降维(PCA)
PCA能够将原始数据集中重要的数据进行聚集。
降维是减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。
在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方
差,方差越大,特征所带的信息量越多。
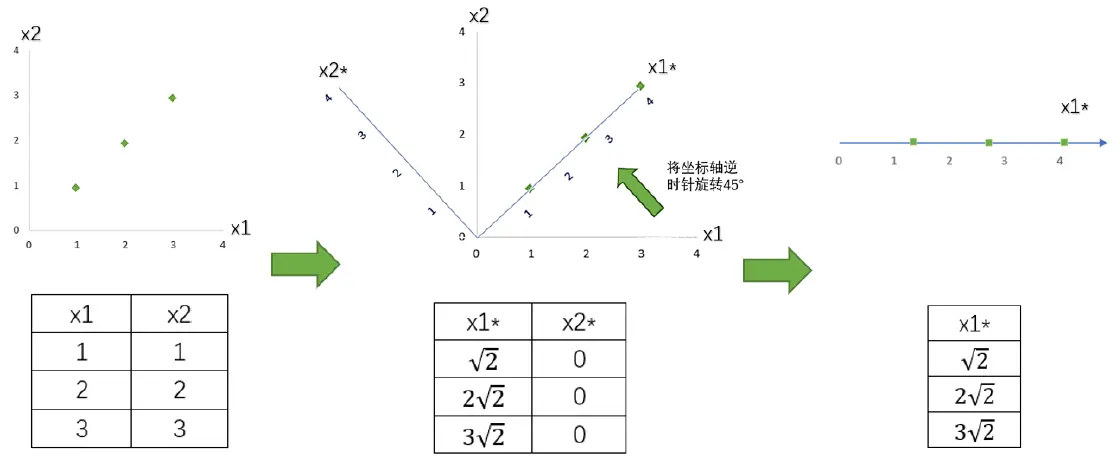
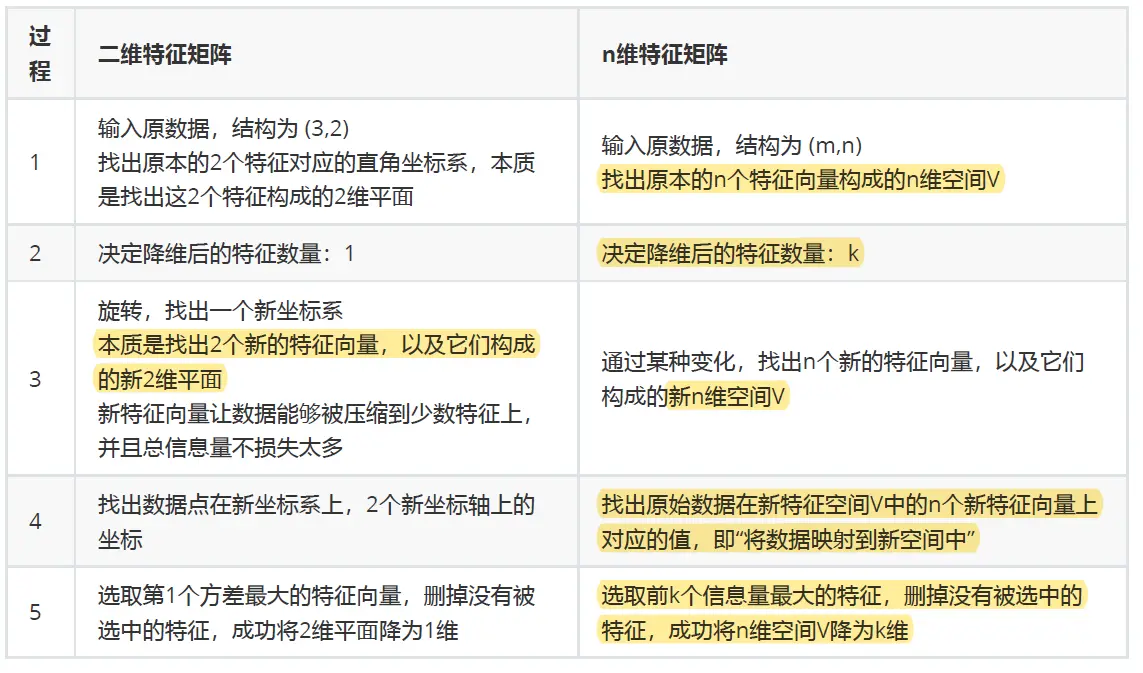
在步骤3当中,我们用来找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。
PCA和特征选择的不同之处?
- 特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,我们依然知道这个特征在原数据的哪个位置,代表着原数据上的什么含义。
- PCA在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向
量,新特征矩阵生成之后也不具有可读性。- PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,我们使用特征选择。
重要参数n_components
- n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数。
- PCA的最大似然估计(maximum likelihood estimation)自选超参数的方法,输入“mle”作为n_components的参数输入,就可以调用这种方法。
pca_mle = PCA(n_components="mle")pca_mle = pca_mle.fit(X)X_mle = pca_mle.transform(X)
- 输入[0,1]之间的浮点数,并且让参数svd_solver ==’full’,表示希望降维后的总解释性方差占比大于n_components指定的百分比,即是说,希望保留百分之多少的信息量。
pca_f = PCA(n_components=0.97,svd_solver="full") #降维后保留97%的信息量pca_f = pca_f.fit(X)X_f = pca_f.transform(X)pca_f.explained_variance_ratio_
重要参数svd_solver
参数svd_solver是在降维过程中,用来控制矩阵分解的一些细节的参数。有四种模式可选:”auto”, “full”, “arpack”, “randomized”,默认”auto”。通常我们就选用”auto“,不必对这个参数纠结太多。
重要属性components_
V(k,n)是新特征空间,是我们要将原始数据进行映射的那些新特征向量组成的矩阵。在矩阵分解时,PCA是有目标的:在原有特征的基础上,找出能够让信息尽量聚集的新特征向量。在sklearn使用的PCA和SVD联合的降维方法中,这些新特征向量组成的新特征空间其实就是V(k,n)。
重要接口inverse_transform
pca = PCA(150)X_dr = pca.fit_transform(X)X_dr.shapeX_inverse = pca.inverse_transform(X_dr)X_inverse.shape
Inverse_transform的功能,是基于X_dr中的数据进行升维,将数据重新映射到原数据所在的特征空间中,而并非恢复所有原有的数据。所以,降维不是完全可逆的。
inverse_transform能够在不恢复原始数据的情况下,将降维后的数据返回到原本的高维空间,即是说能够实现保证维度,但去掉方差很小特征所带的信息。
案例:PCA对手写数字数据集的降维
1 导入需要的模块和库
from sklearn.decomposition import PCAfrom sklearn.ensemble import RandomForestClassifier as RFCfrom sklearn.model_selection import cross_val_scoreimport matplotlib.pyplot as pltimport pandas as pdimport numpy as np
2 导入数据
data = pd.read_csv(r"C:\Users\18700\Desktop\04主成分分析PCA与奇异值分解SVD\digit recognizor.csv")X = data.iloc[:,1:]y = data.iloc[:,0]X.shape#(42000, 784)
3 画累计方差贡献率曲线,找最佳降维后维度的范围
pca_line = PCA().fit(X) #PCA不填是返回min(X.shape)# pca_line = PCA().fit(X) #PCA不填是返回min(X.shape)# pca_line.explained_variance_ratio_ #每个特征的贡献率plt.figure(figsize=[20,5])plt.plot(np.cumsum(pca_line.explained_variance_ratio_)) #cumsum特征依次求和1,1+2,1+2+3plt.xlabel("number of components after dimension reduction")plt.ylabel("cumulative explained variance ratio")plt.show()
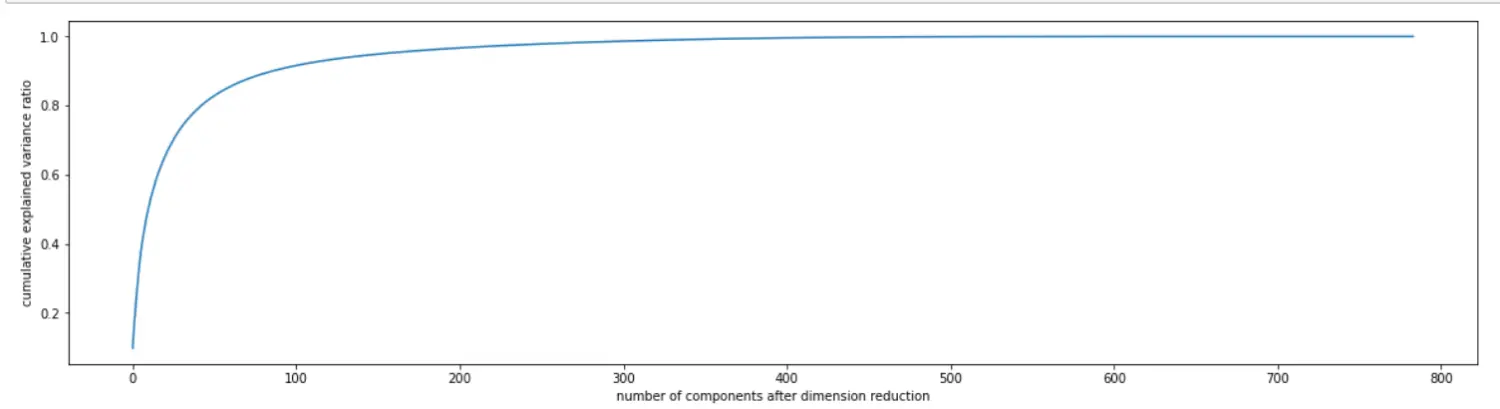
4 降维后维度的学习曲线,继续缩小最佳维度的范围
score = []for i in range(1,101,10):X_dr = PCA(i).fit_transform(X)#用降维的X_dronce = cross_val_score(RFC(n_estimators=10,random_state=0),X_dr,y,cv=5).mean() #cross_val_score(模型,x,y,cv)score.append(once)plt.figure(figsize=[20,5])plt.plot(range(1,101,10),score)plt.show()

5 细化学习曲线,找出降维后的最佳维度
score = []for i in range(10,25): #10-25继续遍历X_dr = PCA(i).fit_transform(X)once = cross_val_score(RFC(n_estimators=10,random_state=0),X_dr,y,cv=5).mean() #cross_val_score(模型,x,y,cv)score.append(once)plt.figure(figsize=[20,5])plt.plot(range(10,25),score)plt.show()
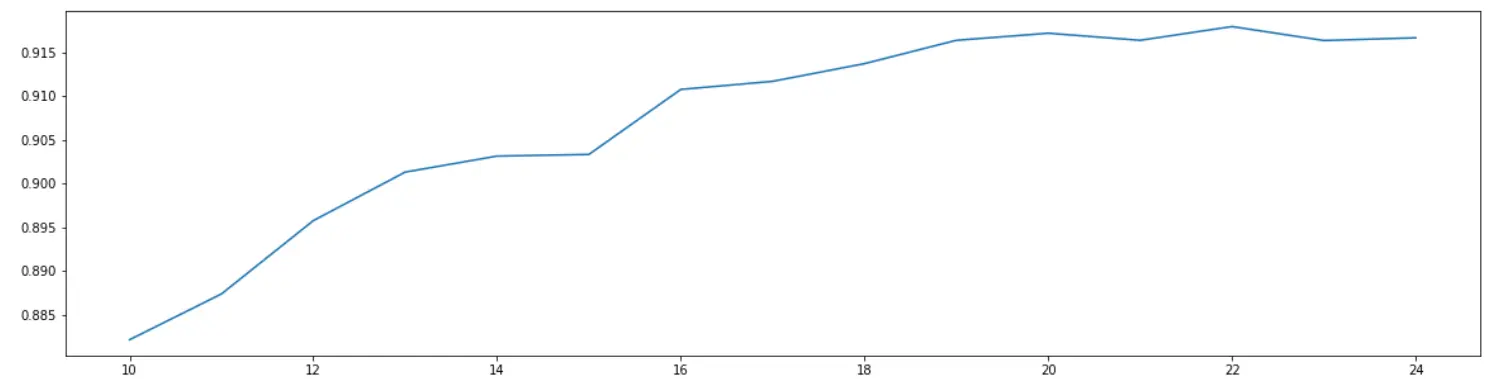
6 导入找出的最佳维度进行降维,查看模型效果
X_dr = PCA(22).fit_transform(X) #X_dr就是降到21维的新特征矩阵X_dr.shapecross_val_score(RFC(n_estimators=10,random_state=0),X_dr,y,cv=5).mean() #调整n_estimators的参数cross_val_score(RFC(n_estimators=100,random_state=0),X_dr,y,cv=5).mean()
输出结果
(42000, 22)0.91585714285714270.9458333333333334
7 KNN模型
现在特征数量已经降到不足原来的3%,可以使用KNN。
from sklearn.neighbors import KNeighborsClassifier as KNN #导入最近邻分类器cross_val_score(KNN(),X_dr,y,cv=5).mean() #KNN默认K=5
8 KNN的k值学习曲线
score = []for i in range(10):#X_dr = PCA(22).fit_transform(X)once = cross_val_score(KNN(i+1),X_dr,y,cv=5).mean() #k取1-10score.append(once)plt.figure(figsize=[20,5])plt.plot(range(10),score)plt.show()

9 定下超参数后,模型效果如何
cross_val_score(KNN(5),X_dr,y,cv=5).mean()# %%timeit# cross_val_score(KNN(5),X_dr,y,cv=5).mean()
输出结果
0.9699047619047618
可以发现,原本785列的特征被我们缩减到23列之后,用KNN跑出了目前位置这个数据集上最好的结果。再进行更细致的调整,我们也许可以将KNN的效果调整到98%以上。
总之,对于一个数据先进行PCA降维处理,再做特征选择处理。

若有收获,就点个赞吧
0 人点赞
