时候)是用于训练树的数据点的数量的对数,相比于其他算法,这是一个很低的成本。
- 能够同时处理数字和分类数据,既可以做回归又可以做分类。其他技术通常专门用于分析仅具有一种变量类型的数据集。
- 能够处理多输出问题,即含有多个标签的问题,注意与一个标签中含有多种标签分类的问题区别开
- 是一个白盒模型,结果很容易能够被解释。如果在模型中可以观察到给定的情况,则可以通过布尔逻辑轻松解释条件。相反,在黑盒模型中(例如,在人工神经网络中),结果可能更难以解释。
- 可以使用统计测试验证模型,这让我们可以考虑模型的可靠性。
- 即使其假设在某种程度上违反了生成数据的真实模型,也能够表现良好。
决策树的缺点
- 决策树学习者可能创建过于复杂的树,这些树不能很好地推广数据。这称为过度拟合。修剪,设置叶节点所需的最小样本数或设置树的最大深度等机制是避免此问题所必需的,而这些参数的整合和调整对初学者来说会比较晦涩
- 决策树可能不稳定,数据中微小的变化可能导致生成完全不同的树,这个问题需要通过集成算法来解决。
- 决策树的学习是基于贪婪算法,它靠优化局部最优(每个节点的最优)来试图达到整体的最优,但这种做法不能保证返回全局最优决策树。这个问题也可以由集成算法来解决,在随机森林中,特征和样本会在分枝过程中被随机采样。
- 有些概念很难学习,因为决策树不容易表达它们,例如XOR,奇偶校验或多路复用器问题。
- 如果标签中的某些类占主导地位,决策树学习者会创建偏向主导类的树。因此,建议在拟合决策树之前平衡数据集。
参考菜菜的sklearn课程

若有收获,就点个赞吧
0 人点赞
